Amazon Transcribeが日本語に対応しましたね!
これで日本語の音声をテキストに変換することができますが、一般的でない固有名詞などを認識させたい場合のためにカスタム語彙を試してみました。
カスタム語彙とは
カスタム語彙を作成して、入力ファイルの音声を処理する方法について Amazon Transcribe により詳細な情報を与えることができます。
カスタム語彙は、オーディオ入力で Amazon Transcribe に認識させたい特別な語句のリストです。
これらは通常、Amazon Transcribe が認識しないドメイン固有の語句や適切な名詞です。
カスタム語彙ファイルを作る
カスタム語彙の作成方法はリストとテーブルの2種類がありますが、今回はテーブルを使用して作成してみました。
カスタム語彙に登録する語句は「奈良萬」です。奈良萬は日本酒の銘柄で、「ならまん」と読みます。とっても美味しいので、ぜひ飲んでみてください!
以下の2行をファイルに記載し、custom-vocabulary.txtという名前で保存します。
※保存するときに文字コードをShift-JISにしたらCreate vocabularyが失敗したので、UTF-8で保存し直しました。
Phrase[TAB]IPA[TAB]SoundsLike[TAB]DisplayAs
ならまん[TAB][TAB][TAB]奈良萬
カスタム語彙を登録する
マネジメントコンソールからカスタム語彙を登録します。
事前に上で作成したカスタム語彙のファイルを任意のS3バケットにアップロードしておきます。
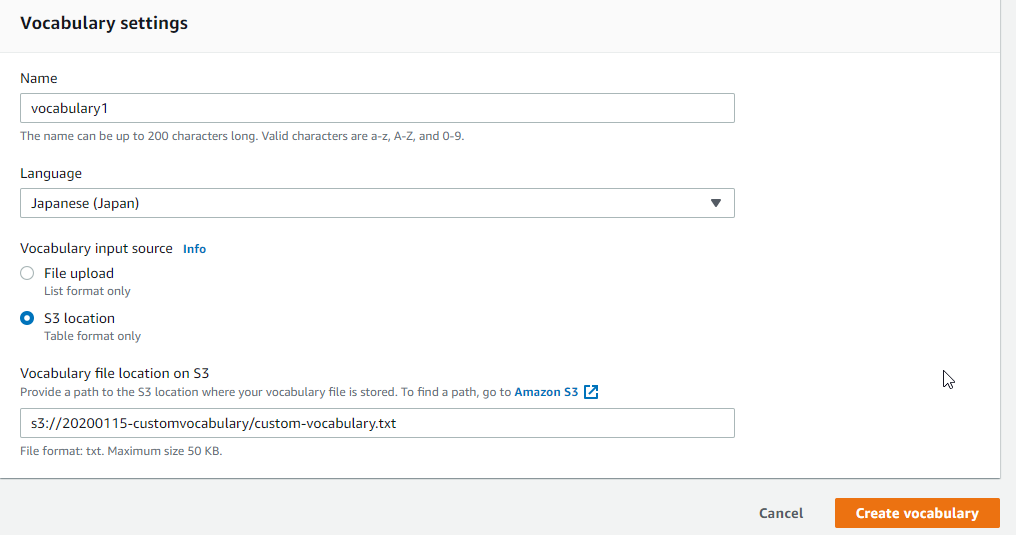
Amazon Transcribe>Custom vocabularyを選択し、Create vocabularyをクリックします。

Nameに任意の名前を入力し、Languageは「Japanese(Japan)」、Vocabulary input sourceは「S3 location」を選択し、Vocabulary file location on S3にはファイルのアップロード先を指定します。
その後、Create vocabularyをクリックします。
ステータスがReadyになったらカスタム語彙登録成功です。

Amazon Pollyでテスト用の音声ファイルを作る
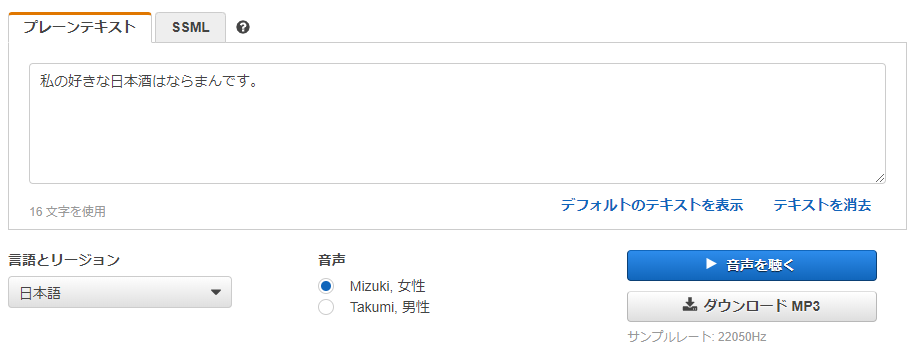
Amazon Pollyでプレーンファイルに「私の好きな日本酒はならまんです。」と入力し、音声ファイルをダウンロードします。
「私の好きな日本酒は奈良萬です。」と入力したところ、「奈良萬」を「ならいちまん」と読み上げてしまったので、銘柄名はひらがなで入力しました。
音声ファイルはカスタム語彙のファイルと同じく任意のS3バケットにアップロードしておきます。
カスタム語彙を使って音声認識させる
Amazon Pollyで作成した音声を認識させます。
ちなみにカスタム語彙を指定しない場合、認識結果は「私 の 好き な 日本 酒 は なら ま ん です」になりました。
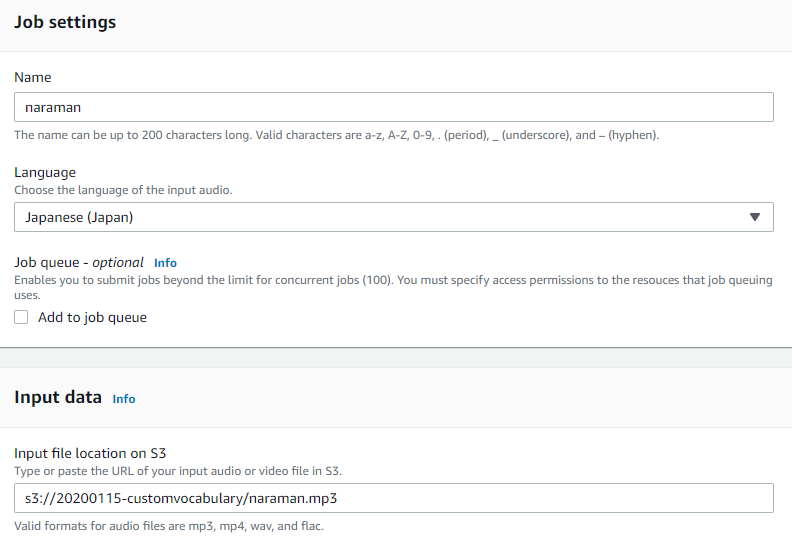
Amazon Transcribe>Transcription jobsを選択し、Create jobsをクリックします。

Nameに任意の名前を入力し、Languageは「Japanese(Japan)」を選択し、Input dataに音声ファイルのアップロード先を指定してNextをクリックします。
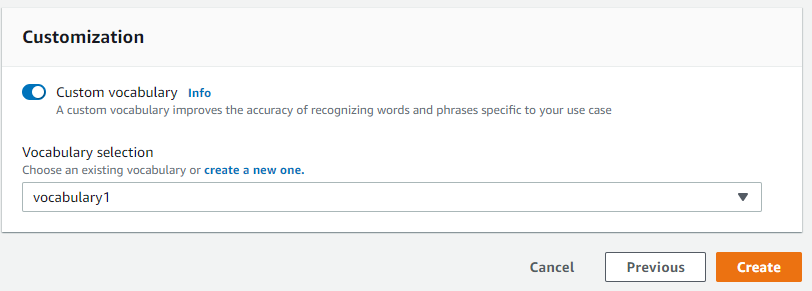
CustomizationのCustom vocabularyをクリックし、先程登録したカスタム語彙を選択してCreateをクリックします。
しばらくするとStatusがCompleteになりました。

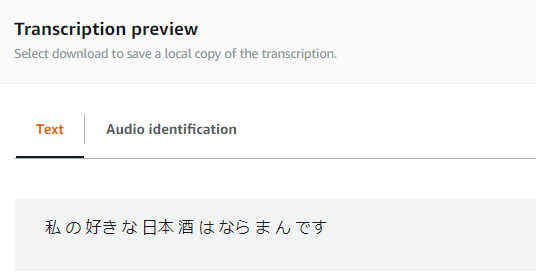
認識結果を見てみると…
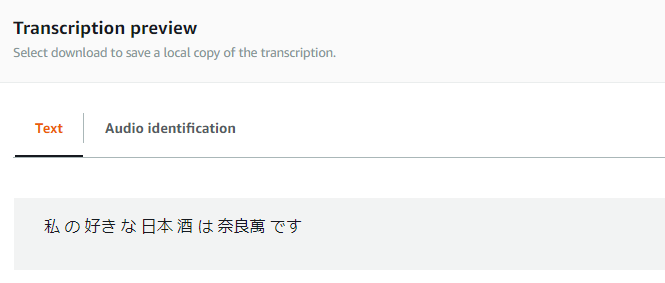
期待通り認識結果が「私 の 好き な 日本 酒 は 奈良萬 です」になっていました!
以上、どなたかのお役に立てれば幸いです。