はじめに
Scalaのコレクションには色々な実装が存在します。
ここでは『イミュータブル』なSetにフォーカスをあてて、各マップの特徴をまとめていきたいと思います。以降、ミュータブル/イミュータブルの明記がない場合はイミュータブルコレクションのことを指します。
(ミュータブル編は必要性に駆られたら調べますが、多分やらない・・・)
-
ここで書くこと
- 各コレクション実装の特徴
-
ここで書かないこと
- 『Setとは?』のようなコレクション概念
- ミュータブルコレクションに関すること
内容は公式ドキュメントに沿ってまとめています。図も公式ドキュメントから拝借したものです。
動作環境
- OS
- MacOS Catalina
- CPU
- Corei9(2.4GHz 8コア)
- メモリー
- 64GB
- Scalaバージョン
- 2.13.2
Scalaのマップ
以下の図は公式ドキュメントに使用されているものです。
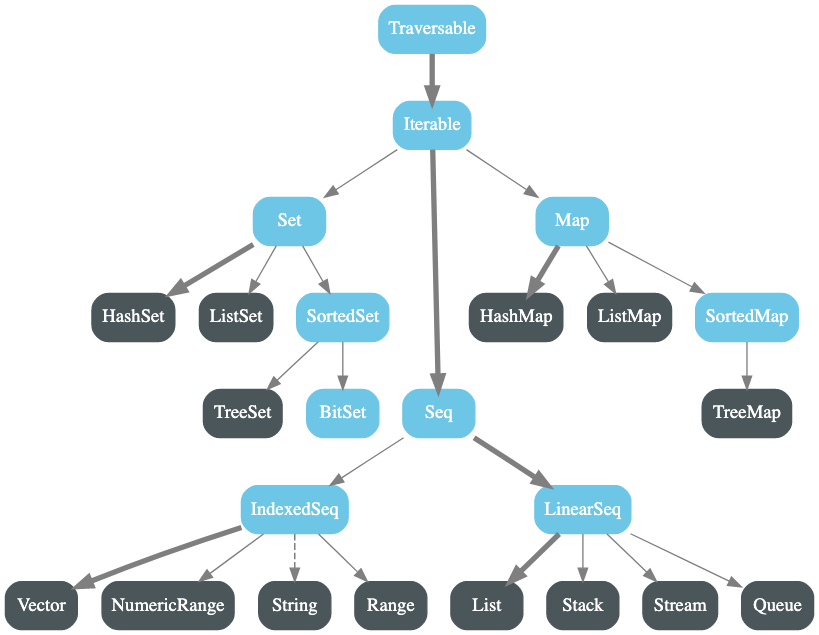
資料:https://docs.scala-lang.org/ja/overviews/collections/overview.html
上記図のMap配下が今回の対象です。ただ、上記の図は少し古いようでScala2.13で追加されたコレクションが反映されていません。それらについても拾える範囲で拾っていきます。
Setの特徴
Setには4種類の実装が用意されています。
HashSet
HashSetは値のハッシュ値を求めてそれをArrayで管理するデータ構造です。Setを使うとなると、基本的にはこれを使うことになると思います。
これ以外のSetの実装は何らかの「順番」をキープしながらデータを管理する構造となっています。
// Setにデータを格納していく
scala> res0 + "qwer"
res9: scala.collection.immutable.HashSet[String] = HashSet(qwer)
// このデータはたまたま登録順に格納された
scala> res9 + "asdf"
res10: scala.collection.immutable.HashSet[String] = HashSet(qwer, asdf)
// このデータは2番目に格納されているように見える
scala> res10 + "uiop"
res11: scala.collection.immutable.HashSet[String] = HashSet(qwer, uiop, asdf)
// 同上
scala> res11 + "fghj"
res12: scala.collection.immutable.HashSet[String] = HashSet(qwer, fghj, uiop, asdf)
// 出力しても登録順にはデータは読み取られない
scala> res12.foreach(println(_))
qwer
fghj
uiop
asdf
// 別の取得方法を試してみてもやはり登録順ではない
scala> res12.tail.head
res16: String = fghj
ListSet
ListMapのSet版です。ListSetのScaladocにもListMapと同様のコメントが書かれています。
this collection suitable only for a small number of elements.
(このコレクションは少数の要素にしか適していません。)
// HashSetの時と同じ順番で同じ内容を登録していく
scala> res17 + "qwer"
res18: scala.collection.immutable.ListSet[String] = ListSet(qwer)
scala> res18 + "asdf"
res19: scala.collection.immutable.ListSet[String] = ListSet(qwer, asdf)
scala> res19 + "uiop"
res20: scala.collection.immutable.ListSet[String] = ListSet(qwer, asdf, uiop)
scala> res20 + "fghj"
res21: scala.collection.immutable.ListSet[String] = ListSet(qwer, asdf, uiop, fghj)
// 登録した順番がキープされている
scala> res21.foreach(println(_))
qwer
asdf
uiop
fghj
SortedSet
ドキュメントに以下のように説明されています。
整列済み集合は (SortedSet) は (集合の作成時に指定された) 任意の順序で要素を (iterator や foreach を使って) 返す事ができる集合
TreeSet
TreeMapと同様に内部的に赤黒木を使っているようです。
こちらはTreeMapとは違って、単純にオブジェクトを作ろうとしたら失敗します。ソート順を指定するためのimplicitなオブジェクトが必要となります。
scala> new TreeSet
^
error: diverging implicit expansion for type Ordering[A]
starting with method Tuple9 in object Ordering
// Stringの降順になるようにソート順を指定
scala> implicit val myOrdering = Ordering.fromLessThan[String](_ > _)
myOrdering: scala.math.Ordering[String] = scala.math.Ordering$$anon$4@6f939588
scala> new TreeSet
res24: scala.collection.immutable.TreeSet[String] = TreeSet()
それでは動作を確認してみます。
// HashSetの時と同じ順番で同じ内容を登録していく
scala> res24 + "qwer"
res25: scala.collection.immutable.TreeSet[String] = TreeSet(qwer)
scala> res25 + "asdf"
res26: scala.collection.immutable.TreeSet[String] = TreeSet(qwer, asdf)
scala> res26 + "uiop"
res27: scala.collection.immutable.TreeSet[String] = TreeSet(uiop, qwer, asdf)
scala> res27 + "fghj"
res28: scala.collection.immutable.TreeSet[String] = TreeSet(uiop, qwer, fghj, asdf)
// 指定したソート順のとおりにソートされている
scala> res28.foreach(println(_))
uiop
qwer
fghj
asdf
BitSet
BitSetは非負整数専用のSetです。
内部ではLongの配列を設けておき、デフォルトでは全要素に0となっています。SetにSetに含める数値については1を立てることで対象の数値を含むか否かを管理しています。
BitSet クラスは、内部で Long の配列を用いている。最初の Long は第0 〜 63 の要素を受け持ち、次のは第64 〜 127 の要素という具合だ。
数値を対象とし、かつ最大値が小さい場合に性能的に優位となるようです。
たくさんの小さい要素を含む場合、ビット集合は他の集合に比べてコンパクトである。ビット集合のもう一つの利点は contains を使った所属判定や、+= や -= を使った要素の追加や削除が非常に効率的であることだ。
// これまでのコレクションは最初にnewしていたけど、BitSetはクラスが用意されていないのでnewできない
scala> new BitSet
^
error: class BitSet is abstract; cannot be instantiated
// その代わりBitSetオブジェクトを使ってインスタンスを作ることができる
scala> BitSet.empty
res37: scala.collection.immutable.BitSet = BitSet()
scala> res37 + 5
res39: scala.collection.immutable.BitSet = BitSet(5)
scala> res39 + 1
res40: scala.collection.immutable.BitSet = BitSet(1, 5)
scala> res40 + 100
res41: scala.collection.immutable.BitSet = BitSet(1, 5, 100)
scala> res41 + 20
res42: scala.collection.immutable.BitSet = BitSet(1, 5, 20, 100)
// 予め用意された配列に0/1を立てるカタチで管理されているので、ある意味最初からソートされている
scala> res42.foreach(println(_))
1
5
20
100
Setの計測
ここまでSetの特徴を見てきましたが、一般的な用途ではHashSetを使うこととなると思います。
その他のコレクションは特化した機能があると同時におそらく性能を犠牲にしているのでしょう。確認してみます。
性能比較をするにあたって同一処理を100回実施した平均時間を比較します。確認に使用したコードはGitHubにアップしています。
HashSet、ListSet、TreeSet、BitSet
データ追加
// 以下の処理をHashSet、ListSet、TreeSet、BitSetに対して実施する
// sizeで指定したデータ数のSetを作成する
def addSetProc(set: Set[Int])(size: Int): Set[Int] = {
var s = set
for (i <- 1 to size) {
s = s.+(i)
}
s
}
計測結果は以下のとおりです。
- 10,000件は試行回数100回の平均時間
- 100,000件は試行回数10回の平均時間
| 件数 | HashSet | ListSet | TreeSet | BitSet |
|---|---|---|---|---|
| 10,000件 | 2 ミリ秒/件 | 98 ミリ秒/件 | 2 ミリ秒/件 | 1 ミリ秒/件 |
| 100,000件 | 21 ミリ秒/件 | 10,954 ミリ秒/件 | 24 ミリ秒/件 | 54 ミリ秒/件 |
ListSetが圧倒的に遅いです。
今回の計測を行うにあたって、ListSetの性能が悪すぎて待ってられないので、100,000件の計測については10回の計測の平均時間を測っています。BitSetもなかなか速いのですが、HashSetとTreeSetには劣るようです。
データを作るだけであれば、HashSetとTreeSetはそれほど性能優位はなさそうです。
データアクセス
最初に格納した要素、最後に格納した要素、ちょうど中間のタイミングで格納した要素を指定してデータを取る際のスピードを確認します。
// SeqやMapのようにインデックスやキーを指定することはできないので、要素を含むか否かの確認をすることでデータアクセスの代わりとする
def dataAccess(set: Set[Int])(target: Int): Int = {
var sum = 0
for (i <- 1 until set.size) {
// データの有無を確認した上で加算する
sum = sum + (if (set.contains(target)) target else 0)
}
sum
}
計測結果は以下のとおりです。
- いずれも試行回数100回の平均時間
- 最初に登録した要素を指定してアクセス
| 件数 | HashSet | ListSet | TreeSet | BitSet |
|---|---|---|---|---|
| 10,000件 | 0 ミリ秒/件 | 206 ミリ秒/件 | 0 ミリ秒/件 | 0 ミリ秒/件 |
| 100,000件 | 1 ミリ秒/件 | - | 3 ミリ秒/件 | 1 ミリ秒/件 |
- 中間に登録した要素を指定してアクセス
| 件数 | HashSet | ListSet | TreeSet | BitSet |
|---|---|---|---|---|
| 10,000件 | 0 ミリ秒/件 | 95 ミリ秒/件 | 0 ミリ秒/件 | 0 ミリ秒/件 |
| 100,000件 | 1 ミリ秒/件 | - | 3 ミリ秒/件 | 1 ミリ秒/件 |
- 最後に登録した要素を指定してアクセス
| 件数 | HashSet | ListSet | TreeSet | BitSet |
|---|---|---|---|---|
| 10,000件 | 0 ミリ秒/件 | 0 ミリ秒/件 | 0 ミリ秒/件 | 0 ミリ秒/件 |
| 100,000件 | 1 ミリ秒/件 | - | 4 ミリ秒/件 | 1 ミリ秒/件 |
ListSetは『どのタイミングで追加したデータにアクセスするか』によって顕著な性能差が見られます。上述のデータ追加時にも明らかになっていたとおり、ListSet用の大量データを作成するのにめちゃくちゃ時間を要するので途中で退場してもらっています。
その他のSetはTreeSetがやや遅いようですが、神経質になって気にする必要はないレベルです。
全走査
foreachでブン回します。
def sequentialAccess(set: Set[Int]): Int = {
var sum = 0
set.foreach { elm =>
sum = sum + elm
}
sum
}
計測結果は以下のとおりです。
- 試行回数100回の平均時間
| 件数 | HashSet | ListSet | TreeSet | BitSet |
|---|---|---|---|---|
| 100,000件 | 0 ミリ秒/件 | 1 ミリ秒/件 | 0 ミリ秒/件 | 0 ミリ秒/件 |
| 500,000件 | 3 ミリ秒/件 | 5 ミリ秒/件 | 2 ミリ秒/件 | 1 ミリ秒/件 |
| 1,000,000件 | 9 ミリ秒/件 | 10 ミリ秒/件 | 5 ミリ秒/件 | 3 ミリ秒/件 |
| 10,000,000件 | 58 ミリ秒/件 | - | 53 ミリ秒/件 | 31 ミリ秒/件 |
ここではBitSetのパフォーマンスが目立ちます。HashSetとTreeSetはどっこいどっこいといったかんじでしょうか。
これでBitSetのデータ登録が速かったら言うことはないのですが、データ登録は少しパフォーマンスで劣るので『数値を格納したSetに何度もアクセスする』という場合に有効になりそうです。
ListSet用の大量データを作成するのにめちゃくちゃ時間を要するので、10,000,000件については退場してもらっています。
結論
ここまでの確認結果に則って「どのような時にどのようなコレクションを使用すべきか」を以下に記しています。
迷ったら
HashSetを使えば良いです。データ追加もデータアクセスも爆速で実行してくれます。
キーの登録順をキープさせたい!
ListSetを使用することとなります。
ただし、件数が多くなってくると登録すら非常に遅くなってくるので要注意です。
データの並び順をソートさせたい!
TreeSetを使用することとなります。格納する値が数値なのであれば、BitSetという選択肢もあります。
格納するのは数値のみ、かつ一度Setを作ったら何度もアクセスする
BitSetの使用を検討しても良いかもしれません。データ登録は少し劣りますが、取得するのは速いのでSetに何度もデータアクセスする必要がある場合は作成時の性能ロスを取得時の性能向上でペイできる可能性があります。