この記事はエイチーム引越し侍 / エイチームコネクト Advent Calendar 2019の14日目の記事です。本日はエイチーム引越し侍の新卒1年目@m-otsukaが担当します。
この記事でやること
GoogleのNatural Languageサービスの1つである
Natural Language APIを用いて、商品レビューを感情分析をしてみます。
Natural Languageとは?
「AutoML Natural Language」と「Natural Language API」の2つのサービスから成るテキスト分析サービスです。
「AutoML Natural Language」は、分析に用いるカスタムモデルの作成を行うことができ、「Natural Language API」では、Googleが持つトレーニング済みモデルを用いて、感情分析、エンティティ分析など、様々な分析を行うことができます。
今回は、Natural Language APIを用いて、感情分析を行います。
感情分析
Natural Language APIでは、__analyzeSentiment__と__analyzeEntitySentiment__という2種類の感情分析があります。
今回は__analyzeSentimen__tメソッドを用いて感情分析を行います。__analyzeSentiment__メソッドでは、ドキュメント全体に対しての感情評価を行うことができます。
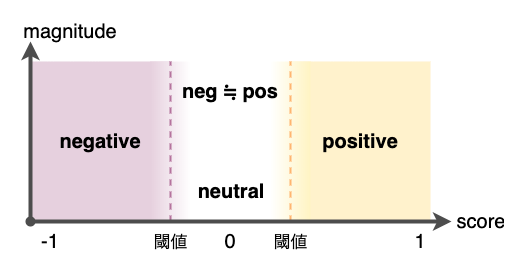
Natural Language APIの感情分析では、__score__と__magnitude__の2つの値を取得することができます。この2つの値を用いて、ドキュメントから著者の感情が、ポジティブかネガティブか、ニュートラルかを判断することができます。
score
- 値が取り得る範囲:-1.0 ~ 1.0|
- ポジティブか、ネガティブかを示す数値です。
- -1.0に近いほどネガティブ、1.0に近いほどポジティブということになります。
magnitude
- 値が取り得る範囲:0 ~ +inf
- ポジティブか、ネガティブか関係なく、感情の絶対値的な大きさを示す数値です。
- 感情的な内容がどのくらい含まれているかを表します。
- 正規化されていないため、ドキュメントが長ければ長いほど大きな値になる傾向があります。
scoreとmagnitudeの解釈
ドキュメントがポジティブかネガティブかどうかは、scoreに閾値を設定することで判断します。
例えば、scoreが0.25を超えたらポジティブ、scoreが-0.25を下回ったらネガティブ、というように判定します。
分析するドキュメントの種類によって、適したscoreの閾値は変わるため、テストを行い閾値を調整していくと良いそうです。
また、scoreが0付近の場合、2つのケースが考えられます。
__感情がニュートラル__な場合と、__感情的ではあるもののポジティブとネガティブが同等に含まれている__場合です。
この2つのケースを判別するために、__magnitude__を用います。
scoreが0付近かつ、magnitudeが低い場合は、感情がニュートラル、
scoreが0付近かつ、magnitudeが高い場合は、ポジティブとネガティブが同等に含まれていると判断できます。
商品レビューを感情分析してみる(レビュー収集)
ここからが本題です。
実際に、__analyzeSentiment__メソッドを用いて感情分析を行っていきます。
今回、感情分析してみる対象にしたのは、AmazonなどECサイトによくみられるカスタマーレビューです。カスタマーレビューは、商品やサービスに対する満足したか不満だったかで、ドキュメントに含まれる感情が大きく変化するので、感情分析するにはもってこいだと思います。
しかし、カスタマーレビューを感情分析するだけでは面白くないので、
高評価のレビューにはポジティブな感情が多く含まれ、
低評価のレビューにはネガティブな感情が多く含まれる
のではないかという仮説を立ててみました。
この仮説が正しいかどうかを、レビューを感情分析することでざっくり検証してみようと思います。
検定を行わないので、あくまでもなんちゃって検証です。
分析対象
今回は、iHerbというサプリメントなどを販売しているECサイトのレビューを分析してみます。
iHerbを分析の対象に選んだ理由は、自分がよく使用するサイトだったというだけです。
利用規約を読み込み、スクレイピングして問題なさそうであったため、とあるサプリメント商品の日本語レビューデータを取得しました。
スクレイピング
サーバーに負荷をかけぬように、インターバルを開けながらスクレイピングを行い、カスタマーレビューデータを収集しました。
iHerbのレビューも、5段階評価です。
そこで、評価1のレビューを「reviews1.txt」、
評価2のレビューを「reviews2.txt」にという風に評価ごとに5つのファイルに保存しています。
取得できたレビューの数は、下記になります。
| 評価 | レビュー数 |
|---|---|
| 5 | 164 |
| 4 | 107 |
| 3 | 49 |
| 2 | 9 |
| 1 | 17 |
本当は、もっとたくさんのレビューを用意して分析するべきだとは思うのですが、今回はあくまでもざっくり検証ということで目を瞑ってください!
商品レビューを感情分析してみる(感情分析)
分析方法
レビューを評価ごと、つまり5つのグループに分類し、感情分析を行いましす。
もし仮説が正しいのなら、評価が高いレビューのグループほど、ポジティブと判定されるレビューが多く、scoreも1.0に近づくはずです。
今回、各評価グループごとにレビューが__ポジティブに判定される割合__と__ネガティブに判定される割合__、そして__scoreの平均値__を比較してみます。
Natural Language APIを使うための準備
今回は、pythonのクライアントライブラリを使用します。
インストールやセッティングなどは、リファレンスでしっかり解説されているので、説明を省きます。
感情分析結果を取得
今回は、annotateTextメソッドを使って分析を行いました。
annotateTextメソッドは、一回のリクエストで複数の分析の結果が得られるとても便利なメソッドです。
annotateTextメソッドを用いると、複数種類の分析を一回ずつ行う場合より、リクエスト回数を減らすことができます。
Natural Language APIは、月のリクエスト回数(厳密にはユニット数)で、請求額が変動するので、とても助かるメソッドです。
今回の記事は感情分析しか取り上げませんが、他の分析結果がどのようになっているかを見たかったため、他の分析の結果も取得しています。
from google.cloud import language
from google.cloud.language import enums
from google.cloud.language import types
import pickle
client = language.LanguageServiceClient()
# 行いたい分析を指定する
features = {
"extract_syntax": True,
"extract_entities": True,
"extract_document_sentiment": True,
"extract_entity_sentiment": True,
"classify_text": False
}
# 各評価ごとで分析結果を保存
for i in range(5):
responses = []
input_file = 'reviews{}.txt'.format(i+1)
output_file = 'responces{}.pickle'.format(i+1)
# レビューの読み込み
with open(input_file, 'r') as f:
reviews = [v.rstrip() for v in f.readlines()]
# レビューの分析
for review in reviews:
document = types.Document(
content=review,
type=enums.Document.Type.PLAIN_TEXT
)
# レビューを分析
response = client.annotate_text(document, features)
responses.append(response)
# 分析結果を格納した配列をpickle化して保存
with open(output_file, 'wb') as f:
pickle.dump(responses, f)
グラフ描画
先ほどのプログラムを実行して、それぞれのレビューに対してのscoreとmagnitudeの値が取得できました。
では、取得したscoreの値を用いて、仮説が正しいかを検証してみようと思います。
今回は、2種類のグラフを描画して、各評価ごとで比較することで、仮説が正しいかどうか確認してみます。
グラフ1
各評価ごとのレビューグループのポジティブと判定されたレビューの割合とネガティブと判定されたレビューの割合のグラフ。
レビューがポジティブかネガティブかどうかの判定は、下記の条件で行いました。
ポジティブ:score>0.25
ネガティブ:score<-0.25
各評価ごとで、ポジティブとネガティブの割合を比較します。
グラフ2
各評価ごとのscoreの平均のグラフ。
グラフの描画は、下記のコードで行いました。
import pickle
import matplotlib.pyplot as plt
import numpy as np
pos_height = []
neg_height = []
sentiment_height = []
for i in range(5):
with open('responces{}.pickle'.format(i+1), 'rb') as f:
test = pickle.load(f)
pos_cnt = 0
neg_cnt = 0
sentiment_ave = 0
for t in test:
if t.document_sentiment.score < -0.25:
neg_cnt += 1
elif t.document_sentiment.score > 0.25:
pos_cnt += 1
sentiment_ave += t.document_sentiment.score
sentiment_ave /= len(test)
pos_height.append(pos_cnt/len(test))
neg_height.append(neg_cnt/len(test))
sentiment_height.append(sentiment_ave)
width = 0.3
xticks = np.arange(5)
labels = np.arange(1, 6)
plt.rcParams['axes.axisbelow'] = True
fig = plt.figure()
# ポジティブとネガティブの割合グラフ
ax1 = fig.add_subplot(
211,
xticks=xticks,
ylabel='percentage'
)
ax1.bar(
xticks-width/2,
pos_height,
color='r',
width=width,
align='center',
label='positive (score > 0.25)'
)
ax1.bar(
xticks+width/2,
neg_height,
color='b',
width=width,
align='center',
label='negative (score < -0.25)'
)
ax1.grid(axis='y')
ax1.legend(loc='lower left', bbox_to_anchor=(0, 1))
# scoreグラフ
ax2 = fig.add_subplot(
212,
xticks=xticks,
xlabel='review rate',
ylabel='sentiment score',
xticklabels=labels,
sharex=ax1
)
ax2.bar(xticks, sentiment_height, color='g', width=width, align='center')
ax2.grid(axis='y')
plt.show()
描画結果
グラフは下記のようになりました。
上のグラフはポジティブネガティブ判定されたレビューの割合のグラフ、下のグラフはscoreの平均値のグラフです。
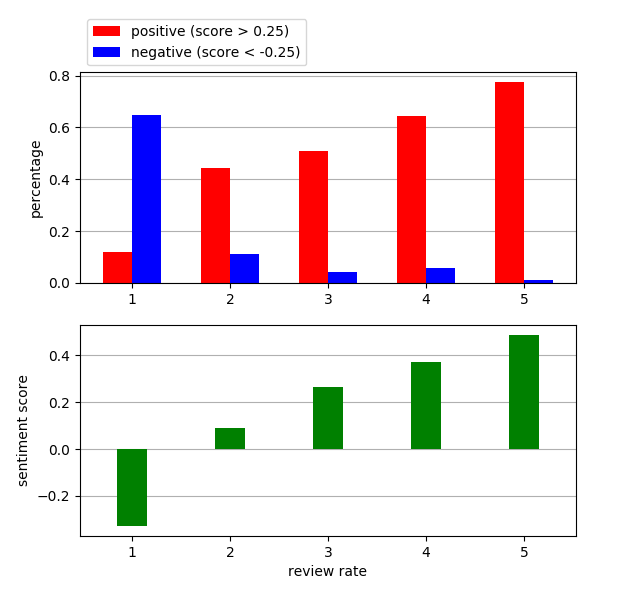
グラフをパッとみたところ、
評価が高いレビューグループほど、
ポジティブと判定されたレビューの割合が高く、
ネガティブと判定されたレビューの割合が低くなっています。
また、評価が高いレビューグループほど、scoreの平均値が高くなっています。
遊びがてらの分析なので、「サンプル数が少ない」、「各評価ごとのサンプル数が異なる」など、分析としては信頼は低いですが、仮説通りの結果が得られて満足です。
終わりに
Natural Language APIでは、Googleのトレーニング済みモデルを用いて分析ができるため、モデルを作成するなどの苦労をせずともそれなりのことができそうです。今回は感情分析だけでしたが、他の分析にも挑戦してみたいですね。
エイチーム引越し侍 / エイチームコネクト Advent Calendar 2019の3日目を担当した@ikuma_hayashiさんも言語解析に関する記事を書いてらっしゃるので、
ぜひ興味がある方は下記リンクへどうぞ!
Docker+Laravel+MeCabで言語解析のWebアプリ環境を構築する
明日の記事
明日のエイチーム引越し侍 / エイチームコネクト Advent Calendar 2019の記事の担当は、@namiitaさんです。
どんな記事か楽しみですね。