Azureでシンプルなデータ分析基盤を作る検証をしています。
Azureでデータ分析基盤作ってみた - ①Synapseの構築という記事の続編として、ADFの構築とETL処理について記載します。
構成
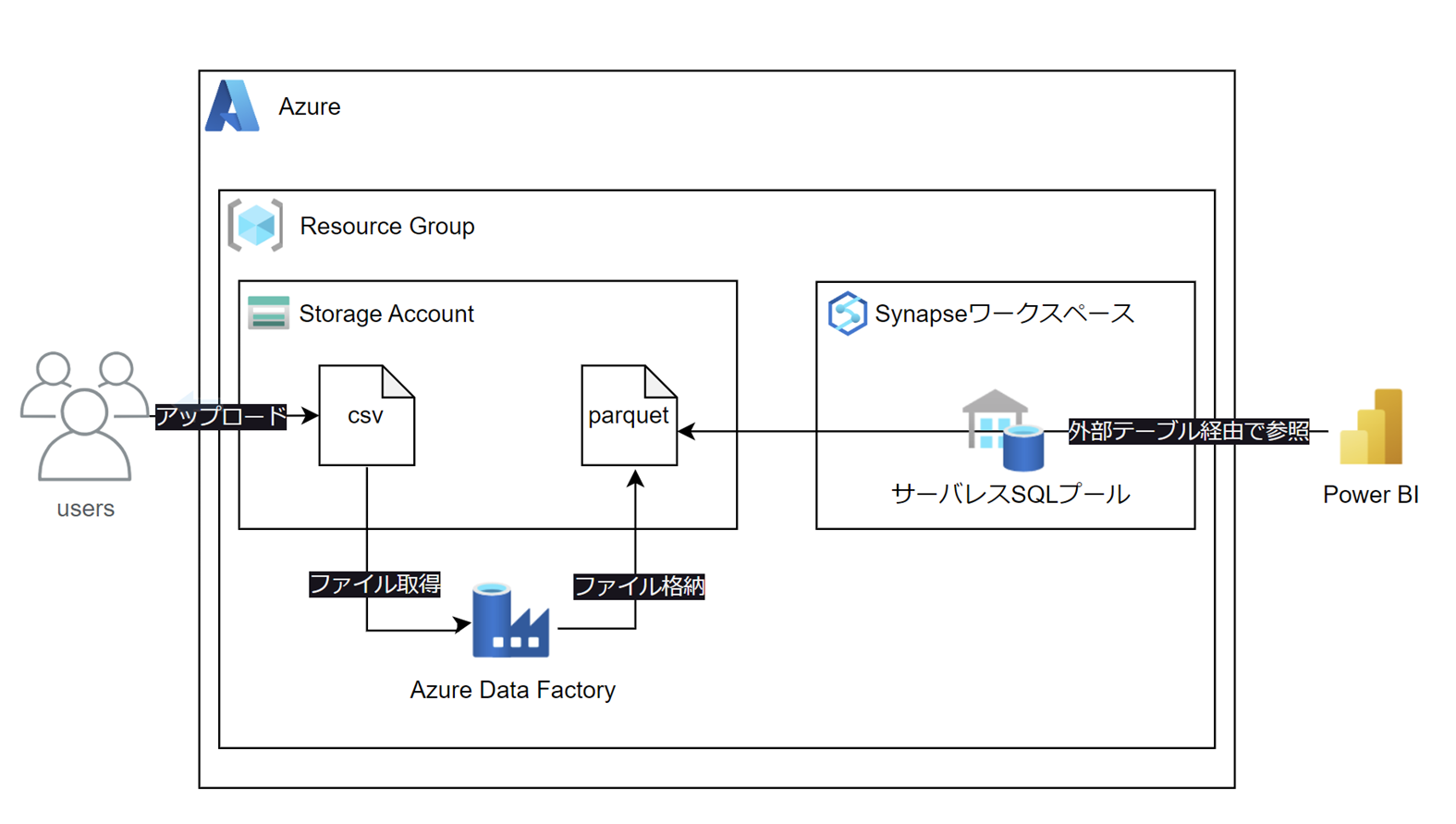
1つのリソースグループの中にストレージアカウント、ADF、Synapseワークスペースを作成します。
ストレージアカウント(ADLS Gen2)に置いたcsvファイルをparquetファイルに変換すると同時に、データ型の変換も行います。
SynapseではサーバーレスSQLプールを使って外部テーブルを作成し、Power BIから外部テーブルを参照できるようにします。
作業内容
以下の順番で作業を行いました。
本記事では「2. ADFの構築とETL処理」について記載します。
1. Synapseの構築
リソースグループ、ストレージアカウント、Synapseワークスペースを構築
2. ADFの構築とETL処理
ADFインスタンスを構築後、ADFでデータ型およびファイル形式の変換(今回はここ)
3. 外部テーブル作成
parqutファイルを参照する外部テーブルをSynapseに作成してPower BIから参照する
今回の構築範囲
ADFインスタンスを構築後、ADFでETL処理をするために必要なコンポーネントの設定をします。
作成するもの
ADFインスタンス
Azure上でデータ統合サービスとして提供される個別の環境のこと。
リンクサービス
Data Factoryが外部リソースに接続するために必要な接続情報を定義するコンポーネント。
今回は事前に作成したストレージアカウントに接続するための情報を定義します。
データセット
データストア内のデータ構造を表すもの。
今回はストレージアカウントに格納したcsvファイルをparquetファイルに変換して保存するため、csvファイル用のデータセットとparquetファイル用データセットの2種類を作成します。
データフロー
データ変換ロジックを作成して管理するもの。
今回はデータ型の変換を行うパイプラインを1つ作成します。
パイプライン
1つの作業単位を実行するための複数のアクティビティから成る論理的なグループ。
今回は先に作成した1つのデータフローを実行するためにパイプラインを使います。
利用するデータ
東京都オープンデータカタログサイトに掲載されている令和6年度認可保育園等一覧(公立・公私連携)というデータを利用します。
赤枠のリンクをクリックするとcsvファイルがダウンロードできるので、構築作業の前にローカルに保存しておきます。

構築作業
csvファイルの格納
前の記事で作成したストレージアカウントのファイルシステム内にinputフォルダとoutputフォルダを作り、inputフォルダに上記のcsvファイルをアップロードします。


ADFインスタンスの構築
Azure Portalの上部の検索窓から「データファクトリ」を検索し、選択します。

データファクトリの画面で「+作成」をクリックします。

基本タブに以下の情報を入力します。
- サブスクリプション:任意のサブスクリプションを選択します
- リソースグループ:前の記事で作成したリソースグループを選択します
- 名前:任意のADFインスタンス名を入力します
- リージョン:任意のリージョンを選択します

Git構成タブ、ネットワークタブ、詳細タブ、タグタブはデフォルトのまま「次へ」をクリックします。
確認と作成タブで設定を確認したら「作成」をクリックしてデプロイが完成するまで待ちます。

デプロイが完了したら作成したADFインスタンスからAzure Data Factory Studioを起動します。
以降「パイプラインの作成と実行」の完了までAzure Data Factory Studioにて作業を行います。

リンクサービスの作成
管理→リンクサービス→+新規をクリックします。

データストアで「Azure Data Lake Storage Gen2」を選択し「続行」をクリックします。

任意のAzureサブスクリプション、前の記事で作成したストレージアカウント名を選択し、「作成」をクリックします。

リンクサービスが作成できました。

csvファイル用データセットの作成
作成者→データセット横の数字→新しいデータセットをクリックします。

「Azure Data Lake Storage Gen2」を選択し「続行」をクリックします。

「DelimitedText」を選択し「続行」をクリックします。

先ほど作成したリンクサービスを選択し、ストレージアカウントに格納したcsvファイルまでのパスを入力します。
スキーマのインポートは「接続またはストアから」を選択します。

エンコードの設定がデフォルトでは既定(UTF-8)になっていますが、csvファイルのエンコードはSHIFT-JISであるため変更します。

スキーマタブでデータのスキーマを確認すると文字化けしていました。。
が、スキーマのインポート→接続またはストアからをクリックすると、文字化けが直りました!
csvファイルに含まれている全てのスキーマが一覧化され、どのスキーマもString型になっていることが確認できました。


parquetファイル用データセットの作成
データストアの選択で「Azure Data Lake Storage Gen2」を選択し「続行」をクリックするところまではcsvファイル用データセットの作成と同じです。
形式の選択では「Parquet」を選択して「続行」をクリックします。

先ほど作成したリンクサービスを選択し、ファイルパスでoutputフォルダまでのパスを入力します。
スキーマのインポートは「接続またはストアから」を選択します。

parquetファイル用データセットが作成できました。

データフローの作成
作成者→データフロー横の数字→新しいデータフローをクリックします。

ソースの追加の横にある「↓」をクリックして「ソースの追加」を選択します。

ソースの設定タブのデータセットで先ほど作成したcsvファイル用のデータセットを選択します。

検査タブで全てのカラムのデータ型がstringになっていることを確認します。

source1の横の「+」をクリックして「派生列」を選択します。

今回は「通し番号」という列のデータ型をint型に変換します。
列で「通し番号」を選択し、「式ビルダーを開く」をクリックします。

「toInteger」と「通し番号」をクリックして「toInteger({通し番号})」という式を作成し、「保存して終了」をクリックします。


元の画面に戻ったら、式に「toInteger({通し番号})」と入力されていることを確認します。

検査タブを開いて通し番号のデータ型がintegerになっていることを確認します。

次にデータの保存先を指定します。
derivedColumn1横の「+」をクリックして「シンク」を選択します。

シンクタブのデータセットで先ほど作成したparquetファイル用のデータセットを選択します。

検査タブで通し番号のデータ型がintegerになっていることを確認できたらデータフローの作成は完了です。

パイプラインの作成と実行
作成者→パイプライン横の数字→新しいパイプラインをクリックします。

先ほど作成したデータフローをパイプラインの画面にドラッグ&ドロップしたらパイプラインは作成完了です。
パイプラインを実行する前に「すべて発行」をクリックします。

これまで作成したパイプライン1つ、データセット2つ、データフロー1つが保留中の変更状態になっていることを確認して、「発行」をクリックします。

発行が完了したら、トリガーの追加→今すぐトリガーをクリックします。
その後パイプライン実行で「OK」をクリックするとパイプラインの実行が始まります。


実行結果は、モニター→パイプライン実行で確認できます。4分ほどで状態が成功になりました。

parquetファイルの確認
ストレージアカウントに作成したoutputフォルダ配下を確認すると、parquetファイルが作成されていました!
次の記事ではSynapseに外部テーブルを作成して、parquetファイルに対してクエリを実行してみます。

まとめ
ADFインスタンスの構築からETL処理までを行いました。
この記事がどなたかのお役に立てば幸いです。