はじめに
最近、画像認識分野では MetaのSAM シリーズが大きな注目を集めています。
特に最新の SAM3 は、セグメンテーションの精度や汎用性が飛躍的に向上しています。
この強力なモデルを使って何か便利なアプリが作れないかと考え、「画像の中にある探し物をAIに見つけてもらうアプリ」 を開発しました。
単にSAM3を使うだけでなく、LLMを介在させることで、誰でも自然な言葉で指示を出せるようにしたのがポイントです。
今回はその仕組みと、ChatGPTやGeminiといった汎用的なLLMサービスとの性能比較について紹介します。
なお、本記事で登場する画像は全てフリー素材を用いています。
作ったもの
「SALLM」
名前はGeminiに考えてもらいました。SAM + LLMが由来です。
画像を貼り付けて探したいものをチャットで伝えるだけで、AIがその場所を特定してバウンディングボックスを表示してくれるWebアプリです。
主な機能は以下の3つです。
- 画像のアップロード & プレビュー
- 自然言語による検索指示(「赤い車を探して」「右下の猫」など)
- SAM3による検出 & バウンディングボックス描画
1. 「言葉」で画像検索
通常の物体検出では、事前に学習されたクラス(「犬」「車」など)しか検出できないことが多いですが、SAM3では物体検出なら何でも行えるため、LLMに検出したい物体について説明すると、 LLMがユーザーの言葉を解釈 し、SAM3への最適なプロンプトを生成します。
例えば、社内の画像をアップロードして、「資料印刷したいんだけどプリンターってどこにある?」 と聞くと...
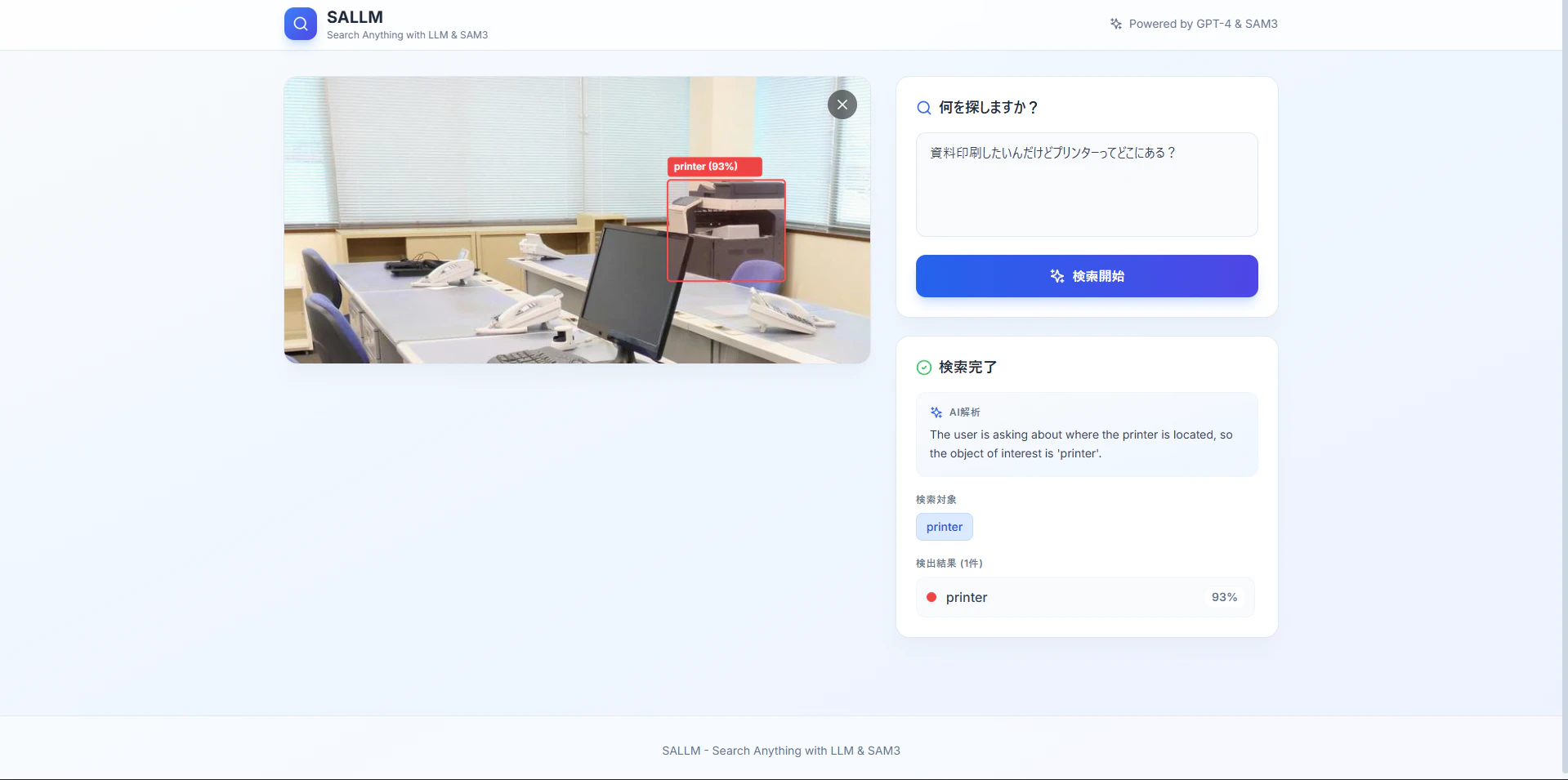
このように、LLMが「プリンター」という意図を汲み取り、SAM3に渡すことで正確に場所を特定してくれます。
2. LLMによる「翻訳」機能
このアプリでは、ユーザーの曖昧な指示をSAM3が理解できる形式に変換してくれます。
例えば、ユーザーが 「右らへんにいる猫ってどこにいますか」 と入力しました。
- ユーザー入力: 「右らへんにいる猫ってどこにいますか」
-
LLMの処理: 画像内の位置関係や形容詞を整理し、SAM3へのプロンプトとして
cat on the right sideを生成 - SAM3: 生成されたプロンプトを元にセグメンテーションを実行
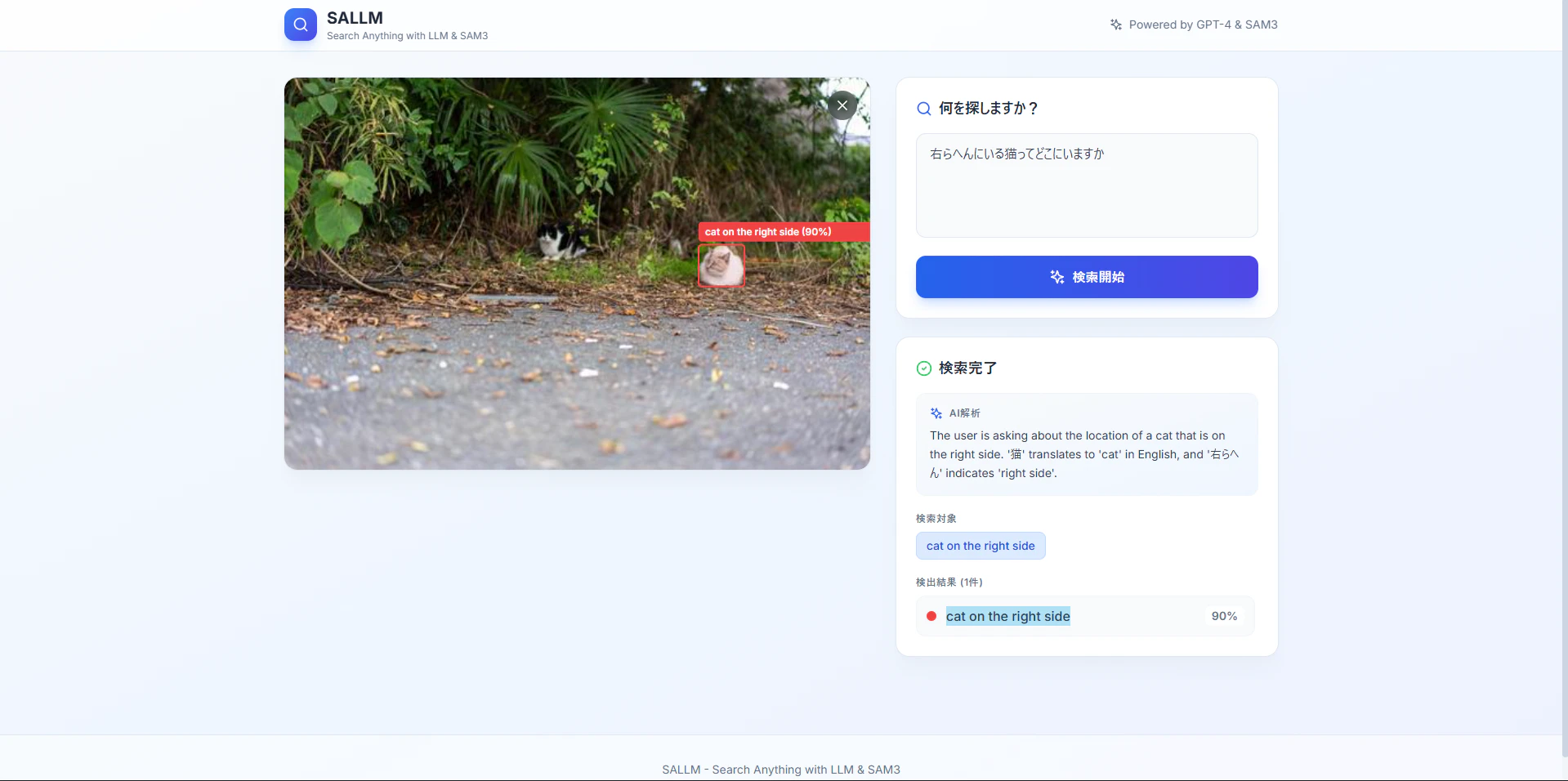
直接SAM3に曖昧な自然言語で指示するよりも、LLMを挟むことでより適切な指示が可能になります。
3. バウンディングボックスによる可視化
ユーザーが一目で「どこにあるか」を把握しやすいように、SAM3で検出された物体をバウンディングボックス で表示しています。
汎用的なLLMサービスとの性能比較
「画像を解析して場所を教える」だけであれば、汎用的なLLMサービスでも可能だと思ったので、検証してみました。結果としては、実際に同じタスクを行わせて比較したところ、処理速度と網羅性において圧倒的な差が出ました。
テスト内容: 以下のような道路の画像をアップロードし、「標識を探して」と指示する。(ChatGPTやGeminiにはもう少し詳しく、元画像にバウンディングボックスを付加して表示するようプロンプトを組みました。)

実行結果はそれぞれ以下の通りです。
| SALLM | ChatGPT | Gemini | |
|---|---|---|---|
| 実行時間 | 約1秒 | 約4分 | 計測不能 |
| 結果 | 全ての標識を検出 | 一番目立つ標識のみ検出 | 生成失敗 |
ChatGPTにこれを行わせると、推論に時間がかかり、結果が出るまでに約4分必要でした。また、結果は一番目立つ標識しか認識してくれませんでした。また、Geminiではそもそも生成を行うことに失敗してしまいました。
一方、今回のアプリでは、LLMは「プロンプト生成」のみに特化し、検出は高速なSAM3に任せるという役割分担ができているため、わずか1秒程度ですべての標識を網羅することができました。
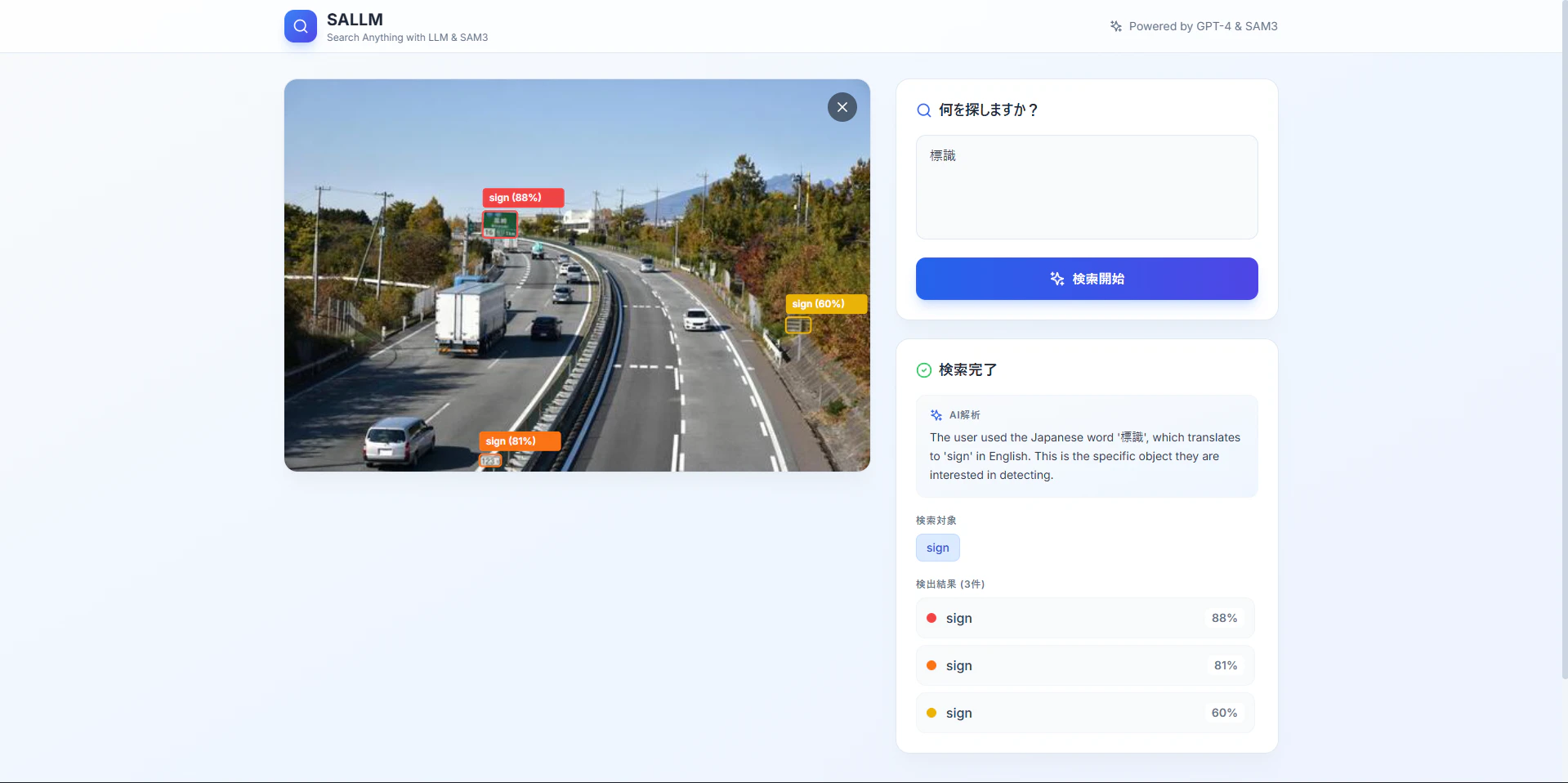
特定のタスクにおいては、汎用モデル単体よりも、適切なモデルを組み合わせたパイプラインの方が圧倒的に高性能であることがわかります。
汎用モデルは「なんでもできる」反面、特定のタスク(特に画像への正確な描画など)においては、ガードレールや処理速度の面で使い物にならないケースがあります。
「適切なモデルを組み合わせた専用パイプライン」 を組むことの重要性が、この比較からもよく分かりました。
技術スタック
今回は Python + TypeScript という構成で構築しました。
バックエンド
- 言語: Python
- フレームワーク: FastAPI
-
AIモデル:
- LLM: GPT-4o
- Vision Model: SAM3
フロントエンド
- 言語: TypeScript
- フレームワーク: React / Next.js
- スタイリング: Tailwind CSS
作ってみて分かったこと
1. 誰でも気軽にSAM3を試せる
これが一番のメリットだと感じました。
通常、SAM3のような最新モデルを試すには、Pythonスクリプトを書いたり、特定のフォーマットでプロンプトを入力したりする必要があります。これは、エンジニア以外にはややハードルが高いです。
しかし、LLMを挟むことで、「自然言語」という最も直感的なインターフェース でSAM3を操作できるようになります。適当な指示でも、LLMが良い感じに変換してくれるため、専門知識がない人でも気軽にプロンプトを作って、最新のSAM3の性能をフルに試せる ようになりました。
2. LLM × SAM3 の相性の良さ
比較検証でも触れましたが、SAM3は非常に高性能ですが、入力プロンプトを作成する必要があります。ここを人間にやらせるのではなく、「指示出しが得意なLLM」に任せる という構成によって自然言語で簡単にプロンプトを作成してくれるのは非常に強力でした。
ユーザーが多少曖昧な言い方をしても、LLMが文脈を補完してSAM3に伝えてくれるため、UXが格段に向上しました。
3. Structured Outputsの有用性
今回の開発において、 Structured Output(構造化出力) を活用しました。
LLMをシステムに組み込む際、最大の課題となるのが 「出力フォーマットの不安定さ」 です。
通常、LLMに「JSONで返して」と頼んでも、余計な会話文(「はい、こちらがJSONです」など)が含まれたり、JSON構文が崩れていたりして、バックエンドでパースエラーを引き起こすことがあります。
そこで今回は、OpenAI APIのStructured Output機能を活用し、厳密なJSON構造での出力を強制しました。これによって、システムによる正確な情報抽出を可能にすることができました。
おわりに
今回は、最新のSAM3とLLMを組み合わせて、対話的に画像内の物体を探せるアプリを作ってみました。
ChatGPTのような汎用LLMサービスも便利ですが、特定の目的に絞って適切なモデルを組み合わせることで、速度、検出精度ともに上回る結果を出すことができました。
今後も何か面白い機能が思いついたら追加してみたいと思っています。