こちらの記事のまとめ。
以下の3タスクでLlama2をファインチューニングした結果、一部タスクでGPT-4を凌ぐ結果となった。
・Functional representations extracted from unstructured text (ViGGO)
構造を持たないテキストから関数呼び出しを生成(引数にあたる情報を正しい順番で抽出し、かつ適切な関数を呼び出す)
・SQL generation (SQL-create-context)
テキストからSQL生成
・Grade-school math question-answering (GSM8k)
小学校レベルの数学

それぞれの色の濃い部分が、ベースラインプロンプトでのLlama-2-chatモデルの性能を示す。
ピンク色は同じプロンプトでのGPT-4の性能を示す。積み重ねられた棒グラフは、Llama-2ベースモデルの微調整による性能向上を示している。
関数呼び出しとSQL生成のタスクでは、ファインチューニングによりGPT-4よりも高い性能を達成したが、数学推論タスクでは、ファインチューニングされたモデルはベースモデルよりも改善されたものの、GPT-4の性能レベルには及ばなかった。
Finetuning Basics
全てのパラメータをtuning対象とした。モデルは次のトークン予測でtuningされ、モデル内の全てのパラメータは勾配更新の対象となる。LLMを訓練する手法として、選択した変換ブロックを凍結させたり、LoRAを使う方法もあるが、実験のため、訓練手法自体はタスクごとに一定に保った。
スクリプトはRay Train、Ray Data、Deepspeed、Accelerateを使用している。
General Training Flow
トレーニング関数が個々のワーカープロセスで実行され、場合によっては複数のマシンに分散されるようになっている。
Ray Train内では、プロセスディスパッチャとして動作し、クラスタ全体でこのトレーニングループをスケールするTorchTrainerクラスを使用。TorchTrainerに使用したいワーカープロセスの数と各プロセスが必要とするリソースの数を知らせる。
データのシャーディング:Ray Trainがデータの取り込みとトレーニングループ間でのデータセットのシャーディングを管理。トレーニングループの先頭で、ワーカーは自分に委譲されたデータセットのシャーディングにアクセスする。
モデルのシャーディング:DeepSpeedがノード間でモデルを分割する方法と、計算とメモリをGPUからCPUにオフロードするタイミングの戦略を定義する。
Special Tokens
タスクをLLMへのpromptとして記述するのではなく、「特殊トークン」を利用して、より単純なプレーンテキストにエンコードした。
{"text": "You are to solve the following math question. Please write
out your reasoning ... etc ... {question}\n{answer}"}
{"text": "<START_Q>{question}<END_Q><START_A>{answer}<END_A>}
特殊トークンを使うことで、タスクの構造を簡単にコード化することができ、また、モデルがいつ出力を停止すべきかのシグナルを提供することができる。上の例では、""を停止トークンとして定義することができる。これにより、文末トークンの出力を待つのではなく、タスクが終了したときにモデルが出力を停止することが保証される。
Llamaトークナイザーはデフォルトで32000のユニークなトークンIDを出力する。4つの特殊トークンを追加すると、
トークンIDは32004個になり、"のIDは32000、""のIDは32001といった感じで割り当てられる。
トークンは以下のように追加できる。
tokenizer = AutoTokenizer.from_pretrained(pretrained_path, ...)
tokenizer.add_tokens(special_tokens, special_tokens=True)
# this will make new learnable parameters for specialized tokens
model.resize_token_embeddings(len(tokenizer))
Compute Details
7Bおよび13Bモデルでは16xA10Gを、70Bモデルでは32xA10G(4xg5.48xlargeインスタンス全体)を使用した。Rayを使用する場合、これらのモデルでフルパラメーター微調整を行うためにA100を確保する必要はない!
下図は、GSM8kデータセットにおいて、コンテキストの長さを512に設定し、1エポックあたり合計3.7Mの有効トークンで実行した例である。
最大10エポックまで学習を実行し、検証セットの最小パープレキシティスコアに従って最適なチェックポイントを選択した。

Functional Representation of Unstructured Text (ViGGO)
ViGGOデータセットは、ゲームレビューについての英語のデータからテキストを生成するデータセットで、本来のタスクは、「関数呼び出し的表現」(スペックの集合)を、それらのスペックを組み込んだ首尾一貫したテキストに変換することである。しかし、我々はこのタスクを逆にした。つまり、構造化されていないテキストを、構造化され解析可能な「関数呼び出し的表現」に変換する。 この表現は、テキストに存在する情報を凝縮し、インデックス付けやその他の下流のアプリケーションに使用することができるため、この一般的な問題は、多くの企業が解決を切望しているものである。

textが与えられると、モデルは入力文の基本的な意味表現を、属性と属性値を持つ1つの関数として構築しなければならない。この関数はtextが何を言っているのか表す必要があり、以下のいずれかでなければならない:
['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute',
'suggest', 'request_explanation', 'recommend', 'request_attribute']
また、属性は以下のいずれかでなければならない:
['name', 'release_year', 'esrb', 'genres', 'platforms', 'available_on_steam',
'has_linux_release', 'has_mac_release', 'specifier', 'rating', 'player_perspective',
'has_multiplayer', 'developer', 'exp_release_date']
ちなみに、プロンプトの工夫だけでこのタスクをLLMに解かせようとすると、指示と例(Few-shot prompt)で非常に長いプロンプトになってしまう。(実際のプロンプトは元記事を参照)
Why Might Fine-Tuning Be Promising?
以前のブログ記事で、我々は「ファインチューニングは事実ではなく、形のためにある」という考え方について述べた。では、このViGGOのタスクにおいて、ファインチューニングされたモデルが、プロンプト・エンジニアリングや数発のプロンプトといった他の方法を凌駕することを期待するのは理にかなっているのだろうか?
この質問に対する答えは単純ではなく、実験が必要だが、ファインチューニングが特定のユースケースに価値を与えることができるかどうかの指針となる、重要なチェック項目をいくつか示そう。
1. 新しい概念ではないか?:
ベースモデルは、事前学習データでこのタスクの概念(ViGGOタスクの場合はビデオゲームに関連する概念)などに出会っていると考えてよいのか、それともまったく新しい概念なのか?全く新しい概念(またはモデルにとって未知の事実)である場合、モデルが小規模なFineTuningによってそれを学習できる可能性はかなり低い。
2.有用なFew-Shot Prompt はあるか?:
Few-Shotプロンプトを使ったとき、改善が見られますか? このテクニックでは、入力と出力のいくつかの例をモデルに示し、同じパターンに従って答えを完成させるように求める。これで大幅な改善が見られた場合、FineTuningでさらに良い結果が得られる可能性がある。これは、FineTuningによって、コンテキストの長さに制約されたり、プロンプトのプレフィックスにトークンを消費したりすることなく、モデル内部のニューラルネットワークの重みにはるかに多くの例を組み込むことができるからだ。
3.トークン予算を考えた時にコスパはどうか?:
プロンプトエンジニアリングがうまくいったとしても、通常長いプロンプトをリクエストごとに入力として提供しなければならない。このアプローチはトークン予算をすぐに消費してしまう。長い目で見れば、そのタスクに特化したニッチなモデルをFineTuningする方が費用対効果が高いこともあるだろう。
さて、今回のViGGOタスクについては、パターン認識を中心に展開されるため、言語と基本的な概念の基本的な把握が必要とされるが、複雑な論理的推論は要求されない。 さらに重要なのは、このタスクは根拠があり、出力に必要な「事実」はすべて入力にすでに埋め込まれているということだ。これは、より小さなLlama-2モデルを微調整するだけでも、このタスクのパフォーマンスを大幅に向上させることができると期待できる。
Evaluation
割愛。
Results
関数呼び出し表現の引数の順番まで含めて評価すると、GPT-4のパフォーマンスは半減。ファインチューニング済みモデルは、順番を考慮してもしなくても同等の高いパフォーマンスを示した。

Takeaways
構造化されたフォームを必要とする場合、ファインチューニングは信頼性が高い。このタスクはまた、「構造化された形式」を要求することが、単純な正規表現またはJSON形式とのマッチングを意味しないことを示している。ViGGOでは、LLMは引数を含めるべきかどうかを判断する必要があり、また、含める引数の順序が優先順位に従うようにする必要もある。
効率という面でも利益がある。一般的なモデルでは、Few-Shotでかなり多くの入力トークンが必要であった。Llama 7bモデルでサービスを作れば、GPT-4にAPI料金を払うよりも大幅に安上がり(特にサービスが成長するにつれて)。ViGGOタスクはパターン認識を中心に展開され、言語と基本的な概念の基本的な把握が必要だが、複雑な論理的推論は要求されない。 さらに重要なのは、このタスクは根拠があり、出力に必要な「事実」はすべて入力にすでに埋め込まれているということだ。これは、より小さなLlama-2モデルを微調整するだけでも、このようなタスクのパフォーマンスを大幅に向上させることができるという良い指標といえよう。
SQL Generation with Llama-2 fine-tuned models
このタスクの目標は、自然言語クエリをデータベース上で実行可能なSQLクエリに変換することである。
WikiSQLとSpiderデータセットを組み合わせたHugging Faceのb-mc2/sql-create-contextデータセットから、不備のあるデータを排除して使用した。

Why Might Fine-Tuning Be Promising?
このタスクでは、LLMは自然言語の構造化表現(SQL)を出力しようとしている。ViGGOとは異なり、このタスクはデータテーブル上で実行されたときに正しい答えを出力しうるSQLクエリが複数存在する可能性があるため、若干曖昧である。しかしこのタスクは、SQLの「構造」を学習し、自然言語をこの構造に変換するLLMの能力によるものであるため、FineTuningに最適であるといえよう。
Evaluation
ダミーのデータセットでコードを実行し、出力の同等性をチェックする方法を使用。
GPT-3.5に、質問、テーブルスキーマ、答えを見て、10個のデータポイントを持つダミーのテーブルを生成するようプロンプトした。このうして得られたデータテーブルを使用。
Results

SQLデータセットの自然言語クエリのいくつかは完全に正しい英語ではない。このデータセットのノイズがGPT-4の結果に若干の影響を与えたと思われる。一方で、ファインチューニングされたモデルは良いパフォーマンスを見せていることから、データセットの癖が何であろうと、その癖に素早く適応できるということが窺える。
Takeaways
SQLタスクで、7bと13bのFinetuneされたモデルは、GPT-4と70bのチャットモデルを上回った。
GPT-4とllama-base-chatモデルでは、長いプロンプトを入力する必要があった。さらに、GPT-4では問題にならなかったが、llama-base-chatモデルは、タスクに不必要な雑多なトークンを何百と出力することが多く、推論時間をさらに遅くしていた(例:"Sure! Happy to help...")。
Grade School Math reasoning (GSM8k)
最後のタスクはGSM8kである。このタスクは、数学の推論と理解に関してLLMを評価するための標準的な学術的ベンチマークである。このデータセットにおけるFineTuningの課題は、前の2つとは異なる。単に構造を学習するのとは対照的に、我々はLLMが数学の問題を解く能力をどれだけ向上させることができるかを調べた。
Question
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Answer
Natalia sold 48/2 = 24 clips in May.
Natalia sold 48+24 = 72 clips altogether in April and May.
#### 72
LLMが72という答えを即座に出せたら素晴らしいのだが、現在のLLMは答えに至る「思考」プロセスを内面化することができない。その代わりに、LLMは「思考」プロセスをアウトプットの一部として生成し、後続の各単語の生成が確かな推論プロセスに基づいていることを保証しなければならない。このデータセットのターゲットとなるAnswerは、思考プロセスの概要を示すようにフォーマットされており、最終的な回答は解析しやすいように####{回答}のフォーマットで結ばれている。
Evaluation
最終的な答えのみを抽出し、グランドトゥルースと比較する評価を行う。
このとき、FineTuningされたモデルはさておき、一般的なLLMでは、望ましい出力形式を一貫できないのが問題となってくる。
生成形式に制約をつけるには、プロンプトで指示したり、Few-Shotの例を提供するなどの方法があるが、今回は簡単のため、また評価プロセスを自動化するために特定の出力形式を確保するために、我々はOpenAIの関数呼び出しAPIを利用した。具体的にはgpt-4またはgpt-3.5-turboモデルを採用し、所定の出力構造を持たない生成結果から回答を抽出した。
また、注目すべきは、ファインチューニングされたモデルは、ターゲット回答に示されたパターンに従うことを素早く学習し、そこから逸脱することはほとんどないということだ。
Why Might Fine-Tuning Be Promising?
モデルは事前学習段階で十分な数学的概念に触れていると考えられる。そのため、そこから汎化できるはずであり、ファインチューニングは内部知識の適切なモードを起動するのに役立つはずである。
さらに、Llama-2の公表されているベンチマークを調べてみると、8つのFew-Shot例を含むGSM8kデータセットで顕著な性能を発揮し、他のモデルを凌駕しているではないか。このことは、豊富な事前学習データの重要性を強調している。
ファインチューニングによってこの数値をさらに向上させることはできるのだろうか?

Baselines
今回のテストでは、以下のベースラインを考慮した:
1.ベースとなる事前学習済みモデルを使用し、Llama-2の報告と同じ8ショットのプロンプトを使う
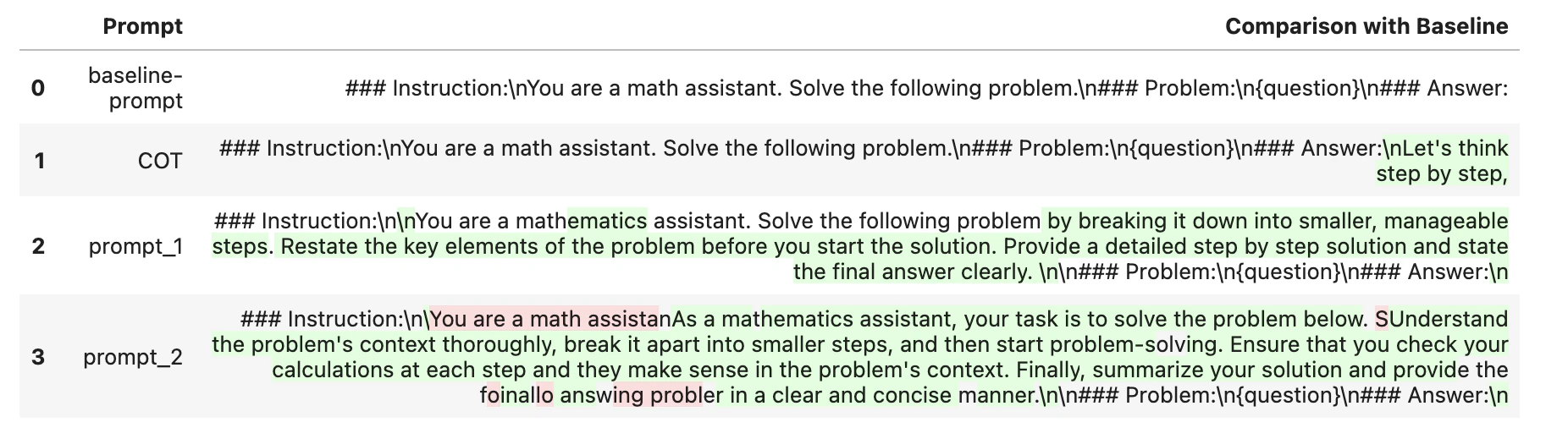
2.Chat-tuned Llamaのバリアントにモデルを使用し、Prompt-Engineeredテンプレートを使用。これらの "チャットチューン "モデルは、汎用アシスタントモデルとして機能するように、MetaによってRLHFを使ってトレーニングされた。RLHFのトレーニングがOpenAIのアプローチと同様に厳格に行われたならば、これらのモデルからも高品質な結果が期待できるはずだ。以下の表は、私たちが使用したプロンプトテンプレートのビューを示し、それらが互いにどのように異なるかを示している。
Results
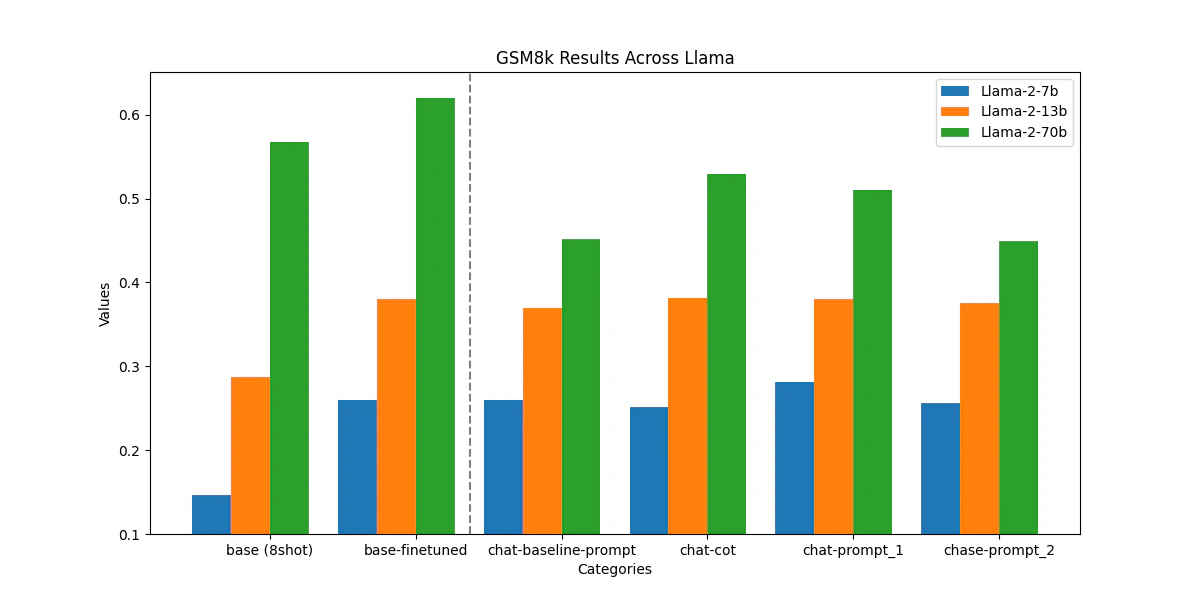
ファインチューニングされた7bと13bのモデルは、ベースラインと比較して精度が10%向上しているが、チャットチューニングされたベースラインと比較すると、マージンは少ない。
ここから言えることは、
- ベースモデルをファインチューニングすることで、この特定のタスクに対するパフォーマンスが一貫して向上する。しかし、必ずしもチャットチューニングされたモデルよりも有意に良い結果が得られるとは限らない。チャットモデルは多用途に使用できるようにファインチューニングされているため、目的のタスクに十分かどうかを判断するには、さまざまなプロンプトで実験する必要があることに留意。
- ファインチューニングされたモデルにプロンプトを入力しても、常にベースモデルよりも優れたパフォーマンスが得られるとは限らない。たとえば、Llama-2-70B-chatは、ベースモデルに8ショットのプロンプトを入力するよりもパフォーマンスが劣る可能性がある。一方、ファインチューニングされたモデルは、ベースモデルに8ショットのプロンプトを入力した場合よりも一貫して良いパフォーマンスを示す。(ここよくわからない)
- このタスクのために微調整されたモデルは、すべてのモデルサイズにわたって優れたパフォーマンスを示すと同時に、提供時のコストは他のベースラインよりも大幅に低くなる可能性がる。このタスクでは、各リクエストのプロンプトに含まれるすべてのトークンに対して課金されるが、ファインチューニングされたモデルでは、実質的に問題に含まれるトークンの数に対してのみ課金される。対象とする配信トラフィックによっては、よりパフォーマンスの高いカスタマイズされたモデルを使用しながら、全体的なコストを低く抑えることができる。(ここよくわからない)
- チャットチューニングされたモデルは、ファインチューニングされていないベースモデルよりも優れたパフォーマンスを示した。チャットチューニングされたモデルと事前にトレーニングされたベースモデルを区別することが重要。チャットチューニングされたモデルは、チャットチューニングプロセスで数学の例を使ってトレーニングされた可能性が高く、その結果、ベースモデルよりも精度が高くなっている。
Further Improving Fine-Tuning Results
全体的にファインチューニングによる改善が見られたが、我々はLlama-13bに焦点を当て、標準的なファインチューニング技術で結果をさらに改善できるか実験した。
GSM8kトレーニングデータセットは比較的小さく、8kデータポイントしかない。数学の問題を解くための学習は、特定のフォーマットで答えを出力する学習よりも単純ではないため、Llama-13bモデルの潜在能力をフルに引き出すには、データポイントの数が不十分だと考えた。
このことを念頭に置き、Llama-13bモデルをベースにして、まずMathQAデータセットでファインチューニングを行い、その後にオリジナルのGSM8kデータセットでファインチューニングを行った。このファインチューニングの追加により、最初にファインチューニングしたモデルの結果がさらに10%向上し、ベースモデルから20%向上した。

この結果は、機械学習における古典的な「より多くのデータ、より良いモデル」のパラダイムと一致すると思われるかもしれないが、MathQAデータセットの性質を考慮すると、驚くべき結果である。MathQAは30,000の質問と答えのペアのコレクションで、GSM8Kデータセットよりもノイズが多く、構造も異なる。解答の質は低く、GSM8Kとは異なり、MathQAの最終解答は多肢選択式である。例えば、変な場所にスペースが入ってたりするのだ。
Conclusion
GPT-4、Claude-2などのクローズド・ソース・モデルは、プロトタイピングや初期価値の証明には強力だが、本番でパフォーマンスの高いLLMアプリを実行するには不十分であることを、これら3つの例を見て納得していただけたと思う。
ニッチなタスクのためにLLMを微調整することは、プライバシーだけでなく、レイテンシ、コスト、そして時には品質(ViGGOやSQLの例など)のためにLLMの価値を引き出す有望なソリューションの1つである。
ファインチューニングでは、データの収集と評価パイプラインの設定に重点を置くべき。