あと、ニュース要約はAI君頼むやで!!!
ざっくりやりたいこと
日本のITニュースを収集・要約して、Slackに毎朝自動投稿するツールを作りたい
若干未完成(重要)
要件整理
GitHub Actionsが毎朝7:30に走り、ITmediaとYahoo!ニュース(ITカテゴリ)のRSSを取得
各記事のはてなブックマーク数をAPIで叩いて「注目度」として三本だけ選抜。
newspaper3kで本文を取得してLLMに200〜300文字で要約してもらい、Slackへポスト。
ポスト済みURLはposted.jsonに突っ込んでおいて、同じ月のうちは二重投稿を防止。
月が変わるタイミングで履歴クリア用ワークフローを走らせる。
インフラを用意せずに済ませられることがミソ。
完成すれば何も気にせず放置でOK。運用は完全にサボれる設計を目指したい。
フォルダ構成
├─ .github/workflows/
│ ├─ notify.yml # 毎朝ニュースを送る
│ └─ clear-posted.yml # 月初に履歴を空っぽにする
├─ main.py # ニュース収集〜Slack 投稿の本体
├─ requirements.txt # ライブラリ
└─ posted.json # 「もう送ったよ」リスト
依存関係は特に説明することなし、こんな感じ
requirements.txt
feedparser
newspaper3k
requests
transformers
torch
sentencepiece
tldextract
lxml[html_clean]
んじゃ処理いくよ〜〜〜〜ん。
最後に完成版も置いてあるので、丸ごと欲しい人はスクロールしてどうぞ。
main.py
まずは外部設定まわり。あと2サイト分のRSSを配列にしておきます。
Webhook URLはリポジトリシークレットから呼び出し。
import os
import json
import datetime
import feedparser
import requests
from newspaper import Article
from transformers import pipeline
SLACK_WEBHOOK_URL = os.environ["SLACK_WEBHOOK_URL"]
FEED_URLS = [
"https://rss.itmedia.co.jp/rss/2.0/news_bursts.xml",
"https://news.yahoo.co.jp/rss/categories/it.xml",
]
すでに投げた記事を覚えておくためのJSON処理
ロードして書き込むだけなのでめちゃシンプル。
import json, os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
STATE_FILE = os.path.join(BASE_DIR, "posted.json")
def load_posted() -> set:
if os.path.exists(STATE_FILE):
with open(STATE_FILE, encoding="utf-8") as f:
return set(json.load(f))
return set()
def save_posted(posted: set):
with open(STATE_FILE, "w", encoding="utf-8") as f:
json.dump(list(posted), f, ensure_ascii=False, indent=2)
feedparserで記事を吸い上げて、はてなブックマークAPIから注目度スコアを付与
エラーは握りつぶして0扱いに。
def get_hatena_count(url: str) -> int:
api = f"https://api.b.st-hatena.com/entry.count?url={url}"
try:
r = requests.get(api, timeout=5)
return int(r.text) if r.ok and r.text.isdigit() else 0
except:
return 0
def fetch_all_entries():
entries = []
for url in FEED_URLS:
feed = feedparser.parse(url)
for e in feed.entries:
entries.append({
"title": e.title,
"link": e.link,
"hatena": get_hatena_count(e.link)
})
return entries
モデルは tsmatz/mt5_summarize_japanese。
重いのでファーストコールでロードし、以降は関数属性でキャッシュしておく。
def summarize(text: str) -> str:
if not hasattr(summarize, "pipe"):
model_name = "tsmatz/mt5_summarize_japanese"
summarize.pipe = pipeline(
"summarization",
model=model_name,
tokenizer=model_name,
framework="pt",
device=-1,
)
prompt = (
"以下の記事を200〜300文字程度で要約してください。"\
"事実を改変せず、重要な数値・固有名詞は保持してください。" + text
)
tokens = summarize.pipe.tokenizer.encode(prompt, return_tensors="pt")
result = summarize.pipe(
prompt,
max_length=300,
min_length=200,
num_beams=10,
no_repeat_ngram_size=3,
length_penalty=1.2,
repetition_penalty=1.05,
early_stopping=True,
do_sample=False,
)
return result[0]["summary_text"].strip()
タイトルはリンク化、Markdownで見栄えを整えて通知。
def notify_slack(items) -> bool:
today = datetime.date.today().strftime("%Y-%m-%d")
blocks = [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"📰 *本日のITニュースまとめ({today})*\n"
}
},
{"type": "divider"}
]
for idx, it in enumerate(items, start=1):
blocks.append({
"type": "section",
"text": {
"type": "mrkdwn",
"text": (
f"*<{it['link']}|{it['title']}>*\n"
f"> はてなブックマーク数: {it['hatena']}\n"
f"> AI要約: {it['summary']}"
)
}
})
blocks.append({"type": "divider"})
payload = {
"blocks": blocks,
"unfurl_links": False,
"unfurl_media": False
}
resp = requests.post(SLACK_WEBHOOK_URL, json=payload, timeout=10)
return resp.ok
フェッチ → フィルタ → 要約 → 通知 → 状態保存
このフロー。3件拾ったら終わり、なければ静かにおやすみなさい。
def main():
posted = load_posted()
all_entries = fetch_all_entries()
candidates = [e for e in all_entries if e["link"] not in posted]
new_entries = sorted(candidates, key=lambda x: x["hatena"], reverse=True)[:3]
if not new_entries:
print("No new items to post.")
return
results = []
for e in new_entries:
art = Article(e["link"])
art.download()
art.parse()
summary = summarize(art.text)
results.append({**e, "summary": summary})
posted.add(e["link"])
notify_slack(results)
save_posted(posted)
if __name__ == "__main__":
main()
最終的なソース
import os
import json
import datetime
import feedparser
import requests
from newspaper import Article
from transformers import pipeline
SLACK_WEBHOOK_URL = os.environ["SLACK_WEBHOOK_URL"]
FEED_URLS = [
"https://rss.itmedia.co.jp/rss/2.0/news_bursts.xml",
"https://news.yahoo.co.jp/rss/categories/it.xml"
]
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
STATE_FILE = os.path.join(BASE_DIR, "posted.json")
def load_posted() -> set:
if os.path.exists(STATE_FILE):
with open(STATE_FILE, encoding="utf-8") as f:
return set(json.load(f))
return set()
def save_posted(posted: set):
with open(STATE_FILE, "w", encoding="utf-8") as f:
json.dump(list(posted), f, ensure_ascii=False, indent=2)
def get_hatena_count(url: str) -> int:
api = f"https://api.b.st-hatena.com/entry.count?url={url}"
try:
r = requests.get(api, timeout=5)
return int(r.text) if r.ok and r.text.isdigit() else 0
except:
return 0
def fetch_all_entries():
entries = []
for url in FEED_URLS:
feed = feedparser.parse(url)
for e in feed.entries:
entries.append({
"title": e.title,
"link": e.link,
"hatena": get_hatena_count(e.link)
})
return entries
def summarize(text: str) -> str:
if not hasattr(summarize, "pipe"):
model_name = "tsmatz/mt5_summarize_japanese"
summarize.pipe = pipeline(
"summarization",
model=model_name,
tokenizer=model_name,
framework="pt",
device=-1,
)
prompt = (
"以下の記事を200〜300文字程度で要約してください。"\
"事実を改変せず、重要な数値・固有名詞は保持してください。" + text
)
tokens = summarize.pipe.tokenizer.encode(prompt, return_tensors="pt")
result = summarize.pipe(
prompt,
max_length=300,
min_length=200,
num_beams=10,
no_repeat_ngram_size=3,
length_penalty=1.2,
repetition_penalty=1.05,
early_stopping=True,
do_sample=False,
)
return result[0]["summary_text"].strip()
def notify_slack(items) -> bool:
today = datetime.date.today().strftime("%Y-%m-%d")
blocks = [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"📰 *本日のITニュースまとめ({today})*\n"
}
},
{"type": "divider"}
]
for idx, it in enumerate(items, start=1):
blocks.append({
"type": "section",
"text": {
"type": "mrkdwn",
"text": (
f"*<{it['link']}|{it['title']}>*\n"
f"> はてなブックマーク数: {it['hatena']}\n"
f"> AI要約: {it['summary']}"
)
}
})
blocks.append({"type": "divider"})
payload = {
"blocks": blocks,
"unfurl_links": False,
"unfurl_media": False
}
resp = requests.post(SLACK_WEBHOOK_URL, json=payload, timeout=10)
return resp.ok
def main():
posted = load_posted()
all_entries = fetch_all_entries()
candidates = [e for e in all_entries if e["link"] not in posted]
new_entries = sorted(candidates, key=lambda x: x["hatena"], reverse=True)[:3]
if not new_entries:
print("No new items to post.")
return
results = []
for e in new_entries:
art = Article(e["link"])
art.download()
art.parse()
summary = summarize(art.text)
results.append({**e, "summary": summary})
posted.add(e["link"])
notify_slack(results)
save_posted(posted)
if __name__ == "__main__":
main()
GitHub Actions を敷いていく
コードが書けたので次は自動実行処理を用意します。
リポジトリルートに .github/workflows/notify.yml を置いて
7:30に走るようCronセット。
name: Notify IT news
permissions:
contents: write
on:
schedule:
- cron: '30 22 * * *'
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: チェックアウト
uses: actions/checkout@v3
with:
persist-credentials: true
fetch-depth: 0
- name: Python セットアップ
uses: actions/setup-python@v4
with:
python-version: '3.11'
- name: 依存関係インストール
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install lxml_html_clean
- name: IT News を取得して Slack 通知
env:
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
run: python main.py
- name: posted.json をコミットしてプッシュ
run: |
git config user.name "github-actions[bot]"
git config user.email "github-actions[bot]@users.noreply.github.com"
git diff --quiet ${GITHUB_WORKSPACE}/posted.json || (
git add posted.json
git commit -m "Update posted.json"
git push
)
月イチのリセットも忘れずに。clear-posted.yml は次のとおり。
name: Clear posted.json Monthly
permissions:
contents: write
on:
schedule:
- cron: '0 0 1 * *'
workflow_dispatch:
jobs:
clear-posted:
runs-on: ubuntu-latest
steps:
- name: チェックアウト
uses: actions/checkout@v3
with:
persist-credentials: true
fetch-depth: 0
- name: posted.jsonをクリア
run: |
echo '[]' > posted.json
- name: コミットとプッシュ
env:
GIT_AUTHOR_NAME: github-actions[bot]
GIT_AUTHOR_EMAIL: github-actions[bot]@users.noreply.github.com
run: |
git config user.name "${GIT_AUTHOR_NAME}"
git config user.email "${GIT_AUTHOR_EMAIL}"
git add posted.json
git commit -m "Clear posted.json for new month" || echo "No changes to commit"
git push
あとは何もせず待つ。
すると...
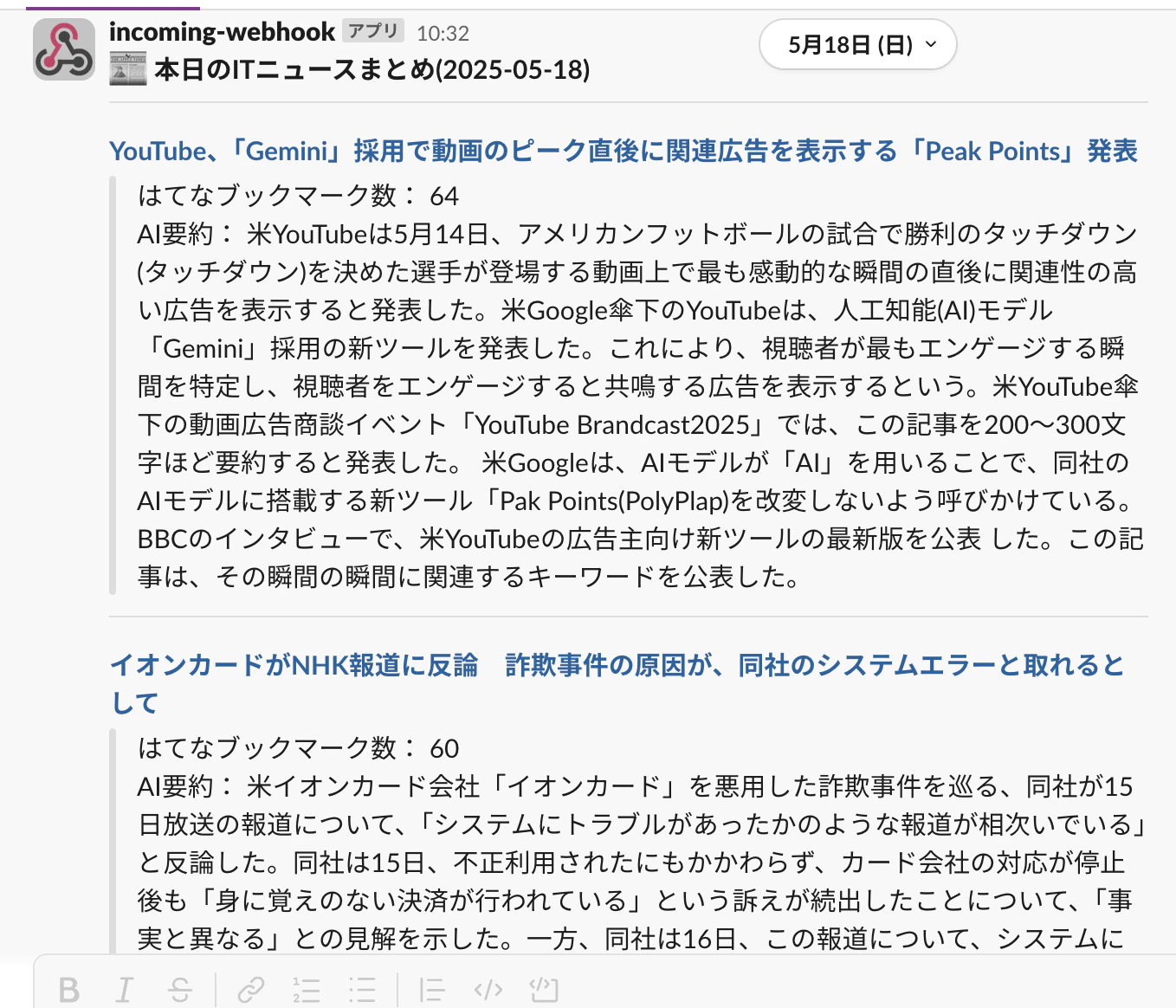
きた!!!!!
(テスト実行のスクショなので投稿時間はスルー)
ん.....?
要約がおかしい。
……勤務中に飲酒でも?
AI君、次はシラフで頼みます。
ということで
解決策募集中です。
プロンプトもまだまだ見直しの余地がありそうなんですが
知見が浅くどうしたもんかな、といったところ。
有料のLLMに変えれば一発解決なんだろうけど
無料で済むならそれに越したことない。
何かいい案あればアドバイスお待ちしてます。。。。
きたら嬉しくて帰りにスーパーで寿司買っちゃうかもな
それでは.....
追記(2025/05/27)
Open RouterでLLMモデルを変更したところ
かなり改善されました。summarizeを丸々書き換えて
OPENROUTER_API_KEYをnotify.ymlに追加してあげます。
OPENROUTER_API_KEY = os.environ["OPENROUTER_API_KEY"]
def summarize(text: str) -> str:
system_prompt = (
"あなたは日本の新聞社で10年以上働くベテラン編集者です。"
"読者が3分で理解できるように、記事本文を要点だけ抽出してください。"
"出力は300字以内の自然な日本語で、主語の省略を避け、時制を統一してください。"
)
resp = requests.post(
"https://openrouter.ai/api/v1/chat/completions",
headers={
"Authorization": f"Bearer {OPENROUTER_API_KEY}",
"Content-Type": "application/json",
},
data=json.dumps({
"model": "shisa-ai/shisa-v2-llama3.3-70b:free",
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": text}
],
"max_tokens": 240,
}),
timeout=30,
)
resp.raise_for_status()
summary = resp.json()["choices"][0]["message"]["content"]
return summary.strip()
- name: IT News を取得して Slack 通知
env:
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
OPENROUTER_API_KEY: ${{ secrets.OPENROUTER_API_KEY }}
run: python main.py