はじめに
Scalaのコレクションには色々な実装が存在します。
ここでは『イミュータブル』なMapにフォーカスをあてて、各マップの特徴をまとめていきたいと思います。以降、ミュータブル/イミュータブルの明記がない場合はイミュータブルコレクションのことを指します。
(ミュータブル編は必要性に駆られたら調べますが、多分やらない・・・)
-
ここで書くこと
- 各コレクション実装の特徴
-
ここで書かないこと
- 『Mapとは?』のようなコレクション概念
- ミュータブルコレクションに関すること
内容は公式ドキュメントに沿ってまとめています。図も公式ドキュメントから拝借したものです。
動作環境
- OS
- MacOS Catalina
- CPU
- Corei9(2.4GHz 8コア)
- メモリー
- 64GB
- Scalaバージョン
- 2.13.2
Scalaのマップ
以下の図は公式ドキュメントに使用されているものです。
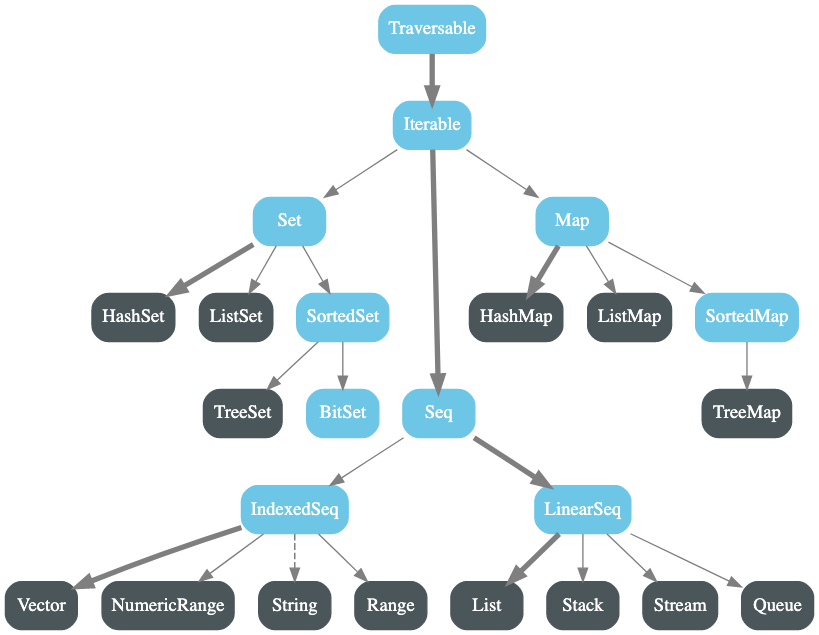
資料:https://docs.scala-lang.org/ja/overviews/collections/overview.html
上記図のMap配下が今回の対象です。ただ、上記の図は少し古いようでScala2.13で追加されたコレクションが反映されていません。それらについても拾える範囲で拾っていきます。
Mapの特徴
Mapには5種類の実装が用意されているのですが、違いについてはコレクションの説明ドキュメントには記載されていません。
HashMap
HashMapはキーのハッシュ値を求めてそれを内部的なキーとしてデータを管理するデータ構造です。Mapを使うとなると、基本的にはこれを使うことになると思います。
これ以外のMapの実装は何らかの「順番」をキープしながらデータを管理する構造となっています。
// Mapにデータを格納していく
scala> res7.updated("qwer", 1)
res13: scala.collection.immutable.HashMap[String,Int] = HashMap(qwer -> 1)
// このデータはたまたま登録順に格納された
scala> res13.updated("asdf", 100)
res14: scala.collection.immutable.HashMap[String,Int] = HashMap(qwer -> 1, asdf -> 100)
// このデータは2番目に格納されているように見える
scala> res14.updated("uiop", 10)
res15: scala.collection.immutable.HashMap[String,Int] = HashMap(qwer -> 1, uiop -> 10, asdf -> 100)
// 同上
scala> res15.updated("fghj", 10)
res16: scala.collection.immutable.HashMap[String,Int] = HashMap(qwer -> 1, fghj -> 10, uiop -> 10, asdf -> 100)
// 出力しても登録順にはデータは読み取られない
scala> res16.foreach(println(_))
(qwer,1)
(fghj,10)
(uiop,10)
(asdf,100)
// 別の取得方法を試してみてもやはり登録順ではない
scala> res16.tail.head
res20: (String, Int) = (fghj,10)
ListMap
内部的にデータの登録順を保持していてくれるデータ構造です。
指定されたキーに一致する値を取得するためにデータ内部を線形に走査してデータアクセスすることとなります。最後に登録したデータが最初にヒットするように格納されているので、最初に格納したキーにヒットするのは一番最後です。
データをMapで管理しつつ、アクセス回数に偏りがある(かつどのキーへのアクセスが多いかを把握できている)場合で使用すると有効です。
ListMapのScaladocには以下のようにあります。
this collection suitable only for a small number of elements.
(このコレクションは少数の要素にしか適していません。)
後半で性能比較を行っていますが、ListMapで大量データを扱おうとするとめちゃくちゃ遅いです。
// HashMapの時と同じ順番で同じ内容を登録していく
scala> res26.updated("qwer", 1)
res27: scala.collection.immutable.ListMap[String,Int] = ListMap(qwer -> 1)
scala> res27.updated("asdf", 100)
res28: scala.collection.immutable.ListMap[String,Int] = ListMap(qwer -> 1, asdf -> 100)
scala> res28.updated("uiop", 10)
res29: scala.collection.immutable.ListMap[String,Int] = ListMap(qwer -> 1, asdf -> 100, uiop -> 10)
scala> res29.updated("fghj", 10)
res30: scala.collection.immutable.ListMap[String,Int] = ListMap(qwer -> 1, asdf -> 100, uiop -> 10, fghj -> 10)
// 登録した順番がキープされている
scala> res30.foreach(println(_))
(qwer,1)
(asdf,100)
(uiop,10)
(fghj,10)
// データを更新
scala> res30.updated("asdf", 500)
res32: scala.collection.immutable.ListMap[String,Int] = ListMap(qwer -> 1, asdf -> 500, uiop -> 10, fghj -> 10)
// キーが同一であれば値が書き換わっても順番はキープされる
scala> res32.foreach(println(_))
(qwer,1)
(asdf,500)
(uiop,10)
(fghj,10)
SortedMap
格納されているデータが自動的にソートされるデータ構造です。
TreeMap
赤黒木というデータ構造でMapを実装したものになります。赤黒木をWikipediaで調べてみると以下のように説明されています。
赤黒木は、探索、挿入、削除などの操作における最悪時間計算量がO(log n)(nはツリーの要素数)と短く、複雑ではあるが実用的なデータ構造として知られている。
なるほど???
よくわからんのでScaladocを見てみます。
This class is optimal when range queries will be performed, or when traversal in order of an ordering is desired.
If you only need key lookups, and don't care in which order key-values are traversed in, consider using * [[scala.collection.immutable.HashMap]], which will generally have better performance. If you need insertion order, consider a * [[scala.collection.immutable.SeqMap]], which does not need to have an ordering supplied.
(このクラスは、範囲の問い合わせが実行される場合や、順序を指定してトラバーサルしたい場合に最適です。
キー検索だけが必要で、キー値がどの順番で走査されるかを気にしない場合は、[[scala.collection.immutable.HashMap]]の使用を検討してください。挿入順が必要な場合は、[[scala.collection.immutable.SeqMap]]を検討してください。)
SeqMapはScala2.13で追加されたコレクションのようです。Scala2.13のRelease Noteに「New abstract collection type SeqMap」とあります。SeqMapは後で触れるとして、TreeMapの特徴をHashMapやListMapの時と同じ様に確認したところ、キーが自動的にソートされていることがわかります。
scala> res4.updated("qwer", 1)
res5: scala.collection.immutable.TreeMap[String,Int] = TreeMap(qwer -> 1)
scala> res5.updated("asdf", 100)
res6: scala.collection.immutable.TreeMap[String,Int] = TreeMap(asdf -> 100, qwer -> 1)
scala> res6.updated("uiop", 10)
res7: scala.collection.immutable.TreeMap[String,Int] = TreeMap(asdf -> 100, qwer -> 1, uiop -> 10)
scala> res7.updated("fghj", 10)
res8: scala.collection.immutable.TreeMap[String,Int] = TreeMap(asdf -> 100, fghj -> 10, qwer -> 1, uiop -> 10)
// 自動的にキーがソートされている
scala> res8.foreach(println(_))
(asdf,100)
(fghj,10)
(qwer,1)
(uiop,10)
SeqMap
SeqMapはListMap等の順序を持つMapのための汎用トレイトです。ListMapの実装を見てみると、以下のようにSeqMapを実装していることがわかります。
sealed class ListMap[K, +V]
extends AbstractMap[K, V]
with SeqMap[K, V]
with ...
具象クラスではないので使い方等は省略します。
ところで、先ほどのRelease Noteの「New abstract collection type SeqMap」の項目を見てみると以下の1文があります。
Implementations: VectorMap (#6854) and TreeSeqMap (#7146) (in addition to the already existing ListMap).
どうやらVectorMapとTreeSeqMapというMapがScala2.13で追加されているようです。
VectorMap
基本的な動作はListMapと同じのようですが、内部的な挙動が異なるようです。Scaladocを見てみます。
Unlike
ListMap,VectorMaphas amortized effectively constant lookup at the expense of using extra memory and generally lower performance for other operations
ListMapは検索対象のキーが挿入された順番によってパフォーマンスが変動するデータ構造でしたが、VectorMapではデータの並び順をキープしつつもキー検索のパフォーマンスを一定に保つようになっているようです。ただし、実現のためにキー検索以外の操作とメモリー効率を犠牲にしているようです。
TreeSeqMap
こちらも順序を意識したMapを扱うための実装です。Scaladocから見て取れる特徴は以下のとおりです。
- ソート順に「挿入順」「変更順」を指定することができる
- 指定した順序で
Mapをソートする
実際に動かしてみます。
ソート順も指定できるようですが、デフォルトのまま試してみます。
scala> res4.updated("qwer", 1)
res5: scala.collection.immutable.TreeSeqMap[String,Int] = TreeSeqMap(qwer -> 1)
scala> res5.updated("asdf", 100)
res6: scala.collection.immutable.TreeSeqMap[String,Int] = TreeSeqMap(qwer -> 1, asdf -> 100)
scala> res6.updated("uiop", 10)
res7: scala.collection.immutable.TreeSeqMap[String,Int] = TreeSeqMap(qwer -> 1, asdf -> 100, uiop -> 10)
scala> res7.updated("fghj", 10)
res8: scala.collection.immutable.TreeSeqMap[String,Int] = TreeSeqMap(qwer -> 1, asdf -> 100, uiop -> 10, fghj -> 10)
scala> res8.foreach(println(_))
(qwer,1)
(asdf,100)
(uiop,10)
(fghj,10)
ListMapと同様の並び順で格納されているようです。
Mapの計測
ここまでMapの特徴を見てきましたが、一般的な用途ではHashMapを使うこととなると思います。
その他のコレクションは特化した機能があると同時におそらく性能を犠牲にしているのでしょう。確認してみます。
性能比較をするにあたって同一処理を100回実施した平均時間を比較します。確認に使用したコードはGitHubにアップしています。
HashMap、ListMap、TreeMap
データ追加
// 以下の処理をHashMap、ListMap、TreeMapに対して実施する
// sizeで指定したデータ数のMapを作成する
def addHashProc(map: Map[Int, Int])(size: Int): Map[Int, Int] = {
var m = map
for (i <- 1 to size) {
m = m.updated(i, randomInt(1000))
}
m
}
計測結果は以下のとおりです。
- 10,000件は試行回数100回の平均時間
- 100,000件は試行回数10回の平均時間
| 件数 | HashMap | ListMap | TreeMap |
|---|---|---|---|
| 10,000件 | 2 ミリ秒/件 | 143 ミリ秒/件 | 2 ミリ秒/件 |
| 100,000件 | 19 ミリ秒/件 | 15,498 ミリ秒/件 | 23 ミリ秒/件 |
ListMapが圧倒的に遅いです。今回の計測を行うにあたって、ListMapの性能が悪すぎて待ってられないので、100,000件の計測については10回の計測の平均時間を測っています。
データを作るだけであれば、HashMapとTreeMapはそれほど性能優位はなさそうです。
キーアクセス
最初に格納したキー、最後に格納したキー、ちょうど中間のタイミングで格納したキーを指定してデータを取る際のスピードを確認します。
// 以下の処理をHashMap、ListMap、TreeMapに対して実施する
// keyで指定したデータにアクセスする
def keyAccess(map: Map[Int, Int])(key: Int): Int = {
var sum = 0
for (i <- 1 until map.size) {
sum = sum + map(key)
}
sum
}
計測結果は以下のとおりです。
- いずれも試行回数100回の平均時間
- 最初に登録した要素のキーを指定してアクセス
| 件数 | HashMap | ListMap | TreeMap |
|---|---|---|---|
| 10,000件 | 0 ミリ秒/件 | 270 ミリ秒/件 | 0 ミリ秒/件 |
| 100,000件 | 2 ミリ秒/件 | - | 2 ミリ秒/件 |
| 1,000,000件 | 17 ミリ秒/件 | - | 34 ミリ秒/件 |
- 中間に登録した要素のキーを指定してアクセス
| 件数 | HashMap | ListMap | TreeMap |
|---|---|---|---|
| 10,000件 | 0 ミリ秒/件 | 114 ミリ秒/件 | 0 ミリ秒/件 |
| 100,000件 | 2 ミリ秒/件 | - | 3 ミリ秒/件 |
| 1,000,000件 | 21 ミリ秒/件 | - | 30 ミリ秒/件 |
- 最後に登録した要素のキーを指定してアクセス
| 件数 | HashMap | ListMap | TreeMap |
|---|---|---|---|
| 10,000件 | 0 ミリ秒/件 | 0 ミリ秒/件 | 0 ミリ秒/件 |
| 100,000件 | 2 ミリ秒/件 | - | 5 ミリ秒/件 |
| 1,000,000件 | 18 ミリ秒/件 | - | 66 ミリ秒/件 |
ListMapは『どのタイミングで追加したキーにアクセスするか』によって顕著な性能差が見られます。その他のMapは件数が少ないうちは差が見られません。
上述のデータ追加時にも明らかになっていたとおり、ListMap用の大量データを作成するのにめちゃくちゃ時間を要するので途中で退場してもらっています。
件数が多くなるにつれてHashMapの方が性能的に優位であることがわかりました。しかし、TreeMapも十分に速いですね。
全走査
foreachでブン回します。
// 以下の処理をHashMap、ListMap、TreeMapに対して実施する
def sequentialAccess(map: Map[Int, Int]): Int = {
var sum = 0
map.foreach{
elm =>
sum = sum + elm._2
}
sum
}
計測結果は以下のとおりです。
- 試行回数100回の平均時間
| 件数 | HashMap | ListMap | TreeMap |
|---|---|---|---|
| 100,000件 | 1 ミリ秒/件 | 2 ミリ秒/件 | 0 ミリ秒/件 |
| 500,000件 | 4 ミリ秒/件 | 10 ミリ秒/件 | 3 ミリ秒/件 |
| 1,000,000件 | 13 ミリ秒/件 | - | 7 ミリ秒/件 |
| 10,000,000件 | 103 ミリ秒/件 | - | 148 ミリ秒/件 |
やはりListMapが目立って遅いです。ここでもListMapは途中で退場してもらっています。
1,000,000件ではTreeMap、10,000,000件ではTreeMapの方が速いという結果になりました。100,000件、500,000件の時もTreeMapの方が速かったので、『一定件数まではTreeMapの方が速いけど、それ以上はHashMapの方が速い』と言えそうです。
(100,000,000件も試そうとしましたが、OutOfMemorryErrorが発生したので断念しました。刻むのも面倒だったので...)
ListMap、VectorMap、TreeSeqMap
VectorMapはListMapを性能向上版とのことなので性能差を比較してみます。
また、ソート順を指定しないTreeSeqMapはListMapと同じ順番でデータが格納されていました。合わせて性能比較してみます。
データ追加・キーアクセス・全走査
- 試行回数100回の平均時間
- データ追加
| 件数 | ListMap | VectorMap | TreeSeqMap |
|---|---|---|---|
| 100,000件 | 18,910 ミリ秒/件 | 40 ミリ秒/件 | 41 ミリ秒/件 |
| 1,000,000件 | - | 546 ミリ秒/件 | 570 ミリ秒/件 |
- いずれも試行回数100回の平均時間
- 最初に登録した要素のキーを指定してアクセス
| 件数 | ListMap | VectorMap | TreeSeqMap |
|---|---|---|---|
| 100,000件 | 30,827 ミリ秒/件 | 2 ミリ秒/件 | 1 ミリ秒/件 |
| 1,000,000件 | - | 19 ミリ秒/件 | 19 ミリ秒/件 |
- 中間に登録した要素のキーを指定してアクセス
| 件数 | ListMap | VectorMap | TreeSeqMap |
|---|---|---|---|
| 100,000件 | 13,591 ミリ秒/件 | 2 ミリ秒/件 | 2 ミリ秒/件 |
| 1,000,000件 | - | 20 ミリ秒/件 | 19 ミリ秒/件 |
- 最後に登録した要素のキーを指定してアクセス
| 件数 | ListMap | VectorMap | TreeSeqMap |
|---|---|---|---|
| 100,000件 | 1 ミリ秒/件 | 2 ミリ秒/件 | 2 ミリ秒/件 |
| 1,000,000件 | - | 19 ミリ秒/件 | 19 ミリ秒/件 |
- シーケンシャルアクセス
| 件数 | ListMap | VectorMap | TreeSeqMap |
|---|---|---|---|
| 100,000件 | 1 ミリ秒/件 | 6 ミリ秒/件 | 6 ミリ秒/件 |
| 1,000,000件 | - | 143 ミリ秒/件 | 144 ミリ秒/件 |
VectorMapもTreeSeqMapも、ListMapとは比にならないくらい速いです。この節のテーマはListMapとの比較なのですが、例によってListMapは遅いので、VectorMapもTreeSeqMapについて1,000,000件の性能計測も行っています。
シーケンシャルアクセスに関してはListMapの方が速いという結果が出ましたが、その他のアクセスについてはVectorMap、TreeSeqMapが優位という結果になりました(ただし、最後に登録した要素へのキーアクセスはListMap優位です)。VectorMapとTreeSeqMapについては性能差が無いように見えます。
結論
ここまでの確認結果に則って「どのような時にどのようなコレクションを使用すべきか」を以下に記しています。
迷ったら
HashMapを使えば良いです。データ追加もデータ取得も爆速で実行してくれます。
キーの登録順をキープさせたい!
VectorMapかListMapを使用することとなります。
特にListMapは件数が多くなってくると登録すら非常に遅くなってくるので、件数が少ない場合にのみ有効な選択です。VectorMapはListMapの性能問題を解決してくれますが、消費メモリーを犠牲にしているとのことなので『件数が多い場合はVectorMap、件数が少ない場合はListMap』という判断が有効かもしれません。
あとは、TreeSeqMapも登録順をキープすることができるようなので、こちらも選択肢になるかもしれません。
キーの並び順をソートさせたい!
TreeMapかTreeSeqMapを使用することとなります。
TreeSeqMapの方が少し複雑なことができますが、そもそもMapのキーをソートさせたい時ってどういう時なんでしょうね?そういうシチュエーションに出会ったことがありません...