本記事はMLOps Advent Calendar 2020の13日目の記事です。
こんにちは。昨年本番環境のComposerでやらかしちゃった人です。今年は比較的平穏に機械学習を使用したサービス開発・運用に携われています。
携わっているサービスの1つで「MLOpsに必要な情報BigQueryに全部おいてみた」ところ想像以上に便利だったので、その方法について共有させてい頂ければと思います。
なお本記事でのMLOpsは
- 予測モデル/ハイパーパラメータのバージョン管理・デプロイ履歴管理
- 推論結果の精度監視 + 入力データの傾向監視
を指しています。
特に今年はコロナでビジネス環境が日々絶えず変化しているため、これらの施策がサービス品質担保に大きく貢献してくれました。
背景
毎日一回24時間先までバッチで未来予測し、結果をAPIサーバーにキャッシュする単純なMLサービスに携わっています。なお、予測に使用する入力データや、正解データはBigQueryに取り込まれています。
一応図にしてみましたが、普通のことしか書いていないですね。
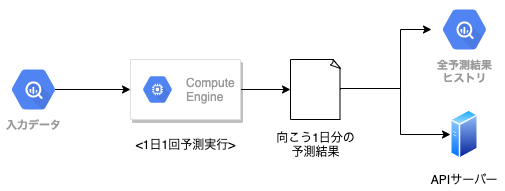
ただこのサービスは諸々の事情で予算が非常に厳しくAPIサーバーを除いてインスタンスを常駐させてはならないという司令が下りました。(バッチ処理時にインスタンス立ち上げるとかはOK。)
MLOpsのためAI Platform Pipeline (Kubeflow)やMLFlow Serverを常駐させて使ってみようと思った私には、大きなダメージ。
MLサービス運用してるのにMLOpsしないなんてとんでもない!と、低コストな解決方法を模索し、最終的にモデルファイル以外ほぼすべてをBigQueryに置く結論に至りました。
詳細
このMLOps法には、次のワークフローが登場します。ワークフローの入出力は基本的にすべてBQで、GCEインスタンス上で処理を実行します(適宜preemptiveインスタンスを使用しています)。なお、ワークフローの起点はCircleCIです。
- Trainer: 予測モデル学習と保存
- Tuner: ハイパーパラメータチューニング
- Deployer: 予測モデルを環境にデプロイ
- Predictor: デプロイされたモデルで推論
- Monitor(Prediction): 予測精度をモニタ
- Monitor(Data): 入力データの傾向監視
Trainer: 予測モデル学習と保存
事前に定義したハイパーパラメータで予測モデルを学習し、モデルを保存します。
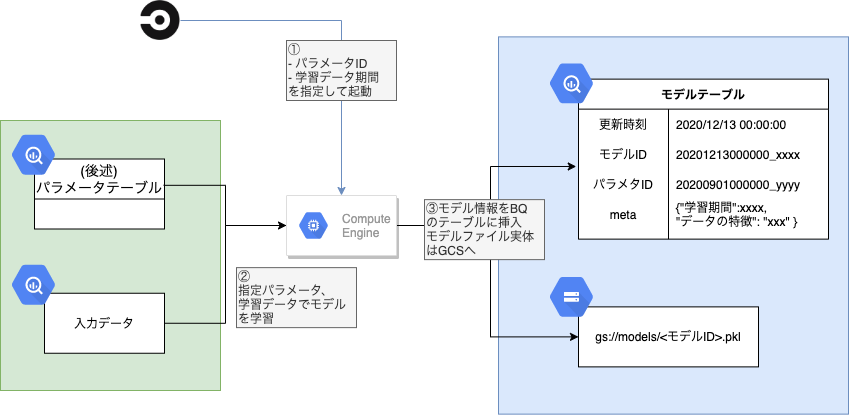
上図の通り、このワークフローは
- 学習期間
- パラメータid(後述)
を指定してGCEインスタンスで処理を行います。
GCEインスタンスでは指定した学習期間、パラメータで予測モデルを学習し、モデルファイルをGCSに保存します。
そして、
- モデル更新時間
- モデルのID (GCSのモデルファイルへのポインタに相当)
- 使用したパラメタのID
- その他メタ情報
- 学習データ期間
- 学習データのKPI(ユニークユーザー数など、後述のMonitor(Data)で監視している内容)
をBQのモデルテーブルに保存します。
Model Cards程ではありませんが、パラメータIDやメタ情報をモデルと一緒に保存しておくことで、モデルの素性を辿れるようにしているのがポイントです。
Tuner: ハイパーパラメータチューニング
ハイパーパラメータチューニングを行い、結果を保存します。
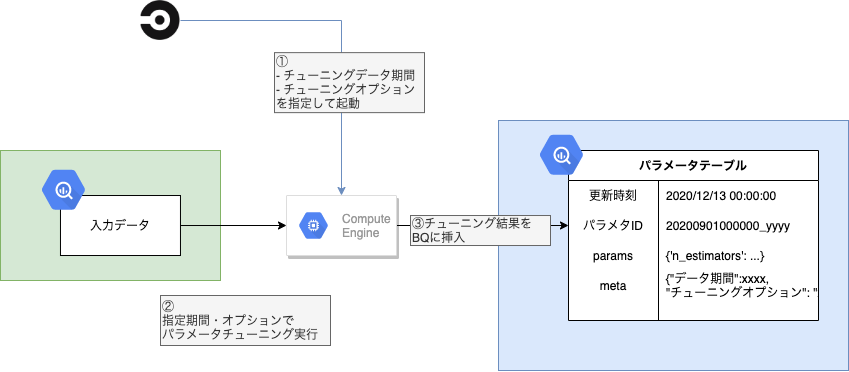
- パラメータチューニング期間
- チューニングオプション(Optuna等パラメータチューニングライブラリにわたすオプション)
を指定して起動しパラメータチューニングを実施。その結果をBQのパラメータテーブルに挿入します。挿入するのは次の情報です。
- パラメータ更新時刻
- パラメータID
- Trainerで参照したのはコレです
- params
- ハイパーパラメータの値をSTRUCTで記載
- その他メタ情報
- チューニングデータ期間や、チューニングライブラリに渡したオプション
ハイパーパラメータまで直でBQで管理してしまう、過激な発想です。
Deployer: 予測対象モデルを設定
Trainerでモデルテーブルに格納されたモデルを、prod/devといった環境にデプロイします。
デプロイといってもリアルタイム予測しているわけではないので、Predictor(後述)の予測に使うモデルにタグを付ける、程度のイメージです。そのタグ付けの全履歴を「デプロイ履歴テーブル」で管理しています。
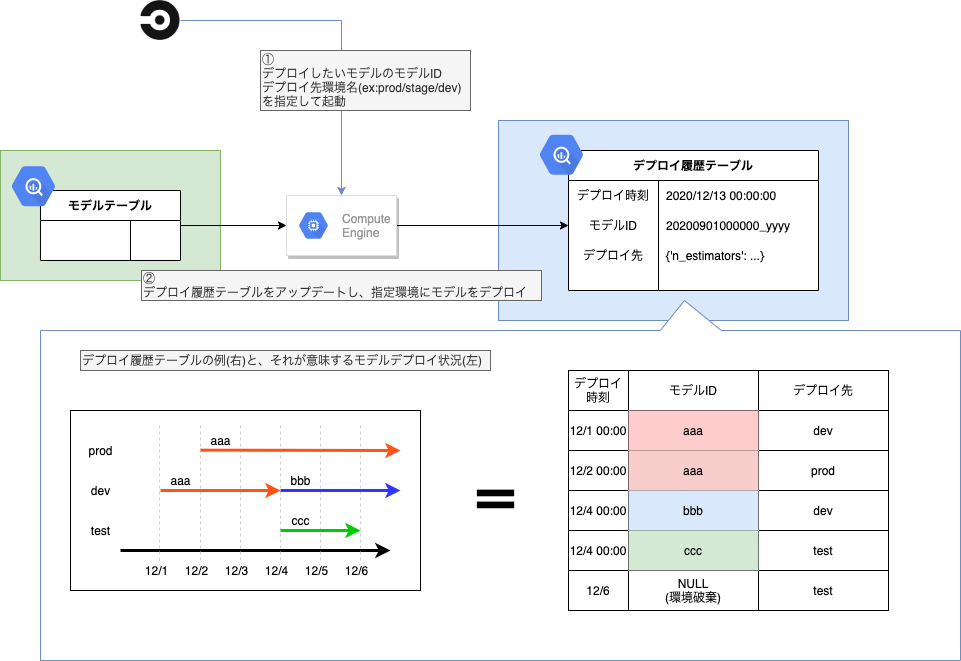
- デプロイしたいモデルのモデルID
- デプロイ先環境名
を指定してワークフローを起動すると、「デプロイ履歴テーブル」にデプロイ情報が1行追加されます。
デプロイ履歴テーブルは上図の通り、「どのモデルがどの環境にいつからデプロイされ始めたか」を管理しており、うまく集計することで環境とモデルの対応を時系列で確認出来ます。
Predictor: デプロイモデルで予測
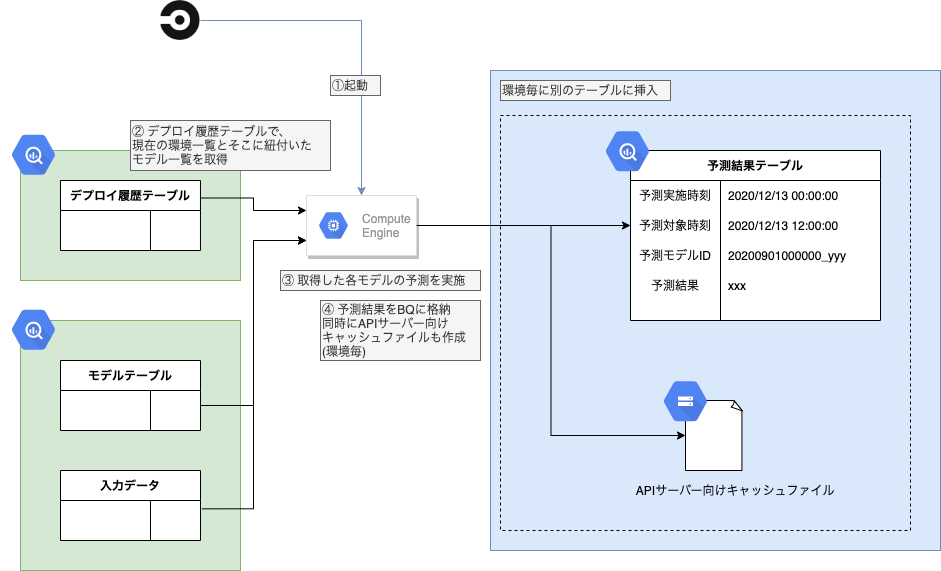
Predictorではまずデプロイ履歴テーブルを参照し、環境の一覧とそこに紐付いたモデルIDの一覧を取得します。その後、各環境について予測を行い、予測結果をBQに挿入します。またAPIサーバー向けのキャッシュファイルも同時に作成します。
ちょっと重要: Deployerでのデプロイから、APIサーバーの予測結果切り替えまでのタイムラグについて
この枠組ではDeployerとPredictorの動作タイミングに注意が必要です。
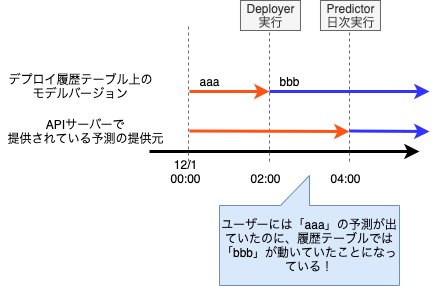
新モデルをDeployerでデプロイしてからPredictorで予測を行うまでは、「デプロイ履歴上は新モデルが動いているけど、APIサーバー(ユーザー)には旧モデルの結果が提示されていた期間」になってしまいます。PredictorがAPI向けキャッシュファイルを更新してから、APIサーバーがキャッシュを読み込むまでタイムラグがある場合、このズレの期間は更に増加します。
そこでユーザーに提示される予測結果が常にDeployerの最新モデルの予測結果と一致するよう、「Deployer実行後はPredictorが即時起動する」ワークフローとし、ズレを最小限にとどめています。(現在のサービス規模では、この程度の対処で十分と判断しています。)
Monitor(Prediction): 予測の精度監視
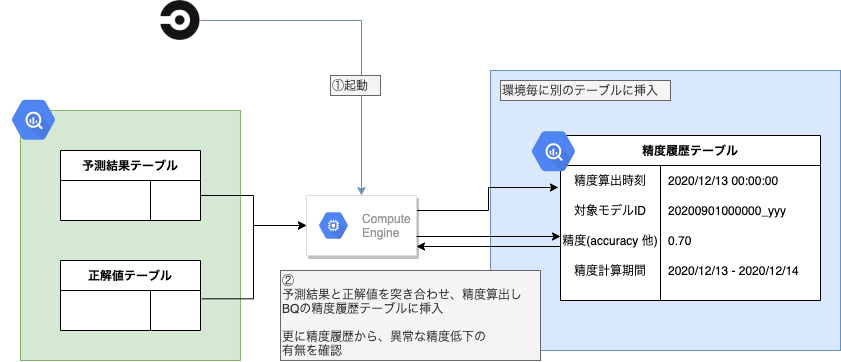
Monitor(Prediction)では予測値と正解値を比較し精度(accuracy 他)を算出、これをBQの精度履歴テーブルに格納します。また精度履歴テーブルを参照して精度の低下を監視します。(簡単のため図では省略していますが、すべてのデプロイ環境について処理を行っています。)
算出した精度や、精度低下のアラートはSlackで通知しています。
精度を常にトラッキングすることでモデルの劣化をいち早く検知し、Trainerによるモデル更新などのアクションにすぐ移れます。
Monitor(Data): 入力データの傾向監視
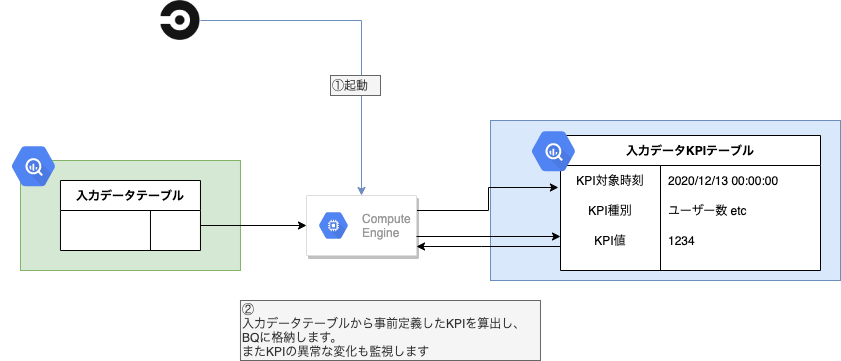
Monitor(Data)に似ていますが、こちらは入力データを監視します。事前定義したKPI(DAW、ユニークユーザー数のようなもの)を計算しBQに保存しておく他、その傾向監視も行います。Monitor(Prediction)同様Slack通知も行います。
Monitor(Prediction)で精度低下が確認された際は、まず真っ先にこのKPIを確認します。精度低下はたいてい外界(サービスを取り巻くビジネス環境)変化のため生じており、KPIにも何らかの変化が確認されることが多いです。Monitor(Prediction)とMonitor(Data)の結果を併せ見て、次のアクションを決定します。
入力データ取り込み系異常などシステム面での問題に気づけることもあります。
ところでMLOps関係ないですが、これのお陰でKPIをすぐに報告資料に差し込め、定期報告にとても便利です。(一番使用頻度高いテーブルかも…)
上記の枠組みを回してみて
コスト削減を目的として作ったドケチシステムでしたが、使うにつれその便利さに驚きました。なんせ、すべてがBigQueryに保存されていて、いつでも簡単にクエリ出来るんです。
精度比較などよくある話はもちろん、
- 入力データに異常が見つかったとして、それを使って学習したモデルがどれで、ユーザーにどの期間影響を及ぼしていたのか
- 予測結果が上振れしたとして、その原因は何なのか (学習データに使用した期間の正解値が高かった? ハイパーパラメータ切り替えた?)
など複雑な分析も、BQを離れることなく即座に実行できます。そしてBQなのでどんなクエリも高速です。
今年はコロナの影響も大きかったのですが、常に精度・KPIをトラッキング出来たので安心してMLサービスを提供し続けられました。MLOpsの重要性はいまいち認識されていない気もしますが、サービス規模を問わずすべてのサービスに導入しておくことを、強く推したいです。
(でもって低コストに導入したい場合、ぜひ本記事の方法を参考にして頂けると…)
ところで今回、モデルファイル本体はGCSに保存しましたがBigQuery ML使えばこれもBigQueryに寄せられ、「純度100%のBigQuery製MLOps」を名乗れるかも。
(あとはGCP詳しい諸氏からは、GCEじゃなくてCloud FunctionsやCloud Run使えとの指摘ありそう。)
これからも地道な改良を繰り返してゆきたいところです。