範囲(range)
範囲とは、最大値-最小値で求められる値です。外れ値の影響を大きく受けます。
四分位範囲
データを小さい方から大きい方へ順番に並べて、A%に位置する値をAパーセンタイルと言います。
特にデータを小さい方から大きい方へ順番に並べて4等分した時、最初の1/4の値を第1四分位数Q1(25パーセンタイル)、1/2の値を第2四分位数Q2(50パーセンタイル)、3/4の値を第3四分位数Q3(75パーセンタイル)と言います。
Aパーセンタイル順位=(データの個数+1)\times \frac{A}{100}
Q_1の順位=(データの個数+1)\times \frac{1}{4}
Q_2の順位=(データの個数+1)\times \frac{1}{2}
Q_3の順位=(データの個数+1)\times \frac{3}{4}
- 四分位範囲IQR▶︎Q3-Q1・全データの中央50%を含む
- 四分位偏差QD▶︎(Q3-Q1)/2
四分位偏差は、Q1とQ3が中央値Q2からどれだけ離れているかを示す指標であり、四分位偏差が小さいほどQ2付近にデータが集中しているためデータの散らばりが小さく、四分位偏差が大きいほどQ2付近にデータが集中していないためデータの散らばりが大きいです。
【補足 -四分位偏差の密度とデータの散らばりの比例関係-】
四分位偏差(四分位範囲)が大きいと、箱ひげ図の箱の部分は大きくなります。「Q1とQ3が中央値Q2から大きく離れている」四分位偏差が大きいAの箱ひげ図の方が、箱の密度が小さく、データの散らばりは大きいです。
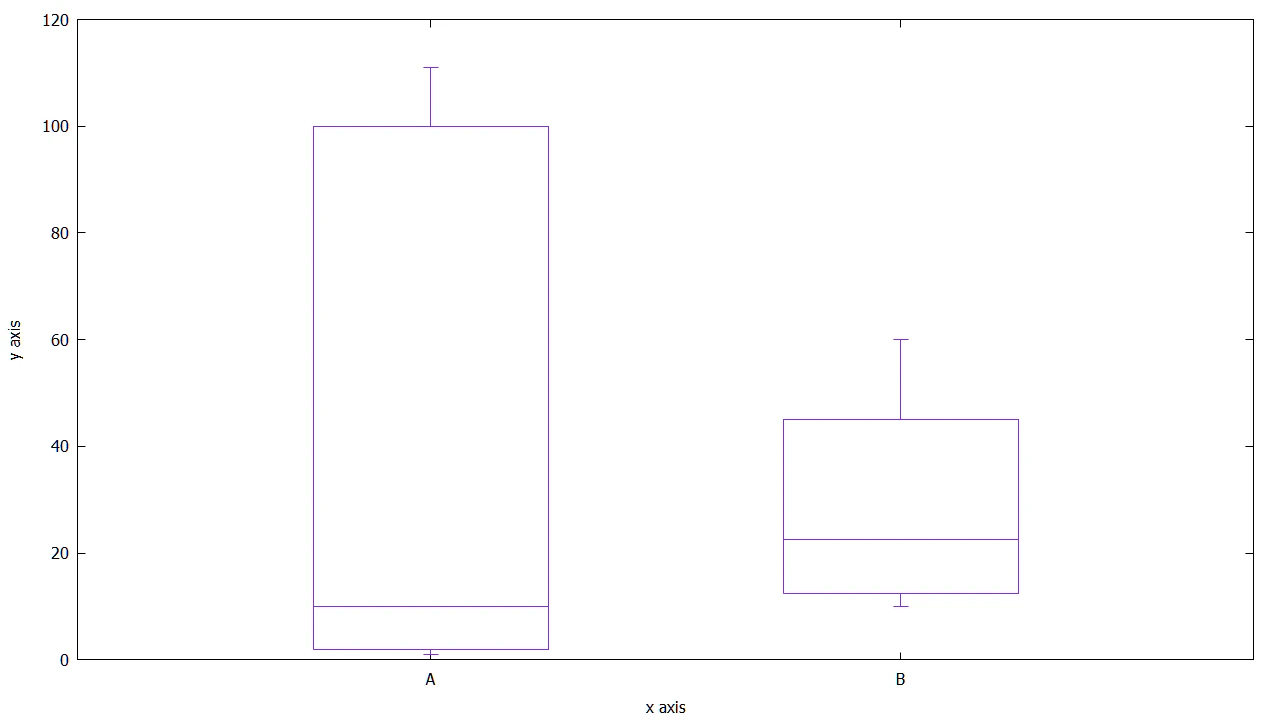
画像引用:gnuplotでヒートマップと箱ひげ図
箱ひげ図
箱ひげ図は、中央値・最小値・最大値・第1四分位数Q1・第3四分位数Q3の5つのデータをグラフで表示し、「データの中心・散らばりの大小・分布の歪み・外れ値の有無」などを示すものです。
- データの中心▶︎中央値の位置で判別
- 散らばりの大小▶︎箱ひげ図全体の長さ・四分位範囲を示す箱自体の長さで判別
- 分布の歪み▶︎箱と最大値・最小値の位置関係で判別
- 外れ値の有無▶︎「Q1-1.5×IQR」をひげの下限、「Q3+1.5×IQR」をひげの上限とした時に、ひげの上下限を超過した値の有無で判別
下の画像のA・B・C・Dの4区間にそれぞれ同じ個数のデータが入っていること、箱であるB-C区間の四分位範囲IQRに全データの50%が入っていること、の2点は注意すべき点です。
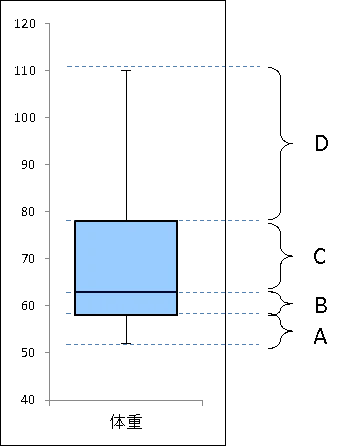
箱ひげ図と外れ値
箱ひげ図では多くの場合、ひげの長さを「四分位範囲IQRの1.5倍」とし、ひげの下限を**「Q1-1.5×IQR」・ひげの上限を「Q3+1.5×IQR」**と設定します。このひげの上限・下限を超過したデータを「外れ値」として扱います。
外れ値が存在する場合は、ひげの上限・下限を超えた部分に◯や×の印で表されます。また外れ値が存在する場合、ひげの下限は「Q1-1.5×IQR」より大きい領域内での最大値、ひげの上限は「Q3+1.5×IQR」より小さい領域内での最小値となります。(上限・下限は、データ全体での最大値・最小値という訳ではない)
平均偏差
平均偏差MDは、偏差の絶対値を取り、その合計をデータの個数nで割ったものです。データの散らばりを調べる上で、標準偏差に比べて平均偏差は数学的に扱いにくく、実際にはあまり使用されていません。
平均偏差=\frac{|x_1-\bar{x}|+|x_2-\bar{x}|+…+|x_n-\bar{x}|}{n}
=\frac{1}{n}\sum_{i=1}^{n} |x_i-\bar{x}|
分散
分散は、データの散らばりの大きさを表す指標で、個々のデータと算術平均の差である偏差を2乗し、それらを合計した値をデータの個数(データの個数から1を引いた値)で割る、つまり偏差平方和をnで割ることによって求められます。
分散はデータを2乗するため、単位は付きません(無名数・無次元数である)。
- 分散が小さいほど、平均に近いデータが多い(データの散らばりが小さい)
- 分散が大きいほど、平均から遠いデータが多い(データの散らばりが大きい)
母分散σ^2=\frac{1}{n} \sum_{i=1}^{n} (x_i-\mu)^2
標本分散s^2=\frac{1}{n} \sum_{i=1}^{n} (x_i-\bar{x})^2
不偏分散
標本から母集団の特性値を推測する「推測統計学」の分野において、標本分散は母分散の推定値にはならない(標本分散 < 母分散)ことが証明されており、偏差平方和をn-1で割る不偏分散が母分散の正しい推定値になるとされています。
不偏分散=\frac{1}{n-1} \sum_{i=1}^{n} (x_i-\bar{x})^2
標本分散と不偏分散は、どちらも標本の分散でありますが、標本分散は**「標本のデータの散らばりを表す」時に使用され、不偏分散は「標本から母集団のデータの散らばりを表す」**時に使用されます。
標準偏差
標準偏差は、分散の正の平方根として求められます。分散は無名数(無次元数)でありますが、標準偏差は元のデータと同じ単位(次元)を持つため、データの散らばりの大きさを評価する際には、扱いやすい標準偏差がよく用いられます。
母標準偏差σ=\sqrt{σ^2}=\sqrt{\frac{1}{n} \sum_{i=1}^{n} (x_i-\mu)^2}
標本標準偏差s=\sqrt{s^2}=\sqrt{\frac{1}{n} \sum_{i=1}^{n} (x_i-\bar{x})^2}
3σのルール
3σのルール(68–95–99.7則)とは、正規分布において、**平均値μを中心に±σ・±2σ・±3σ(平均±標準偏差)**の幅で範囲を取った際に、データがそれぞれ68.27%、95.45%、 99.73%の割合で含まれるという経験則です。

「3σのルール」は、データが正規分布に従わないどのような分布である場合でも、チェビシェフの不等式により μ±2σ の範囲に少なくとも約75%のデータが、μ±3σ の範囲に少なくとも約89%のデータが含まれることが分かっています。
※ チェビシェフの不等式
確率変数Xの平均μ、標準偏差σ、任意の数k(k>0)において以下の不等式が成り立つ。
P(|X-\mu|\geq kσ) \leq \frac{1}{k^2}
変動係数
変動係数CVは、標準偏差σを平均値μで割った値です。
変動係数を用いることで、対象の異なる2つの集団の散らばりの程度を相対的に比較することができます。
変動係数CV=\frac{σ}{\mu}
標準得点
標準得点には、標準化変量z(z得点)と偏差値(Z得点)の2種類が存在します。
標準得点を用いることで、母集団の中における個々のデータの相対的な位置を比較することができます。
標準化変量z
標準化変量z(z得点)は、平均が0・標準偏差が1になるように変換した得点です。
偏差(z-μ)を標準偏差で割ることによって求められます。
z=\frac{x-\mu}{σ}
偏差値
偏差値(Z得点)は、平均が50・標準偏差が10になるように変換した得点です。
偏差値=z×10+50
歪度
歪度は、データの分布の歪み・左右対称性を示す指標です。
歪度=\frac{n}{(n-1)(n-2)}×\sum_{i=1}^{n}(\frac{x-\bar{x}}{s})^3
=\frac{E[(X-\mu)^3]}{σ^3}
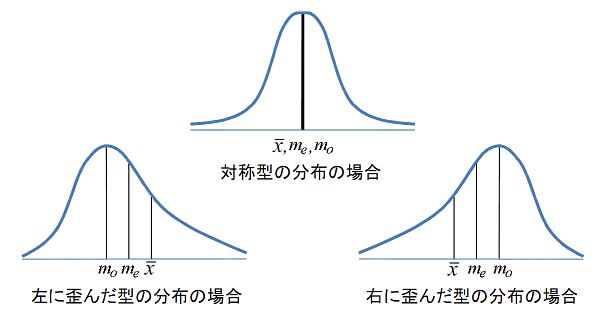
歪度とグラフの分布の関係は以下のようになります。
- 分布が左右対称(正規分布)▶︎歪度 = 0
- 右に裾が長い分布▶︎歪度 > 0
- 左に裾が長い分布▶︎歪度 < 0
尖度
尖度は、データの山の尖り度と裾の広がり度を示す指標です。
正規分布の尖度を0とする定義と、3とする定義があることに注意が必要です。
尖度=\frac{n(n+1)}{(n-1)(n-2)(n-3)}×\sum_{i=1}^{n}(\frac{x_i-\bar{x}}{s})^4-3\frac{(n-1)^2}{(n-2)(n-3)}
=\frac{E[(X-\mu)^4]}{σ^4}-3
この定義式の場合、尖度とグラフの分布の関係は以下のようになります。
- 分布が正規分布▶︎尖度 = 0
- 正規分布より尖っている分布▶︎尖度 > 0
- 正規分布より尖っていない(平らな)分布▶︎尖度 < 0