前書き
本記事は他の記事で用いられているような数学Bで学ぶ式を使わず、Pythonで内包表記を使ってニューラルネットワークを実装します。タイトルに「数B未履修でもわかる!」とありますが、これソースは僕です。数Bどころか数II・数IIIも未履修。数A、数Iも一年のブランクがあります。
先に保険をかけておきますが、専門家でも何でもない数B未履修者が3日間頑張ってかみ砕いただけの説明なので間違っているところが多々あるかもです。イメージ位にとどめておくのがよいと思います。
本文
ニューラルネットワークとは?
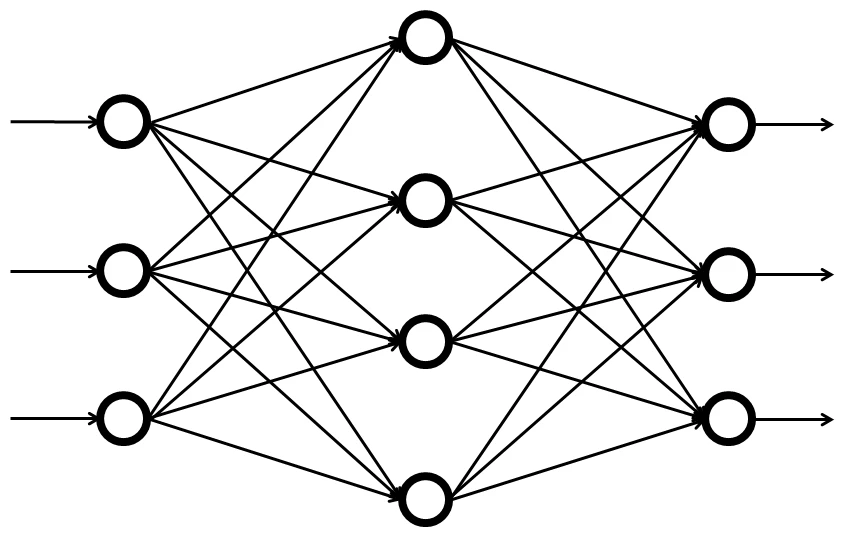
- 列ごとに層という分け方をして、一番左の層を入力層、一番右の層を出力層、その間にある層をそのまま中間層と呼びます。
- 丸で示されているものはノードと呼び、矢印で示されているものは経路と呼びます。
- それぞれの経路には、重みと呼ばれる倍率が設定されており、出力された値に重みがかけられた値が経路に沿って次の層のノードに向けて出力されます。
- 前の層から入力された値とそれぞれのノードに設定されたバイアスと呼ばれる定数との総和が0よりも大きければノードはその総和をそうでなければ0を出力します。
- その作業を指定した回数繰り返します。(上記の図では1回)
- 出力層では、前の層から入力された値とそれぞれのノードに設定されたバイアスと呼ばれる定数との総和が0より大きければ1をそうでなければ0を出力します。
※これは一例です。関数を変更したりして別のニューラルネットワークも作成できます。
ニューラルネットワークによって何ができるか
ニューラルネットワークが上で示した通り、ReLU関数 (xが0よりも大きければxをそうでなければ0を出力する関数)やStep関数(xが0より大きければ1をそうでなければ0を出力する関数)といった関数の集まりであることからもわかるように、ニューラルネットワーク自体を一つの大きな関数ととらえることもできます。例えば、出力層のノードの数を2つに設定し、りんごの何かしらのデータ(画像・咀嚼音...etc)が入力されたときに1つ目のノードから1が出力され、みかんの咀嚼音なら咀嚼音のデータが入力されたときに、2つ目のノードから1が出力される重み・バイアスの値を総当たりなどで見つけ出します。すると、りんごのデータとみかんのデータを区別できるニューラルネットワーク(AI)の完成というわけです。
※知らんけど!!!
ニューラルネットワークとは? 2
前述した「ニューラルネットワークとは?」というセクションをPythonで補足説明していきます。
1. 列ごとに層という分け方をして、一番左の層を入力層、一番右の層を出力層、その間にある層をそのまま中間層と呼びます。
層番号を、入力層に0、中間層に1~n、出力層にn+1と振ります。
入力層のデータは、このような形で変数に入れておきます。data[0]が入力層の1番上のノードのデータ、data[1]が入力層の2番目のノードのデータ。。。となっています。以降、中間層、出力層でもこの形でデータを管理します。
data = [0, 1, 0]
2. 丸で示されているものはノードと呼び、矢印で示されているものは経路と呼びます。
3. それぞれの経路には、重みと呼ばれる倍率が設定されており、出力された値に重みがかけられた値が経路に沿って次の層のノードに向けて出力されます。
今回、重みは-1.0 ~ 1.0の値をとります。
ニューラルネットワークで使う重みの総数は
w = 入力層のノード数 * 中間層のノード数 + 中間層のノード数 * 中間層のノード数 * (中間層の層数 - 1) + 中間層のノード数 * 出力層のノード数
なので、
weightdata = [random.choice(range(-10, 10)) / 10 for i in range(w)]
のように生成できます。
入力層からの出力を計算してみます。
data = [[datum * weight for datum, weight in zip(data, weightdata[開始位置:終了位置])] for node in range(中間層のノード数)]
開始位置、終了位置に関してはnodeを利用して表します。
オフセット = 現在の層番号 * 中間層のノード数
開始位置 = オフセット * 中間層のノード数 + len(data) * node
終了位置 = オフセット * 中間層のノード数 + len(data) * (node + 1)
# len(data) は前の層のノード数を表す
4. 前の層から入力された値とそれぞれのノードに設定されたバイアスと呼ばれる定数との総和が0よりも大きければノードはその総和をそうでなければ0を出力します。
3.の計算を終えた段階では
[[0.2, -0.1, 0.6], [0.3, 0.1, -0.2], [0.0, 0.3, -0.4]]
と2次元配列の形になっているので、これを合計し、バイアスを足します。
今回、バイアスも-1.0 ~ 1.0の値をとり、ニューラルネットワークで使うバイアスの総数は入力層以外のノード数と等しいので、
b = 中間層のノード数 * 中間層の層数 + 出力層のノード数
biasdata = [random.choice(range(-10, 10)) / 10 for i in range(b)]
data = [sum(datum) + biasdata[オフセット + node] for node, datum in enumerate(data)]
後半部分は、要するにこういうことです。
x if x > 0 else 0
5. その処理を指定した回数繰り返します。(上記の図では1回)
例えばこんな風に
for 層番号 in range(中間層の層数):
処理
6. 出力層では、前の層から入力された値とそれぞれのノードに設定されたバイアスとの総和が0より大きければ1をそうでなければ0を出力します。
前半部分は4.と同じですが後半部分が少し違います。
1 if x > 0 else 0
ニューラルネットワークの実際のコード
上で説明したものを組み合わせて、実際にコードを書いてみます。
import random
data = [0, 1, 0]
nodes = 3 #中間層のノード数
layers = 1 #中間層の層数
outputs = 3 #出力層のノード数
weightdata = [random.choice(range(-10, 10)) / 10 for i in range(len(data) * nodes + nodes * nodes * (layers - 1) + nodes * outputs)]
biasdata = [random.choice(range(-10, 10)) / 10 for i in range(nodes * layers + outputs)]
print(weightdata, biasdata)
for layer in range(layers):
offset = layer * nodes
data = [[datum * weight for datum, weight in zip(data, weightdata[offset * nodes + len(data) * node : offset * nodes + len(data) * (node + 1)])] for node in range(nodes)]
data = [sum(datum) + biasdata[offset + node] if sum(datum) + biasdata[offset + node] > 0 else 0 for node, datum in enumerate(data)]
print(data)
offset = layers * nodes
data = [[datum * weight for datum, weight in zip(data, weightdata[offset * nodes + len(data) * node : offset * nodes + len(data) * (node + 1)])] for node in range(outputs)]
data = [1 if sum(datum) + biasdata[offset + node] > 0 else 0 for node, datum in enumerate(data)]
print(data)
ニューラルネットワークの完成です!実行して遊んでみましょう!
学習してみる
「ニューラルネットワークによって何ができるか」で
出力層のノード数を2つに設定し、りんごの何かしらのデータ(画像・咀嚼音...etc)が入力されたときに1つ目のノードから1が出力され、みかんの咀嚼音なら咀嚼音のデータが入力されたときに、2つ目のノードから1が出力される重み・バイアスの値を総当たりなどで見つけ出します。すると、りんごのデータとみかんのデータを区別できるニューラルネットワーク(AI)の完成というわけです。」
と述べましたが、これを実際にやってみたいと思います。りんごのデータとみかんのデータを用いて説明していますが、これらのデータは最初に扱うには少し大きすぎるので、入力層のノード数、出力層のノード数を1つに設定し、XORゲートのような動作をするAIを作ってみたいと思います。
XORゲートとは排他的論理和の論理ゲートである。右に真理値表を挙げる。2入力の場合、入力の片方が1で、かつ、もう片方は0のとき、1を出力する。入力が両方1または両方0のときは、0を出力する。
ということで、ニューラルネットワークが[1, 1]や、[0, 0]に対して[0]を[1, 0]や[0, 1]といった入力に対して[1]を出力するようになる重みやバイアスの値を見つければよさそうです。総当たりでやります。
- ランダムに重み・バイアスの値を生成する。
-
[1, 1],[0, 0],[1, 0],[0, 1]をニューラルネットワークに入力する。 -
[1, 1]や[0, 0]を入力した際に[1]が出力されていたら、ニューラルネットワークの評価を+1、[1, 0]や[0, 1]を入力した際に[0]が出力されていても評価を+1、それ以外の結果になっていたら評価を-1します。 - 1~3までを何回か繰り返し、評価が一番高い重み・バイアスの値を探します。
ということで、実際にコードを書いていきます。
import random
correctdata = [[0, 1], [1, 0]]
incorrectdata = [[1, 1], [0, 0]]
nodes = 2 #中間層のノード数
layers = 1 #中間層の層数
outputs = 1 #出力層のノード数
best = {'evaluation': 0, 'weightdata': [], 'biasdata': []} #評価が一番高い重み・バイアスの値を格納する辞書
for cycle in range(300):
evaluation = 0 #評価値
weightdata = [random.choice(range(-10, 10)) / 10 for i in range(len(correctdata[0]) * nodes + nodes * nodes * (layers - 1) + nodes * outputs)]
biasdata = [random.choice(range(-10, 10)) / 10 for i in range(nodes * layers + outputs)]
for data in correctdata + incorrectdata:
initialdata = data
for layer in range(layers):
offset = layer * nodes
data = [[datum * weight for datum, weight in zip(data, weightdata[offset * nodes + len(data) * node : offset * nodes + len(data) * (node + 1)])] for node in range(nodes)]
data = [sum(datum) + biasdata[offset + node] if sum(datum) + biasdata[offset + node] > 0 else 0 for node, datum in enumerate(data)]
offset = layers * nodes
data = [[datum * weight for datum, weight in zip(data, weightdata[offset * nodes + len(data) * node : offset * nodes + len(data) * (node + 1)])] for node in range(outputs)]
data = [1 if sum(datum) + biasdata[offset + node] > 0 else 0 for node, datum in enumerate(data)]
if initialdata in correctdata and data[0] == 1:
evaluation += 1
elif initialdata in incorrectdata and data[0] == 0:
evaluation += 1
else:
evaluation -= 1
if evaluation > best['evaluation']:
best = {'evaluation': evaluation, 'weightdata': weightdata, 'biasdata': biasdata}
print(best)
はい。超絶簡易的ですが、AIが完成しました。300サイクル回すようになっていますが、これを実行してみると最大のevaluationが2になったり4になったりすると思います。これは、学習が足りていないということです。10000サイクル回すように書き換えてみると安定してevaluationが4になると思います。適当に変数をいじって遊んでみると面白いです。
あとがき
ここまで読んでいただいて本当にありがとうございます。ここまで読んでいただいたのに申し訳ないのですが、本当にこの解釈であっているかどうかハチャメチャに不安です。誰かフィードバックください。。。今回使ったコードはGithubにも上げてあります。