会話は作業領域、リポジトリは記憶領域——AIエージェント開発を破綻させないコンテキスト管理術
少し大きめの開発をしていた時のことです。セッションを切り替えずに、一つのチャットセッションのまま何日も開発を強行してしまいました。
その結果、チャット履歴が肥大化して頻繁に Compact(コンテキストの自動圧縮)が発生。数時間前に会話で決定したはずの「認証APIの仕様変更」や「エラーハンドリングの共通設計」が、AIの短期記憶から次々と消え去っていきました。
記憶を失ったAIエージェントは、すでに修正したはずの古いバグをコードに再混入させたり、意図しないリファクタリングで正常に動いていた別機能を破壊し始め、結局半日分の作業が手戻りになるという痛い目を見たのです。
Claude Code、Codex、OpenClawなど、自律的にファイルを読み書きし、コマンドを実行できる「AIエージェント」の登場により、私たちの開発スタイルは劇的に変化しています。
最初は「超有能なジュニアエンジニア」がチームに加わったかのようにサクサクと開発が進みます。しかし、プロジェクトが中〜大規模になり、コードベースが大きくなるにつれて、多くの人が次のような「エージェントの劣化」に直面します。
- 記憶喪失: 「さっき説明した仕様」や「昨日決めた実装方針」をきれいに忘れる。
- 設計のドリフト: 勝手に既存のアーキテクチャを無視したリファクタリングを始め、コードを壊す。
- 思考停止: テストの通し方やビルド方法が分からなくなり、エラーと修正の無限ループに陥る。
なぜこれが起きるのでしょうか?
理由はシンプルです。AIエージェントとのチャットログ(会話コンテキスト)だけに依存して開発を進めているからです。
本記事では、この問題を根本的に解決するための基本思想「会話は作業領域、リポジトリは記憶領域」と、それを具現化した9つのフェーズからなる「AIエージェント向けプロジェクト開発ライフサイクル」を解説します。
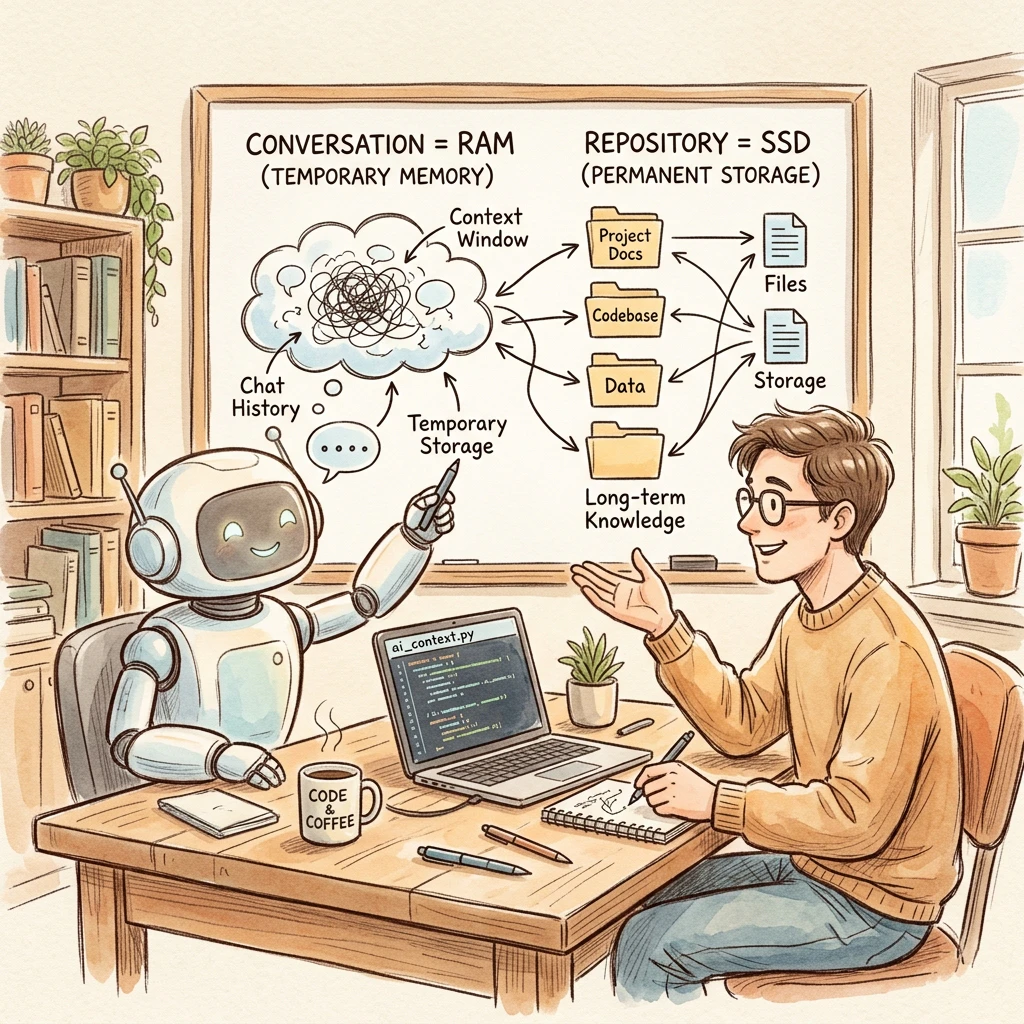
1. コアコンセプト:「会話はメモリ、リポジトリはストレージ」
AIエージェント開発を成功させるためのゴールデンルールは以下の一文に集約されます。
会話は作業領域(RAM)、リポジトリは記憶領域(SSD)
PCで言えば、AIとのチャットスレッド(会話履歴)は一時的な「RAM」です。PCの電源を切ればRAMがクリアされるのと同様に、AIエージェントとのやり取りも以下のようなタイミングで簡単に初期化・リセット(クリア)されます。
- 新しいチャットセッションを開始したとき
- トークン上限に達し、コンテキストが自動で圧縮(Compact)されたとき
- エージェントのプロセスを再起動したとき
これに対し、プロジェクトのリポジトリ(Gitで管理されたコードやMarkdownドキュメント)は「SSD」です。
AIエージェントに「記憶し続けてほしいこと」があるならば、チャットで指示するのではなく、ドキュメントとしてリポジトリに保存し、AI自身にそれを読み書きさせる必要があります。
リポジトリを「唯一の真実のソース(Single Source of Truth)」とし、AIエージェント自身にもそのドキュメントの保守を担当させる。これこそが、中大規模プロジェクトを破綻させずに開発し続けるための鍵です。
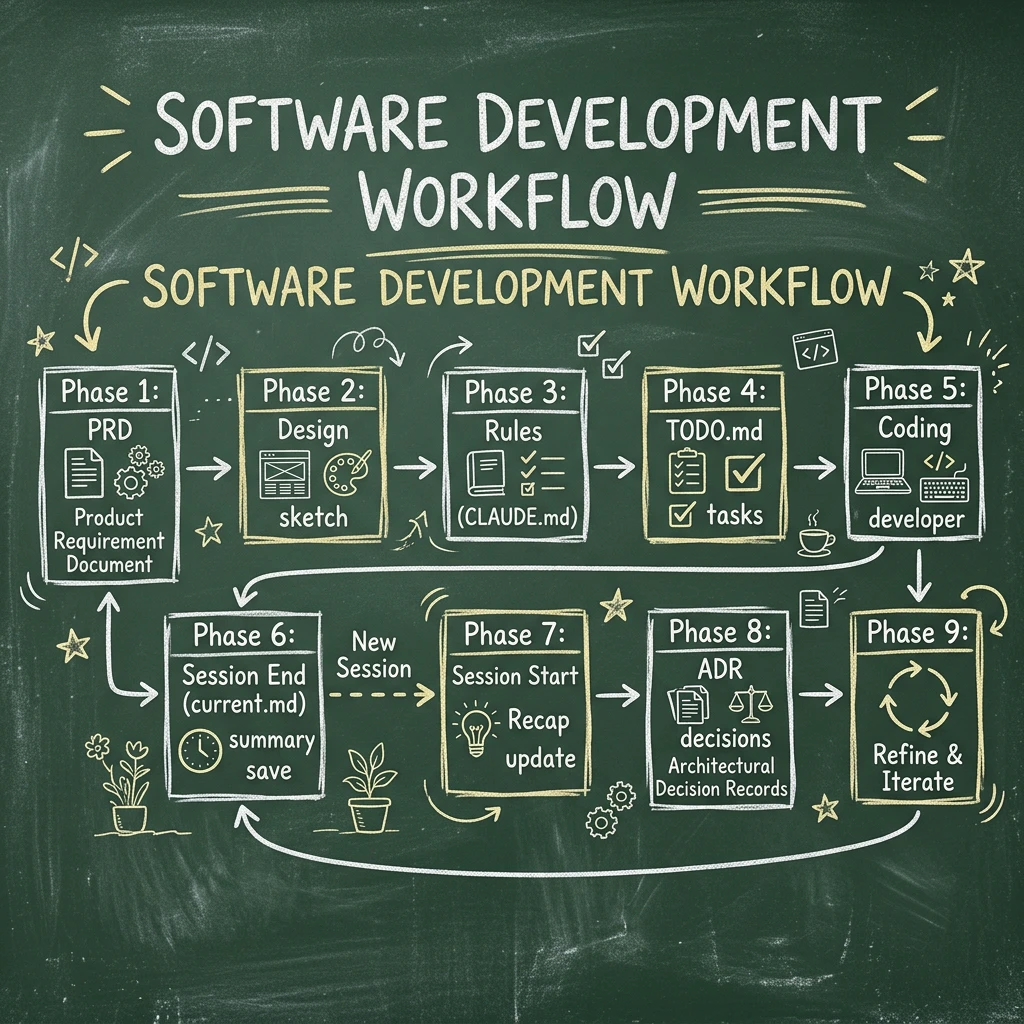
2. AIエージェント開発ライフサイクル(全体像)
ドキュメント駆動でAIと協調開発するためのライフサイクルは、以下の9つのフェーズで構成されます。
3. 各フェーズの詳細とドキュメント設計(テンプレート付)
各フェーズで何を実施し、どのようなドキュメントを整備すべきかを解説します。
Phase 1: 要件定義(コードはまだ書かない)
システムの目的と要求を明確化します。AIエージェントはいきなりコードを書きたがりますが、それを制止して「何を作るべきか」を合意するフェーズです。
- 実施内容: システムの目的整理、ユーザー要求 of 整理、MVPの定義、技術選定、開発ロードマップ策定。
-
成果物:
docs/prd.md(Product Requirement Document)
docs/prd.md の記載項目例
- プロジェクト概要: なぜこのシステムを作るのか
- 対象ユーザー: 誰がどのような状況で使うのか
- 機能要件 (MVP): 必須となる機能一覧
- 非機能要件: パフォーマンス、セキュリティ、スケーラビリティ
- 制約事項: 使用する言語/フレームワーク、外部APIの制約
- 開発マイルストーン: リリースまでの段階的ステップ
Phase 2: 設計ドキュメント作成
要件をシステム構成やデータ構造に落とし込みます。AIが「迷子」にならず、一貫したアーキテクチャでコードを書くための地図になります。
- 実施内容: システム構成図の整理、API設計、ディレクトリ構成の決定、データモデル・DBスキーマ設計。
-
成果物:
docs/ architecture.md (システム全体像、コンポーネント構成) spec.md (詳細仕様) api.md (APIエンドポイント定義、スキーマ) README.md (プロジェクトの起動方法、概要)
Phase 3: CLAUDE.md 作成
AIエージェントがプロジェクトに参画する際の「憲法」を定義します。多くのAIエージェント(特にClaude Codeなど)は、リポジトリ直下の CLAUDE.md を起動時に自動的に読み込みます。
- 目的: AIの振る舞い(エージェントとしての性格)の統一、コーディング規約の共有、ビルドやテストのコマンド定義。
- 注意: 一時的なTODOや作業進捗はここに書かない(静的なルールのみを記載)。
# プロジェクト開発ガイド
## 概要
[プロジェクトの短い説明。例: AIエージェント向けコンテキスト管理ツール]
## 技術スタック
- Frontend: Next.js (App Router), Tailwind CSS
- Backend: NestJS (TypeScript)
- Database: PostgreSQL, Prisma ORM
## 🛠 開発コマンド
- 依存関係のインストール: `npm install`
- 開発サーバー起動: `npm run dev`
- ビルド: `npm run build`
- テスト実行: `npm run test`
- リンター/フォーマッター: `npm run lint` / `npm run format`
## 📐 コーディング規約
- **言語仕様**: TypeScriptを厳格に使用。`any` の使用は原則禁止。
- **アーキテクチャ**: クリーンアーキテクチャに準拠。UIとビジネスロジックを分離すること。
- **エラーハンドリング**: 例外は握り潰さず、エラー境界まで適切に伝播させること。
- **テスト**: ロジックの変更時は、必ず単体テスト(Jest)を更新または新規作成すること。
## 📝 AIエージェントへの特別指示
1. ファイルを変更する前に、必ず現在の設計方針(`docs/architecture.md`)を確認してください。
2. 実装方針に大きな迷いが生じた場合は、独断で進めず、必ずユーザーに質問してください。
3. コードを書き換えた後は、必ず `npm run test` を実行し、デグレーションがないか確認してください。
Phase 4: TODO管理
開発計画をタスクレベルで管理し、AIと人間の共通の「看板」とします。
-
成果物:
TODO.md -
管理方法: Markdownのチェックボックスを使用し、状況(未着手
[ ]、着手中[/]、完了[x])を明示します。
# 開発タスク一覧
## 🚀 MVP (最小限の機能)
- [x] プロジェクト初期化・Prismaセットアップ
- [/] ユーザー認証機能 (Auth0連携)
- [ ] ダッシュボード画面の作成
- [ ] APIエンドポイントの実装 (CRUD)
## 🔮 将来機能 (Future)
- [ ] AIアシスタント機能の追加
- [ ] CSVエクスポート機能
Phase 5: 実装開始(ここからコードを書く)
ここからようやくコードの実装に入ります。
- 原則: 「1セッション = 1機能」を徹底します。一度に多くの機能を実装させようとすると、AIのコンテキストが破綻し、バグの温床になります。
-
プロセス:
- タスクを1つ選ぶ(
TODO.mdを[/]に変更) - 実装コードを書く
- テストを実行し、パスすることを確認
- レビュー(人間による確認)
- Git Commit(意味のある最小単位でコミット)
- タスクを1つ選ぶ(
- 設計変更が発生した場合: チャットで「やっぱりこうしよう」と伝えるのではなく、後述する ADR (Architecture Decision Record) を作成・更新します。
Phase 6: セッション終了(状態の永続化)
開発を中断する際、あるいは1つのまとまった作業を終える際、必ず現在の状況をドキュメントに書き出します。
-
成果物:
sessions/current.md - 記録内容: 何を行い、何が残っており、何が課題か。
セッションを終了してスレッドを切り替える前に、AIにこのファイルを更新させることこそが、コンテキスト圧縮(Compact)による情報喪失を防ぐ最大の防衛策となります。
# セッションサマリー (2026-06-27 16:30)
## 🎯 完了したこと (Done)
- 認証機能のベース実装 (`src/auth/` 配下のコントローラーとサービス作成)
- サインイン、サインアップの単体テスト作成・パス
## ⏳ 仕掛かり中のタスク (Pending)
- サインアウト処理時のセッションクッキーの削除処理(ロジックは書いたが動作未検証)
## ⚠️ 発生した課題・懸念事項 (Issues)
- Auth0のテスト用クライアントIDが未発行のため、現在はモックでテストを実行中。
- 次回セッション開始時に、環境変数 `.env` に設定を追加する必要あり。
## ⏭️ 次回アクション (Next Steps)
1. 環境変数の設定とAuth0の実機接続テスト
2. `TODO.md` の「ユーザー認証機能」を `[x]` に更新する
Phase 7: 次回セッション開始(状態の復元)
開発を再開する(またはAIエージェントを立ち上げ直す)ときは、AIに以下の順番でファイルを読み込ませることで、前回のコンテキストを完全に復元させます。
-
CLAUDE.md(プロジェクトの基本ルール) -
TODO.md(全体の進捗状況) -
sessions/current.md(前回どこまでやったか、次のタスクは何か) - 必要に応じて
docs/architecture.mdやdocs/adr/
💡 AIへの指示例:
「開発を再開します。まずCLAUDE.md、TODO.md、sessions/current.mdを読み込んで現在の状況を理解し、次のアクションについて提案してください。」
Phase 8: 設計変更管理 (ADR)
開発中に発生した設計方針の変更や技術選定の意思決定は、docs/adr/ ディレクトリ配下に「ADR (Architecture Decision Record)」として記録します。
-
命名ルール:
docs/adr/0001-use-prisma.mdのように連番を付与します。 - メリット: AIが「なぜこのようなコードになっているのか」の背景(コンテキスト)を理解し、同じような誤った設計変更を提案するのを防ぎます。
ADR の記載項目例
- ステータス: 提案中 / 承認済み / 却下
- 背景: 解決したい課題や当時の状況
- 採用案: 決定した事項
- 却下案: 検討したものの採用しなかった代替案とその理由
- 影響範囲: この決定によって何が変わるか
Phase 9: 長期運用
プロジェクトが数週間、数ヶ月と続く場合も、このライフサイクルのループを回し続けます。「実装が終わったらドキュメントを更新する」「コミット前にセッションサマリーを更新する」という習慣をAIエージェント自身に徹底させます。
4. 開発を成功させる3つの基本原則
原則1:会話は「記憶」ではない
AIが「わかりました!」と言ったとしても、それは現在のスレッド内だけで有効な一時的な理解です。明日には忘れていると思ってください。必要な情報は必ず「コード」または「ドキュメント」としてリポジトリに保存します。
原則2:プロジェクトが「唯一の真実のソース」であること
AIが参照する情報は、すべてリポジトリ内に完結している状態を目指します。外部のNotionやSlackのやり取りを前提にすると、AIはそれを参照できず、不整合が発生します。
原則3:ドキュメントの保守もAIの仕事にする
人間がすべてのドキュメントを最新に保つのは大変です。AIエージェントに次のルールを課しましょう。
- 「設計を変更するコードを書くなら、まずADRを書くこと」
- 「タスクを完了したら、自律的に
TODO.mdを更新すること」 - 「作業を終える前に、
sessions/current.mdを更新すること」
AIを「言われた通りにコードを書く労働者」ではなく、「プロジェクトのドキュメントとコードの一貫性を自ら守る自律的な同僚」として扱うことで、AIエージェント開発は初めてその真価を発揮します。
5. まとめ
AIエージェントを活用した開発は、従来の「コードを書く作業の効率化」から、「設計と記憶の管理の効率化」へとシフトしています。
「会話は作業領域、リポジトリは記憶領域」という原則を徹底し、ドキュメント主導の開発ライフサイクルを回すことで、中〜大規模なプロジェクトでもAIの力を100%引き出し、安全かつ高速に開発を進めることができるようになります。ぜひ、あなたのプロジェクトでも導入してみてください。