はじめに
HDDにはS.M.A.R.Tという自己診断機能があります。
サーバーで使われるSAS形式のHDDにはSATAのHDDで取得している情報の他に温度などもっと細かい情報も持っています。
今回はそこから温度の値を取得してNode_Exporterでデータを取得、PrometheusとGrafanaでグラフを表示してみます。
なんでNode_Exporter?
PrometheusにはPushGatewayなど便利な収集機能などもありますが、今回はNode_Exporterと同一ホスト名で揃えたかったのでNode_Exporterの追加情報として登録しました。
(後のGrafanaの段でホストが違うとめんどくさい)
前提
使用機材
DELL PowerEdge R210II
ちょっと古い
smartmontoolsのインストール
# -yオプションは嫌い、ちゃんと依存関係とか見て使いたい・・・
sudo yum install smartmontools
ServerAdministratorのインストール
DELLのサーバーは管理用にServerAdministratorというツールが提供されています。
参考:Dell OpenManage Server Administrator(OMSA)をyumからインストールする
※同僚の記事です。
後述のディスクIDを使用したいのでインストールしておきます。
というか、ディスク障害検知とかするのに使うのでOS入れたらまずいれるやろ
ディスクの確認
OMSAで取得するディスクIDをラベルに使用したいので、確認しておきます。
[m-kikuchi@manage01 ~]$ omreport storage pdisk controller=0
List of Physical Disks on Controller PERC H200 Adapter (Slot 1)
Controller PERC H200 Adapter (Slot 1)
ID : 0:0 ←ここをラベルで使用するのでメモしておく。
Status : Ok
Name : Physical Disk 0:0
State : Online
Power Status : Not Applicable
Device Name : Not Available
Bus Protocol : SAS ←SATAだと温度は取れない。
Media : HDD
・
・
・
ちなみにディスク障害などでサポートに連絡する場合はこのIDを伝えると早いです。
Node_Exporterの準備
以下のフォルダのデータを収集するように起動オプションで設定しておきます
# ここが欲しい
/opt/prometheus/collector/
# 起動オプション
./node_exporter --collector.textfile.directory=/opt/prometheus/collector
PrometheusとGrafana
こっちはデータソースの登録が適切にされているのを前提で!(投げやり)
コマンドテスト
OSのバージョンやRAIDコントローラーの種類でコマンドが変わるので通るコマンドを探す
# CentOS7や、PERC系はだいたいこっち、sdaやsdbを指定するがどっちでも良かったりダメだったり
# コントローラー依存がありそう、両方で拾えた場合はディスク番号はどちらも共通
# -d megaraid,0 /dev/sda と-d megaraid,0 /dev/sdbは同じディスクの情報が帰ってくる
sudo /usr/sbin/smartctl -a -d megaraid,0 /dev/sda
# CenOS6や、ソフトウェアRAIDだとこっち
sudo /usr/sbin/smartctl -a /dev/sg1
帰ってくる結果は同じだが、sg[1-9]の方はRAIDボリュームだったりCD-ROMドライブだったりするのでしっかり確認すること
コマンド結果は以下の通り
$ sudo /usr/sbin/smartctl -a /dev/sg1
smartctl 5.43 2012-06-30 r3573 [x86_64-linux-2.6.32-358.18.1.el6.x86_64] (local build)
Copyright (C) 2002-12 by Bruce Allen, http://smartmontools.sourceforge.net
Vendor: SEAGATE
Product: ST3600057SS
Revision: ES66
User Capacity: 600,127,266,816 bytes [600 GB]
Logical block size: 512 bytes
Logical Unit id: 0x5000c50068e5c963
Serial number: 6SL6R42F
Device type: disk
Transport protocol: SAS
Local Time is: Tue Jun 27 16:51:20 2017 JST
Device supports SMART and is Enabled
Temperature Warning Disabled or Not Supported
SMART Health Status: OK
Current Drive Temperature: 35 C ←今回はここがほしい
Drive Trip Temperature: 68 C
・
・
・
コマンド
Prometheusは以下の形式でデータを収集します。
smartctlで出てきた値から当該箇所を抜き出してsedで頑張るマン
項目名{ラベル名1="文字列",ラベル名2="文字列"} 値
ワンライナーで頑張る
# /dev/sdaからひろう場合
/usr/sbin/smartctl -a -d megaraid,0 /dev/sda |grep 'Current Drive Temperature'|sed 's/^Current Drive Temperature://g'|sed 's/[ |:|C]//g'|sed 's/^/HDD_Temperature{DiskID="0:1:0",mount="\/dev\/sda"} /g' >/opt/prometheus/collector/hdd_temp.prom
/usr/sbin/smartctl -a -d megaraid,1 /dev/sda |grep 'Current Drive Temperature'|sed 's/^Current Drive Temperature://g'|sed 's/[ |:|C]//g'|sed 's/^/HDD_Temperature{DiskID="0:1:1",mount="\/dev\/sda"} /g' >>/opt/prometheus/collector/hdd_temp.prom
# /dev/sg1からひろう場合
/usr/sbin/smartctl -a /dev/sg1 |grep 'Current Drive Temperature'|sed 's/^Current Drive Temperature://g'|sed 's/[ |:|C]//g'|sed 's/^/HDD_Temperature{DiskID="0:0",mount="\/dev\/sg1"} /g' >/opt/prometheus/collector/hdd_temp.prom
/usr/sbin/smartctl -a /dev/sg2 |grep 'Current Drive Temperature'|sed 's/^Current Drive Temperature://g'|sed 's/[ |:|C]//g'|sed 's/^/HDD_Temperature{DiskID="0:1",mount="\/dev\/sg2"} /g' >>/opt/prometheus/collector/hdd_temp.prom
やってる事
# 対象ドライブの温度の行を取得
/usr/sbin/smartctl -a /dev/sg1 |grep 'Current Drive Temperature' |
# 温度の値だけ欲しいのでそれ以外を消す
sed 's/^Current Drive Temperature://g'|
sed 's/[ |:|C]//g'|
# Prometheusで使用する名前とラベルを行頭に差し込む、DiskIDに最初に調べたドライブのID、mountに取得したポイントを記録した
sed 's/^/HDD_Temperature{DiskID="0:0",mount="\/dev\/sg1"} /g'
# ファイルに書き込む(1行目はファイルを作り直すので>で送る)
>/opt/prometheus/collector/hdd_temp.prom
# 2行目以降は追記なので>>で送る
>>/opt/prometheus/collector/hdd_temp.prom
設定
データ取得用のスクリプトにしておく
# HDDの温度
/usr/sbin/smartctl -a /dev/sg1 |grep 'Current Drive Temperature'|sed 's/^Current Drive Temperature://g'|sed 's/[ |:|C]//g'|sed 's/^/HDD_Temperature{DiskID="0:0",mount="\/dev\/sg1"} /g' >/opt/prometheus/collector/hdd_temp.prom
/usr/sbin/smartctl -a /dev/sg2 |grep 'Current Drive Temperature'|sed 's/^Current Drive Temperature://g'|sed 's/[ |:|C]//g'|sed 's/^/HDD_Temperature{DiskID="0:1",mount="\/dev\/sg2"} /g' >>/opt/prometheus/collector/hdd_temp.prom
追記したら手動で実行してみて値を確認する。
$ cat /opt/prometheus/collector/hdd_temp.prom
HDD_Temperature{DiskID="0:0",mount="/dev/sg1"} 36
HDD_Temperature{DiskID="0:1",mount="/dev/sg2"} 43
Node_Exporterで読める形式で出力されればOK
できたらcrontabに登録しておく、5分置きにでも更新しておけばいいかな。
確認
curlを使ってmetricsにアクセスして、当該行があればOK
Node_Exporterは呼び出された時に各パラメーターを読み込むため、所定の位置に所定のファイルがあれば自動で反映される。
$ curl http://localhost:9100/metrics |grep HDD
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP HDD_Temperature Metric read from /opt/prometheus/collector/hdd_temp.prom
# TYPE HDD_Temperature untyped
HDD_Temperature{DiskID="0:0",mount="/dev/sg1"} 36
HDD_Temperature{DiskID="0:1",mount="/dev/sg2"} 43
100 85996 100 85996 0 0 1594k 0 --:--:-- --:--:-- --:--:-- 1646k
同様にPrometheusも値が増えていたら自動で登録するのでそのまま反映される。

Grafanaさんでがんばる
ダッシュボードをつくってそれっぽくみれるように

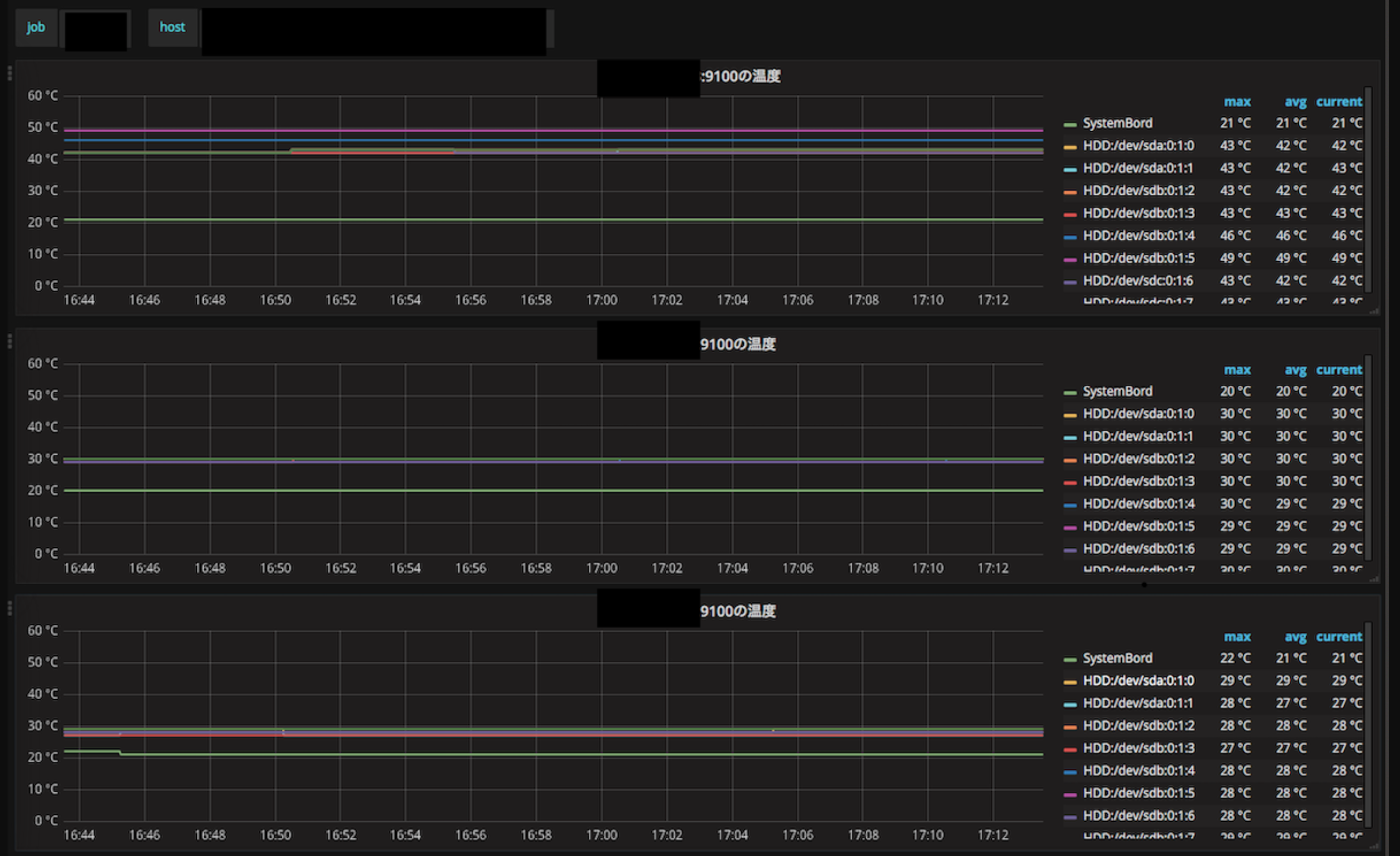

まとめ
本記事はSMART情報をコマンドラインでこねくり回してPrometheusで読める様に整形してあらかじめ設定したNode_Exporterの収集場所におくことにより、値を収集する様にしています。
別にSMARTでもなんでもよいっていう話でした。
おまけ
上の方でOMSAに触れてますので、応用でこんなことも可能です。
# 物理ディスクの正常な数を数えて出力
/opt/dell/srvadmin/bin/omreport storage pdisk controller=0 | grep Status | grep Ok | wc -l |sed 's/^/OmReport_PDisk_Status /g' >/opt/prometheus/collector/pdisk.prom
# 物理ディスクの数を数えて出力
/opt/dell/srvadmin/bin/omreport storage pdisk controller=0 | grep Media | wc -l |sed 's/^/OmReport_PDisk_Num /g' >/opt/prometheus/collector/pdisk_num.prom
StatusがOKなストレージの数と認識している数を出力しておき、以下のアラートルールでディスク障害を検知するみたいなことができます。(むしろこっちの記事をかけ)
ALERT Local_HDDFAILD
IF OmReport_PDisk_Status < OmReport_PDisk_Num
FOR 1m
LABELS {severity="High"}
ANNOTATIONS {description="{{ $labels.instance }} がHDD壊れたみたいですよ", summary="Instance {{ $labels.instance }} HDD-Failed"}
- alert: Local_HDDFAILD
expr: OmReport_PDisk_Status < OmReport_PDisk_Num
for: 1m
labels:
severity: High
annotations:
description: '{{ $labels.instance }} がHDD壊れたみたいですよ'
summary: Instance {{ $labels.instance }} HDD-Failed