前書き
自分は別にプログラマではなかったのです。プログラミング経験と言えば中学校の時一時期 BASIC を少し独学して、大学でプログラミング入門の授業で C を少しだけ触って、あとはまあ4年生の時の卒業研究でそれなりに CUDA プログラムを組んだ程度。あとは就職してからディレクターをやりながらも少しくらい(主に UI 周り)既存の Objective-C のソースコードの修正をやった程度です。
そんな僕が会社の都合もあってプログラマにジョブチェンジさせられ、ちょうど Apple も新たに Swift という言語を世に送り出したからこれならまあまあ簡単そうっと思いながら少しずつプログラムを組み始めました。
そしておおよそ1年くらい経ちましたし、そろそろ今までの経験をまとめてみたいと思っております。この記事では Swift の文法についても話しますし、もう少しでっかい規模のデザインパターンなどの話も少し話しますので長文になってしまいますが、誰かの役に立てるなら嬉しいです。
そしてもちろんですがこの記事で書いたことは全て「正しい」とか全て「最善」という保証はありません。タイトルで記載した通り自分はあくまで初心者です。ですのでもし内容について何かご意見やご感想があれば是非教えていただけると幸いでございます。
とりあえず感想
それなりの向上心さえ持っていれば毎日毎日コード書いていくとプログラミングスキルはすっごい早いペースで向上します。これはガチ。ソースは俺。ぶっちゃけ、自分が1ヶ月前どころか、1週間前に書いたソースコードでさえ1週間後に読み直すと「うっわーなにこのクソコード」ってなります。それだけではない、「くそだ」と思う部分のカテゴリもだんだん変わってきます。最初は「なんでそこで Forced Unwrapping するんだそこは Optional Binding でやったほうがいいだろ」とか、徐々に「なんでこんな冗長なコード書くんだそこはもう少しエレガントに書けるだろ」とか、少し前なら「なんでそれをデフォのまま internal にしてるんだそこは private のほうがいいだろ」とか、一番最近なら「なんでこのオブジェクトにそのオブジェクトを持たせてるんだそこは delegate でいいだろ」とかのように、本当に少しずつとよりハイレベルな「クソさ」が気づけるようになるなぁと実感しております。ですので大事なことなのでもう一度言います。それなりの向上心さえ持っていれば毎日毎日コード書いていくとプログラミングスキルはすっごい早いペースで向上します。
Optional 型との付き合い方
Swift の最大の特徴とでも言える Optional 型。初心者はもちろん、他の言語のエキスパートでさえその言語に Optional 型がなければ最初は戸惑う部分ではないかと思います。ところがこの Optional 型慣れてきたら、本当にすごいエレガントなコードで高い安全性を保証できるなぁと実感します。
Optional 型についての解説は Qiita でも Google でも探せばごまんとあるのでここで細かい解説を割愛しますが、二つ重要なこと、「String と String?(本当に正しく書くと Optional<String> になるが)は完全に違う二つの型」と、「Swift では nil 自体が一つの値だ」ということを常に念頭に置いたほうがいいでしょう。この2つさえ理解していれば Swift での Optional 型の扱い方が理解しやすくなると思います。
ではコード上に Optional 型について何を注意しなければいけないのかというと、極力に Forced Unwrapping を避けるようにすることが一番重要ではないかと思います。もちろん全く使わないわけではないが、せっかく Swift が仕様レベルで nil によるランタイムエラーをほぼ撲滅してくれているのに(多分唯一ランタイムでの nil エラーはおそらく配列の範囲外アクセスではないかと思います)それを積極的に圧し折るのはプログラマとして失格だと思います。でももちろん毎回毎回型検査から仕事を始めるのはコードも長くなるし馬鹿じゃないのと思われるので、じゃあどうすればいいのかというと、Optional Binding や Optional Chaning を駆使してエレガントなコードを書くことですね。
例えばの話、下記のコードがあるとします:
let object = NSUserDefaults.standardUserDefaults().objectForKey("user data")
var data = object as? [String: Int]
var hp = data?["hp"]
//////いろいろ処理//////
if hp != nil {
hp = hp! + 2
data!["hp"] = hp!
} else {
hp = 2
data = ["hp": 2]
}
NSUserDefaults.standardUserDefaults().setObject(data, forKey: "user data")
まあこれだけならまだしも、プログラムの中でこういうコードが溢れてたら正直うっとうしいですよね。data も hp も最初からどうせこれ nil はプログラム設計としてありえないからいちいち nil 確認したくない、というわけでこのように直してみました:
let object = NSUserDefaults.standardUserDefaults().objectForKey("user data")
var data: [String: Int]! = object as? [String: Int]
if data == nil {
data = ["hp": 0]
}
var hp: Int! = data["hp"]
//////いろいろ処理//////
hp = hp + 2
data["hp"] = hp
NSUserDefaults.standardUserDefaults().setObject(data, forKey: "user data")
これでしたらまあ少しはスッキリしましたね。宣言部がちょっと長くなりましたが処理部は nil チェックをせずに済むので元々8行が必要なところが一気に3行に減りました。しかしこれではまだ十分によろしくない。宣言部が長いのもありますが、そもそも data も hp もまだ Optional 型のままだというのは非常に頂けない。というわけでさらに下記のように改良します:
let object = NSUserDefaults.standardUserDefaults().objectForKey("user data")
var data = object as? [String: Int] ?? [String: Int]()
var hp = data["hp"] ?? 0
//////いろいろ処理//////
hp = hp + 2
data["hp"] = hp
NSUserDefaults.standardUserDefaults().setObject(data, forKey: "user data")
これでコードが一気にスッキリしましたね。宣言部は最初と同じ3行のままで処理部も同じく3行で終わるし、何より一番いいのは一時的にしか使われてない object 以外は全て非 Optional 型になるので、Forced Unwrapping も発生しないから nil によるランタイムエラーも発生しない。ここのトリックは全ての変数に ?? で取得失敗時のデフォルト値を与えているところです。
これは最初から nil 型がありえないから Optional 型を使わないようにした例ですが、逆にじゃあ nil がありうる場合、Optional 型を使わなければならない場合はどうすればいいのかというと、じゃあ同じく上記の例で、今度は宣言部を最初のまま処理部だけ Optional 型のままで処理してみましょう:
let object = NSUserDefaults.standardUserDefaults().objectForKey("user data")
var data = object as? [String: Int]
var hp = data?["hp"]
//////いろいろ処理//////
if var data = data, hp = hp {
hp += 2
data["hp"] = hp
} else {
let defaultHP = 2
hp = defaultHP
data = ["hp": defaultHP]
}
NSUserDefaults.standardUserDefaults().setObject(data, forKey: "user data")
とこんな風に、ソースコードの長さは仕方なくむしろ1行増えましたが、Optional Binding(if var の部分)のおかげで Forced Unwrapping がなくなりました。
ところがここで一つ、上記では「極力に Forced Unwrapping を避けるようにする」と書きましたが、「絶対に Forced Unwrapping を使わない」とは言ってません。ではどういう場合に使うかというと、Xcode のサンプルコードなどもありますが、@IBOutlet 要素は全て「暗黙的 Forced Unwrapping Optional 型」です。なぜこうなっているかというと、UIViewController などのオブジェクトはなるべく生成時の負担をかけたくないため、生成時ではなく生成後にこれらの要素を作っているからです。すなわち利用時にはこれらの要素は必ずありますが、生成時はこれらを生成しないため Optional 型を使っています。同様に UIViewController オブジェクトの view 要素も同じです。これも念頭に置いておけば、以後 UIViewController や UIView のサブクラスを自作する時に役に立つと思います。
そして実際の製品には使わないほうがいいでしょうが、逆にとりあえず素早く何かしらの動作・アルゴリズムの確認だけ Playground で確認したい、という場合も、むしろランタイムエラーがあってなんぼだしいちいち nil 確認してられないから積極的に Forced Unwrapping を使っても全く問題ないです。
Closure、大事。とても大事
こちらは Swift の特徴ではなく、他の言語でしたら、例えば Java ならラムダ式というのがあってこれもまさに Closure と同じようなものですが、でも初心者にとってはこれはかなり(Optional 型以上に)難しく感じるものではないでしょうか。でも信じてください、これを身につけたらいろんなものが魔法のように実現しやすくなるのです。
Closure を一言で言うと「関数を変数として扱える」ということです。でもこれが一体何の役に立つのか?という質問が理解できてないと、やはり初心者ならただでさえなんか難しいようで敬遠してしまいます。関数を変数として扱えるということの何が嬉しいかというと、やはり一番嬉しいのは関数の引数として関数が使えるということでしょう。
例えばとある変数 result があるとしてます。ところがこの変数の値がどうやって計算するのかは定かではありません。例えばユーザの何かしらの動作により、足し算をやるかもしれないし掛け算をやるかもしれない。こういった時は通常の変数引数で result 変数を算出する関数が作れません。ところが、関数が引数として使えるなら、関数をこの算出関数に渡すことができるので、計算ができちゃいます。では具体的にコードで見てみましょう:
var result = 0.0
var a = 0.0
var b = 0.0
func calculate(function: () -> Double) {
print(result)
result = function()
print(result)
}
a = 1
b = 2
calculate({ a + b })
result
a = 3
b = 4
calculate({ a * b })
result
a = 5
b = 0
calculate({ () -> Double in
if b == 0 {
return 0
} else {
return a / b
}
})
result
こちら Playground で実行するコードですが、とりあえず結果の result、引数の a と b があって、さらに計算式として func calculate(function: () -> Double) { print(result); function() print(result) } というやたらと長い関数を定義しています。
この関数を分解してみると、function: () -> Double の部分が Closure を定義しています。これはすなわち「引数がなく、戻り値が Double の関数」ということです。そしてこの calculate 関数自体の戻り値は特になく(正確には戻り値が Void ですが)、中身はまず一回現在の result をログ出力して、次に result を function() 実行した値を代入します。ここで何故代入できるかというと、function の戻り値は Double だと calculate 関数の定義時にすでに決めたから、function の実行結果が result と型が一致するため代入できます。ちなみにここで肝になっているのは実行時に function の後に () が付いているところです。これが「function を実行する」という意味をします。ここで()のみと書いているのは、function に引数がないと定義している「() -> Double の部分の()」ためです。逆にもし引数があるならそれも入れなければなりません。そして function() を実行した後にもう一回 result をログ出力して結果を比較できるようにしています。
そして下のこの calculate(function) 関数の実行も見てみましょう。まず1つ目の例は「a = 1、b = 2 の時、a + b を計算する」という式です。普通の関数の実行なら、おそらく calculate(変数) のように書くと思われますが、ここでは少々違くて calculate({ 計算式 }) と書いています。ここで {} が「中身は関数だよ」という意味を持ちます。そしてこの一個の {} が Closure、すなわち一つの変数です。
ところが、定義時に「function の戻り値は Double だ」と定義したはずなのに、return がどこにも見当たらないですね。実はこれは簡易記法で(詳しくは下の3番目の例で解説します)、要するに1行だけで結果が戻り値なら {計算式} で書けます。
そして2番目の例、今度は掛け算で a = 3、b = 4 の時の a * b を同様に計算します。
最後の3番目の例、今回はちょっと長くなりますが、同じように calculate の後ろの () の中にある {} が一つの Closure だということです。この Closure の中身を見てみると、まず最初に () -> Double in と書いていますが、これはこの Closure の引数と戻り値を定義しています。() ですので引数はなし、-> Double ですので戻り値は Double です。そして in の後ろが関数の中身です。この関数で一つ通常のと違う処理というと、割り算をしていますがもし b が 0 だったら 0 も返す、ということですね(普通に計算するなら結果は Double.infinity、すなわち無限大です)。
このように、関数を引数として扱えるとこのような便利なことができちゃいます。もちろんこの例では全てが同じクラスの中にあるので別に Closure を使わなくても実現できますが、逆にコーディングスキルが向上してたくさんのクラスを扱えるようになった時、よく calculate の定義と calculate の呼び出しが違うクラスにあったりしますので、そういった場合は本当にこの Closure がないと非常に不便な記述が強いられますので、今のうちにある程度覚えておいた方が後々になって便利です。
ちなみに上記は「関数を引数として使う」時ですが、Closure はもう一つちょっと変わった使い方もできます。例えば下記のコードがあるとしましょう:
class MyViewController: UIViewController {
var viewA: UIView!
var viewB: UIView!
override func viewDidLoad() {
self.viewA = UIView()
self.viewA.backgroundColor = .whiteColor()
self.viewA.hidden = true
self.view.addSubview(self.viewA)
self.viewB = UIView()
self.viewB.backgroundColor = .blackColor()
self.viewB.hidden = false
self.view.addSubview(self.viewA)
}
}
はい、かなりおなじみの UIViewController のサブクラスで viewDidLoad() メソッド内でのビュー処理ですね。それぞれ viewA と viewB を改行で擬似的に二つのブロックに分けてそれぞれ定義して表示します。ところがこの書き方ですと、まあ最初に書く時なら特に問題ないと思われますが、例えばこの後修正をかける時とかですと、自動補完などの問題で下のようになったりする可能性もあります:
class MyViewController: UIViewController {
var viewA: UIView!
var viewB: UIView!
override func viewDidLoad() {
self.viewA = UIView()
self.viewA.backgroundColor = .whiteColor()
self.viewA.hidden = true
self.view.addSubview(self.viewA)
self.viewB = UIView()
self.viewA.backgroundColor = .redColor()
self.viewB.hidden = false
self.view.addSubview(self.viewB)
}
}
はい、お気づきでしょうか?self.viewB のブロックで backgroundColor を UIColor.redColor() に修正しています。ところがここで自動補完のせいでなぜか viewB のブロックで書いたつもりなのに実際は viewA を操作してしまっています。
このようなことをなるべく防ぐためには、「局部スコープ」というちょっと変わったやり方があります。スコープというのは簡単に言うと「変数や関数の有効範囲」ということです。C 言語などでしたら簡単に {} で囲むだけで有効範囲を意図的に狭めることが可能ですが、Swift 1.X 系の時ではそれが Closure の定義と被ってしまうためそんな簡単にはできません。でも逆にそれを利用して Closure で書くことができます。具体的には下記のようなコードを見てみましょう:
class MyViewController: UIViewController {
var viewA: UIView!
var viewB: UIView!
override func viewDidLoad() {
self.viewA = {() -> UIView in
let view = UIView()
view.backgroundColor = .whiteColor()
view.hidden = true
self.view.addSubview(view)
return view
}()
self.viewB = {() -> UIView in
let view = UIView()
view.backgroundColor = .redColor()
view.hidden = false
self.view.addSubview(view)
return view
}()
}
}
この書き方ですと、viewA と viewB の定義がそれぞれ Closure の中に独自で view を定義してその中に色々設定しているのです。これでしたら、viewB のブロックで間違って viewA を設定していまいました、というようなことを防ぐことができます。
ちなみにここも注意点がひとつありますが、Closure の最後の行を見ればわかりますが } ではなく }() で終わっているのです。ここも () で Closure の中身を実行していることが重要です。これを書かないと、「戻り値が UIView の関数」になってしまいコンパイルエラーになります。
追記:
ところが上記のコードは Swift 1.X 系の時に使う書き方ですが、2.X 系からは do が使えるようになったので Closure を使わなくてもできるようになります:
class MyViewController: UIViewController {
var viewA: UIView!
var viewB: UIView!
override func viewDidLoad() {
// Swift 2.X 系では do を使えば簡単に局部スコープ作れます
do {
let view = UIView()
view.backgroundColor = .whiteColor()
view.hidden = true
self.view.addSubview(view)
self.viewA = view
}
do {
let view = UIView()
view.backgroundColor = .redColor()
view.hidden = false
self.view.addSubview(view)
self.viewB = view
}
}
}
とこのように、catch なしの do 構文で局部スコープ作れちゃいます。
追記終了
ソースコードで View や ViewController を作る
正直なところ、実は自分は未だに Storyboard や xib で View を作ることが慣れていませんし好きではありません。WatchKit ならもちろん仕方ないのですが、iPhone アプリなら大体の場合とりあえずソースコードで View と ViewController を作っているのです。
なぜわざわざ面倒そうなソースコードで作るかというと、ソースコードの方が再利用がしやすいだけでなく、一番のメリットはバージョン管理が非常にしやすいということです。Storyboard などで作ると、そもそも Storyboard 自体がブラックボックスの部分もありますし、git などでバージョン管理してると、いつ、どういう修正をしたか、というのが非常に分かりづらいのです。まあこれはどっちかというと習慣の問題もありますので、絶対こっちの方が正しい、というようなことは言いません。ただもし機会がありましたら、ソースコードで一回 View や ViewController を作ってみてもいいと思います。何より、UIView や UIViewController の動作の理解も深めるのではないかと思います。
enum でより高い安全性と機能性を確保
enum は Objective-C と比べて、Swift で大幅に強化された機能の一つです。Swift では enum にいろんな拡張ができちゃうので、switch と一緒に使うと非常に簡単に安全性と機能性を確保できちゃいます。
例えば UIButton 要素の動作を定義するとき、たくさんの UIButton 要素が並んでると、それぞれの関数で動作を定義するのではなく、ボタンに tag を付け、一つの関数で switch でボタンの tag で動作を切り分けることが多いです。なぜこのようなことをするのかというと、for 文でボタン作ることができるのでソースコードの簡略化ができるのと、ボタン動作の一元管理ができるので保守的にもやりやすいのです。ところがデメリットも一つあって、それは UIButton の tag は Int 型ですので、どうしても switch 文で default 処理を書かなければなりません。
例えば下記のようなコードがあるとします:
class MyViewController: UIViewController {
override func viewDidLoad() {
for i in 1 ... 4 {
let frame = CGRect(x: CGFloat(i) * 50, y: 0, width: 50, height: 50)
let button = UIButton(frame: frame)
button.addTarget(self, action: "onButtonTapped:", forControlEvents: .TouchUpInside)
button.tag = i
self.view.addSubview(button)
}
}
func onButtonTapped(sender: UIButton) {
switch sender.tag {
case 1:
//Do Something
break
case 2:
//Do Something
break
case 3:
//Do Something
break
case 4:
//Do Something
break
default:
break
}
}
}
このコードを読めばわかりますが、for 文で UIButton 群を作れるので非常に書きやすいです。そして onButtonTapped(sender: UIButton) メソッドの中で UIButton の tag を取得して switch で動作を分岐しています。非常にわかりやすいですね。
ところがこれの不便なところは、例えば今後ボタンを一つ追加したとします。そしたら何をしなければいけないかというと、まずは for 文の範囲を一つ広げないといけません。そして case にも一つ追加しないといけません。どれか一つでも欠けたら当然動作がバグってしまいます。そしてそれ以上に大変なのは、まあこれまだボタン4つしかない場合ですが、ボタンじゃない場合などは case が膨大な数に上る可能性もありますが、そうなったら全部 Int 型だとどれが何のかも分かりづらいですしメンテしてるとパソコンを地面に叩きつけて踏んづけたい気持ちになります()。というわけで、このコードを enum を導入してみましょう:
enum MyButtonType: Int {
case Button1 = 1, Button2, Button3, Button4
case Dummy
static let allValues = {() -> [MyButtonType] in
return [Int](Button1.rawValue ..< Dummy.rawValue).flatMap({ (value) -> MyButtonType? in
return MyButtonType(rawValue: value)
})
}()
}
extension UIButton {
var type: MyButtonType {
return MyButtonType(rawValue: self.tag) ?? .Dummy
}
}
class MyViewController: UIViewController {
override func viewDidLoad() {
for buttonType in MyButtonType.allValues {
let frame = CGRect(x: CGFloat(buttonType.rawValue) * 50, y: 0, width: 50, height: 50)
let button = UIButton(frame: frame)
button.addTarget(self, action: "onButtonTapped:", forControlEvents: .TouchUpInside)
button.tag = buttonType.rawValue
self.view.addSubview(button)
}
}
func onButtonTapped(sender: UIButton) {
switch sender.type {
case .Button1:
//Do Something
break
case .Button2:
//Do Something
break
case .Button3:
//Do Something
break
case .Button4:
//Do Something
break
case .Dummy:
break
}
}
}
このように、すべてのボタンタイプを Dummy 加えて enum で先に定義しておきます。これでしたら Dummy の前に case 入れておけば、allValues の中には絶対入りますので、プログラムの for 文を修正しなくても絶対に漏れることはありません。ちなみに allValues の作り方にも先ほどの Closure を使っていますが、まあ詳しい解説は省きますがここの肝は範囲を ..< で定義することで、最後の Dummy が allValues に入ることがなくなります。そして、何かボタンを追加しましたら、Swift の switch 文は default 処理を入れない限り、すべての可能性に対して動作を定義しなければなりませんので即時にコンパイルエラーが発生し、定義し忘れることもなくなるでしょう。そして何より、ボタンの名前を自分で定義できるので、ただの数字で見るよりはるかにわかりやすいのです。
ちなみに上記のコードですべての case に break を入れているのは Playground での実行を考慮しているためですので実際のコードは別に入れる必要はありません。
もちろんこれをもう少し発展系にすると、どうせなら enum の中で動作を定義しちゃおう、ということも可能ですので、そうするとコードがさらにわかりやすくなります(ただスコープが MyViewController じゃ無くなるのでこのままではできることが限られてしまいますが):
enum MyButtonType: Int {
case Button1 = 1, Button2, Button3, Button4
case Dummy
static let allValues = {() -> [MyButtonType] in
return [Int](Button1.rawValue ..< Dummy.rawValue).flatMap({ (value) -> MyButtonType? in
return MyButtonType(rawValue: value)
})
}()
func buttonAction() {
switch self {
case .Button1:
//Do something
break
case .Button2:
//Do Something
break
case .Button3:
//Do something
break
case .Button4:
//Do something
break
case .Dummy:
break
}
}
}
extension UIButton {
var type: MyButtonType {
return MyButtonType(rawValue: self.tag) ?? .Dummy
}
}
class MyViewController: UIViewController {
override func viewDidLoad() {
for buttonType in MyButtonType.allValues {
let frame = CGRect(x: CGFloat(buttonType.rawValue) * 50, y: 0, width: 50, height: 50)
let button = UIButton(frame: frame)
button.addTarget(self, action: "onButtonTapped:", forControlEvents: .TouchUpInside)
button.tag = buttonType.rawValue
self.view.addSubview(button)
}
}
func onButtonTapped(sender: UIButton) {
sender.type.buttonAction()
}
}
まあさらに UIButton をサブクラス化して enum を SequenceType プロトコルに対応すれば Dummy すらなくすこともできますが今現在の仕様ですとちょっと面倒なので省きます。
値型と参照型の違いを身につけよう
Swift において、参照型は class のインスタンス、すなわち「オブジェクト」のみです。それ以外は値型です。普通の変数ももちろんそうですし、struct のインスタンスや enum なども値型です。
値型と参照型の何が違うかというと、その変数の中身が「値そのもの」になるのが値型で、それではなく「値を保持しているメモリ上のアドレス」になっているのが「参照型」です。つまり「値型」は値そのものを取得しているのに対し、「参照型」は値の所在を取得しているのです。まさに「参照」ですね。
では実際に運用している時、それぞれの特徴は何かというと、実際下記のコードを見てみましょう:
class SomeClass {
var a = 1
}
struct SomeStruct {
var a = 1
}
let someClass = SomeClass()
let anotherClass = someClass
someClass.a
anotherClass.a = 3
someClass.a
let someStruct = SomeStruct()
let anotherStruct = someStruct
someStruct.a
anotherStruct.a = 3
someStruct.a
まず Playground で SomeClass と SomeStruct をそれぞれ定義しておきます。中身は同じように a という初期値が 1 の Int 型の変数があります。
次にまず SomeClass のインスタンス someClass を作ります。そして someClass から anotherClass インスタンスを作ります。この時点で someClass.a はまだ初期値の1のままです。それでは anotherClass.a を適当に3に変更してみましょう。そうするとまた someClass.a の値を見てみましょう、同じく3になるのがわかると思います。
なぜこうなるのかというと、someClass が保持している値は、SomeClass を生成したオブジェクトそのものではなく、それがメモリ上にあるアドレスだからです。そして同じように let anotherClass = someClass で anotherClass を作る時も、コピーしているのはオブジェクトそのものではなく、someClass が保持しているアドレスの値なのです。だから someClass も anotherClass も、実は同じオブジェクトを参照しているのです。だから anotherClass.a を変更したら、同じオブジェクトを参照している someClass.a も一緒に変更されることになります。
次に SomeStruct の場合を見てみましょう。let someStruct = SomeStruct() でインスタンスを作って、let anotherStruct = someStruct インスタンスを作ります。この時点でもちろん someStruct.a は初期値の1のままです。ところが次に anotherStruct.a = 3 で値を変更してみましょう。あれ?いきなりこの時点でエラー出てるぞ?同じく let で作ってるのにさっきの anotherClass インスタンスは問題なく通ったのに?
これも値型の特徴なのです。というより、むしろ逆に let でオブジェクトを作っているのに、オブジェクトの中身を変更できるのが class、すなわち参照型の特徴です。先ほど言いました通り、参照型が保持しているのはメモリ上のアドレスなので、中身をどう変えようか変数としての someClass も anotherClass も全く変更がありませんので、let の定数宣言でも問題ありません。ところが struct は値型ですので、let で宣言すると中身の変更は当然定数としての anotherStruct の中身の変更となり、定数だから変更は認められないとエラーが出ます。
それではこのテストを続行するように、someStruct と anotherStruct の宣言を全部 var に変更してみて、結果を見てみましょう:
var someStruct = SomeStruct()
var anotherStruct = someStruct
someStruct.a
anotherStruct.a = 3
someStruct.a
さて今度はどうでしょう。anotherStruct.a の値を3に変更しても、someStruct.a の値は初期値の1のままです。これは var anotherStruct = someStruct で生成している時、someClass の時と違って someStruct の中身そのものをコピーして作っていたので、someStruct と anotherStruct は別々のインスタンスになっているから、anotherStruct をどう変更しようか someStruct に影響はありません。
ちなみに、上記の anotherClass のコード、もし let anotherClass = someClass の後に anotherClass = SomeClass で再定義しようとすると let 宣言だからエラーが起こります。まあ当然ですね。
この値型と参照型の違いを理解できたら、サンプルコードに出てきる一部のコード対しての理解も深めるのではないかと思います。例えばたまに let application = UIApplication.sharedApplication() のようなコードがありますが、UIApplication は class だから参照型なので、このコードは UIApplication.sharedApplication() から値を取得しているのではなく、既存の UIApplication.sharedApplication() そのものを取得しているのです。だからこの後 application に対して何を変更しようと、即座に UIApplication.sharedApplication そのものに反映されます。この手法は application のみでなく様々の場所で利用され、特に一番多く利用されているのは UIView オブジェクトを取得する場合ではないかと思われます。例えば UIView クラスにわざわざ子ビューをクラスの中に保持していなくても、もし tag が設定されていればいつでもそのコビューを取得できます。例えば下記のように:
class MyViewController: UIViewController {
override func viewDidLoad() {
let aChildView = UIView()
aChildView.tag = 100
self.view.addSubview(aChildView)
}
func setChildViewBackgroundTo(color: UIColor) {
if let aChildView = self.view.viewWithTag(100) {
aChildView.backgroundColor = color
}
}
}
上記のコードでは、MyViewController に特に aChileView をどこにも保持しておらず、ただ単に viewDidLoad() のところで即座に生成して自分に追加しただけです。ところが setChildViewBackgroundTo(color: UIColor) のメソッドで、self.view.viewWithTag(tag) で必要なビューを取得できるから、メソッド内でそれを取得して aChildView として保持して、背景色の変更を行うことができます。こういうのが参照型の便利なところですね。もし class が値型でしたら、viewWithTag で取得してもただの同じ中身の別オブジェクトしか取れないので、実際自分に追加した元の aChildView に設定変更ができなくなります。
もちろん逆に、こういうのをしっかりと覚えておかないと、痛い目にあうこともよくありますよ。例えば class で何かの設定オブジェクトを定義して、そしてとあるオブジェクトにその設定オブジェクトを適用して、今度別のオブジェクトを作って「さっきのオブジェクトと同じ設定でいいや」と思ってそのまま適用してしまったら、今度は別オブジェクトの設定オブジェクトの中身を変更したら元オブジェクトの設定オブジェクトも同様に変更されてしまいます。
循環参照、ダメ。絶対
さて、「参照型」の話を進めると、「循環参照」という概念が出てきますね。例えば、普通の変数だとしたら
var a = 1
var b: Int?
b = a
a = b
みたいな感じですと、これは a と b それぞれメモリ上では違うものになりますので別物になります。ところが参照型のインスタンスですと:
class A {
var b: B?
}
class B {
var a: A?
}
let a = A()
let b = B()
a.b = b
b.a = a
というようなコードになりますと、a の中に b という B のオブジェクトがあり、逆に b の中に a という A のオブジェクトがあります。この場合、a も b.a もメモリ上では同じものであり、逆に b も a.b もメモリ上では同じものとなります。
一番最初にみなさんが思いつくであろう弊害は、メモリ管理の問題です。値型の場合は複数の変数が同じものを参照することがまずありえないので、メモリ管理が非常に楽です。その変数が使わなくなったら破棄すればいいだけですので(しかも昔の C 言語みたいに手動で malloc や free する必要もありません)ユーザがほとんどメモリ管理を気にする必要がないでしょう。ところが参照型の場合、同一メモリ領域にアクセスしているのは一つの変数だけではない可能性もありますので、Swift では ARC(Auto Reference Counter)でメモリ管理をしています。簡単に言うと参照が増える時にカウンターを上げ、参照しなくなった時カウンターを一つ下げ、0 になったら該当メモリ領域を解放する、といったようなもんでしょう(UIView などのオブジェクトの管理はもう少し複雑のようですが)。ところが、循環参照していると、例えば上記のコードですと A オブジェクトは a と b.a の二つの参照があるので、カウンターが 2 ですが、a を nil に設定してもカウンターが 1 減って 1 になり、消滅せずメモリリークにつながります。(詳しくはこちらが詳しく説明されているのでご参考にすればと思います)
もちろんこれについては片方に「弱参照」という手法を用いれば解決できる問題ではあります。弱参照は何かと言うと、カウンターを上げない参照のことです。参照を上げないので、カウンターが 0 になれますので破棄できます。ところが循環参照はメモリ管理以上に、「オブジェクトの所有関係がわかりづらくなり、密結合につながり保守性が低下する」という非常に大変な問題点もあります。残念ながらこちらはどうしようもありません。
例えば下記のコードがあるとします:
class Person {
var car: Car?
func goForADrive() {
self.car?.drive()
}
func buyGasoline() {
print("Go buy some gasoline")
}
}
class Car {
var owner: Person
init(owner: Person) {
self.owner = owner
}
func drive() {
print("Drive!")
}
func outOfGasoline() {
self.owner.buyGasoline()
}
}
let maki = Person()
let ferrari458Italia = Car(owner: maki)
maki.car = ferrari458Italia
maki.goForADrive()
ferrari458Italia.outOfGasoline()
Car には drive という機能を定義して、Person に goForADrive という機能に self.car?.drive() の動作を行うようにします。そして逆に、Person に buyGasoline という機能を定義し、Car には self.outOfGasoline という機能に self.owner.buyGasoline() の動作を行うようにします。
それでは nishikinoMaki という Person オブジェクトと、ferrari458Italia という Car オブジェクトをそれぞれ作り、nishikinoMaki の car を ferrari458Italia に設定し、ferrari458Italia の owner を nishikinoMaki に設定します。見事な循環参照ですね。
さて、nishikinoMaki ちゃんがドライブしたい!と思った。goForADrive() だ!というわけで ferrari458Italia.drive() 動作が行います。
そしてしばらく経ったら、おや ferrari458Italia のガソリンがなくなった。outOfGasoline() だ!というわけで nishikinoMaki が buyGasoline しにいくわけですね。
このような循環参照の場合、最大の欠点は、どれか一つに修正を行った場合、(これを参照している)全てのクラスにも修正を入れないといけないかもしれない、ということになります。例えば、Car が何かしらの進化を遂げて drive ではなくとうとう fly 機能に生まれ変わった!そういったとき当然 Person の goForADrive の中身も self.car?.fly() に修正しなければなりませんし、逆に Person もちょっと機嫌が悪くて、「何で私がガソリンの買い出しに行かないといけないの?イミワカンナイ」と指示されるのも嫌で別の行動をしたい場合、Car の outOfGasoline の中身もそれに合わせて修正しなければならない。いや、そもそもこの理屈はおかしい。何で Car が Person の行動を把握しなくちゃいけないんだ?Person の全ての行動を把握できちゃったら確実に人類と機械の間に戦争が始まってターミネ(ry
という妄想はまあ大概にして、そもそも論として、Car は Person の所有物であり、Person が Car の全ての動きを把握するのは別に当たり前ですが Car が Person を把握してはいけません。親オブジェクトが子オブジェクトを把握するのは当たり前ですが子オブジェクトが親オブジェクトを把握してはいけません。つまり、親オブジェクトが子オブジェクトを参照するのは問題ありませんが子オブジェクトが親オブジェクトを参照するのはダメなのです。
じゃあ Car が outOfGasoline したらどうすればいいの?と言いますと、一つの方法は Protocol と delegate の出番です。早速修正コードを見てみましょう。
class Person: CarDelegate {
var car: Car?
func goForADrive() {
self.car?.drive()
}
func buyGasoline() {
print("Go buy some gasoline")
}
func solveGasolineShortageProblem() {
self.buyGasoline()
}
}
class Car {
var delegate: CarDelegate?
func drive() {
print("Drive!")
}
func outOfGasoline() {
self.delegate?.solveGasolineShortageProblem()
}
}
protocol CarDelegate {
func solveGasolineShortageProblem()
}
let nishikinoMaki = Person()
let ferrari458Italia = Car()
nishikinoMaki.car = ferrari458Italia
ferrari458Italia.delegate = nishikinoMaki
nishikinoMaki.goForADrive()
ferrari458Italia.outOfGasoline()
今度は、CarDelegate というい protocol を作って、Car の owner: Person の代わりに delegate: CarDelegate? という要素を定義します。ちなみに「Delegate」は「権限譲渡」の意味で、今までずっと習慣的にこういう名付け方しているだけなので別に例えば「owner」のままだとか違う名前をつけてても全然問題ないのですが、ただまあ保守性を考えるとやはり見慣れた名前の方がわかりやすいじゃないですか。
そして、CarDelegate の中に、solveGasolineShortageProblem というメソッドを追加します。そしたら Car の outOfGasoline の中身を self.delegate?.solveGasolineShortageProblem に変更します。つまり「ガソリンがなくなったから有権者がなんとかしてくれ」という合図です。
これで、Person を CarDelegate という protocol に対応するように宣言し、solveGasolineShortageProblem のメソッドを追加して、対応の仕方を中身として self.buyGasoline() と設定します。これで、nishikinoMaki と ferrari458Italia のオブジェクトを生成したら、ferrari458Italia.delegate を nishikinoMaki に設定すれば、ferrari458Italia が outOfGasoline の時、delegate、すなわち nishikinoMaki を呼び出して、solveGasolineShortageProblem と要求します。呼ばれた nishikinoMaki は solveGasolineShortageProblem の対処として、buyGasoline します。
一見、こんな作り方は循環参照するように作るより実装が複雑になったようですが、これによって得たメリットは、Person の動作を修正した場合、Car の修正が全く必要がない、ということです。だってそもそも Car は Person に対して何も知らないんですから。Person が仕様変更してようかしてまいか関係ありません。というわけで、もし nishikinoMaki が「もうガソリンなくなったの?仕方ない 458 イタリア売ってラ フェラーリ買おうか」と思ったら、
class Person: CarDelegate {
//略
func sellMyCar() {
self.car = nil
print("458 イタリア売却しました")
}
func buyANewCar() {
let laFerrari = Car()
laFerrari.delegate = self
self.car = laFerrari
print("ラ フェラーリを購入しました")
}
func solveGasolineShortageProblem() {
self.sellMyCar()
self.buyANewCar()
}
}
と、Person の動作だけを修正すれば OK です。まあそれにしてもお金持ちっていいよね…裏山
でも、このままでは結局実質 protocol を介しての循環参照だから、Delegation を弱参照に変更しない限り結局はメモリリークが発生してしまいます。ここで登場してもらうのは、Class-only Protocol と言う定義の手法です。やり方は簡単、CarDelegate をこんな風に class 限定で定義するだけです:
protocol CarDelegate: class {
// 略…
}
上記のように定義すれば、delegate を「弱参照」で宣言できるようになります:
class Car {
weak var delegate: CarDelegate?
// 略…
}
ちなみに、こういったテクニックも後の MVC アーキテクチャの応用において非常に頻繁に出てくるから、今のうちに身につけておいた方がいいでしょう。
アクセスコントロールを意識しよう
初心者の頃は、とりあえずなんかコード組んで動かせればそれで問題ないのですから、アクセスコントロールを特に意識する必要はありません。ところがプログラミングスキルが徐々に上達していき、何か実際のアプリを組めるようになると、アクセスコントロールが徐々に重要になってきます。
アクセスコントロールの一つの意義はコンパイル時の最適化です。他のクラスやファイルからアクセスできないようにすることで不要な参照をなくし、パフォーマンスの向上につながります。
そしてもう一つ大きな意義は、やはり保守のしやすさですね。ここ最近一つ思ったのは、保守のしやすさは、コードの万能さに反比例する、ということです。クラスとかストラクチャーとか、できることが多ければ多いほど、保守がしづらくなります。ですので一つ一つのクラスの本当の「仕事」を考え抜き、自分の責務だけしか果たさないようにするのは非常に大事です。そしてその中の一つが、「他人に自分の全てを教えない」ということです。他人が自分のことを知らないほど、自分の修正が他人への負担が少ないのです。
「外部に内部のことをなるべく開示しないようにする」という自制心は、確かに各クラスなどのできないことを増やしており、最初は「なんでこんな無駄なことをやらないといけないの」とか思うかもしれません。例えば同じく上の Person と Car を例にしてみましょう。今度は Car の drive 機能を、ちょっと具体的に作ってみましょう:
class Car {
weak var delegate: CarDelegate?
func drive() {
self.startEngine()
self.changeShift()
self.releaseSideBrake()
self.stepOnGasPedal()
}
func startEngine() {
print("Start Engine")
}
func changeShift() {
print("Change Shift")
}
func releaseSideBrake() {
print("Release Side Brake")
}
func stepOnGasPedal() {
print("GO! GO! GO!")
}
func outOfGasoline() {
self.delegate?.solveGasolineShortageProblem()
}
}
はい、drive をちょっと具体的に、startEngine、changeShift、releaseSideBrake と stepOnGasPedal の 4 ステップにしてみました。このままでは当然今までと同じように Person 側は self.car?.drive() でドライブできます。ところが、このままでは Person は Car の全ての機能を把握できちゃうので、例えば「いや俺はこんな人並みの生き方がいやだ!他人と違うことをしたい!」とか言いながら、goForADrive メソッドの中身を下記のように書き換えます:
func goForADrive() {
self.car?.releaseSideBrake()
self.car?.startEngine()
self.car?.changeShift()
self.car?.stepOnGasPedal()
}
これでどうだ!こんな手順でも車動かせるじゃないか!ということになりますね。はい。
もちろん実際の日常生活ではこれが当たり前ですが、しかしプログラミングの世界だと事態がもう少し複雑になります。まず車の操作の仕方なんてしょっちゅう変わることなんてありえない。サイドブレーキがない車なんてまずない(もちろん「サイド」にあるとは限らないが)し、ペダルの順番も必ず決まって右がアクセルで一個左がブレーキ、MT 車ならさらに左にクラッチがあるように配置されます。こういった「標準化」のおかげで、我々は運転教習所を通って教習車で練習するだけで、ほとんど決まった形式のどんな車でも乗れるようになります(例えばフツメンなら一般乗用車と原付など)。
ところが、プログラミングの世界だと、仕様変更なんてしょっちゅうあるものです。昨日まではこの仕様でしたが、明日いきなり「サイドブレーキなんて無駄だ!なくせ!」という無茶振りを受けてじゃあ仕方なく releaseSideBrake の手順をなくしたら、Person 側の goForADrive の中身を書き換えなければいけません。車の OS をアップデートしたら教習所通い直せみたいなもんです。そんなの嫌じゃないですか。
というわけで、最初から drive の中身のものを全て private にしましょう。こうすれば Person はそんな無駄な制御ができなくなり、Car がどんなに仕様変更しようと、drive 機能がなくならない限り Person 側は常にその呼び出しだけで使えるから修正が必要ありません。
class Car {
weak var delegate: CarDelegate?
func drive() {
self.startEngine()
self.changeShift()
self.releaseSideBrake()
self.stepOnGasPedal()
}
private func startEngine() {
print("Start Engine")
}
private func changeShift() {
print("Change Shift")
}
private func releaseSideBrake() {
print("Release Side Brake")
}
private func stepOnGasPedal() {
print("GO! GO! GO!")
}
func outOfGasoline() {
self.delegate?.solveGasolineShortageProblem()
}
}
まあ、もちろん「別にこれらのメソッドを private にしなくても、Person 側がこれらのメソッドを使わないようにすればいいだけじゃないか」と思うかもしれません。しかしコード組んだ当初は自分はもちろんこういったことは把握できますが、3 ヶ月経った後に自分が保守するとき、もしくは他人がこのコードを修正するときになるとどうでしょうか?なんの説明もないので使ってはいけないなんて誰も覚えていない・知らないことになるのです。そういったことが起こらないようにも、きちんとアクセスコントロールして、private を入れておきましょう。何度でも言いますが、一つ一つの部品ができることが少なければ少ないほど、後々のメンテナンス性が向上されます。
class と struct の使い分け
さてここまで来たらやはり避けては通れないですよね、class と struct の使い分けの問題。Objective-C の場合、そもそも struct は C からそのまま引き継がれてて非常に貧弱なので、多くの場合 class がどうしても必要だからある意味逆にわかりやすい点もあったりします(参照型がもたらす弊害は別問題として)。ところが Swift の場合、struct も class と同じくらい強力です(唯一 class があって struct がない大きな特徴を言うと「継承」という概念がない、と言ったろころくらいですかね)。そうなると、多くの場合迷ってきちゃいますよね。自分が実現したいものに関して、class でも struct でもどっちでも解決できるのですが、どっちを利用すべきなのか最初の頃はやはりこう言った迷いもたくさんあるのではないかと思います。
自分の場合どういう風に使え分けているか、結論から言うと、「データとして利用したいもの」に関しては struct を、「データのまとめ役だったりマネージメントするオブジェクト」に関しては class を利用するようにしています。
なぜこのような使い分けをしてるかというと、やはり決め手は「値型」か「参照型」か、という class と struct 最大の区別です。例えばゲームのセーブデータを管理するマネージャーでしたら、多くの場合、「代入」は「このマネージャーへのアドレスをいろんなオブジェクトから参照して何か処理」をしてもらいたいので、こういった場合は参照型である class の方が便利です。逆に、そのマネージャーが管理する一つ一つのセーブデータの場合、多くの場合「代入」は「データそのものをコピー」がしたいので、値型である struct の方が便利であり、データをコピーすることによって、不用意にコピー元のデータを改ざんしたりすることもなくなります。つまり「今この変数を保持しているのはそのデータへの参照アドレスだ」ということを意識しなくて済むということを意味します。Objective-C では struct はメソッドや算出プロパティなどが使えないので、本当は値型の方が嬉しいのにどうしても class を使わざるをえないといったシチュエーションを、Swift が解決してくれた、という見方もできるのではないかと思います。
Singleton デザインパターンの是非
オブジェクト指向の勉強が進むと、「Singleton」というデザインパターンと出会うこともあると思います。そして必ずそれと同時に、「Singleton はなるべく使わないようにする」というような忠告も目にするでしょう。
まず、Singleton は確かに非常に強力で便利なものです。オブジェクトは常に一つしか存在しないことが保証され、かつどこからでもそれを利用できてしまいます。Swift は 1.2 から Singleton の実装も非常に簡単にできるようになり、例えば下記のように作ればできちゃいます:
class SomeClass {
static var defaultObject: SomeClass = SomeClass()
private init() {
}
}
とりあえず適当に SomeClass を作って、そして自分自身のオブジェクトを static var として定義して、最後は他のところからオブジェクトを作れないようにイニシャライザーを private にして隠します。こうすればどこからでも SomeClass.defaultObject で SomeClass の唯一のオブジェクトを呼び出せます。
ところが Singleton がもたらした弊害も非常に大きいです。一番大きいなポイントはまさに「所有関係が曖昧になること」でしょう。一つだけ Singleton オブジェクトがあるならともかく、いくつも Singleton オブジェクトがあったら、誰が誰を所有すべきなのかが非常に分かりにくくなり、循環参照の時と同じように、どれか一つでも修正したら、周りのすべてのクラスが影響を受けてしまいます。
アクセスコントロールのところでも申しましたように、自制心は万能さと反比例しますが、メンテナンス性と比例します。いい自制心をかけてプログラムを組めば、何かの修正や調整があるときに、修正すべき箇所を最小限にとどめてくれます。逆に自制心がなく、どこからでも利用出来るということはつまり逆を言うと、Singleton オブジェクトの仕様を修正した時、それを利用したすべての場所も修正しなければならないかもしれません、ということです。
そして更に、循環参照の時と同じように、参照カウンターが 0 にならないため、いつオブジェクトを破棄すべきかわからず、常にメモリ領域を占拠することになってしまいます。
でももちろん、Singleton を絶対使ってはいけないわけではありません。実際 UIKit も大量に Singleton を利用しています。NSFileManager.defaultManager() とか、NSUserDefaults.standardUserDefaults() とか、UIApplication.sharedApplication() とかまさに Singleton の代表格でしょう。なので実際 Singleton はいつ使うべきかを考察してみると、まず「どれかにも属さない」というもの、「必ず一つしかオブジェクトが存在しない」というもの、そして「様々なオブジェクトから利用されることが予想できる」というもの、これらの条件がすべて揃っているものなら、Singleton も使っても良いではないかと思います。例えば一つ例を挙げますと、ゲームとかのセーブデータマネージャーはある意味 Singleton に適しているものの一つではないかと思われます。セーブデータマネージャーならアプリの様々な要素からしてみると割と独立した存在ですし、必ず一つしかない(というか複数あったら困る)し、そして様々な要素から呼び出してセーブロードすることが予想できます。ですので、セーブデータの管理なら、Singleton で作っても良いではないかとは個人的に思います。ただし、もちろんセーブデータマネージャーも Singleton じゃなくても作れるし、そしてどんなプロジェクトでも同じですがなるべく Singleton オブジェクトの数を最小限に抑えるべきです。何より、Singleton でセーブデータマネージャー作ったら、どんな Singleton オブジェクトでも同じですが、セーブデータマネージャーの仕様変更があったら、これを利用しているすべてのクラスにも修正が必要かもしれないということは変わりません。
プロトコル指向プログラミングとは
「オブジェクト指向」はわかりますが、「プロトコル指向」とは?と最初戸惑うと思います。まあこれも仕方ない、だって今まで「プロトコル指向」なんて言葉がほとんどなかったんですから。
Swift 2.0 から、アップルが「プロトコル指向」という概念を広めようとしています。簡単に言うと、「オブジェクト指向で利用される class は固有の問題点がいくつかあるので、これらを解決するのがプロトコル指向だ」ということです。
ではオブジェクト指向はどんな問題があるかというと、まず「参照型」だということが挙げられます。もちろん今までのコードで分かるとおり、参照型自体が悪だというわけではありませんし、そもそも参照型の方が嬉しい、といったシナリオもいくらでもあります。ところが初心者にとってはわかりづらいというのは確かだし、値型の方が嬉しいというシナリオに対応しづらいというのもまた事実です。
そして class が単一継承しかできない、というのもまた面倒なところです。時々複数の特徴を継承したい場合もあります。そういった場合は対応の仕方は大体すっごい包括的なスーパークラス作って、そこからいろんなサブクラスを作るといった方法です。ところがこの場合、多くのものはスーパークラスで定義したのはいいもの具体的な実装がしづらい、という面倒なところもあります。なので実装は各サブクラスに任せるしかないのですが、オーバーライドは必須項目ではないので新しいサブクラスを作るとき忘れたりすることもまたよくあります。
というわけで、class 以外の選択肢として、struct+protocol というアプローチも Swift 2.0 で推奨されました。これの何が嬉しいかというと、struct は値型ですので、値型の方が嬉しい、というシナリオに非常に対応しやすいです。そして protocol は多重対応ができ、そして基本自分自身は実装を設定しないため、実装を実際自分を対応している struct や class に強制的に任せることもできます。
プロトコル指向プログラミングの詳細に関してはこちらの記事と公式ビデオセッションをご覧いただければと思います。
Framework を活用しよう
開発が進むと、今度は複数の似たようなものを開発することも出てくるかもしれません。この場合、一つの選択肢は元のプロジェクトをそのままコピペして新しいプロジェクトを開発することです。これなら最速に新しいプロジェクトの開発ができますので、スタートダッシュが非常に早いです。
ところが、プログラムというのは、一回出来上がったらそれでハイ終わりというようなものではないのです。終わってもサービスが存続する限りアフターケア、すなわちメインテナンスが必要です。完全に別々のプロジェクトにしてしまうと、例えば一つのプロジェクトをバグフィックスしたら、もう一つのプロジェクトにも同様に同じような作業をやらなければなりません。こんな同じようなプロジェクトが多いほどそういった手間が増えてしまいます。気づいたら本来30分で終わる作業がなぜかプロジェクトが多い分丸一日過ぎてしまったといったようなこともありえます。時間の無駄なんてまだ二の次です。そもそもプログラマっていう人種は「重複労働」が大っ嫌いな人種なのです。なので時間の無駄以上に、「まったく同じような作業を一日中ずっと繰り返してること」自体に苦痛を感じちゃいます。
こんなことを少しでも減らしてくれるのは、Framework の存在です。Framework を作ることによって、同じようなプロジェクトを立ち上げる時その Framework から利用しますので、修正の時も一つの Framework を修正するだけで全てこの Framework を利用しているプロジェクトが一気に同じように修正されます。まあもちろん修正がこの Framework の利用方法自体にも及ぼしてる場合は仕方なく全プロジェクトもそれに合わせて修正しないといけないのですが…それでも、こういったことは比較的に少ないし作業量も大体の場合そんなに重くない(Framework の設計さえそれなりにしっかりしていればの話ですが)ので、やはり Framework を利用しないで全プロジェクトに同じような修正を入れることよりは全然楽です。
Framework の作り方に関してはこちらをご覧いただければと思います。
MVC アーキテクチャによるのアプリ開発
さて、ようやくこの記事の最後の項目になりました。ある意味、ここまで書かれたすべての項目は、全部この章のための準備だと言っても過言ではありません。
まず MVC について三行でまとめると
- モデル・ビュー・コントローラーを分ける
- それぞれに自分の役割以外のことをさせない
- それにより高い再利用性と保守性を得る
いけてるプログラマのようにアピール!
と言った感じでしょうか。ではモデル・ビュー・コントローラーはそれぞれどんな役割を持っているのかを簡単に見ていきましょう。
まずはモデルです。これは基本データの処理を行う部品です。何かの計算をやらせたい、といった時、具体的にその動作をおこなっているのがこのモデルです。
続いてはビュー。これは文字通り、「描画」を担う部品です。どのパーツは画面のどこに表示させるべきか、などと言ったことの処理は全てビューの責務です。ところが、音声の再生ももしかすると実はある意味「ビュー」の役割じゃないのか?と筆者は思ったり思わなかったり。
そして最後はコントローラー。iOS 開発ならみなさんお馴染みの UIViewController オブジェクトがまさにこれを担当しています。これは何をやっているのかというと、ユーザからの入力を受け付けて適切な命令をモデルやビューに送ったり、モデルとビューの架け橋を担ったり、そして別のコントローラーを呼び出すのもこのコントローラーの役目です。
ではモデル・ビュー・コントローラーはお互いどういった参照関係かというと、図にすると下記のようになるでしょう:
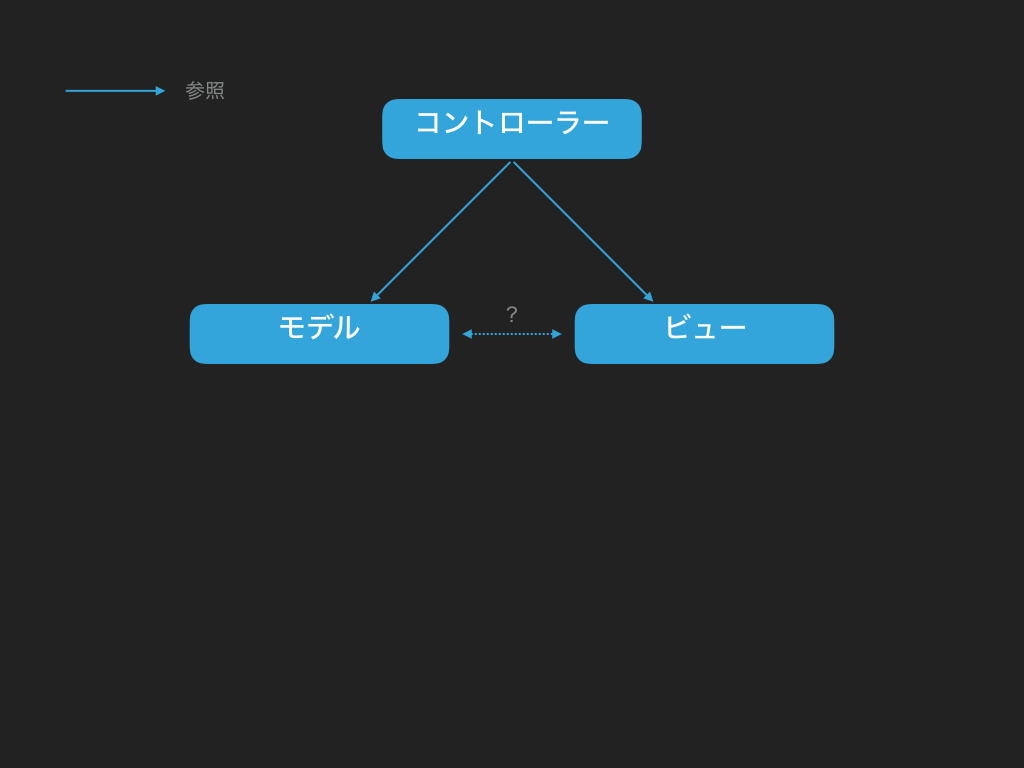
上記の図で分かるとおり、基本コントローラーが入力受け付け担当のため、様々な仕事をモデルなりビューなりを命令するのがコントローラーの仕事だから、モデルもビューも基本コントローラーから参照できるようにします。ところがこの記事で書いたとおり、「循環参照」は基本ダメなので、モデルからでもビューからでもコントローラーが参照できないようにしなければなりません。なら、モデルとビューはお互いどう参照すればいいのでしょうか?
ひと昔(SmallTalk が提唱した MVC モデルの時代?)では、実はビューからモデルが参照できるようにしても大丈夫と言った作りが主流だったらしいです(詳しくは知りません、というかその時そもそもまだ生まれてすらいません)。まあモデルが演算終わって何かしらの通知を送ってそれを受け取ったビューが直接モデルに参照して新しい値を取得して描画し直す、といった流れですね。
ところが最近はモデルとビューの間でも直接参照させないように作るのが主流になってきたっぽいです。本当かどうかは筆者には判断するすべはありませんがまあ多分それほど間違ってはいないかなと思います(少なくともアップルの公式ドキュメントでは直接参照しないように書いてるらしいです)。だって考えてみると、どっちか片方でも相手を参照できるように作ったら実質循環参照になっちゃうんじゃないですか。それで直接モデルとビューがお互い参照できないように作るためには、主な手段は三つあります。
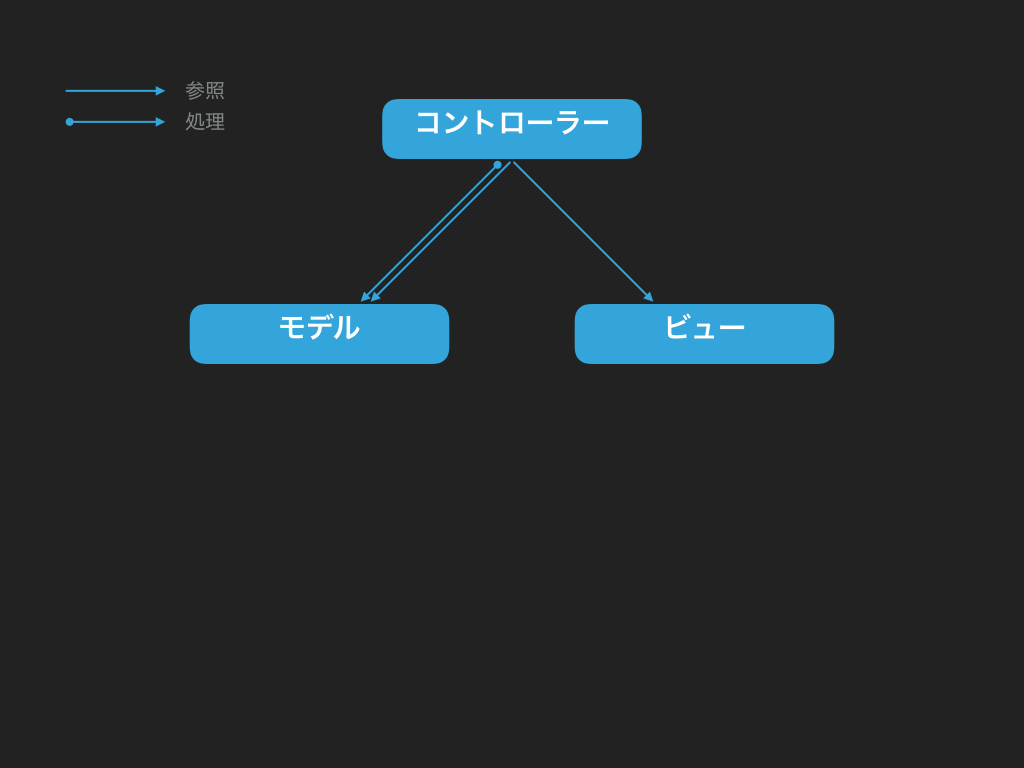
Callback を使う方法
まず一つはコールバックを利用する方法です。どういう方法かというと、モデルとビュー両方保持しているコントローラーから、あらかじめ処理してほしいものを一緒に投げる、例えばモデルにこの処理してほしい、そして処理終わったらビューをこのように更新するということも一緒にあらかじめモデルに丸投げする方法です。図にすると下記のようになります:
で、具体的にどういう風にやるかというと、下記のコードをごらんください:
import UIKit
class ViewController: UIViewController {
var testModel: TestModel!
var testView: TestView!
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
self.testModel = TestModel()
self.testView = TestView(frame: CGRect(origin: .zero, size: self.view.frame.size))
self.testView.label.text = self.testModel.displayedString
self.view.addSubview(self.testView)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
override func touchesEnded(touches: Set<UITouch>, withEvent event: UIEvent?) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0)) { () -> Void in
self.testModel.appendString("!") { (newString) -> Void in
dispatch_async(dispatch_get_main_queue(), { () -> Void in
self.testView.updateLabelString(newString)
})
}
}
}
}
import UIKit
class TestModel: NSObject {
var displayedString: String
override init() {
self.displayedString = "Hello, World!"
super.init()
}
func appendString(string: String, finished completionHandlerWithNewString: ((String) -> Void)? = nil) {
self.displayedString += string
completionHandlerWithNewString?(self.displayedString)
}
}
import UIKit
class TestView: UIView {
let label: UILabel
override init(frame: CGRect) {
self.label = UILabel(frame: CGRect(origin: .zero, size: frame.size))
super.init(frame: frame)
self.addSubview(self.label)
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
func updateLabelString(string: String) {
self.label.text = string
}
}
と、まず ViewController に TestModel と TestView 両方生成して保持させておきます。ViewController からタッチ判定を受けたら、別スレッド立ち上げて TestModel に "!" を後ろに一個追加するように命令します。そして追加が終わったらまたメインスレッドに切り替えてビューの表示を更新するという命令も一緒に TestModel に投げます。こうすることで TestModel が TestView を知らなくても描画の更新ができるようになります。
ここで一番のギミックになっているのは TestModel の appendString というメソッドの作り方です。具体的に見てみましょう:通常の追加文字列 string の後ろに、finished completionHandlerWithNewString: ((String) -> Void)? = nil という引数(Closure)が設定されています。この completionHandlerWithNewString が引数名で、この関数の最後に completionHandlerWithNewString?(self.displayedString) のように呼び出されています。これはつまり、self.displayedString をこの Closure の引数として実行する、ということです。
次に実際この appendString(_, finished:) の関数を呼び出しているコントローラー側のコードを見てみましょう。self.testModel.appendString("!") { (newString) -> Void in …… } のように呼び出しています。こうすることによって、モデルから処理の結果を newString として受け取って、これを実際の self.testView.updateLabelString(newString) で使うことができるようになります。
Swift の勉強で一番最初にぶつかるであろう壁となる Closure。上の方にも書いてある通り、最初は「何に使うんだろう??」と、疑ったり意味不明に思ったりする人も多いではないかと思いますが、こうしてみるとはっきりと使い道もわかってきて少しは上達してみる勇気も湧いてくるのではないかと思います。
ちなみに、なぜ TouchesEnded ではいちいち別スレッド立ち上げたりまたマインスレッド戻したりと面倒くさいことをやってるかというと、ここでは単純なサンプルをあげてるだけですので、モデルの処理が非常にシンプルですぐ終わりますが、通常のモデルの処理は重い作業も沢山あります。TouchesEnded メソッドはメインスレッドから呼び出されるので、そのままメインスレッドでモデル処理をやらせると、その間だけメインスレッドが他の処理が全くできなくなり、これはすなわち画面タッチなどにも反応できない、ということを意味します。ユーザからしてみるとこの間アプリがフリーズしてるように見えますので、ユーザエクスペリエンスとしては最悪ですのでそれを避けなければなりません。だからいちいち面倒くさそうなスレッド切り替え作業をやらなければならないのです。
ところが、この非常にシンプルな Callback の方法ですが、ひとつ欠点があります。それはモデルとビューの連携が最初からすでにシーケンシャル的に決まっていれば、コントローラーから予め動作を設定してあげられるのですが、逆にそうでない場合、例えば演算の結果によってビューを違う操作で処理したい場合だったり、ビューの処理タイミングが一定でなかったりなど、そう言った複雑な制御が入ってる場合は Callback が使えない(まあ全く使えないわけではありませんがその場合ソースコードが非常に長くなってしまう上コントローラーがとてつもなく肥大化してしまい結果的にメンテナンス性が下がるしパフォーマンスもイマイチよろしくない)ので、別の方法が必要です。
NSNotificationCenter を利用する方法
例えば、「通知」というやつを利用するパターンがあります。iOS や OS X なら NSNotificationCenter という便利な通知を送り合う仕組みがあってですね。これを利用すると、Callback の時と同じように、お互い参照できなくても、いろんな連携ができるようになります。しかもそれらの処理は全て各々のパーツ内で完結するため、コントローラーの肥大化も避けられます。図にすると下記のようになります:
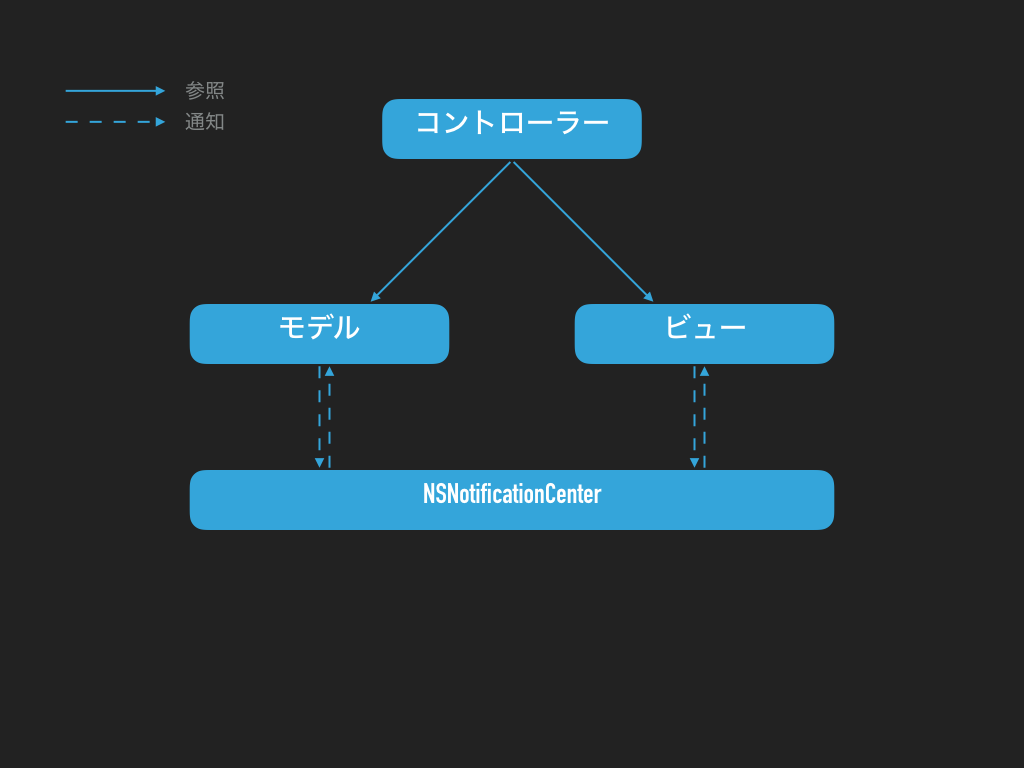
簡単に言いますと、まずモデルとビューにそれぞれ NSNotificationCenter に受け取らせてほしい通知を登録します。そしたら例えばモデルが何かしらの演算終わってビューに内容を更新してほしいと言った時に、NSNotificationCenter に NSNotification オブジェクトを投げます。それを受け取ったビューが通知内容に応じて描画を更新します。簡単ですね?逆も同じです。簡単なコードを見てみればわかると思います:
import UIKit
class ViewController: UIViewController {
var testModel: TestModel!
var testView: TestView!
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
self.testModel = TestModel()
self.testView = TestView(frame: CGRect(origin: .zero, size: self.view.frame.size))
self.testView.label.text = self.testModel.displayedString
self.view.addSubview(self.testView)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
override func touchesEnded(touches: Set<UITouch>, withEvent event: UIEvent?) {
self.testModel.appendString("!")
}
}
import UIKit
class TestModel: NSObject {
var displayedString: String
override init() {
self.displayedString = "Hello, World!"
super.init()
}
func appendString(string: String) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0)) { () -> Void in
self.displayedString += string
switch self.displayedString.characters.count {
case 0 ..< 20:
NSNotificationCenter.defaultCenter().postNotificationName("NewString", object: self.displayedString)
case 20:
if let image = UIImage(named: "TestImage") {
NSNotificationCenter.defaultCenter().postNotificationName("NewString", object: image)
}
case 21:
NSNotificationCenter.defaultCenter().postNotificationName("NewString", object: true)
default:
self.displayedString = "Hello, World!"
NSNotificationCenter.defaultCenter().postNotificationName("NewString", object: self.displayedString)
}
}
}
}
import UIKit
class TestView: UIView {
let label: UILabel
override init(frame: CGRect) {
self.label = UILabel(frame: CGRect(origin: .zero, size: frame.size))
super.init(frame: frame)
self.addSubview(self.label)
NSNotificationCenter.defaultCenter().addObserver(self, selector: "needsUpdate:", name: "NewString", object: nil)
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
deinit {
NSNotificationCenter.defaultCenter().removeObserver(self)
}
func needsUpdate(sender: NSNotification) {
switch sender.object {
case let newString as String:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
self.label.text = newString
})
case let newImage as UIImage:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
let imageView = UIImageView(frame: self.label.frame)
imageView.contentMode = .ScaleAspectFill
imageView.image = newImage
self.addSubview(imageView)
})
case let removeImage as Bool where removeImage:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
for subview in self.subviews {
if subview is UIImageView {
subview.removeFromSuperview()
}
}
})
default:
break
}
}
}
上記のコードでは、ViewController でタッチを検出したら TestModel の appendString(string: String) メソッドを呼び出し、"!" の文字列を追加するように命令します。これだけです。先ほど Callback の時のようなクソ長い制御文がありません。
次に TestModel の appendString(string: String) メソッド内では、先ほど紹介した通りメインスレッドのままで処理させるのはあまりよろしくないため一応別スレッドを立ち上げて、displayedString プロパティを更新します。
では、文字列の演算が終わったら、ビューの表示を更新させたいのですが、モデルでは ViewController も TestView も保持されていませんし Closure も渡されません。なのでここは NSNotificationCenter の登場です。適当に例えば "NewString" の名前で通知を作って、object か userInfo に処理してほしい結果を送るだけですので非常にシンプルです。ここでは self.displayedString の文字数が 20 文字以下の場合そのまま文字列を送り、20 文字になったらとある画像を送り、さらにこれ以上になったら文字列をリセットする、というようなちょっと複雑にした感じの処理をさせます:
func appendString(string: String) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0)) { () -> Void in
self.displayedString += string
switch self.displayedString.characters.count {
case 0 ..< 20:
NSNotificationCenter.defaultCenter().postNotificationName("NewString", object: self.displayedString)
case 20:
if let image = UIImage(named: "TestImage") {
NSNotificationCenter.defaultCenter().postNotificationName("NewString", object: image)
}
case 21:
NSNotificationCenter.defaultCenter().postNotificationName("NewString", object: true)
default:
self.displayedString = "Hello, World!"
NSNotificationCenter.defaultCenter().postNotificationName("NewString", object: self.displayedString)
}
まあ一応これでも Callback なら先ほどの newString: String のところを newObject: NSObject に書き換えればできないことはないですけど、ただこれ以上複雑なパターン、例えば呼び出しタイミングや回数がバラバラだったり、そもそも違うものを呼び出させたかったり(このサンプルでは TestView 一つしかないけど他の View に処理させたかったり)するとやはり Callback の限界を感じますね。まあそれは良しとして、最後にこの通知を受け取ったらどうすればいいか、ということも定義してあげないといけないですので、TestView に行って、まずは先ほど定義した "NewString" という名前の通知を監視するように init に書きます:NSNotificationCenter.defaultCenter().addObserver(self, selector: "needsUpdate:", name: "NewString", object: nil)。さらに、一応オブジェクトが破棄されたら監視をやめないといけないですので deinit でこのように書いてあげます:NSNotificationCenter.defaultCenter().removeObserver(self)
受け取った通知をどう処理すればいいか、と言うのは先ほどの監視定義の selector の所に定義します。上記のコードですと "needsUpdate:" ですので、さらに下記のようにメソッドを作ります:
func needsUpdate(sender: NSNotification) {
switch sender.object {
case let newString as String:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
self.label.text = newString
})
case let newImage as UIImage:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
let imageView = UIImageView(frame: self.label.frame)
imageView.contentMode = .ScaleAspectFill
imageView.image = newImage
self.addSubview(imageView)
})
case let removeImage as Bool where removeImage:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
for subview in self.subviews {
if subview is UIImageView {
subview.removeFromSuperview()
}
}
})
default:
break
}
}
今度は、通知が送られてくるのはメインスレッドではないので、画面を更新するためにメインスレッドを呼び出し、送られてきた通知のオブジェクトが文字列なら label の文字列を通知で送られてきたものに置き換え、画像なら新規の画像ビューを上に重ねて表示し、さらに Bool 値が送られてきて、しかも値が true であれば画像ビューを全て消すという処理を定義します。どうでしょうか?シンプルですよね。ちなみに上記の図ではモデルもビューもお互い通知を投げるって感じになっていますが実際のところビューから通知を投げることはほとんどないではないかと思います。基本受けですから(おい)、ただまあ強いて言うのなら例えば何かアニメーションをさせてそしてそのアニメーションが終わったらモデルに何かしてもらいたい、とかいう場合だったらビューから通知を投げることもアリなんじゃないかと思います。
ただ、NSNotificationCenter を利用するのはとても手軽で便利ですが、欠点も一応あります、それはお互いのオブジェクトの関係があまりにも疎すぎるため、メンテナンスするときや仕様修正するとき、**「通知を投げる処理だけ実装したけど受け取る処理を実装し忘れた!」とか、逆に「通知を受け取る処理は実装したけどそもそもどこにも通知を投げていない!」**とかいうパターンもありえます。上記のコードも、モデル側から通知を投げる処理だけコメントアウトしても、逆にビュー側から通知を受け取る処理だけコメントアウトしても、コンパイル上は全く何事もないように通りますので、そういった意味ではプログラマの思う通りに動いてくれないこともありえます。ですのでこのようなことを防ぐためには、さらに別の方法が必要です。
Delegation を使う方法
Delegation、よく「権限譲渡」と訳されますが、最初の頃は「なんじゃこれ」と思うこともあるじゃないかと思います(というか正直筆者は思いました)。そもそも iPhone アプリ開発も、最初のサンプルプロジェクトであれなんであれ、必ず AppDelegate というデリゲーションが存在するけど、なんかよく知らんけどとりあえずアプリが動いてて最初に入ってくるのがこのファイルっぽい、とだけくらいしかわからないのですね。まあ具体的には上の「循環参照、ダメ。絶対」を読めば少なくともちょっとくらいイメージがわかってこれるのではないかと思います。図にすると下記のような感じになります:
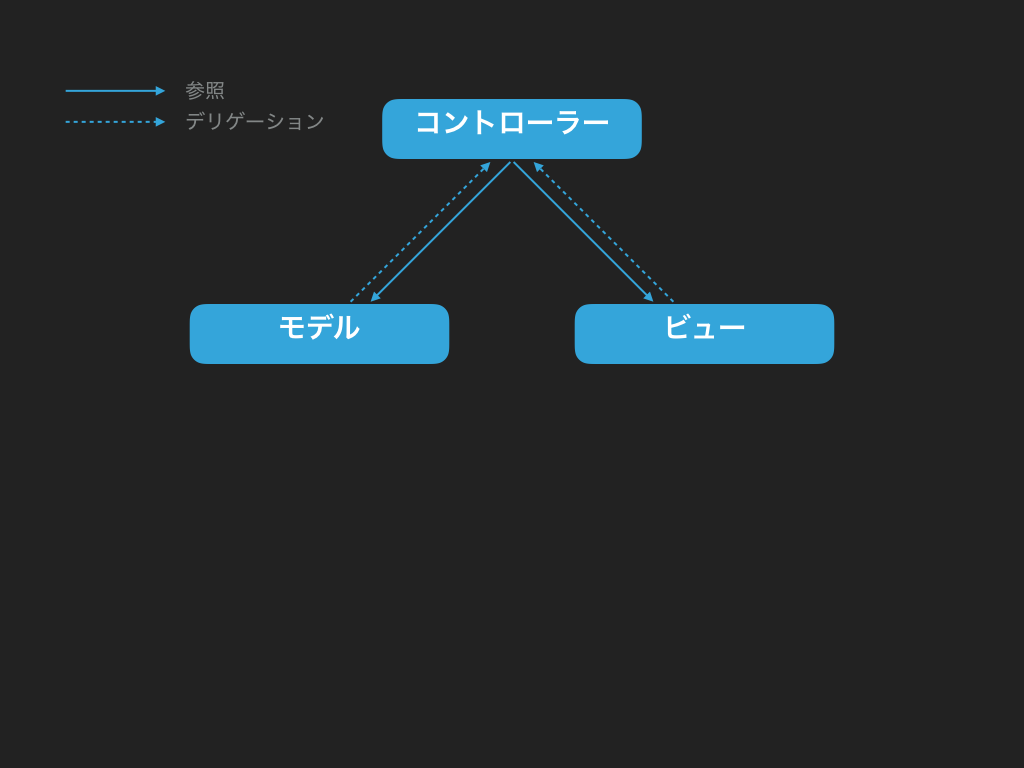
要するに、自分は具体的にどうすればいいかわからないから、わかる人に丸投げするという無責任なやり方です。例えば下記のコードを見てみましょう:
import UIKit
class ViewController: UIViewController, TestModelDelegate {
var testModel: TestModel!
var testView: TestView!
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
self.testModel = TestModel()
self.testView = TestView(frame: CGRect(origin: .zero, size: self.view.frame.size))
self.testModel.delegate = self
self.testView.label.text = self.testModel.displayedString
self.view.addSubview(self.testView)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
override func touchesEnded(touches: Set<UITouch>, withEvent event: UIEvent?) {
self.testModel.appendString("!")
}
// TestModelDelegate
func display(something: NSObject) {
self.testView.display(something)
}
}
import UIKit
protocol TestModelDelegate {
func display(something: NSObject)
}
class TestModel: NSObject {
var displayedString: String
var delegate: TestModelDelegate?
override init() {
self.displayedString = "Hello, World!"
super.init()
}
func appendString(string: String) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0)) { () -> Void in
self.displayedString += string
switch self.displayedString.characters.count {
case 0 ..< 20:
self.delegate?.display(self.displayedString)
case 20:
if let image = UIImage(named: "TestImage.png") {
self.delegate?.display(image)
}
case 21:
self.delegate?.display(true)
default:
self.displayedString = "Hello, World!"
self.delegate?.display(self.displayedString)
}
}
}
}
import UIKit
class TestView: UIView {
let label: UILabel
override init(frame: CGRect) {
self.label = UILabel(frame: CGRect(origin: .zero, size: frame.size))
super.init(frame: frame)
self.addSubview(self.label)
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
func display(something: NSObject) {
switch something {
case let newString as String:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
self.label.text = newString
})
case let newImage as UIImage:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
let imageView = UIImageView(frame: self.label.frame)
imageView.contentMode = .ScaleAspectFill
imageView.image = newImage
self.addSubview(imageView)
})
case let removeImage as Bool where removeImage:
dispatch_async(dispatch_get_main_queue(), { () -> Void in
for subview in self.subviews {
if subview is UIImageView {
subview.removeFromSuperview()
}
}
})
default:
break
}
}
}
上記のコードを見てるとわかると思いますが、NSNotificationCenter を使う方法とかなりコードが似ています。具体的に違いを見ていきましょう。
まず、TestModel のファイルに TestModelDelegate という protocol が設定されています。そして TestModel にも delegate という TestModelDelegate? のプロパティがあります。この TestModelDelegate には display(something: NSObject) というメソッドが宣言されています。
そして、TestModel の appendString に、先ほどと同じようにいろんな場合分けがなされており、処理が終わったら self.delegate を呼び出して display(something) を自分のデリゲーション先に投げます。
次に ViewController を見てみると、まず定義のところに、class ViewController: UIViewController の後ろにさらに , TestModelDelegate が追加されています。これは ViewController は TestModelDelegate プロトコルに対応しているということを宣言しています。こうすると、いきなり Xcode に怒られて、TestModelDelegate に対応してないぞ!と言われます。まあ当然ですね、この段階ではまだ TestModelDelegate の display(something: NSObject) メソッドを実装していないもん。というわけで実装します:
// TestModelDelegate
func display(something: NSObject) {
self.testView.display(something)
}
(まあ別にコメント部分は必要ないのですが一応保守するときわかりやすいようにつけておきました)
ところがこの段階ではまだ testModel のデリゲーション先が nil のままですので、self.testModel = TestModel() の後ろに、デリゲーションを自分に指定するように self.testModel.delegate = self と追記しましょう、これで TestModel から self.delegate?.display(something) が呼ばれたとき、自分の self.display(something) が呼び出されます。
ところが当然ですが、この段階ではまだ TestView の方を何もしていないので、TestView の方も見てみましょう。まずは通知を受け取ることも処理することもないので、通知登録などの文言が全くありません。次に先ほど通知を処理する needsUpdate(sender: NSNotification) のメソッドを中身そのままメソッド名だけ display(something: NSObject) に変更して、それに合わせて中の switch の部分も sender.object から something に直すだけで、NSNotificationCenter を利用した時とほぼ同じ動作の実装ができました。
このコードですと、例えば TestView の所、func display(something: NSObject) を忘れると、ViewController の display(something: NSObject) の実装で利用出来るメソッドがないと思い出させてくれるので、Delegation を利用すれば、最初の child.delegate = self とさえ書くの忘れなければ、実装し忘れというようなことは基本ありえないですので、仕様変更やメンテナンス時は NSNotificationCenter を利用する方法よりはミスが出にくいじゃないかと思います。
ただデメリットも割と目立ちます、どういうことかというとデリゲーションはやはりモデルとビューの架け橋であるコントローラーに負担をかけてしまいますので、結果的にコントローラーの肥大化、メンテナンス性の低下につながりかねない、ということです。
まとめ
以上、MVC を実現するためによく使われる 3 つの方法ですが、それぞれの利点・欠点をまとめると下記のような表になりますので、必要に応じて、最適な実装方法を検討すればいいのではないでしょうか:
| Callback | NSNotificationCenter | Delegation | |
|---|---|---|---|
| 実装がシンプル | ○ | △ | × |
| 複雑な実装に対応しやすい | × | ○ | ○ |
| 疎結合になって自由度が高い | △ | ◎ | ○ |
| コントローラーが肥大化しにくい | × | ○ | × |
| メンテ時ミスしにくい | ○ | × | ○ |
ところがここで一つ注意しなければならないことがあるのですが、今回のサンプルコードはなるべく簡単なもので示してみたかったので、モデル・ビュー・コントローラーは 1 対 1 対 1 の関係になってしまいましたが、実際のプロジェクトではそうと限りません。一つのコントローラーが複数のモデルやビューを持ったり、さらにモデルが複数の子モデル、ビューが複数の子ビューを持ったり、複数のコントローラーが同じモデルを持ったりすることも十分ありえます。そもそも「メンテナンス性」の他に「再利用性」も考えての MVC モデルですからね。例えば下記のような画像の構造があっても全然ありえます:
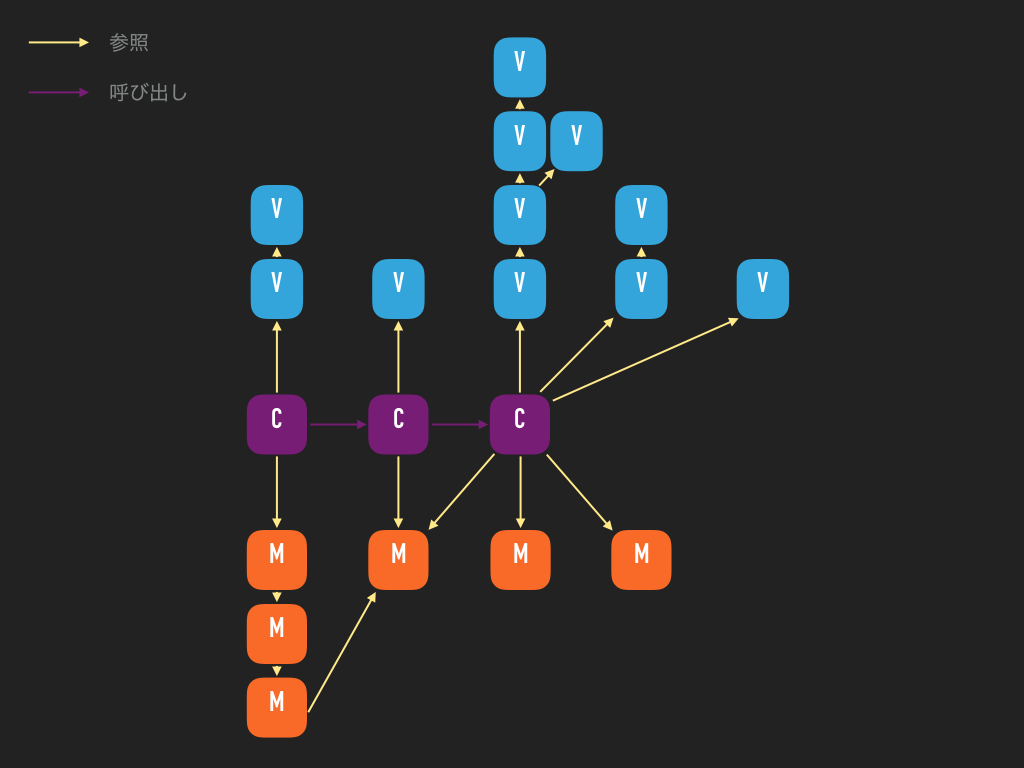
とこのように、こんな複雑な構造をしていてもおかしくありません。このようにパーツを小さく分けることによって再利用性が高まり、メンテナンス性も向上されますので、皆さんも是非 MVC パターンを活用してみてください。