はじめに
LLMで既存のベクトル化データを使うときの問題点
昨今、RAG(Retrieval-Augmented Generation)などの文脈で「ベクトル検索(Vector Search)」やベクトル化したDB(ChromaDBやOramaなど)が使われている。
しかし、実際にアプリを開発・運用していると、いくつかの「壁」にぶつかることはないだろうか?
特に大きな問題が 「埋め込みモデル(Embedding Model)への依存」 だと思う。
OpenAIの text-embedding-3-small でベクトル化したデータは、当然ながら text-embedding-3-large や、Cohere、Claude、あるいはローカルLLMの埋め込みモデルとは互換性がない。
一度ベクトル化してしまうと、そのデータは「特定のモデル」にロックインされてしまう。
そこで新たに作ってみた、段階的意味指紋法によるDB
リポジトリはこちら。
私は今現在、小説やその他物書きをする方々のために、エディタアプリを作っている。そのアプリでは、ユーザーが自由にAIモデルを切り替えられる機能を実装しようとしている。
「今日はOpenAIで」「明日はコスト節約でローカルLLMで」といった具合に、ユーザーが自由にAIモデルを選んで自分の執筆作業を支援してもらえるようになる。
しかし、既存のベクトル検索のアプローチでは、これが大きな足かせになる。AIモデルを変えるたびに、データベース内のドキュメントをすべて再ベクトル化(Re-indexing)しなければならないからです。これではコストも時間もかかってしまう。
「AIモデルが変わっても、検索用データはそのまま使い回したい」
「APIの課金を気にせず、ローカルでバシバシ検索したい」
「サーバーにデータを送りたくない(プライバシー保護)」
普通に検索するだけなら、別にJavascriptの文字列検索でもいいが、「自然な文章」で検索するとなると、厳しい。
自分のエディタアプリで使っているAIモデルのシステムプロンプトを工夫し、使わせるツールのスキーマ定義で検索キーワードを受け渡してもらっているが、どうしてもキーワードの羅列での検索になってしまう。
AIモデル自身も自然な文章での検索するという思考に至らないらしい。そのためにはツール自身のスキーマ定義を工夫する必要がある。
そういうときにデータ準備の手間となる埋め込み化は、はっきりいって邪魔だと感じたのだ。
こうした思いから、あえて「学習済みモデルを使わない」アプローチである PsfDB (Progressive Semantic Fingerprinting Database) を開発した。
PsfDBの設計思想
PsfDBは、「ニューラルネットワークを使わず、アルゴリズムで意味的近さを測る」 というアプローチを取っている。噛み砕いて説明すると、以下のような特徴となる。
1. 「埋め込み(Embedding)」ではなく「指紋(Fingerprint)」
AIモデルが学習した「意味空間」にマッピングするのではなく、テキストの特徴(文字の並び、単語の頻度、文構造など)をハッシュ関数に通して「指紋」を作る。
これは計算式で決まるため、OpenAIを使おうが、Claudeを使おうが、オフラインだろうが、常に同じテキストからは同じ指紋が生成される。これが「モデル非依存」の正体だ。
正直言って、Claude Sonnet 4.5、Claude Opus 4.6、Gemini Pro 3.0らいくつかのAIに分業してつくってもらったので、コアの部分の意味はわかってない。
埋め込みでモデルを使わなきゃいけないのやだ!まったく新しいの提案して!と言ったらなんか出してきた。
・・・なんだ、段階的意味指紋法って?波紋法?
多分このあたりが関係してくる。 Fingerprint (computing) - Wikipedia
2. 段階的(Progressive)な絞り込み
検索速度を確保するために、4段階のフィルタリングを行っている。
- 超高速: 文字レベルのハッシュでざっくり候補を絞る(100万件→5万件)
- 高速: N-gram(単語の断片)でさらに絞る
- 中速: トピックモデル的なアプローチで意味的に遠いものを排除
- 精密: 文構造などのパターンマッチング
いきなり重い計算をするのではなく、徐々に候補を減らすことで、ブラウザ上でも実用的な速度を実現している。
3. クライアントサイド完結 & オフライン動作
外部APIを一切叩かない。ライブラリ自体も軽量なJavaScriptファイル1つで済むようにしている。
IndexedDB(ブラウザ内蔵DB)にデータを保存するため、インターネットに繋がっていなくても検索が可能です。ユーザーの入力データが勝手に外部サーバーに送られることもない。
もちろん永続化せず、メモリだけで使うことも可能。
導入方法
非常にシンプル。ビルドステップも不要にした。私自身がわかるレベルの使い方じゃないといけないので。
1. ファイルの入手
リポジトリから psfdb.js をダウンロードして、プロジェクトに配置する。
2. 読み込み
HTML (ブラウザ) の場合:
<script src="path/to/psfdb.js"></script>
Node.js の場合:
const PsfDB = require('./psfdb.js');
//---moduleなら
import "./psfdb.js"
使い方
基本的な使い方は、add して search するだけ。
基本的なテキスト検索
// 1. データベースの初期化
const db = new PsfDB('MyDatabase');
await db.initialize();
// 2. データの追加(非同期で指紋生成・保存されます)
await db.add('機械学習は人工知能の一分野です。');
await db.add('Pythonはデータサイエンスで人気があります。');
await db.add('今日の天気は晴れです。');
// 3. 検索
const result = await db.search('AIについて教えて');
// 結果の表示
result.forEach(item => {
console.log(`類似度: ${item.similarity}`);
console.log(`内容: ${item.data}`);
});
JSONデータの検索(構造化データ)
テキストだけでなく、JSONオブジェクトもそのまま放り込める。事前にDBにスキーマ定義を渡す必要もない。特定のフィールドの値や、数値の範囲での検索も可能だ。
await db.add({
id: 1,
name: "高級キーボード",
price: 35000,
category: "ガジェット"
});
// "ガジェット" カテゴリで、かつ "キーボード" っぽいものを探す
const results = await db.search({
text: "打ちやすいやつ", // テキストでの曖昧検索
keyPath: { // フィールド指定での完全一致
path: "category",
value: "ガジェット"
},
numericRange: { // 数値範囲でのフィルタ
path: "price",
max: 40000
}
});
たとえばVimのコマンドリファレンスのCSVをデモ画面に渡して検索してみる。
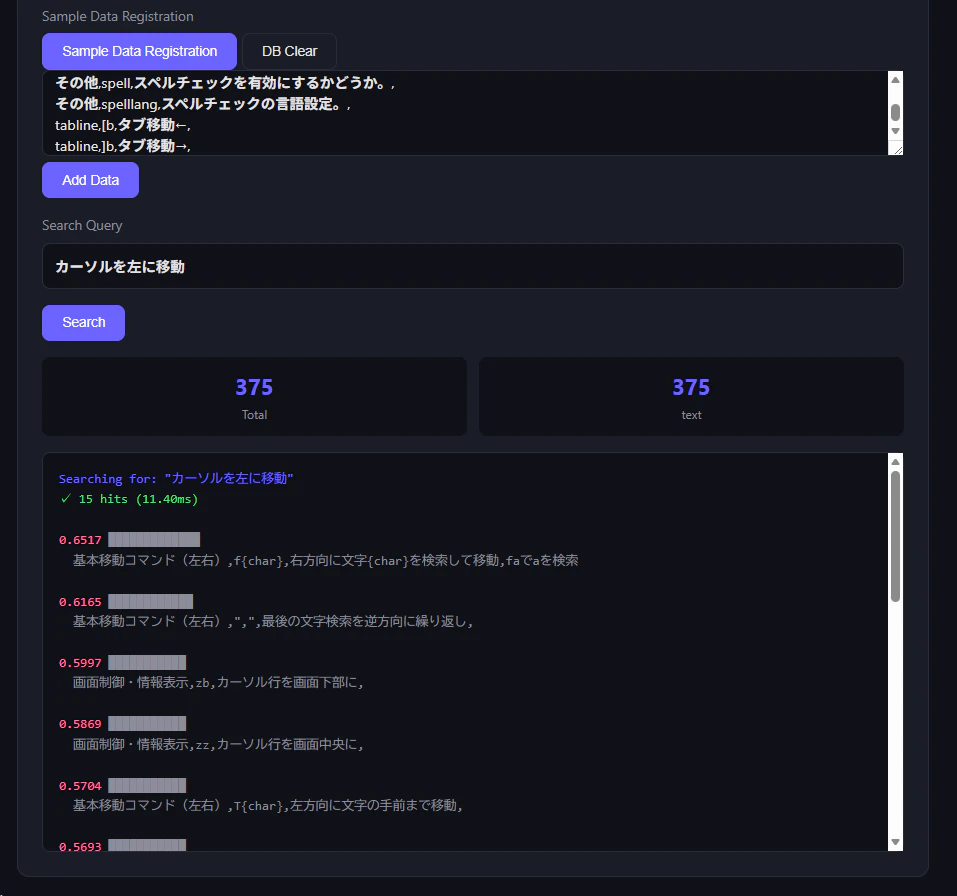
similarityというスコアが大体0.56 以上、さらにいえば 0.7 以上であれば、目的に適った検索ができているとみて良い。
まとめ
PsfDBは、以下のようなユースケースに刺さるライブラリだと思う。
- ローカルLLMアプリ: ユーザーの手元で完結させたい
- プライバシー重視: 検索データを外部に出したくない
- 低コスト: Embedding API代を払いたくない
- モデル切り替え: 将来的に別のAIモデルに乗り換える可能性がある
もちろん、大規模な商用Vector DB、著名なベクターDBと比較すれば、意味理解の深さや数十億規模のスケール性能では劣るはず。しかし、「個人のPCやブラウザの中で、サクサク動く、賢い検索」が欲しい場面では、強力な選択肢になると思う。
ぜひ使ってみて、GitHubにスターやフィードバックをいただけると光栄だ。