はじめに
前回までは、健康診断写真をアップロードし、項目の分析や永久保存、健診結果やユーザー設定に基づいての自動提案機能を実装してきました。
しかし、AIエージェントは従来のソフトウェアと異なり、同じ入力でも毎回異なる出力を返します。これにより、以下のような課題が生じます。
- エージェントがブラックボックスで、内部で何が起きているか分からない
- 誤った出力の原因特定ができない(プロンプト?ツール?LLMの判断?)
- プロンプト変更時に品質が下がったことに気づけない
- 出力の良し悪しを人間が毎回目視確認するしかなく、スケールしない
- Token使用量が見えず、コスト管理ができない
この記事では、MastraフレームワークのTraceとEvals機能、さらにLangfuseとの連携によって、これらの課題をどう解決できるかを実践的に解説します。
Part 1: Mastra Trace
1.1 Traceとは
エージェントの1回の実行全体をSpanの階層ツリーとして記録したものです。「何が・どの順番で・どれだけ時間がかかったか」を後から確認できます。
Mastraが出力するTraceデータはOpenTelemetry(OTel)準拠なので、Jaeger・Grafana・Datadogなど任意の対応ツールでそのまま可視化・分析できます。
1.2 Spanとは
Traceを構成する一つひとつの処理ブロックをSpanと呼びます(LLM呼び出し、ツール実行など)。Mastraが自動生成するため、開発者による計装は不要です。
Span種別
| spanType | 表示名 | 意味 |
|---|---|---|
agent_run |
Agent | エージェント全体の1回の実行(ルートSpan) |
model_generation |
Model | LLMへの全API呼び出しをまとめた親Span |
model_step |
Step: N | LLMへの1回のAPI呼び出し(ステップごと)。ツール使用時は複数stepになる |
tool_call |
Tool | ツールの1回の実行(DB問い合わせ等の実処理) |
model_chunk |
Chunk | LLMがStreamingで返すレスポンスの断片。nameで種類が分かれる:text(テキスト出力)/ tool-call(ツール呼び出し指示)/ tool-result(ツール結果の返却) |
processor_run |
Processor | 会話記録をMemory読み書き等 |
1.3 Studio UI
http://localhost:4111/observability でTrace一覧を確認できます。各Traceをクリックすると、Spanのツリーと詳細が表示されます。
1.4 Trace例
スケジュール確認
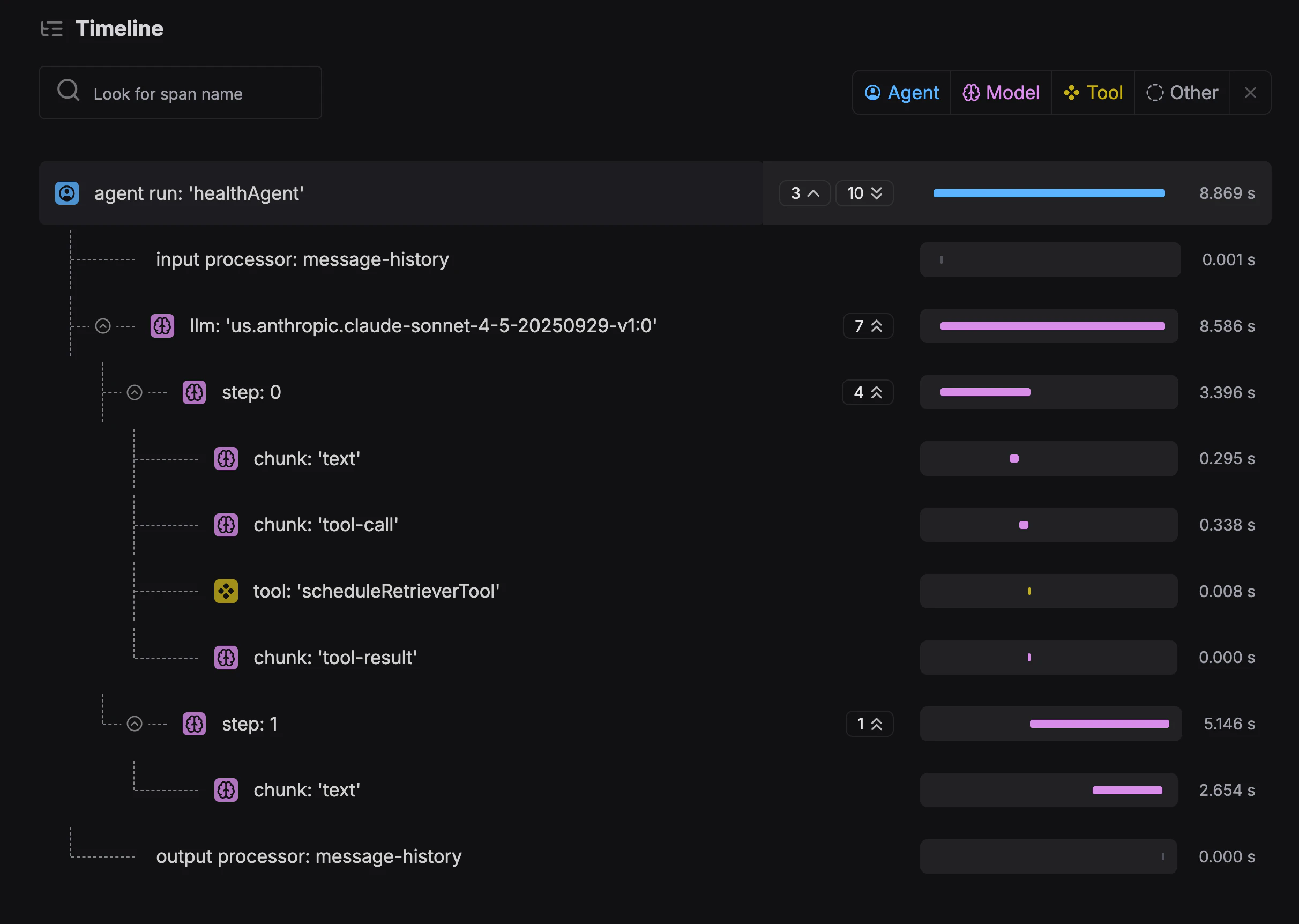
agent run: 'healthAgent' (全体: 56秒)
├─ input processor: message-history (Memoryからスレッド履歴読み込み)
├─ llm: 'claude-sonnet-4-5' (LLM全体)
│ ├─ step: 0 (1回目LLM → ツール呼び出しを決定)
│ │ ├─ chunk: 'text' (「スケジュールを確認します」等のテキスト)
│ │ ├─ chunk: 'tool-call' (scheduleRetrieverTool呼び出し)
│ │ ├─ tool: 'scheduleRetrieverTool' (DB問い合わせ: 0.06秒)
│ │ └─ chunk: 'tool-result' (ツール結果をLLMに返却)
│ └─ step: 1 (2回目LLM → ツール結果を元に最終回答)
│ └─ chunk: 'text' (スケジュール内容の説明テキスト)
├─ output processor: message-history (Memoryにスレッド履歴保存)
└─ [scorer spans] (評価スコアの計算)
スケジュール新規作成
agent run: 'healthAgent'
├─ input processor: message-history
├─ llm: 'claude-sonnet-4-5'
│ ├─ step: 0 (1回目LLM → ツール呼び出し決定)
│ ├─ step: 1 (2回目LLM)
│ │ ├─ tool: 'healthContextTool' (健康データ取得: 0.06秒)
│ │ └─ chunk: 'tool-result'
│ ├─ step: 2 (3回目LLM → スケジュール生成を決定)
│ │ ├─ tool: 'scheduleGeneratorTool' (スケジュール生成+DB保存: 27秒)
│ │ └─ chunk: 'tool-result'
│ └─ step: 3 (4回目LLM → ユーザーへの最終説明)
│ └─ chunk: 'text'
├─ output processor: message-history
└─ [scorer spans]
1.5 Token消費の確認
各 model_step Spanの attributes に記録されます。
stepは
model_stepSpanの別名。全てSpanだが、LLM呼び出しのSpanだけをstepと呼ぶ。
{
"usage": {
"inputTokens": 5588,
"outputTokens": 98
}
}
model_generation(LLM親Span)には合計値が記録されます。
{
"usage": {
"inputTokens": 18131,
"outputTokens": 3340
}
}
Token料金
Input tokenとOutput tokenは料金が異なります。Output tokenの方が高いです。
| Claude Sonnet 4.5(Bedrock)料金(1MTokenあたり) | |
|---|---|
| Input token | $3.00 |
| Output token | $15.00(Inputの5倍) |
上記の合計値で計算すると:
Input: 18,131 tokens × $3.00/1M = $0.054
Output: 3,340 tokens × $15.00/1M = $0.050
合計: 約 $0.10(約15円)/ 1リクエスト
1.6 Observability設定
// src/mastra/index.ts
import { Observability, DefaultExporter } from '@mastra/observability';
export const mastra = new Mastra({
observability: new Observability({
configs: {
default: {
serviceName: 'health-checkup',
exporters: [new DefaultExporter()], // → mastra_ai_spans テーブルに書き込み
},
},
}),
});
1.7 Trace関連テーブル
Mastra v1がPostgreSQLに自動作成するテーブル群:
| テーブル | 役割 | 主要カラム |
|---|---|---|
mastra_ai_spans |
全Spanの記録(メインテーブル) |
traceId, spanId, parentSpanId, name, spanType, attributes, input, output, startedAt, endedAt
|
mastra_traces |
旧バージョン互換用 |
id, traceId, name, startTime, endTime
|
Part 2: Mastra Evals
2.1 Evalsとは
エージェントの応答品質を定量的に評価する仕組みです。各Traceに対してScorer(scorer)を実行し、0〜1のスコアを記録します。
2.2 実装したScorer一覧(6つ)
| Scorer | 種別 | 対象ユースケース | 評価内容 |
|---|---|---|---|
completenessScorer |
コード | 全て | 応答の網羅性 |
saveHealthCheckToolScorer |
コード | 画像保存 |
save-health-checkが呼ばれたか |
healthItemCountScorer |
LLM judge | 画像保存 | 保存された検査項目の件数 |
scheduleCreationToolScorer |
コード | スケジュール作成 |
get-health-context→generate-weekly-scheduleの順で呼ばれたか |
scheduleRetrievalToolScorer |
コード | スケジュール確認 |
get-current-scheduleが呼ばれたか |
trendAnalysisToolScorer |
コード | トレンド分析 |
generate-health-trend-chartが呼ばれたか |
2.3 ユースケース別自動選択
メッセージ内容と画像有無から、適切なscorerセットを自動で選択します。
| ユースケース | 判定条件 | 適用Scorer |
|---|---|---|
| 健康診断画像の保存 | 画像あり | completeness + saveHealthCheckTool + healthItemCount |
| スケジュール新規作成 | 「作成」「プラン」等 | completeness + scheduleCreationTool |
| トレンド分析 | 「傾向」「推移」等 | completeness + trendAnalysisTool |
| スケジュール確認 | 「スケジュール」「予定」等 | completeness + scheduleRetrievalTool |
| その他の会話 | 上記以外 | completeness のみ |
2.4 評価関連テーブル
| テーブル | 役割 | 主要カラム |
|---|---|---|
mastra_scorers |
スコア結果の記録(メインテーブル) |
scorerId, traceId, spanId, score(0〜1), reason, preprocessStepResult, analyzeStepResult, source(LIVE/TEST) |
mastra_evals |
旧バージョンの評価結果 |
agent_name, metric_name, result, input, output
|
mastra_scorer_definitions |
Scorer定義の管理 |
id, status, activeVersionId
|
データ・実験系(未使用)
mastra_datasets / mastra_dataset_items / mastra_experiments / mastra_experiment_results
Part 3: Langfuse連携
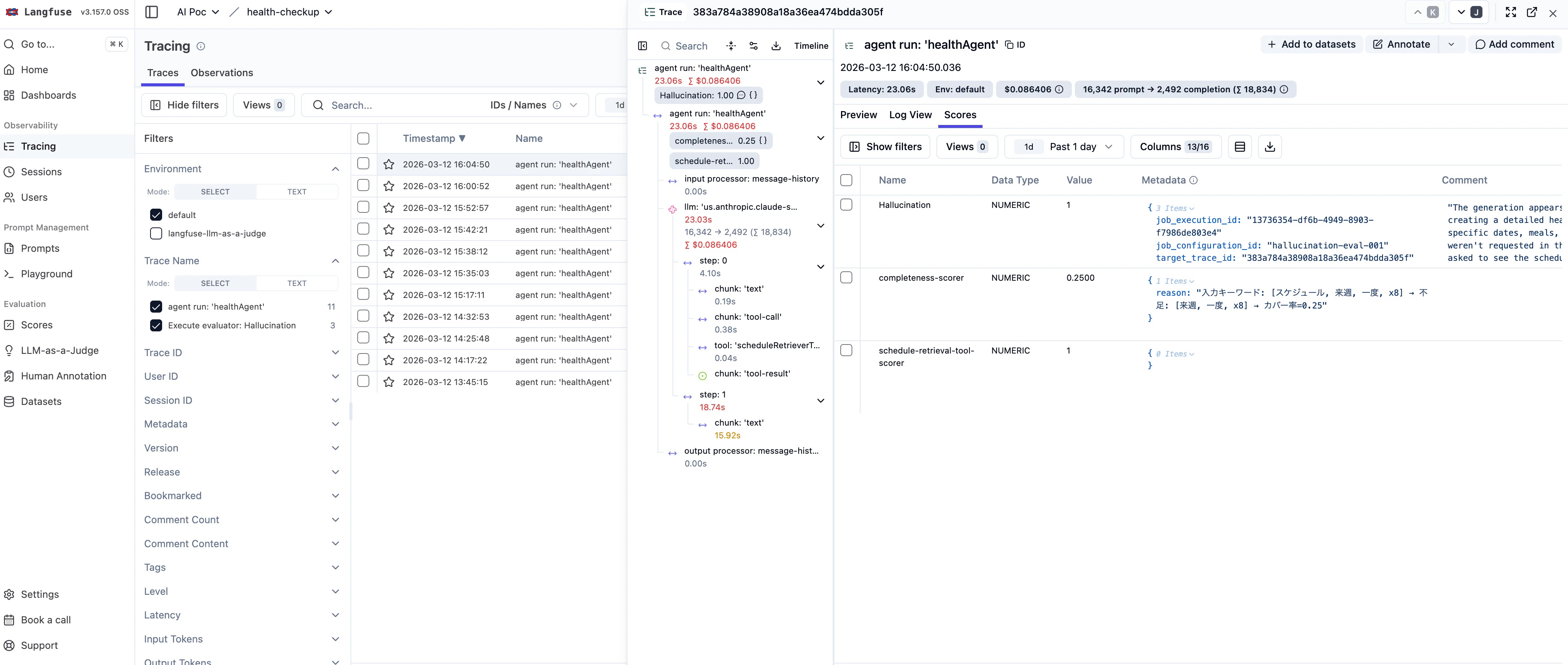
3.1 Langfuseとは
OSSのLLM Observabilityプラットフォームです。セルフホスト(Docker Compose)またはクラウド版(langfuse.com)で利用できます。
主な機能:
- Traces: 各エージェント実行のSpanツリー(フィルタ・検索対応)
- Sessions: スレッド単位の会話履歴
- Generations: LLM呼び出しごとのInput/Output/Token数/Latency
- Scores: Mastra Scorerの評価結果 + Langfuse Evaluatorの評価結果
- Dashboard: 日次のリクエスト数・Latency・コスト・スコアのグラフ
3.2 Trace転送の仕組み
Mastraはエージェント実行時に、業界標準のOpenTelemetry(OTel)形式でSpanデータを自動生成します。LangfuseExporterを追加するだけで、このデータがLangfuseにも自動送信されます。Langfuse用の特別なコードを書く必要はなく、Exporterを1つ追加するだけで連携が完了します。
エージェント実行
│
├─ Mastra Observability (OTelSpan生成)
│ │
│ ├─ DefaultExporter → mastra_ai_spans テーブル (Mastra Studio用)
│ │
│ └─ LangfuseExporter (OTelSpan → Langfuse形式に変換して送信)
│ │
│ ├─ agent_run → Langfuse Trace
│ ├─ model_generation → Langfuse Generation (model, usage, parameters付き)
│ ├─ tool_call → Langfuse Span
│ └─ model_chunk → Langfuse Event
│
└─ 両方に同じTraceデータが並行送信される
3.3 Scorer結果の自動連携
Mastra Scorerの評価結果も、LangfuseExporter内部のaddScoreToTrace()メソッドを通じてLangfuseのscore() APIを呼び出すことで、Langfuse上に自動表示されます。
Mastra Scorer実行完了
│
├─ DefaultExporter → mastra_scorers テーブル
│
└─ LangfuseExporter.addScoreToTrace()
│
└─ langfuse.score({
traceId, // 対象TraceID
observationId: spanId, // 対象SpanID
name: scorerName, // e.g. "completeness-scorer"
value: score, // 0〜1
dataType: "NUMERIC",
metadata: { reason } // スコアの根拠
})
3.4 Langfuse Managed Evaluators(内蔵LLM-as-a-Judge)
Mastra Scorerとは別に、Langfuse側でもLLM-as-a-Judgeによる自動評価が可能です。Langfuse UIの Evaluators タブからTemplateを選んで設定します。評価にはLLM API呼び出しが必要です(Bedrock等を LLM Connection として設定)。
Template一覧
| Evaluator | 評価内容 | 0の意味 | 1の意味 | 適合度 |
|---|---|---|---|---|
| Hallucination | 回答に事実と異なる内容(幻覚)がないか | 幻覚なし(事実に忠実) | 完全に幻覚(捏造) | 要カスタマイズ ※ |
| Helpfulness | 回答がユーザーにとって有用か | 全く役に立たない | 非常に有用 | 高 |
| Relevance | 質問に対して回答が関連しているか | 完全に無関係 | 完全に関連 | 高 |
| Correctness | 回答が正解と一致しているか(期待出力が必要) | 完全に不正解 | 完全に正解 | △(Dataset Experiments専用) |
| Conciseness | 回答が簡潔か | 非常に冗長 | 簡潔で無駄がない | 中 |
| Toxicity | 有害・不適切な内容がないか | 無害 | 非常に有害 | 低 |
| Context Relevance | RAG取得コンテキストが質問に関連しているか | 完全に無関係 | 完全に関連 | 高(RAG向け) |
| Context Correctness | RAGコンテキストが正確か | 完全に不正確 | 完全に正確 | 中(RAG向け) |
Hallucination と Toxicity はスコアが高いほど悪い(1 = 幻覚/有害)。それ以外はスコアが高いほど良い(1 = 有用/関連/正解)。
Hallucinationについて: デフォルトTemplateはシンプルなQ&A向けです。ツールでDBからデータを取得するエージェントでは、正しく取得したデータも「捏造」と誤判定されます。使用する場合はプロンプトのカスタマイズが必要です。
3.5 セルフホスト構成
Docker Composeで以下のサービスを追加します。
| サービス | 役割 |
|---|---|
langfuse-web |
Langfuse WebUI (port 13000) |
langfuse-worker |
バックグラウンドワーカー |
langfuse-db |
Langfuse専用PostgreSQL |
langfuse-clickhouse |
分析用カラムナーDB |
langfuse-redis |
キャッシュ・キュー |
langfuse-minio |
S3互換オブジェクトストレージ |
3.6 導入手順
Step 1: パッケージインストール
pnpm add @mastra/langfuse
Step 2: docker-compose.yml にLangfuseサービスを追加
既存の健康診断DBとは別に、Langfuse専用のPostgreSQL・ClickHouse・Redis・MinIOを追加します。ポートは既存と衝突しないように 13000(Web UI)、19090(MinIO)を使用します。
# Langfuse - LLM Observability Platform
langfuse-worker:
image: langfuse/langfuse-worker:3
depends_on: &langfuse-depends-on
langfuse-db: { condition: service_healthy }
langfuse-minio: { condition: service_healthy }
langfuse-redis: { condition: service_healthy }
langfuse-clickhouse: { condition: service_healthy }
environment: &langfuse-env
DATABASE_URL: postgresql://postgres:postgres@langfuse-db:5432/langfuse
CLICKHOUSE_URL: http://langfuse-clickhouse:8123
CLICKHOUSE_MIGRATION_URL: clickhouse://langfuse-clickhouse:9000
CLICKHOUSE_USER: clickhouse
CLICKHOUSE_PASSWORD: clickhouse
CLICKHOUSE_CLUSTER_ENABLED: "false"
REDIS_HOST: langfuse-redis
REDIS_AUTH: langfuseredis
# ... (S3・MinIO設定省略)
langfuse-web:
image: langfuse/langfuse:3
ports:
- "13000:3000"
environment:
<<: *langfuse-env
NEXTAUTH_URL: http://localhost:13000
NEXTAUTH_SECRET: <generated-secret>
Step 3: Mastra ObservabilityにLangfuseExporterを追加
// src/mastra/index.ts
import { LangfuseExporter } from '@mastra/langfuse';
export const mastra = new Mastra({
observability: new Observability({
configs: {
default: {
serviceName: 'health-checkup',
exporters: [
new DefaultExporter(), // → Mastra Studio用
new LangfuseExporter({ // → Langfuse用
publicKey: process.env.LANGFUSE_PUBLIC_KEY,
secretKey: process.env.LANGFUSE_SECRET_KEY,
baseUrl: process.env.LANGFUSE_BASE_URL,
}),
],
},
},
}),
});
Step 4: 環境変数を設定
LANGFUSE_PUBLIC_KEY=pk-lf-xxxxx # Langfuse UIで生成
LANGFUSE_SECRET_KEY=sk-lf-xxxxx # Langfuse UIで生成
LANGFUSE_BASE_URL=http://localhost:13000
環境変数名は LANGFUSE_BASE_URL(アンダースコア区切り)です。LANGFUSE_BASEURL では認識されません。
Step 5: 起動・確認
# 全サービス起動
docker compose up -d
# Langfuse UI: http://localhost:13000
# 1. アカウント作成 → Organization作成 → Project作成
# 2. Settings → API Keys → Create New API Keys
# 3. 取得したキーを .env に設定
# 4. ダッシュボード再起動後、エージェントを使うとTracesにTraceが表示される
Part 4: ビジュアル比較
Mastra Studio UI
Langfuse
まとめ
Mastra Traceでエージェント内部の処理フローを可視化し、Evalsで応答品質を自動スコアリングできるようになりました。さらにLangfuseを連携することで、コスト分析やチームでの共有・運用にも対応できます。今後はDatasets & Experimentsによるプロンプト変更前後のA/Bテストや、CI/CDパイプラインへの品質ゲート組み込みなど、さらなる拡張も期待できます。