はじめに
Scalaのコレクションには色々な実装が存在します。
ここでは『イミュータブル』なSeqにフォーカスをあてて、各リストの特徴をまとめていきたいと思います。以降、ミュータブル/イミュータブルの明記がない場合はイミュータブルコレクションのことを指します。
(ミュータブル編は必要性に駆られたら調べますが、多分やらない・・・)
-
ここで書くこと
- 各コレクション実装の特徴
-
ここで書かないこと
- 『Seqとは?』のようなコレクション概念
- ミュータブルコレクションに関すること
内容は公式ドキュメントに沿ってまとめています。図も公式ドキュメントから拝借したものです。
動作環境
- OS
- MacOS Catalina
- CPU
- Corei9(2.4GHz 8コア)
- メモリー
- 64GB
- Scalaバージョン
- 2.13.2
Scalaのリスト
以下の図は公式ドキュメントに使用されているものです。
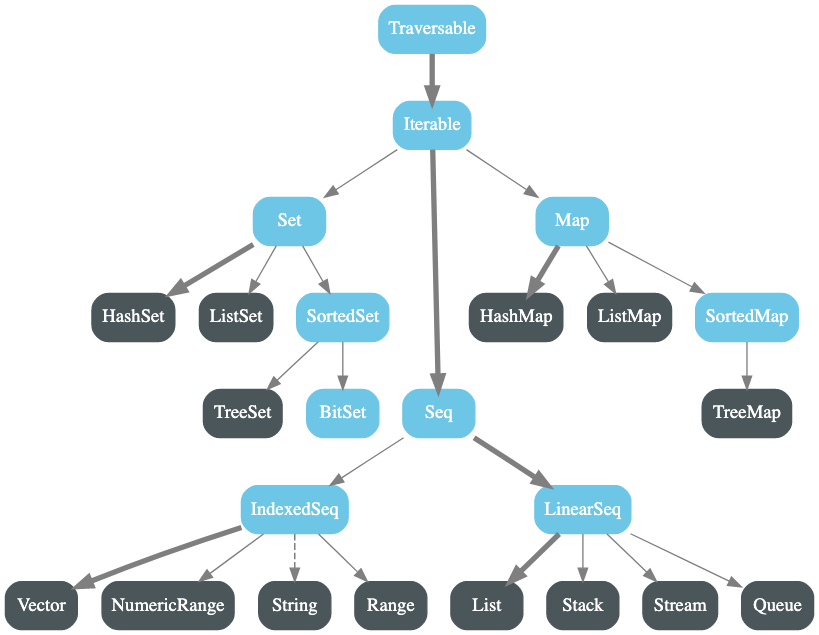
資料:https://docs.scala-lang.org/ja/overviews/collections/overview.html
上記図のSeq配下が今回の対象です。ただ、上記の図は少し古いようでScala2.13で追加されたコレクションが反映されていません。それらについても拾える範囲で拾っていきます。
Seqの特徴
Seq系は更にIndexedSeqのシリーズとLinearSeqのシリーズに分けられます。
IndexedSeq
添字付リスト。ランダムアクセスに強いデータ構造のシリーズです。
Range
Rangeの詳細
数値を扱うリストです。あまり使ったことはありません・・・
scala> 0 to 10 by 2
res3: scala.collection.immutable.Range = Range 0 to 10 by 2
scala> res3(3)
res16: Int = 6
scala> res3.head
res7: Int = 0
scala> res3.tail
res8: scala.collection.immutable.Range = Range 2 to 10 by 2
// IndexedSeqはTraversableを実装するので、foreachでデータ走査が可能
scala> res3.foreach(println _)
0
2
4
6
8
10
NumericRange
RangeはIntegerで扱える範囲の数値で構成するためのデータ構造であるのに対して、NumericRangeは数値全般に対して一般化されています。
scala> 0L to 10 by 2
res9: scala.collection.immutable.NumericRange[Long] = NumericRange 0 to 10 by 2
String
文字列 (String) は直接には列ではないが、列に変換することができ、また、文字列は全ての列演算をサポートする
Stringは本来はコレクションではないのですが、StringOpsがStringの値を受けとってコレクション相当の操作を可能にしています。StringOpsはIndexedSeqLikeというIndexedSeqのためのテンプレートを実装しており、これによってStringがIndexSeqの特性を持つことを実現しています。
scala> "Collection"
res17: String = Collection
scala> res17(4)
res18: Char = e
scala> res17.head
res19: Char = C
scala> res17.tail
res20: String = ollection
scala> res17.foreach(println(_))
C
o
l
l
e
c
t
i
o
n
Vector
ここまでリストっぽくないデータ構造ばかり登場してきましたが、ここからが本番です。
Vectorの詳細
ベクトルはどの要素の読み込みも「事実上」定数時間で行う。
JavaのArrayListのScala版です。
内部的には木構造でデータを管理しており、1つのノードは32以下の要素 or ノードを管理しています。ノードを深くするごとに32のN乗の要素を扱うことができるようになるため、浅いノードでも膨大な数の要素(2ホップで32,768要素)を扱うことができます。
IndexedSeq系のデータ構造はランダムアクセス用のデータ構造としてカテゴリされているが、Vector以外は対象データが限定されているのでランダムアクセス用途で汎用的に使用できるデータ構造となるとVector一択になる様子。
LinearSeq
線形リスト。先頭からの順次アクセスに強いデータ構造のシリーズです。
List
リストは Scala プログラミングの働き者であり続けてきたので、あえてここで語るべきことは多くない。
ということで、ScalaのSeq代表といえばListです。
特徴はというと、
リストは最初の要素とリストの残りの部分に定数時間でアクセスでき、また、新たな要素をリストの先頭に追加する定数時間の cons 演算を持つ。他の多くの演算は線形時間で行われる。
つまり、head :: tailを再帰的に実行することで構成されるデータ構造ですね。最も頻繁に使用するSeqだと思います。
Stream
Listの遅延評価版です。
ストリーム (Stream) はリストに似ているが、要素は遅延評価される。そのため、ストリームは無限の長さをもつことができる。
なお、このStreamですが、Scala2.13.0から非推奨となっています。代わりにLazyListを使用するべきとのことです。
@deprecated("Use LazyList instead of Stream", "2.13.0")
val Stream = scala.collection.immutable.Stream
LazyListオブジェクト内に定義されているconsを見てみると、パラメーターが名前渡しされているのがわかります。
object cons {
/** A lazy list consisting of a given first element and remaining elements
* @param hd The first element of the result lazy list
* @param tl The remaining elements of the result lazy list
*/
def apply[A](hd: => A, tl: => LazyList[A]): LazyList[A] = newLL(sCons(hd, tl))
}
一方、Listでは特に名前渡しもされずそのまま評価されて保持されているのがわかります。
final case class ::[B](override val head: B, private[scala] var tl: List[B]) extends List[B] {
override def tail : List[B] = tl
override def isEmpty: Boolean = false
}
Stack
機能的にリストとかぶるため、不変スタックが Scala のプログラムで使われることは稀だ: 不変スタックの push はリストの :: と同じで、pop はリストの tail と同じだ。
確かにね。公式にも『要らん子』扱いされています。
というか、Scala 2.13では公式ドキュメント内にあるサンプルコードを実行するとエラーになります...
scala> val stack = scala.collection.immutable.Stack.empty
^
error: object Stack is not a member of package scala.collection.immutable
Scala 2.13-M2時点のAPIドキュメントには以下のような記述があります。
Note: This class exists only for historical reason and as an analogue of mutable stacks. Instead of an immutable stack you can just use a list.
(注:このクラスは、歴史的な理由でのみ存在し、可変スタックの類似物として存在します。不変スタックの代わりに、リストを使用できます。)
しかし、2020/07/13時点で最新VerであるScala 2.13.3のAPIドキュメントにはStackは存在しません。
なるほど、そうですか・・・
Queue
FIFOなデータ構造ですね。FIFOを必要とする場面で使うのが適切だとは思うのですが、普通のリストっぽくheadやtailを使うこともできるし、ランダムアクセスだってできます。
scala> scala.collection.immutable.Queue[Int]()
res3: scala.collection.immutable.Queue[Int] = Queue()
scala> res3.enqueue(1)
res5: scala.collection.immutable.Queue[Int] = Queue(1)
scala> res5.enqueue(5)
res7: scala.collection.immutable.Queue[Int] = Queue(1, 5)
// 適当な数を突っ込んだQueueを用意
res17: scala.collection.immutable.Queue[Int] = Queue(1, 5, 10, 15, 20)
scala> val (el, rest) = res17.dequeue
el: Int = 1 // dequeueで取れた中身
rest: scala.collection.immutable.Queue[Int] = Queue(5, 10, 15, 20) // dequeueした結果の残り
// 適当な数を突っ込んだQueueを用意
res17: scala.collection.immutable.Queue[Int] = Queue(1, 5, 10, 15, 20)
// headで先頭を取得することもできる
scala> res17.head
res18: Int = 1
// tailで残りを取得することもできる
scala> res17.tail
res19: scala.collection.immutable.Queue[Int] = Queue(5, 10, 15, 20)
// ランダムアクセスもできる
scala> res17(4)
res21: Int = 20
// もちろんforeachもできる
scala> res17.foreach(println(_))
1
5
10
15
20
Seqの計測
ここまでSeqの特徴を見てきましたが、一般的な用途では以下を使うこととなると思います。
- ランダムアクセスあり:Vector
- ランダムアクセスなし:List
その他のコレクションは特化した機能があると同時におそらく性能を犠牲にしているのでしょう。確認してみます。
性能比較をするにあたって同一処理を100回実施した平均時間を比較します。確認に使用したコードはGitHubにアップしています。
VectorとList
Vectorはランダムアクセス用データ構造、Listはシーケンシャルアクセス用データ構造です。
データ追加、データアクセスの観点で性能比較してみます。
データ追加
// 以下の処理をVectorとListに対して実施する
// sizeで指定したデータ数のリストを作成する
def addProc(seq: Seq[Int])(size: Int): Seq[Int] = {
var s = seq
for (_ <- 1 to size) {
s = s.+:(randomInt(1000))
}
s
}
計測結果は以下のとおりです。
- 試行回数100回の平均時間
| 件数 | List | Vector(2.13.2) | Vector(2.13.1) |
|---|---|---|---|
| 1,000,000件 | 33 ミリ秒/件 | 51 ミリ秒/件 | 155 ミリ秒/件 |
| 10,000,000件 | 314 ミリ秒/件 | 444 ミリ秒/件 | 1,355 ミリ秒/件 |
やはり「データを追加する」という観点ではListの方が1.5倍ほど早いことがわかります。ただ、リストは読み出ししてナンボなので、データ追加の性能については頭の片隅に留めておく程度でOKだと思います。
なお、Scala2.13.1だと5倍ほどの性能差が発生します(別件でバージョン変更してて、バージョン戻すの忘れててたまたま発見した)。Scala2.13.1(おそらく2.13.0も)を使用する場合はVectorに大量データの追加を行う場合は少し危険です。
データアクセス
ランダムアクセス
// 以下の処理をVectorとListに対して実施する
// seqには検証したいだけのデータ件数が格納されたVectorまたはListを渡す
def randomSumProc(seq: Seq[Int]): Int = {
var sum = 0
for (i <- 0 until seq.size) {
sum = sum + seq(i)
}
sum
}
計測結果は以下のとおりです。
- 試行回数100回の平均時間
| 件数 | List | Vector(2.13.2) | Vector(2.13.1) |
|---|---|---|---|
| 10,000件 | 96 ミリ秒/件 | 0 ミリ秒/件 | 0 ミリ秒/件 |
| 100,000件 | 11,547 ミリ秒/件 | 3 ミリ秒/件 | 2 ミリ秒/件 |
顕著な差が出ました。『ランダムアクセスするならVectorの方が良い』ではなく、『Listでランダムアクセスを行ってはならない』ぐらいの性能差です。
今回の計測を行うにあたって、Listの性能が悪すぎて待ってられないので、100,000件の計測については10回の計測の平均時間を測っています。ただし、Scala2.13.2とScala2.13.1での目立った性能差はありませんでした。
シーケンシャルアクセス
// 以下の処理をVectorとListに対して実施する
// seqには検証したいだけのデータ件数が格納されたVectorまたはListを渡す
def sequentialSumProc(seq: Seq[Int]): Int = {
def loop(list: Seq[Int], sum: Int): Int = {
// `head :: tail` や `elm :: Nil` のような書き方をすると、Vectorを渡した時に例外が発生する
list match {
case _ if list.isEmpty => sum
case _ => loop(list.tail, sum + list.head)
}
}
loop(seq, 0)
}
計測結果は以下のとおりです。
- 試行回数100回の平均時間
| 件数 | List | Vector(2.13.2) | Vector(2.13.1) |
|---|---|---|---|
| 10,000件 | 0 ミリ秒/件 | 2 ミリ秒/件 | 1 ミリ秒/件 |
| 100,000件 | 3 ミリ秒/件 | 8 ミリ秒/件 | 20 ミリ秒/件 |
| 1,000,000件 | 24 ミリ秒/件 | 59 ミリ秒/件 | 186 ミリ秒/件 |
どちらも100,000件程度では瞬間で終わってしまうので、1,000,000件まで試しています。シーケンシャルアクセスではListの方が2.5程度速いことがわかりましたが、『Vectorでシーケンシャルアクセスを行ってはならない』というレベルではありません。特に、件数が10,000件を下回るケース(大半がそうだと思いますが)では無視できるレベルの性能差だと思います。
ただし、こちらもScala2.13.2とScala2.13.1でVectorに顕著な性能差があるので要注意です。
ListとLazyList
Streamは非推奨なので考慮しません。LazyListに焦点をあてます。
LazyListは無限のデータを扱えるので、同じ程度の性能であればできることのLazyListの方をメインで使用しても良いのでは?性能比較してみます。
データ追加
データ追加に使用する処理はVectorとListを比較する際に使用した処理と同一内容です。
- 試行回数100回の平均時間
| 件数 | List | LazyList |
|---|---|---|
| 1,000,000件 | 32 ミリ秒/件 | 32 ミリ秒/件 |
| 10,000,000件 | 367 ミリ秒/件 | 441 ミリ秒/件 |
データ件数が1,000,000件程度だと性能差はないようです。10,000,000件の追加となると少し性能差が見られましたが、そんな大量のデータを扱うこともレアケースなので『追加については性能差はほぼない』と考えても差し支えなさそうです。
データアクセス
ランダムアクセス
こちらの処理もVectorとListを比較する際に使用した処理と同一内容です。
計測結果は以下のとおりです。
- 試行回数100回の平均時間
| 件数 | List | LazyList |
|---|---|---|
| 10,000件 | 98 ミリ秒/件 | 253 ミリ秒/件 |
| 100,000件 | 11,407 ミリ秒/件 | 27,073 ミリ秒/件 |
VectorとListの比較で『Listでランダムアクセスを行ってはならない』という結論が出たはずですが、LazyListはそんなListも目じゃないくらい遅いです。
シーケンシャルアクセス
こちらの処理もVectorとListを比較する際に使用した処理と同一内容です。
計測結果は以下のとおりです。
- 試行回数100回の平均時間
| 件数 | List | LazyList |
|---|---|---|
| 10,000件 | 0 ミリ秒/件 | 0 ミリ秒/件 |
| 100,000件 | 1 ミリ秒/件 | 1 ミリ秒/件 |
| 1,000,000件 | 16 ミリ秒/件 | 18 ミリ秒/件 |
シーケンシャルアクセス用途で用いるならどちらを使っても問題なさそうですね。
結論
ここまでの確認結果に則って「どのような時にどのようなコレクションを使用すべきか」を以下に記しています。
Seq系コレクションの取捨選択
Range、NumericRange、String、Stack、Queueはいずれも扱うデータまたは利用シーンが限定的なコレクションなので、汎用的なリストであるVector、List、LazyList/Streamについて考えます。
個別の利用シーンにハマらない限りはRangeなどを使う必要はないのではないかと思います。
ランダムアクセスしたい!
Vector一択です。Listで大量データのランダムアクセスしたら死にます。LazyListでランダムアクセスしたらもっと死にます。
シーケンシャルアクセスしたい!
シーケンシャルアクセスをしたいのであれば、その意図が明確になるListを使用するのが望ましいと思います。ただ、大量データでない限りはそれほど神経質にならなくても良いと思います。ただし、大量データを何度もmapさせて大量の一時リストを作ってしまわざるをえない処理の場合は少し考えた方が良いかもしれません。塵も積もれば遅くなるので。
遅延リストを使いたい!
LazyList一択です。Streamは非推奨になっているようなので、今後は使用しない方が良いのかな。
その他
Scala2.13.2でVectorのパフォーマンスが向上しているようなので、古いバージョンを使用していてVectorの性能に悩まされているのであればScalaのバージョンを上げることを検討した方が良いかもしれません。