tl;dr
2020年1年間のはてなブックマークの人気エントリー3万件をもとに技術トレンドを分析。
その結論とPythonでグラフ化した手順を書き記します。
※ご指摘がありましたが、技術トレンドというよりitニューストレンドと言った方が正しいかもしれません。踏まえてお読みください。
前置き
手元に2020年の1年間ではてなブックマークの技術カテゴリーにおいて人気エントリーに一度でも乗ったことのある記事のタイトルデータが3万件ほどあったため、形態素解析を行い単語の出現頻度順に並べてみました。欠損の割合としては多くても1割程度、つまり少なくとも9割程度のデータは揃っているはずなので精度はかなり高いと思います。
(※はてなブックマークはNewsPicksみたくインターネット上の記事をブックマーク・コメントでき、より多くブックマークされた記事が人気エントリーとしてピックアップされるサービスです。web系エンジニアなら日常的に技術カテゴリーを見てる人は多いと思います。)
単純に上から並べると一般名詞やメディアの名前が上位を占めてしまうので、上位1000位のうち技術/技術系サービスに関係ありそうな単語だけをピックアップしました。結果としてピックアップした上位150位ほどで以下のようになっています。
結果
約150位まで全体像
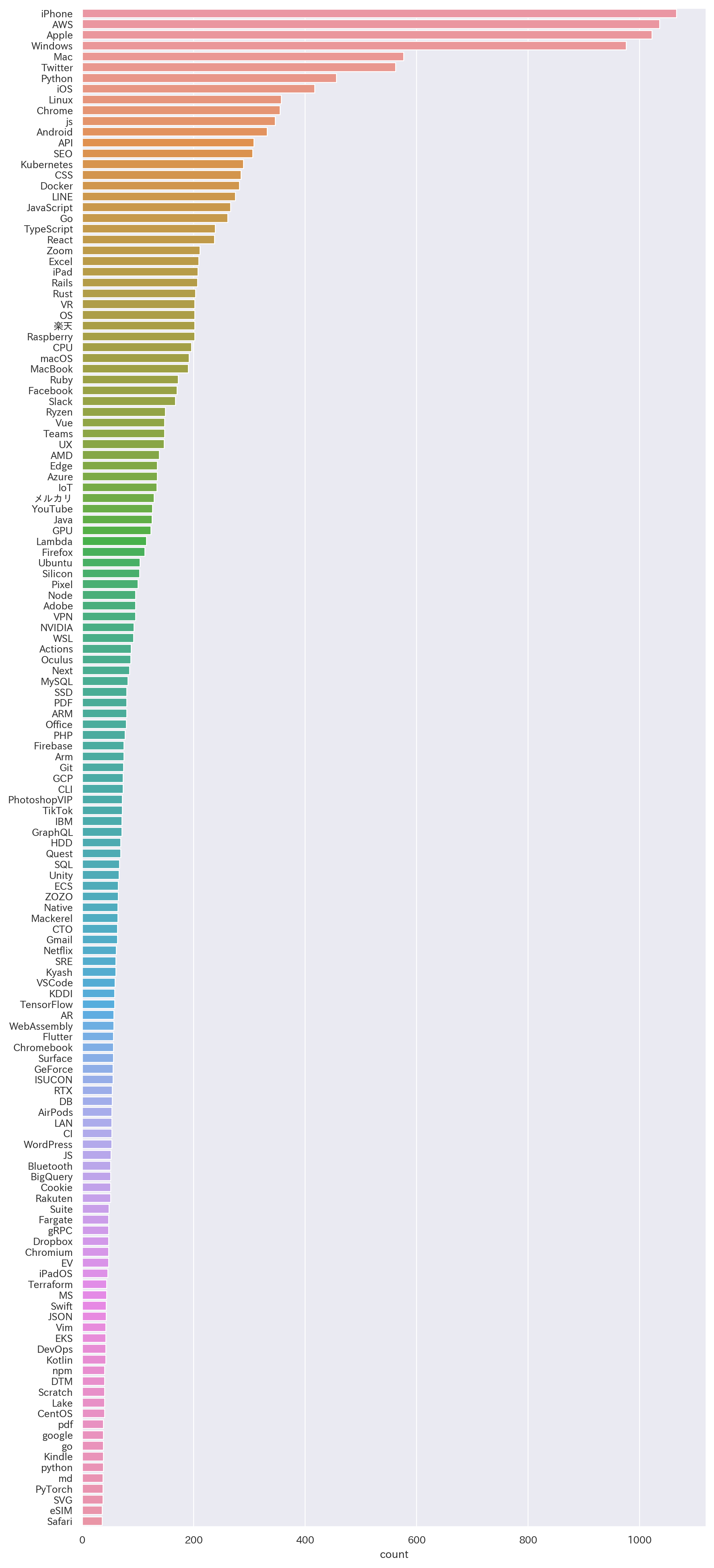
1〜50位詳細
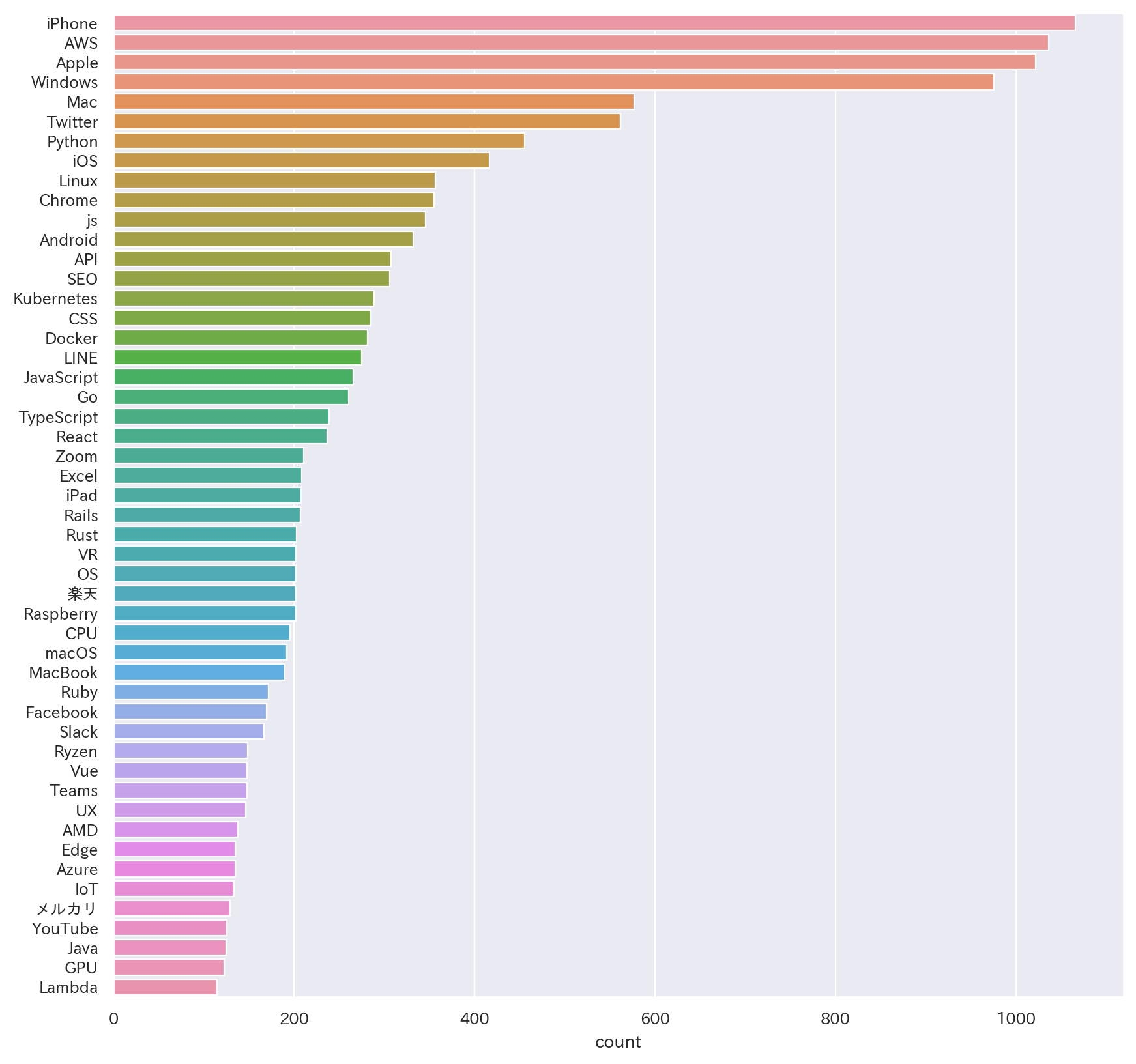
51~100位詳細
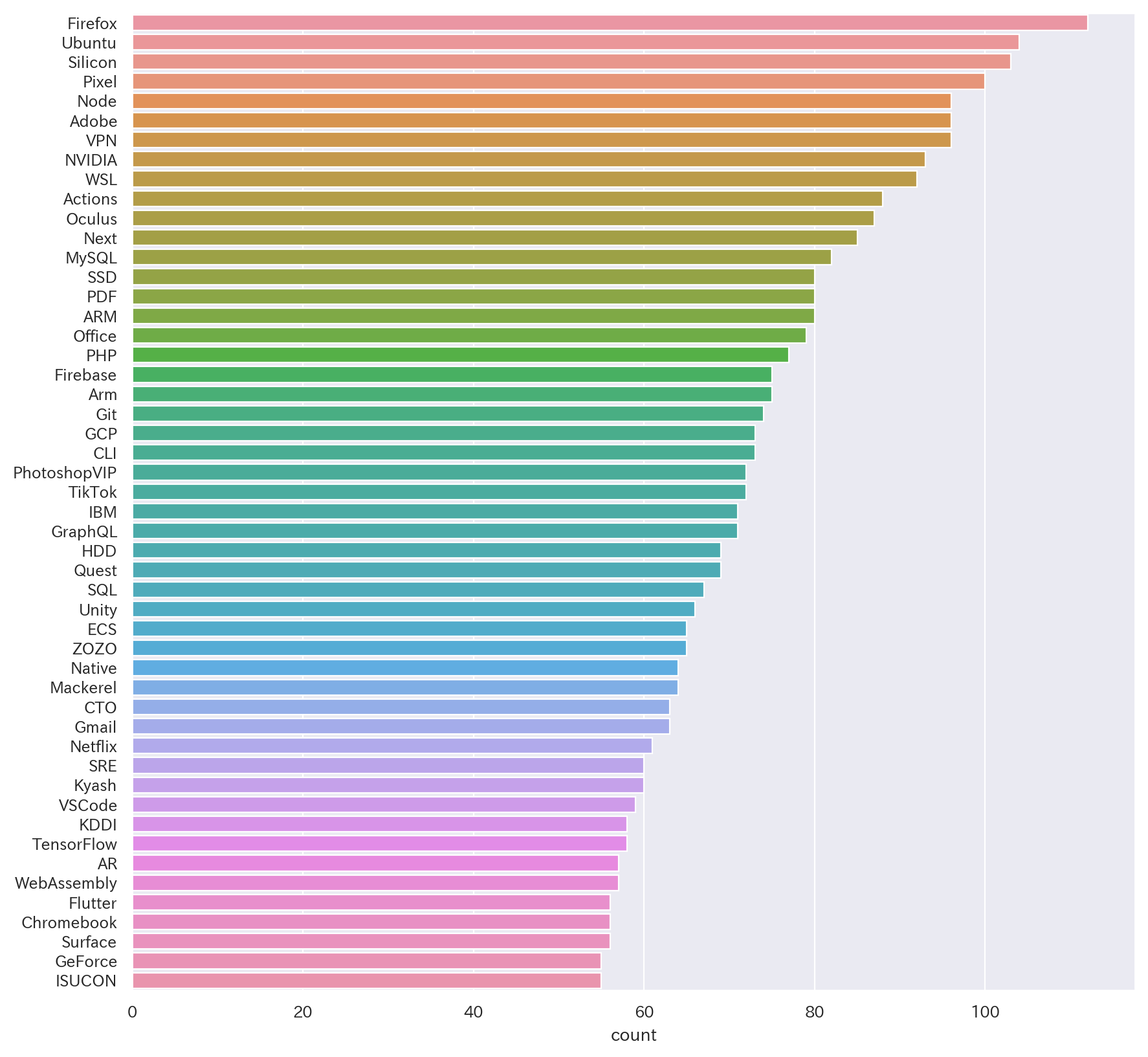
101位詳細~
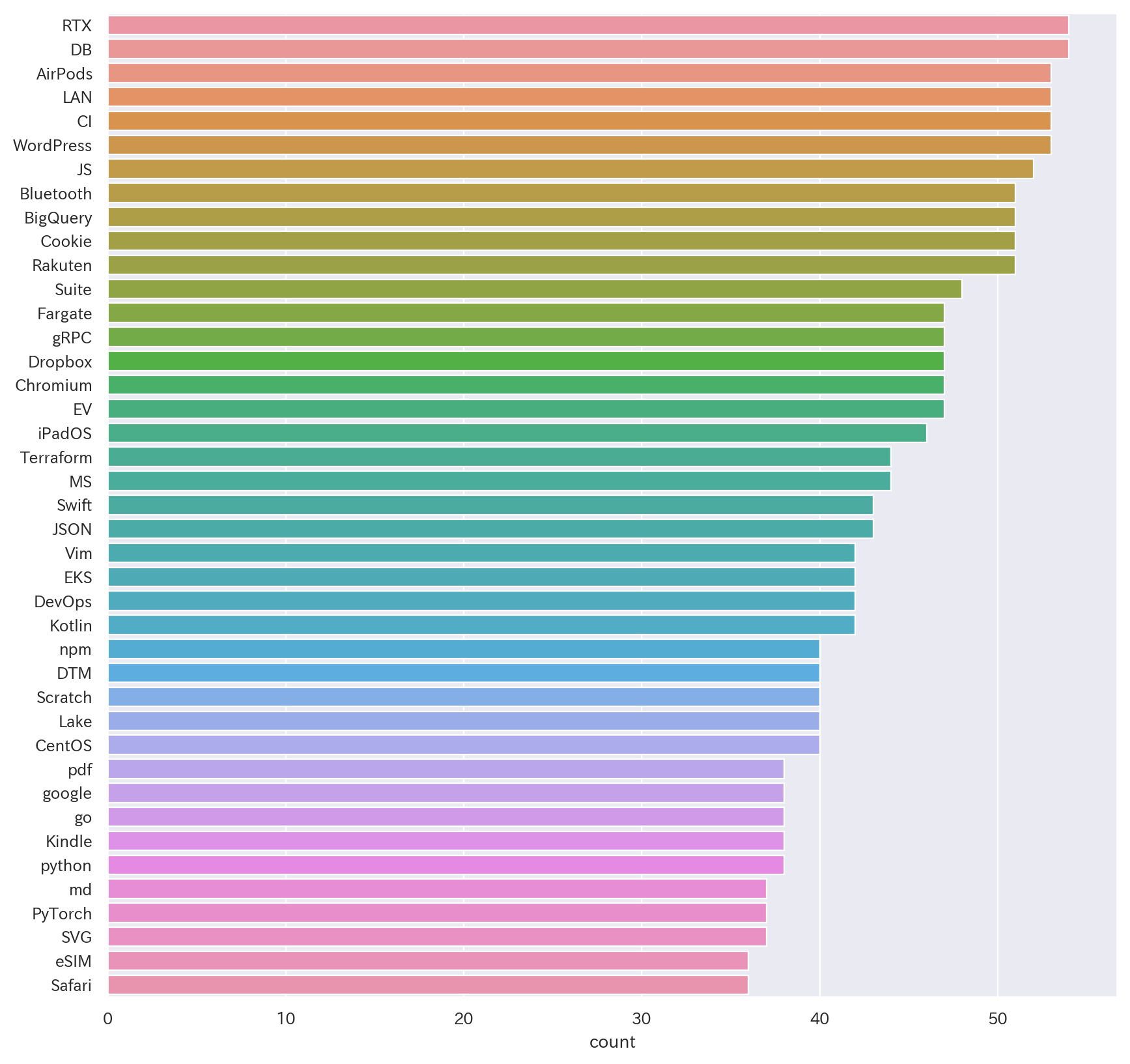
(※collectionsライブラリの仕様かseabornの仕様かはわかりませんが、実際の数字とグラフの値に若干のズレがあることを確認しています🙇♂️)
実装コストの兼ね合いで名寄せは実装していません。表記の揺れはある程度吸収できていそうですが、jsとJavaScriptなど一部吸収できていない部分もあります。直感に反しているものがあればぜひデータに当たってみてください。
プログラミング言語系ではTypeScriptも別で上位に入ってきていることを考えるとJavaScriptが頭抜けていてPythonが追従しているようなかたちが見て取れるかと。クラウドサービスの中ではGCPがFirebaseの名で語られることが多そうだとはいえAWSの言及回数がダントツです。
また、KubernatesやRustなんかは200記事タイトル以上で言及されており自分の思ったより上位に入ってきていて驚きました(それだけ注目されているということだと思います)。枯れた技術で言うと、ネガティブな文脈で触れられることも多かったと感じますがRails(言語よりフレームワークが先に来るのがRubyらしいですね)がRustと同程度言及されていて、Javaが約150回言及で50位程度、PHPも100回弱言及で100位以内には入ってきてるといったところで根強い人気がありそうです。
Kubernates/ECS/EKS/Fargateなどが入ってきていることを考えるとコンテナオーケストレーションの分野は体感通り注目をますます集めているなと感じます。
皆さんはギャップ・印象のほどいかがでしょうか。思っていたところと違ったところなどあればコメント等で意見交換できると面白いかもしれませんね。
(ちなみに、自分が普段業務で使っているScalaは頻度32回で150位圏外でした😂)
手順
pythonは環境構築周りがかなりややこしいです。Macでやる場合はAnacondaかpyenvでpython3系を入れることになると思います。AnacondaはかなりリッチなのでpyenvでPython3を入れたあと、pip3で必要なライブラリだけをinstallするのが良さそうです。
condaとpip:混ぜるな危険 - onoz000’s blog
Anacondaとpipを併用すると干渉することがあるらしいので気をつけてください。Anacondaはpythonのディストリビューションの1つで機械学習系のライブラリがセットになったものだったと思います。今回はbrewでpyenvを入れていきます。
$ brew install pyenv
$ pyenv install -l # ダウンロードできるバージョン一覧
$ pyenv install 3.7.9 # 自分の場合は3.7系依存のCLIツールを使っていたので3.7.9を入れる
$ pyenv global 3.7.9 # pythonコマンドで使うバージョンを変更
$ python --version # => Python 3.7.9
pip3が入るので必要なライブラリを導入していきます。
$ pip3 install collections matplotlib seaborn japanese_matplotlib pandas mecab-python3
形態素解析にはMecabを使うので入れてなければbrewでいれます。
$ brew install mecab
$ brew install mecab-ipadic # 辞書データ
pythonコードを書きます。固有名詞に絞ってしまうと、Lambdaなどの単語が一般名詞に分類されることもあったりで正確にカウントできないため、今回は泣く泣く一般名詞と固有名詞両方とも含めてカウントすることとしました。本来は固有名詞だけを正確にカウントできる方が楽かと思いますので、mecab-ipadic-NEologなど他の辞書データ検討で精度を上げていきたいところです。
import MeCab
import collections
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
# リストを平坦化するflatten関数
flatten = lambda x: [z for y in x for z in (flatten(y) if hasattr(y, '__iter__') and not isinstance(y, str) else (y,))]
# csvデータの取り込み→リストへ
data = pd.read_csv("trend-hatena-tech-2020.csv").values.tolist()
flatten_data = flatten(data)
m = MeCab.Tagger ('-Ochasen') # ここでmecab-ipadic-neologdなど別の辞書データを指定することも可能
m.parse('') # バグの迂回
words=[]
for row in flatten_data:
node = m.parseToNode(row)
while node:
# 名詞かつ一般名詞もしくは固有名詞の場合カウント対象のwordに含める
hinshi=node.feature.split(",")[0]
hinshi2=node.feature.split(",")[1]
if hinshi == "名詞" and (hinshi2 == "一般" or hinshi2 == "固有名詞"):
words.append(node.surface)
node = node.next
c = collections.Counter(words)
del c['*']
common_words = c.most_common(1500) # 頻度上位1500位の単語をカウントしtuppleのリストで取得
sns.set(context="paper",font="IPAexGothic") # seabornの日本語対応
fig = plt.subplots(figsize=(100, 250), dpi=120) # 描画サイズとdpiの調整
sns.countplot(y=words,order=[i[0] for i in common_words])
plt.show() # プロット
参考までにcsvの中身(記事の最初で示したスプレッドシートをcsvでエクスポートしたものです)。
$ cat trend-hatena-tech-2020.csv
「なんだこれは…」と絶句 HDD落札男性が見た中身:朝日新聞デジタル
サカナクション、Chara、フジファブリック、女王蜂、米津玄師らを手がける土岐彩香の仕事術(前編) | エンジニアが明かすあのサウンドの正体 第9回 - 音楽ナタリー
社会人大学院で得たもの、失ったもの - 怠惰を求めて勤勉に行き着く
GCP Projectを消しちゃった話 - 839の日記
Go でトランザクションをフルスクラッチで実装した - kawasin73のブログ
【山田祥平のRe:config.sys】在宅勤務時代のディスプレイ選び - PC Watch
「世界最悪級の流出」ブロードリンク社の2chスレを見ると事件は起こるべくして起こったことがわかる - アンテナ開発者ブログ
何度も使えるエコなカイロ 『ハクキンカイロ』がもうすぐ100年「使い捨ての13倍の暖かさ」「コスパ最強」 - Togetter
LGの弱点も丸裸に、韓国メーカーを「駆逐」したダイキン 開発設計の3つの戦略と4つの戦術 | 日経 xTECH(クロステック)
2019年版 SEOのトレンドと注目すべきトピック - Speaker Deck
...
実行します。
$ python count.py
上記コードのようにフィルターせずに素直に全て表示した場合とても見にくいので

今回は気合でフィルターしました😢
import MeCab
import collections
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
flatten = lambda x: [z for y in x for z in (flatten(y) if hasattr(y, '__iter__') and not isinstance(y, str) else (y,))]
data = pd.read_csv("trend-hatena-tech-2020.csv").values.tolist()
flatten_data = flatten(data)
m = MeCab.Tagger ('-Ochasen')
m.parse('')
words=[]
for index,row in enumerate(flatten_data):
node = m.parseToNode(row)
while node:
hinshi=node.feature.split(",")[0]
hinshi2=node.feature.split(",")[1]
if hinshi == "名詞" and (hinshi2 == "一般" or hinshi2 == "固有名詞"):
words.append(node.surface)
node = node.next
c = collections.Counter(words)
del c['*']
common_words = c.most_common(1000)
# filter条件(pythonワカラナイのでベタ書き😇)
filter_condition = lambda key: key == "iPhone" or key == "AWS" or key == "Apple" or key == "Windows" or key == "Mac" or key == "Twitter" or key == "Python" or key == "iOS" or key == "Linux" or key == "Chrome" or key == "js" or key == "Android" or key == "API" or key == "SEO" or key == "Kubernetes" or key == "CSS" or key == "Docker" or key == "LINE" or key == "amp" or key == "JavaScript" or key == "Go" or key == "TypeScript" or key == "React" or key == "Zoom" or key == "Excel" or key == "iPad" or key == "Rails" or key == "Rust" or key == "VR" or key == "OS" or key == "楽天" or key == "Raspberry" or key == "CPU" or key == "macOS" or key == "MacBook" or key == "Ruby" or key == "Facebook" or key == "Slack" or key == "Ryzen" or key == "Vue" or key == "Teams" or key == "UX" or key == "AMD" or key == "Edge" or key == "Azure" or key == "IoT" or key == "メルカリ" or key == "YouTube" or key == "Java" or key == "GPU" or key == "Lambda" or key == "Firefox" or key == "Ubuntu" or key == "Silicon" or key == "Pixel" or key == "Sim" or key == "Node" or key == "Adobe" or key == "VPN" or key == "NVIDIA" or key == "WSL" or key == "Actions" or key == "Oculus" or key == "Next" or key == "MySQL" or key == "SSD" or key == "PDF" or key == "ARM" or key == "Office" or key == "PHP" or key == "Firebase" or key == "Arm" or key == "Git" or key == "GCP" or key == "CLI" or key == "PhotoshopVIP" or key == "TikTok" or key == "IBM" or key == "GraphQL" or key == "HDD" or key == "Quest" or key == "SQL" or key == "Unity" or key == "ECS" or key == "ZOZO" or key == "Native" or key == "Mackerel" or key == "CTO" or key == "デー>タベース" or key == "Gmail" or key == "Netflix" or key == "SRE" or key == "Kyash" or key == "VSCode" or key == "KDDI" or key == "TensorFlow" or key == "AR" or key == "WebAssembly" or key == "Flutter" or key == "Chromebook" or key == "Surface" or key == "GeForce" or key == "ISUCON" or key == "RTX" or key == "DB" or key == "AirPods" or key == "LAN" or key == "CI" or key == "WordPress" or key == "JS" or key == "Bluetooth" or key == "BigQuery" or key == "Cookie" or key == "Rakuten" or key == "Suite" or key == "Fargate" or key == "gRPC" or key == "Dropbox" or key == "Chromium" or key == "EV" or key == "iPadOS" or key == "Terraform" or key == "MS" or key == "Swift" or key == "JSON" or key == "Vim" or key == "EKS" or key == "DevOps" or key == "Kotlin" or key == "npm" or key == "DTM" or key == "Scratch" or key == "Lake" or key == "CentOS" or key == "pdf" or key == "google" or key == "go" or key == "Kindle" or key == "python" or key == "md" or key == "PyTorch" or key == "SVG" or key == "eSIM" or key == "Safari"
# dictへキャストし、フィルターしたあとでlistへ戻す
filtered_common_words = list({key: value for key, value in dict(common_words).items() if filter_condition }.items())
sns.set(context="paper",font="IPAexGothic")
fig = plt.subplots(figsize=(10, 25),dpi=100) # データ量が変わるのでサイズの調整
sns.countplot(y=words,order=[i[0] for i in filtered_common_words]) # フィルターしたリストを渡す
plt.show()
再び実行
$ python count.py
最初の画像の出来上がり🎉
コメントなど残ったままの殴り書きのコードで良ければGithubにJupyterNotebookの実行結果と合わせて公開しておきます。タイトルではなくタグでカウントしてみたり、(無言)ブックマーク数での重み付けなどしてみるとまた結果が変わって面白いかもしれませんね。来年もまたやって比較してみたいです。以上。
参考
seabornで見てみる「ぼっちゃん」(お遊びpythonシリーズ)
pip install して import するだけで matplotlib を日本語表示対応させる
PythonでCSVファイルをリストに格納する方法