あらすじ
データベース設計について調べ始めて数日、主キーのID生成することになったボクくん
「serialでレコードに連番振るのは芸がないなぁ・・・」
「UUIDはなんか長い、snowflake形式のIDがtimestampも付けられるしこれにしよう!」
「ついでに64bitの中でIDの種類(ユーザーとか記事とか)も含めたいな」
「名前はnarrowflakeにしよう!なんか語感似てるし」
ボクくんは無事に独自規格IDの設計と生成器実装まで出来るのでしょうか?
前提知識
- snowflake
- PL/pgSQL
それぞれの軽い説明
SnowflakeとはTwitterやDiscordで使われている64ビットのユニークID生成プロトコル
IDの中にTimestampや発行ワーカープロセスの情報とシーケンス番号を入れて一意性を実現している
PL/pgSQLはpostgresで使えるプログラミング言語
SQL内に含める関数を定義するのに使う
設計
これがぼくのオリジナルIDだ!!
narrowflake identifier
+-+---------------------+-------------------------+----------+---------+
| | timestamp starts | datacenter info(8bit) | sequence | content |
|0| 2021/01/01 00:00:00 +----------+--------------+ number | type |
| | (41bit) | id(3bit) | worker(5bit) | (10bit) | (4bit) |
+-+---------------------+----------+--------------+----------+---------+
(total 64bit)
説明しよう!
timestamp (41bit)
2021/01/01 00:00:00起算の経過秒を格納する
Snowflakeと同様に41bit分確保しているので約69年間の秒数をカウント可能
datacenter info (8bit)
大まかに説明するとこの8ビットは物理的な発行場所+ワーカープロセスの値
つまり発行プロセス毎にこの部分は一意なので、この下で発行されるシーケンスのbit長が秒間に発行できるユニークIDの上限になる
id (3bit/8bit)
idセクションは主に地域で分けることを想定している
日本でデータセンターを分散させるなら東京、大阪、函館・・・のようにして割り当てる
どうせ8個もデータセンター作らないでしょうきっと、人間が住んでる大陸5個しか無いし
もし足りなくなったらワーカーIDの最上位ビットたぶん使ってないのでそれを当てよう(え)
worker (5bit/8bit)
データセンターのワーカープロセスごとに分ける想定
今回の実装だとSQLサーバー上で発行する形になるのでプロセスと言うよりSQLサーバーごとに割り当てられる形だ
sequence number (10bit)
同じ秒に発行されたIDでもシーケンス(連番)を変えることで一意性を保つ仕組みになっている
異なる秒ですべてsequence numberが0から始まる必要性は無いため、時刻が異なればカウントが始まる数字も異なる
PayPayの秒間トランザクションが1000超えたって記事を見たので10ビットにした
content type (4bit)
snowflakeにはないビット
クライアント側でIDの種別を判断できるためIDのみのキャッシュでデータ種別がわかる
また問い合わせ前にこのセクションを見て弾く事もできる
なんかpostgres側でID生成する前提で作ったからDBサーバー指向になっちゃったなぁ・・・
narrowflake実装編
目標としては
create table Accounts(
account_id bigint default narrowflake_id() primary key,
account_name varchar(30) not nurr,
account_mail varchar(255) not nurr
);
みたいにserialの代わりに使えるようにしたい
のでまずシーケンス部分を実装するのにSQLのシーケンスを使う
SQLのシーケンスとは任意の連番を割り振る用途で用意されているテーブルだ
設定でカウントダウン形式の連番なども生成することが可能だ
0から1023までの新しいシーケンスnarrow_seqを作成する
drop sequence if exists narrowflake_seq;
create sequence narrowflake_seq
maxvalue 1023,
minvalue 0,
cycle -- 最大値に到達したら周回させる
;
シーケンスはnextval('narrowflake_seq')の形で取り出すことが出来る
nextval('narrowflake_seq')は、呼び出すたびに内部でインクリメントされて0->1023->0->...の連番サイクルが取り出せる
そして関数を作る
postgresqlのfunctionで使うのはPL/pgSQL言語
drop function if exists narrowflake(text, bit, bit);
create function narrowflake(seq_table text, datacentar_id bit, content_type bit)
returns bigint as $$
begin
return (
(extract(epoch from date_trunc('second', current_timestamp)) - 1609426800.0)::bigint::bit(41) ||
datacentar_id::bit(8) ||
nextval(seq_table)::bit(10) ||
content_type::bit(4)
)::bit(63)::bigint;
end;
$$ language plpgsql;
関数がしていることを簡単に説明すると、各ビットのセクションごとにbit型で計算して、ビット結合演算子||でつなげて、bigintにキャストしている
使用するsequenceテーブル・datacenter_id・content_typeはnarrowflake_id(seq_table, datacenter_id, content_type)の引数として指定できる形にした
動作の確認
select narrowflake('narrowflake_seq', b'01111111', b'0001');
--# narrowflake
--# ----------------
--# 83127126966465
--# (1 row)
2進数に直すと0000 0000 0000 0000 0100 1011 1001 1010 1000 1010 1101 1111 1100 0000 1100 0001
データセンターIDの01111111やコンテンツID0001が正しく差し込まれている
timestampフィールドは1 0010 1110 0110 1010 0010 1011
経過時間に直すと00年 08月 18日 18時 17分 31秒
正しく実装することが出来た
感想
今の所単一のデータベースサーバの設計なのでワーカープロセスIDは固定だが、もし大量のデータを分散して検索する必要が出てきた際にsnowflakeは無理なく拡張できる仕様だと思った
postgresの水平分散型のデータベースにしたときに、問合わせるデータベースサーバーの宛先をクライアントが意識せずIDに埋め込んでくれるのは便利そうだ
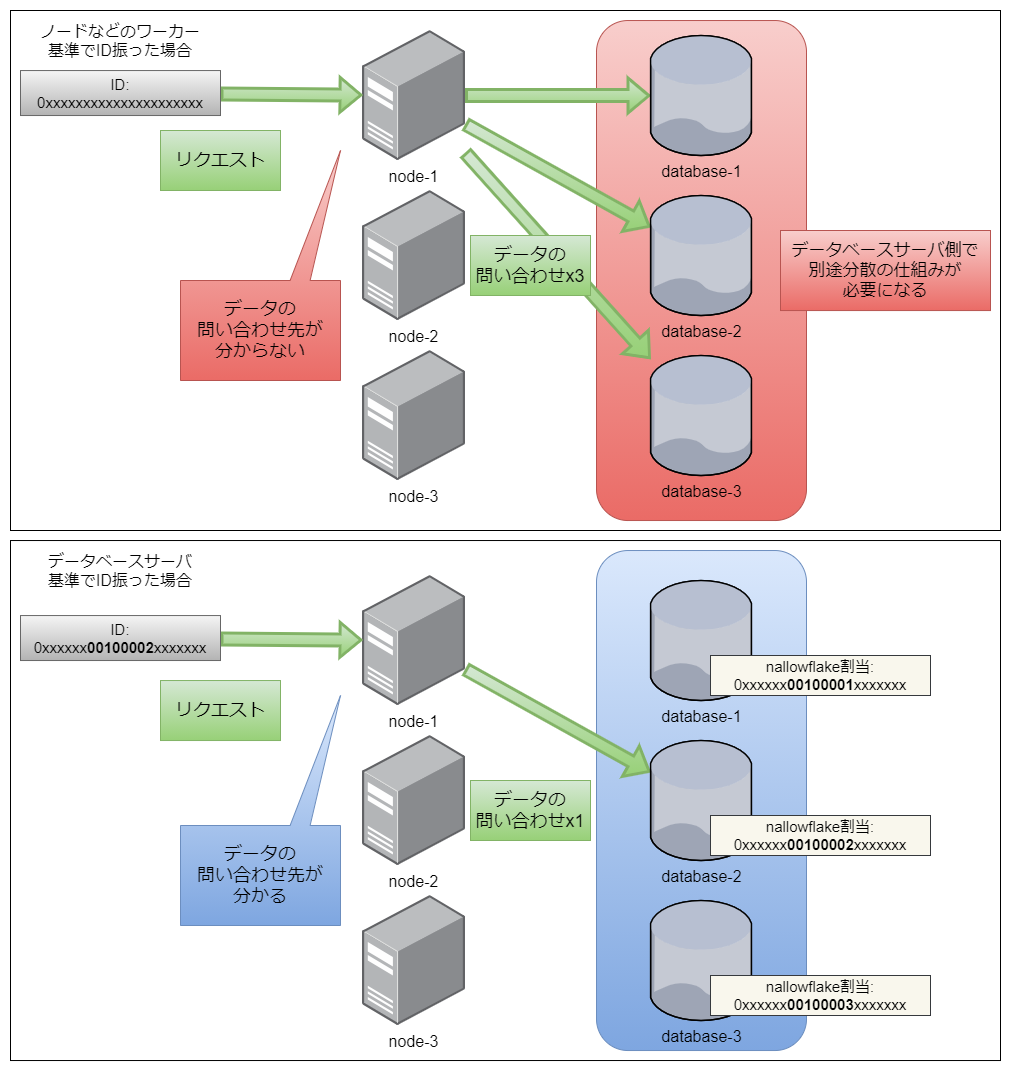
イメージはこんなかんじ
特に今回の実装だとID生成機構を全部postgresにまとめられるのでメンテナにとってわかりやすい、かもしれない
ただPL/pgSQLはpostgresでしか使えないため他RDBMへの以降にコストがかかるし、キャストを多用しているのでパフォーマンス面の調査、SQLサーバー側をクラスター化する場合ならpostgres以外の選択肢があるのかなど、分散化の課題についてはもう少し調べてみたいと感じた