環境
- Windows 10
- Python 3.7.1 (Anaconda3-2018.12-Windows-x86_64)
- PyOCR
- Tesseract-OCR 4.0.0
導入は以下の記事を参考にした。
PythonでOCR
画像整理ツール
個人的に拾い物画像をたくさん保存しているが、数が増えてくると整理が大変。
そこで、画像の中のテキストから、画像整理を支援するツールが作れないかと考えた。
例えば古のFirefoxのスクリーンショット
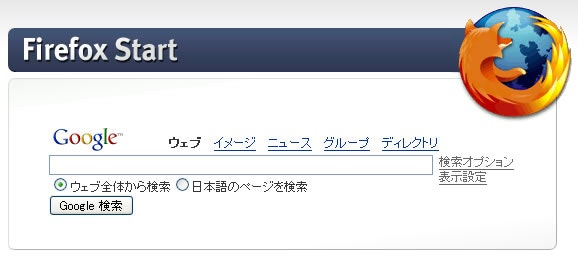
以下、同画像のOCR結果
1
Firefox Start て
Goosle ウェブ イッージ ニュニス グルーブ ディレクトリ
にミヌゴゴゴゴ
⑤ ウェブ全体から検索 〇日本語のページを検索 天
それなりに画像を特徴づける単語は取れている。
ただ、出力される文字列が若干間違っていてゴミ混じりなので、文章などの場合MeCabとかに食わせても全部ちゃんと認識するのか不安な状態
(そもそも自分は自然言語処理自体が専門分野ではないので、MeCab使いこなせそうにないが…)
粗削りな方法だが、OCR結果の文章に登録単語が含まれるかどうかを特徴量にして、適当な分類器で画像を整理するツールを作ってみることにした。
つまり、アプローチ的には画像ファイルが相手といっても(OCR後の汚れた)テキストを対象に分類しているという方が正しいかもしれない。
機械学習は院生時代に少しかじった程度のニワカなので、色々荒いところは勘弁してほしい。
あらかじめ言っておくと、まだこのツールの精度は低い。
今回は対象が画像なので、シンプルな方法をとる。
手持ちの画像の場合、大抵含まれる文字列は長くないので、含まれているその画像を特徴づける単語を持ってくれれば良い。
まず改行区切りの単語ファイルを用意する(これは人力で入れる)
中身は国名、普通名詞、固有名詞などで画像の特徴になりそうなものを手動で適当に選んだものを入れている。
(本当はちゃんとしたコーパスから持ってくるべきかもしれないが、大規模になると色々複合的な問題起きそうで今回は諦めた)
単語・文字ファイルは以下のような内容(約400単語)
東京
京都
大阪
...
コンピュータ
プログラム
データ
ファイル
フォルダ
...
Windows
Office
Google
...
パン
うどん
そば
ソース
タレ
パスタ
...
そして、画像が含んでいるテキストに単語ファイルの単語を含むかどうか表すベクトルを作る。
当然ながら単語ファイルの単語を含まない画像は分類できない
(コードを動かすと分類できるが結果は無意味)
そして、既にフォルダ内にある整理済みの画像で学習し、直下を未知画像として仕分ける方針とした。フォルダ名をラベルとする。
| フォルダ内の画像ファイル (約2600個) | 学習・評価用 |
| 直下にある画像ファイル | 未整理画像 →実用 |
具体的には以下のようにしたい。
例)
| |日本|推移|Google|ラベル(=フォルダ名)|
|:---------------:|:--:|:--:|:--:|:----:|:----------------:|
|統計の画像 | 0 | 1 | 0 |社会|
|世界情勢の画像 | 1 | 0 | 0 |世界|
|Web関連の画像 | 0 | 0 | 1 |ネット|
以下、実際のフォルダの一部の抜粋。(画像を直接出すと著作権的にあれかもしれないので、フォルダ名だけ。)

1. 画像のOCR
OCRはそこそこ時間がかかるのでOCRするコードを分けている。
まず学習用・分類対象画像についてOCRして、データをPickleで保存しておく。
並列化がフォルダごとだったり、雑なつくりなのは容赦。
import pickle
from PIL import Image
import sys
import pyocr
import pyocr.builders
import glob
import os
import numpy as np
from multiprocessing import Pool
import multiprocessing as multi
def ocrimage(file):
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
ocrtext = tool.image_to_string(
Image.open(file),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
return ocrtext
if __name__ == '__main__':
njobs = 1
if multi.cpu_count() > 2:
njobs = multi.cpu_count() - 1
ocrdata1 = []
for p in glob.glob('./**', recursive=False): #ディレクトリとファイル取得
if os.path.isdir(p):
# ディレクトリの場合
filelist = []
for p2 in glob.glob('./'+p+'/*', recursive=False): #ディレクトリとファイル取得
if os.path.isfile(p2):
# ファイルの場合
name, ext = os.path.splitext(p2)
if ".jpg" == ext or ".png" == ext or ".gif" == ext:
filelist.append(p2)
# せめてフォルダー内の画像ごとでの並列化はやる
process = Pool( njobs )
ocrtexts = process.map(ocrimage, filelist)
process.close()
for index, p2 in enumerate(filelist):
ocrtxt = ocrtexts[index]
label = str(p)
filepath = p2
print( filepath )
print( ocrtxt )
ocrdata1.append( [label, filepath, ocrtxt] )
ocrdata2 = []
filelist = []
for p in glob.glob('./**', recursive=False): #直下のディレクトリとファイル取得
if os.path.isfile(p):
# 直下のファイルの場合
name,ext = os.path.splitext(p)
if ".jpg" == ext or ".png" == ext or ".gif" == ext:
filelist.append(p)
process = Pool( njobs )
ocrtexts = process.map(ocrimage, filelist)
process.close()
for index, p in enumerate(filelist):
ocrtxt = ocrtexts[index]
print( p )
print( ocrtxt )
ocrdata2.append( [p, ocrtxt] )
# テキストを保存する
filename = 'ocrdata1.dat'
pickle.dump(ocrdata1, open(filename, 'wb'))
# テキストを保存する
filename = 'ocrdata2.dat'
pickle.dump(ocrdata2, open(filename, 'wb'))
2. 画像の分類
次に、OCRしたテキストからRandomForestを使ってファイルを分類する。
本当は一筆書きの長いコードになってしまったのだが、目的別に分離しておく。
まず、必ず実行する部分のみ記載しておく。
以下のコードで行うことは次の通り。
- 各画像をOCRしたテキストから登録単語が含まれるかをベクトルに変換
- 画像ごとの変換したベクトルを繋げてデータセットを作成。
import pickle
from PIL import Image
import sys
import pyocr
import pyocr.builders
import glob
import os
import shutil
from matplotlib import pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
f = open('word.txt', "r", encoding='utf-8')
wordlist = f.read()
f.close()
words = wordlist.split('\n') # 改行で区切る
print(words)
def text2train(txt):
data = np.zeros(len(words))
for index, word in enumerate(words):
if word in txt: # 単語が含まれる
data[index] = 1
return data
ocrdata1 = pickle.load(open('ocrdata1.dat', 'rb'))
ocrdata2 = pickle.load(open('ocrdata2.dat', 'rb'))
labels = []
train = []
for data in ocrdata1:
txt = data[2]
labels.append( data[0] )
train.append( text2train(txt) )
labels = np.array(labels)
train = np.array(train)
データの偏り・OCR失敗対策
OCR失敗したファイルと、分類に使えるファイルがほとんど入ってないフォルダは学習から除外(uncategorized)にした。
また、不均衡データの対策方法として学習時にデータに重みを与えると良いらしい 1 ので、それを採用した。
# OCR失敗したものを省く
for i,label in enumerate( labels ):
if train[i].sum() == 0:
labels[i] = ".\\uncategorized"
# 散布図の色用 & 不均衡データ対策の計算のため ラベルを数値に変換
labels_unique = np.unique(labels)
label2num = {}
for i, label in enumerate(labels_unique):
label2num[label] = i
col = np.zeros(len(labels))
for i,label in enumerate(labels):
col[i] = label2num[label]
# データ数が10個未満のラベルを省く
for i,p in enumerate(labels_unique):
if (labels == p).sum() < 10:
print("ignore {}".format(p))
labels[labels == p] = ".\\uncategorized"
labels_unique = np.unique(labels) #再更新
# 不均衡データ対策
weights = dict()
for i,p in enumerate(labels_unique):
weights[p] = 1 / ( len(labels[labels == p]) / (len(labels)) )
# 大きさの正規化
for data in train:
dist = np.vectorize(lambda x:x**2)(data).sum()
if dist > 0:
data /= np.sqrt(dist) # 大きさを正規化する
targetdata = []
filepathdata = []
for data in ocrdata2:
filepath = data[0]
filepathdata.append( filepath )
txt = data[1]
targetdata.append(text2train(txt))
分類
RandomForestを使う。
clf_RF = RandomForestClassifier(n_estimators=1000, random_state=0, class_weight=weights)
評価
次に、①学習で使った画像と同じデータセットをそのまま突っ込む場合と、②3分割の交差検証を試行した。
評価用コード
(ちなみに以下のコードだと1個とか2個で画像入れてるフォルダがある場合「データ分割できねえぞ」って怒られる)
model = clf_RF
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import make_scorer
from sklearn.metrics import f1_score
from sklearn.model_selection import cross_validate
def precision_micro(y_true, y_pred): return precision_score(y_true, y_pred, average='micro')
def recall_micro(y_true, y_pred): return recall_score(y_true, y_pred, average='micro')
def f1_micro(y_true, y_pred): return f1_score(y_true, y_pred, average='micro')
cv_results = cross_validate(model.fit(X_train, labels), X_train, labels,
scoring = {'accuracy': 'accuracy',
'precision': make_scorer(precision_micro),
'f1': make_scorer(f1_micro),
'recall': make_scorer(recall_micro)},
cv=3)
print(cv_results)
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X_train, labels, cv=3)
print('Cross-Validation scores: {}'.format(scores))
print('Average score: {}'.format(np.mean(scores)))
出力結果
{'fit_time': array([2.6834538 , 2.62779975, 2.7557683 ]), 'score_time': array([1.08580923, 1.04728389, 1.01936221]), 'test_accuracy': array([0.42834138, 0.45409836, 0.44147157]), 'train_accuracy': array([0.70943709, 0.69729286, 0.71649066]), 'test_precision': array([0.42834138, 0.45409836, 0.44147157]), 'train_precision': array([0.70943709, 0.69729286, 0.71649066]), 'test_f1': array([0.42834138, 0.45409836, 0.44147157]), 'train_f1': array([0.70943709, 0.69729286, 0.71649066]), 'test_recall': array([0.42834138, 0.45409836, 0.44147157]), 'train_recall': array([0.70943709, 0.69729286, 0.71649066])}
Cross-Validation scores: [0.42834138 0.45409836 0.44147157]
Average score: 0.4413037724750721
ここでの結果は44%程度とかなり微妙な感じに。
OCR失敗対策の下処理を終えた後でもOCRに不向きそうな画像が結構あり、もう少しテキストの多いものに絞れば精度上がりそうではある。
実用
数値的な評価だけじゃなくて人間的な納得感の面でも見てみる。
ここで出しても怒られなさそうな無難なやつだけ。
なお、ここで試す画像は当然学習データに含まないものを選ぶ。
スクショじゃないものも選びたかったが、ここで出して良さそうなのがなかなか見つからなかったので仕方なし。
Java

あなたとJAVA,
今すぐダウンロー
OCRの時点でサイズの小さい文字が取れていない。
特徴になる単語がなかったのか「uncategorized」に分類されてしまった。
Googleの検索結果
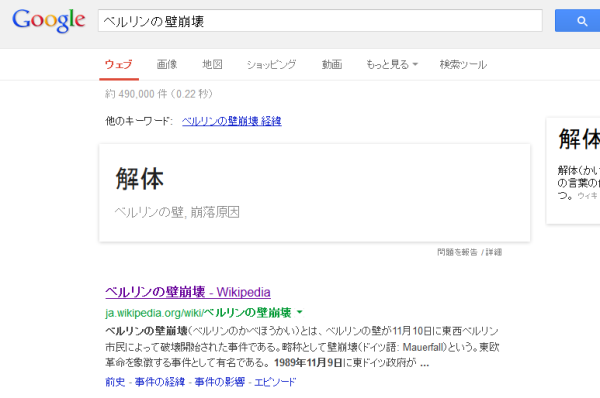
Google ベルリンの生順
ウェブ 画俺 地図 ショッピング 動画 。 もっと見る< 検索ウール
00000條0のめ
他のキーワード。 ペルリンの明夫 解人
解 体 親はかし
の言葉の
うう
ベルリンの革准還
ame
ベルリンの副 - idpeda
評wikipedia_orgwikiベルリンの豆崩壌 ・
ベルリンの加間9りこのかべき2のいをは、べリンの宮が11有OB東大ペリン
市民によって破壊開欠された事件である。時称として壁剛壊ドイッ語- Mauerfal)という。 東欧
人する人として笛でる1969年人月9Hににイ>和が 。
人村人のエピソード
これはなぜか「漫画」に分類された。
学習データの「漫画」のフォルダには「絵柄は漫画だけど様々なジャンルのファイル」を入れていたので、そいつらに影響された可能性がある。
昔のFirefoxのホーム画面
記事序盤に出した画像。
1
Firefox Start て
Goosle ウェブ イッージ ニュニス グルーブ ディレクトリ
にミヌゴゴゴゴ
⑤ ウェブ全体から検索 〇日本語のページを検索 天
これは「コンピュータ」に分類された。
結果としては悪くはない。
ただし、「コンピュータ・ソフト」や「ネット」というフォルダにもブラウザやWeb関連の単語を含んでいる画像を入れていた。
そのため、そっちに分類された方が良かったかもしれない。
JRおでかけネット(JR西日本のサイト)のスクショ
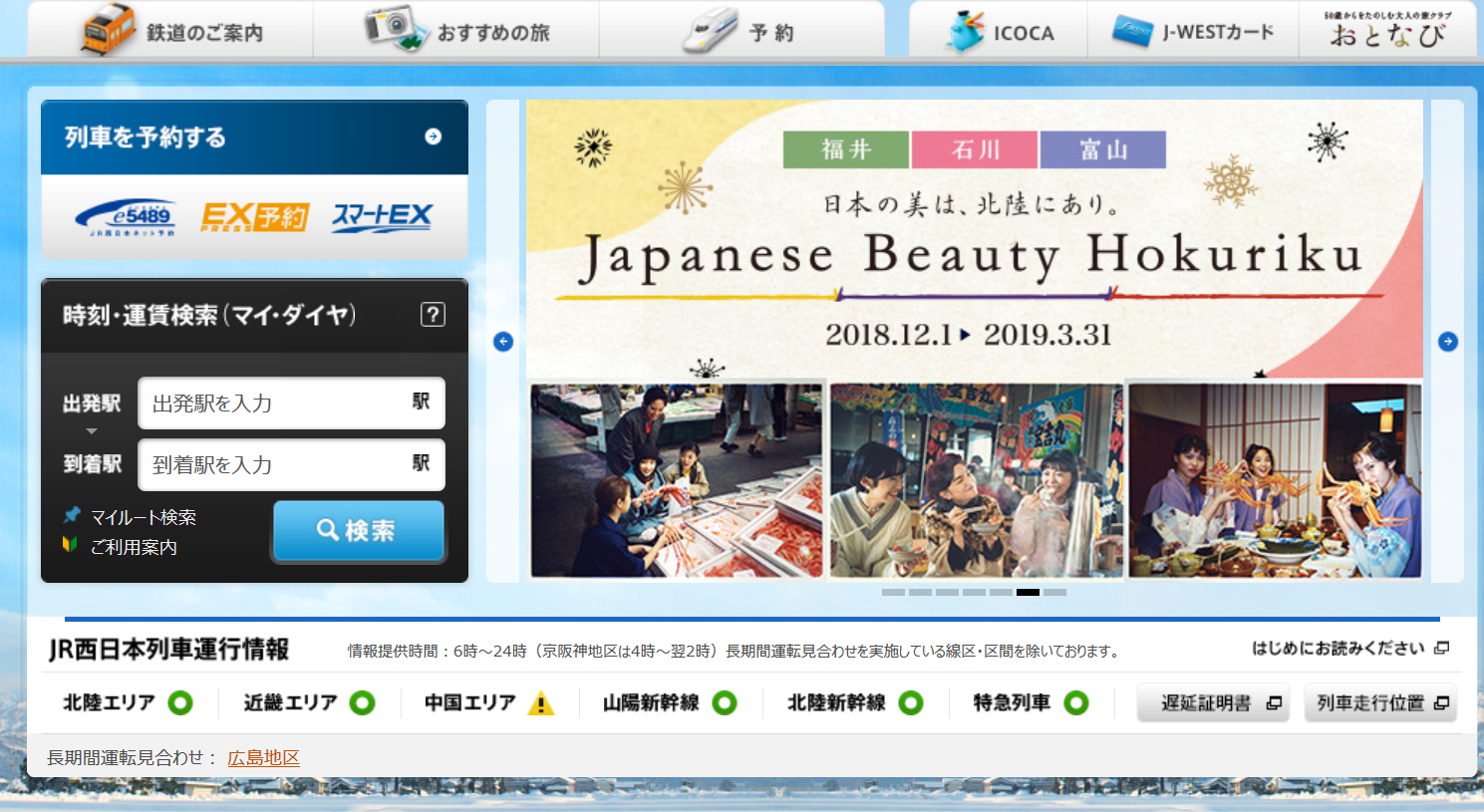
と 鉄道ご案内 1 9 ぉすすゅの放 ーグ oc 編)wesみ-ト おとなび
@ っと 層に 「
2を了する 上本還可 。
ンーsiss ズー/丘 日本の身は、北村にあり。 3
Japanese Beauty Hokuriku 購
ー メーーーーーーーーーーーーーーとーーーーーーーーーーーーーデ議
記・ (マイダイヤ) 較 プー拉
RE 間旨 o 2018.12.1> 2019.3.31 胃 o
ー 補に ま ー
本 "| czcmREH5n
そ細 遇計 中 |
到着 7 M 】 にし 2
ee間 。 の co 電 Nグ3代要 衣 2
ご利用案内 で て 1 人 こまアーミー こす 5
旨遇引 Em SS 還/ や:全WW | 1 革eeデデー、
JR西日本列車運行情報 情報提供時間 : 6時ご24時 (京阪神地区は4時ご伴2時) 長期間運転見合わせを実施している角区・区間を除いております。 はじめにお読みください 避
北陸エリアァ 〇 近畿エリア ① 中国エリア 』m 山陽新幹線 〇 北陸新幹線 〇 特急列車 〇 遅延証明書 品 列車走行位置品
剛 長期間軍転見合わせ : 広島地区 8
mo 人ーーイトー本
これは「鉄道」に分類された。
これは真っ当な結果。
分類はテキストベースなので、直にテキストを放り込んでどうなるかを見ることもできる。
model.predict([text2train("駅 JR 列車 山陽線")])
array(['.\\鉄道'], dtype='<U16')
学習データの質が良くないので単語1つの違いで全然結果が違うこともある。
model.predict([text2train("Windows Linux Mac")])
array(['.\\コンピュータ'], dtype='<U16')
Linuxを入れなかったらデザインになった。
model.predict([text2train("Windows Mac")])
array(['.\\デザイン'], dtype='<U16')
最後にフォルダ分け用コード片
for index, result_label in enumerate(result):
if os.path.isfile( filepathdata[index] ):
print( result_label, filepathdata[index] )
os.makedirs("./autoclf/"+result_label, exist_ok=True)
print( os.path.basename(filepathdata[index]) )
shutil.move(os.path.basename(filepathdata[index]), "./autoclf/"+result_label)
まだまだ微妙だなあと思う点
-
画像内にジャンルに無関係な単語が結構ある(データの問題)
-
画像が特定のフォルダに偏る
- 不均衡なデータなのが原因?(学習ベクトルの重み付けで対策はしたが、まだ不十分)
- OCRに失敗した場合に滅茶苦茶なテキストが出力されるので、そこに登録単語が含まれていた場合引きずられる
- 1文字の漢字だけで入れてる単語とかが引っかかりやすい
-
今回の手法だと、分類する際にデータに同じ単語が必ず含まれている必要がある
- 単語の登録数拡大と、類義語、対義語が集約できれば精度が上がると思うのだが…
-
そもそもフォルダ分けが適当
-
複数の属性を持つ画像がある
- 例えば昔のホビーコンピュータの画像は「ゲーム」に分類すべきか「コンピュータ」に分類すべきか
- Google翻訳の面白い翻訳の画像は「ネット」に分類すべきか「言語」に分類すべきか
- ゲームとアニメのネタがコラボで同一画像の中に混じっている場合は?
- (人間でも悩むのでこれはどうしようもない)
-
複数の属性を持つ画像がある
-
フォルダ名が元々分類を想定していない
- 2018って名前のフォルダに画像を整理せず突っ込んでたりとかするため画像ジャンルとしての意味をなさない
- そもそも、その時その時の感性でフォルダに入れているのでいい加減
-
漫画の吹き出しに多い縦書きが読めない
- (TesseractOCRのインストール時にjpn-vertを入れようとしたけどなぜか404になるので諦めた)
- script/Japanese_vertが手書き用のモデルっぽい?が、OCR結果があまり良くなかった。
-
ロゴや手書きの文字、ポップ体など文章で一般的ではない書体はTesseract OCRではほぼ読み取れない
-
そもそも文字の入ってない画像が結構な割合ある
- 単語ベースで分類したので、ほぼ文字の入ってない未整理画像が大量に残ってしまった…
-
実用重視で作ったため評価がガバガバ→なんとかしたい
-
再現率は??F値は?
- カジュアルにSVM使いたかっただけなので許してくれ…
-
再現率は??F値は?
まとめ
OCR結果に基づく画像整理支援ツールを作った。
全く分類できてないわけではないのだが、体感でも精度はイマイチ。改良の余地はかなりありそう。
作るのより評価の方が大変だった。
研究だったらもう少し詰めないといけない感がある(文章が画像の重要な要素となってる画像群のみで試すとか)けど、個人用ツールなのでまた手作業で色々検証するのはしんどいかな。
何か改良案あれば教えてほしい。
研究とかではないので続くかは…未定。
今後やりたいこと
-
手動で単語リスト作るのは微妙なので、単語リストを自動作成したい。また、ちゃんとしたコーパスから抽出したものを使いたい
- 汎用のコーパスを使うと、今の方法だと雑過ぎて一般的すぎる単語が邪魔してきそうな感もあるが…(TF-IDFが関係する話か?)
-
学習データに画像だけではなくジャンルごとに分けた文章ファイルも追加するとか
- 画像だけで学習させるのはだいぶ横着
- 別途、文章ファイルの頻出単語みたいなもの抽出した方がデータ量も確保できそうだし、ちゃんと学習しそう
- ジャンルごとに登録単語を入れておいてルールベース的な手法の補完みたいな手法?(単語登録がしんどそうだけど)。
-
(微妙な点にも書いたが)word2vecを使えば類義語対義語が近くに出てくるはずなので、類似度を使うアプローチというのもありかもしれない
- ある単語に類似度が高い単語を含んでたら、その単語含んでることにするとか
-
本当は画像って複数の属性を持ちうるものなので、フォルダという1つの属性に縛るのは良くない気もしている
- 階層的クラスタリングなるものが中間処理に使えないか気になっている
-
前は画像の整理にFenrirFSを使っていたが、データベースから中身のタグを引っ張ってきたりすればもっと良くなりそう?
-
画像を直接使ってChainerとかTensorFlowとかで分類するアプローチと組み合わせるのも面白そう
- ただ、画像が含んでいる物体ごとの詳細なラベル付けとかはしんどそう
- 深層学習フレームワークの導入なんも分からん…
-
比較的シンプルな方法で言えば、平均色とかRGBそれぞれについて空間周波数とかの特徴量取ってきて分類に使うことで、画像の質感的なものを頼りにできるかも
- →写真(風景、食べ物など)、ゲーム画面、アニメ、マンガ、スクショぐらいの区別はつきそう?
-
Google ColaboratoryのOCRの方が精度高いみたいなのでそっち使いたいが大量の画像処理しても良いのか謎
その他
-
最初はかな、アルファベット、JIS第一水準漢字を1文字ずつ単語帳に含んでいたのだが、無関係な文字にひきずられて過学習してしまったのでやめた。
- これをやることで、単語が未登録だった場合でも、"JAXA"という文字列がある画像なら、「A,J,Xを含んでいる→宇宙関連」という形で学習に影響してくれれば全く分類されないよりはマシになる…と考えていた。
- また、OCRにゴミが混じった場合でも何かしら反映してくれるため対策になるはず。
- 実際、分類精度は高まったのだが、無関係な文字列に機敏に影響される分類器になってしまった(OCR失敗時のゴミ文字を拾うため)。
-
最初はSVM使ってグリッドサーチとかしてたがRandomForestに書き換えた
- (とある人にその方が良いとアドバイス受けたのと、BoW的な特徴量の場合その方が向いているという記事2 があったため)
-
最初は主成分分析かけてたけどそんなに意味なかったのでやめた