この記事は、Fusic Advent Calendar 2019 18日目の記事です。
昨日は @tutida による「Lambda Destinations を SAM で試してみた」でした。Lambdaの新機能、良さそうですね!
本記事は、lightGBMでのハイパラ探索のやってみた記事です。とりあえず動かし方を知る、初心者向けの内容となります。
本記事の対象者
- lightGBM(回帰)でBayesian Optimizationをやってみたい人・やり方忘れた人
ベイズ最適化によるハイパーパラメータ探索について
本記事では説明を割愛させていただきます。(私自体がまだ勉強できてません🙇)
こちらの動画やこちらの記事がわかりやすそうです。
環境
- Google Colab(CPU): Python3
データセット
- House Sales in King County, USAを使います。
- 「このデータセットには、シアトルを含むキング郡の住宅販売価格が含まれています。2014年5月から2015年5月の間に販売された住宅が含まれます。」とのことです。
- レコード数は21,613件です。
- 説明変数は18個ありますが、今回は以下の10個のみを使用します。
'sqft_living','grade', 'sqft_above', 'sqft_living15',
'bathrooms','view','sqft_basement','lat','waterfront'
- 目的変数は
priceです。
内容
探索前・後で比較してみます。
探索前
データセットのアップロードとデータの前処理を行った後、学習させます。
参考までにデータの前処理までのコードはこちら
import gc
import lightgbm as lgb
import math
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import urllib.request
from google.colab import files
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split, KFold
seed = 12345
num_round = 1000
n_folds = 3
# 手元からデータをColabにアップロードする
uploaded = files.upload()
org_df = pd.read_csv('kc_house_data.csv')
df = org_df[['price', 'sqft_living','grade', 'sqft_above', 'sqft_living15','bathrooms','view','sqft_basement','lat','waterfront']]
train_df, test_df = train_test_split(df, test_size=0.2, shuffle=True, random_state=seed)
train_df = train_df.reset_index(drop=True)
test_df = test_df.reset_index(drop=True)
y_train = train_df.pop('price')
y_test = test_df.pop('price')
以下、学習部分のコードです。
categorical_features = ["grade", "view", "waterfront"]
params = {
"application": "regression_l1",
'learning_rate': 0.1,
"metric": "mae",
}
shuffle = False
kf = KFold(n_splits=n_folds, shuffle=shuffle, random_state=seed)
models = []
for train_index, test_index in kf.split(train_df):
train_features = train_df.loc[train_index]
train_target = y_train.loc[train_index]
test_features = train_df.loc[test_index]
test_target = y_train.loc[test_index]
d_training = lgb.Dataset(train_features, label=train_target, categorical_feature=categorical_features, free_raw_data=False)
d_test = lgb.Dataset(test_features, label=test_target,categorical_feature=categorical_features, free_raw_data=False)
model = lgb.train(params,
train_set=d_training,
num_boost_round=num_round,
valid_sets=[d_training,d_test],
verbose_eval=50,
early_stopping_rounds=50)
models.append(model)
del train_features, train_target, test_features, test_target, d_training, d_test
gc.collect()
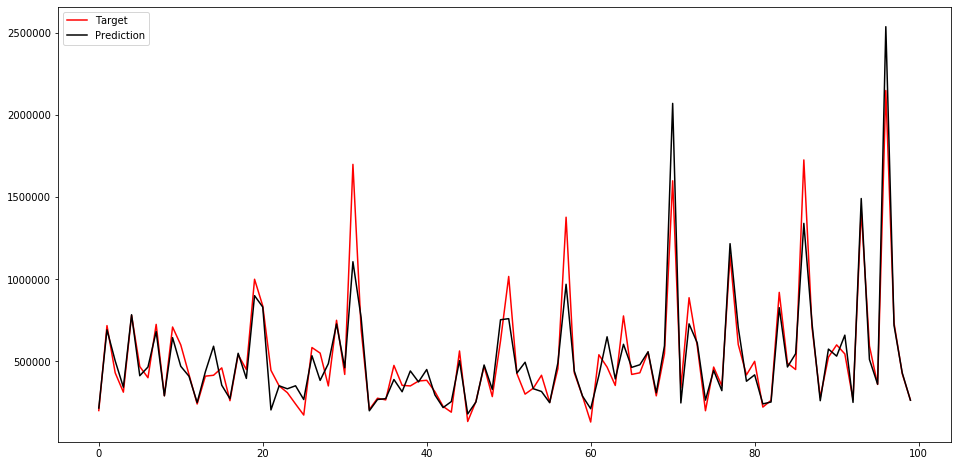
学習前に分割して残しておいたテストデータに対して評価を実行すると、mean_absolute_errorが 82482.93 となりました。
先頭から100個目までのテストデータのラベル値・予測値をプロットすると以下のようなになりました。
参考までに評価のコードはこちら
def pred(X_test, models, batch_size=1000):
iterations = (X_test.shape[0] + batch_size -1) // batch_size
print('iterations', iterations)
y_test_pred_total = np.zeros(X_test.shape[0])
for i, model in enumerate(models):
print(f'predicting {i}-th model')
for k in range(iterations):
y_pred_test = model.predict(X_test[k*batch_size:(k+1)*batch_size], num_iteration=model.best_iteration)
y_test_pred_total[k*batch_size:(k+1)*batch_size] += y_pred_test
y_test_pred_total /= len(models)
return y_test_pred_total
preds = pred(test_df, models)
mean_absolute_error(y_test, preds)
xs = list(range(100))
fig = plt.figure(figsize=(16, 8))
plt.plot(xs, y_test.values[:100], color = 'r')
plt.plot(xs, preds[:100], color = 'k');
plt.legend(['Target', 'Prediction'], loc = 'upper left');
plt.show()
ハイパラ探索
BayesianOptimizationを使用しました。
以下のコードです。
! pip install bayesian-optimization
from bayes_opt import BayesianOptimization
def lgb_eval(num_leaves, feature_fraction, bagging_fraction, max_depth, lambda_l1, lambda_l2):
train_data = lgb.Dataset(train_df, label=y_train, categorical_feature=categorical_features, free_raw_data=False)
params = {
'application': 'regression_l1',
'num_iterations': num_round,
'learning_rate': 0.1,
'early_stopping_round': 50,
'metric':'mae'
}
params["num_leaves"] = math.ceil(num_leaves)
params['feature_fraction'] = max(min(feature_fraction, 1), 0)
params['bagging_fraction'] = max(min(bagging_fraction, 1), 0)
params['max_depth'] = math.ceil(max_depth)
params['lambda_l1'] = max(lambda_l1, 0)
params['lambda_l2'] = max(lambda_l2, 0)
cv_result = lgb.cv(params, train_data, num_boost_round=num_round, nfold=n_folds, seed=seed, verbose_eval=50, stratified=False)
return max(cv_result['l1-mean'])
lgbBO = BayesianOptimization(lgb_eval, {'num_leaves': (31, 100),
'feature_fraction': (0.6, 1),
'bagging_fraction': (0.8, 1),
'max_depth': (5, 15),
'lambda_l1': (0, 1),
'lambda_l2': (0, 1)}, random_state=seed)
init_round=10
opt_round=15
lgbBO.maximize(init_points=init_round, n_iter=opt_round)
ちなみに上記のmaximizeを計測した結果は以下でした。
CPU times: user 6.6 s, sys: 366 ms, total: 6.97 s
Wall time: 3.7 s
この処理により、以下のパラメータが得られました。
lgbBO.max['params']
{'bagging_fraction': 0.9192732020838761,
'feature_fraction': 0.6207830180410134,
'lambda_l1': 0.8950895280539212,
'lambda_l2': 0.7282661803271173,
'max_depth': 13.183500113899145,
'num_leaves': 65.51536994557694}
探索後
上記のパラメータを使って再度学習させてみます。
categorical_features = ["grade", "view", "waterfront"]
params = {
"application": "regression_l1",
"learning_rate": 0.1,
"metric": "mae",
}
params.update(lgbBO.max['params'])
params['num_leaves'] = math.ceil(params['num_leaves'])
params['max_depth'] = math.ceil(params['max_depth'])
shuffle = False
kf = KFold(n_splits=n_folds, shuffle=shuffle, random_state=seed)
turned_models = []
for train_index, test_index in kf.split(train_df):
train_features = train_df.loc[train_index]
train_target = y_train.loc[train_index]
test_features = train_df.loc[test_index]
test_target = y_train.loc[test_index]
d_training = lgb.Dataset(train_features, label=train_target, categorical_feature=categorical_features, free_raw_data=False)
d_test = lgb.Dataset(test_features, label=test_target,categorical_feature=categorical_features, free_raw_data=False)
model = lgb.train(params,
train_set=d_training,
num_boost_round=num_round,
valid_sets=[d_training,d_test],
verbose_eval=25,
early_stopping_rounds=50)
turned_models.append(model)
del train_features, train_target, test_features, test_target, d_training, d_test
gc.collect()
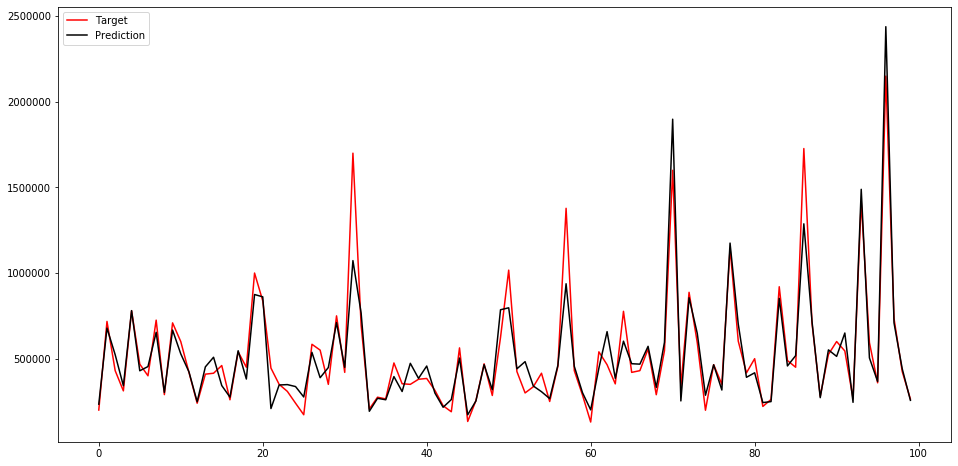
学習したモデルで評価すると、mean_absolute_errorが83192.65となりました。
探索前より悪くなってしまっていますね…。
ちなみにグラフは以下のようになりました。
まとめ・感想
- ベイズ最適化によるハイパーパラメータ探索をやってみました。
- 実装自体は様々な記事を上げてくださっているので、簡単にできました。
- 一方で、結果としては探索後のほうが探索前より悪くなってしまいました。いくつか理由を考えみました。
-
maximize()のイテレーションが少なく局所解に陥っている or 探索が足りていない? - 探索範囲の指定が効果的なものに出来ていない?
-
- いずれにしろ、「BayesianOptimization使っておけば素人でも誰でもチューニングできる」というわけでは無さそうだと感じました。
- 現在、Kaggleで表データコンペに参加しているので、そちらでも同じようなことをやろうと思っています。もし効果が出たら別記事で報告させていただきます。
参考にした記事
- scikit-optimize の BayesSearchCV を用いたベイズ最適化によるハイパーパラメータ探索
- Predicting King County House Prices
- google Colaboratoryでファイルを読み込む方法
- Hyperparameters Optimization for LightGBM, CatBoost and XGBoost Regressors using Bayesian Optimization.
以上です!