Oracle Cloud Infrastructure(OCI)Data Flowは、Apache Spark ™アプリケーションを実行するためのフルマネージド・サービスです。特に大規模なデータの処理に向きます。
OCIオブジェクト・ストレージ上のファイルを読み込み、Autnomous DBへのデータロード処理を例にして、OCI Data Flowでの実現方法を三回を分けて紹介したいと思います。
- Part 1: Apache Sparkを使って、ローカル環境でPythonプログラムを実行する方法。
- Part 2: アプリケーションをOCIへデプロイし、実行する方法。
-
Part 3 (本文): プライベート・エンドポイントを経由し、ADBへデータをロードする方法。
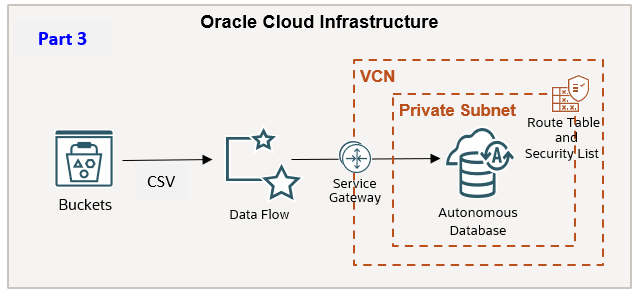
ステップ
1. 事前準備
1-1. 関連OCIリソースの作成
IAMリソース
| リソース・タイプ | 名前 | コメント |
|---|---|---|
| コンパートメント | PoC | 検証用コンパートメント |
| バケット | dataflow-logs | データ・ロード・ログの格納先 |
| グループ | Data_Flow_Grp | 検証用ユーザーを入れる |
| ポリシー | Data_Flow_Policy |
ポリシーのステートメント:
Allow group Data_Flow_Grp to read buckets in compartment PoC
Allow group Data_Flow_Grp to manage dataflow-family in compartment PoC
Allow group Data_Flow_Grp to manage objects in compartment PoC where ALL {target.bucket.name='dataflow-logs', any {request.permission='OBJECT_CREATE', request.permission='OBJECT_INSPECT'}}
ネットワーク・リソースとインスタンス
| リソース・タイプ | 項目 | 内容 | コメント |
|---|---|---|---|
| Subnet | タイプ | プライベート | ADBとComputeの格納先 |
| Service GW | サービス | All <Region_Key> Services in Oracle Services Network |
データ・フローから、プライベートADBに接続 |
| NAT GW | ローカルのVMから、外部へアクセス | ||
| Route Table | ルール | ターゲット: Service GW 宛先: All <Region_Key> Services in Oracle Services Network
|
|
| ルール | ターゲット: NAT GW 宛先:0.0.0.0/0 |
||
| Security List | Ingress | XX.XX.XX.XX/32, TCP 22 | 踏み台のIP アドレスを指定 |
| Egress | 0.0.0.0/0, 全てのプロトコル | ||
| Autonomous DB | ワークロード・タイプ | データ・ウェアハウス | |
| アクセス・タイプ | プライベート・エンドポイント | Walletで接続 | |
| Compute | OS | Oracle Linux 8 | |
| 用途 | 1.ローカル環境での動作確認 2. アーカイブファイルの作成 |
プライベート・サブネットにあるので、踏み台を経由してアクセスする。 |
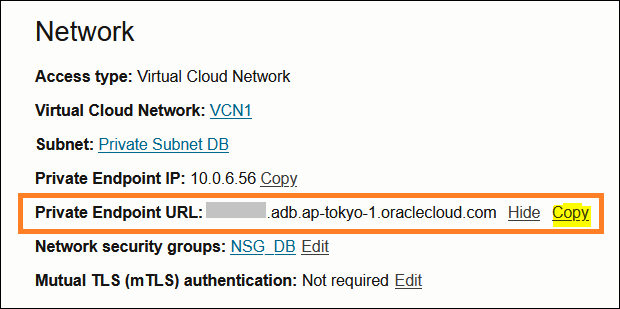
ADBプライベート・エンドポイントURLの取得
ADBの詳細画面から、URLをコピーしておいてください(STEP 2-1で使う)。
1-2. ローカル環境での動作確認
アプリケーションをOCIへデプロイする前、ローカル環境での動作確認を強く推奨します。詳細は、前回(Part 1)の記事をご参照ください。
※、検証用のソース(Python)は、パブリックADBの例でしたが、プライベートADBにも適用します。
1-3. Docker のインストールと起動
前回のPart 2で紹介した内容と同じです。既に実施した場合、このステップを飛ばしてください。
Docker のインストール
sudo dnf install -y dnf-utils zip unzip
sudo dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
sudo dnf install -y docker-ce --nobest
Docker の起動
[opc@linux8-private ~]$ sudo systemctl start docker
[opc@linux8-private ~]$ sudo systemctl enable docker
Created symlink /etc/systemd/system/multi-user.target.wants/docker.service ¨ /usr/lib/systemd/system/docker.service.
[opc@linux8-private ~]$
1-4. アーカイブ(archive.zip)の作成
前回のPart 2で紹介した内容と同じです。既に実施した場合、このステップを飛ばしてください。
パッケージャ・ツール・イメージをダウンロードします。
コマンド:sudo docker pull phx.ocir.io/oracle/dataflow/dependency-packager:latest
[opc@linux8-private ~]$ sudo docker pull phx.ocir.io/oracle/dataflow/dependency-packager:latest
latest: Pulling from oracle/dataflow/dependency-packager
<中略>
Status: Downloaded newer image for phx.ocir.io/oracle/dataflow/dependency-packager:latest
phx.ocir.io/oracle/dataflow/dependency-packager:latest
[opc@linux8-private ~]$
一時フォルダ(/tmp/shared)を用意してください。requirements.txt(1行のみ)を作成し、関連のJARファイルと共にその下に保存します。
mkdir /tmp/shared
chmod 777 /tmp/shared
echo oci > /tmp/shared/requirements.txt
cp -p /home/opc/download/ojdbc/ojdbc11.jar /tmp/shared
cp -p /home/opc/download/ojdbc/ucp11.jar /tmp/shared
cp -p /home/opc/download/ojdbc/oraclepki.jar /tmp/shared
cp -p /home/opc/download/hdfs/third-party/lib/bcpkix-jdk15on-1.70.jar /tmp/shared
cp -p /home/opc/download/hdfs/third-party/lib/bcprov-jdk15on-1.70.jar /tmp/shared
dockerコマンドでアーカイブを作成します。
コマンド:sudo docker run --rm -v $(pwd):/opt/dataflow --pull always -it phx.ocir.io/oracle/dataflow/dependency-packager:latest -p 3.8
[opc@linux8-private ~]$ cd /tmp/shared
[opc@linux8-private shared]$ ll
total 15452
-rw-r--r--. 1 opc opc 963713 Mar 11 05:01 bcpkix-jdk15on-1.70.jar
-rw-r--r--. 1 opc opc 5867298 Mar 11 05:01 bcprov-jdk15on-1.70.jar
-rw-r--r--. 1 opc opc 6971601 Mar 29 08:57 ojdbc11.jar
-rw-r--r--. 1 opc opc 490830 Mar 29 08:57 oraclepki.jar
-rw-rw-r--. 1 opc opc 4 May 24 04:18 requirements.txt
-rw-r--r--. 1 opc opc 1513648 Mar 29 08:57 ucp11.jar
[opc@linux8-private shared]$ sudo docker run --rm -v $(pwd):/opt/dataflow --pull always -it phx.ocir.io/oracle/dataflow/dependency-packager:latest -p 3.8
<中略>
Scanning for local jars in your current folder to be included in archive.zip ...
The following jar files will be included in the archive.zip:
/opt/dataflow/ojdbc11.jar
/opt/dataflow/ucp11.jar
/opt/dataflow/oraclepki.jar
/opt/dataflow/bcpkix-jdk15on-1.70.jar
/opt/dataflow/bcprov-jdk15on-1.70.jar
Are you sure you want to put all these jar files(5) into archive.zip? [Y/n]y
<中略>
archive.zip is generated!
[opc@linux8-private shared]$
archive.zipとversion.txtの2つファイルが作成されました。archive.zipをOCIオブジェクト・ストレージにアップロードしてください。
[opc@linux8-private shared]$ ll archive.zip version.txt
-rw-r--r--. 1 2001 2000 84600576 May 24 13:38 archive.zip
-rw-r--r--. 1 2001 2000 664 May 24 13:38 version.txt
[opc@linux8-private shared]$
OCI-CLIは既にインストールと設定済であれば、次のコマンドでアップロードできます。
コマンド例:oci os object put -bn MyBucket --file archive.zip
2. OCIでアプリケーションの作成と実行
2-1. プライベート・エンドポイントの作成
OCIメニュー → Analytics & AI → Data Lake → Data Flow → Create private endpoint
DNS zones to resolve: ADBプライベート・エンドポイントURLを入力
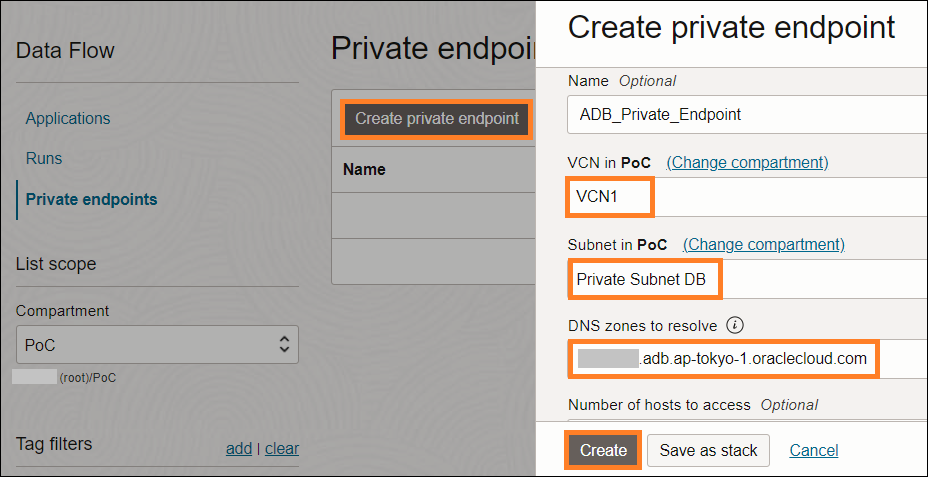
作成開始後の状態: Creating → Inactive
※、"Inactive"の状態で、アプリケーションの実行は可能です。
作成ボタンをクリックすると、次のようなエラーが発生した場合:
メッセージ:Unable to process JSON input
可能な原因:DNS zones to resolveは未入力か、入力内容は不正。
対策:ADBのプライベート・エンドポイントURLを正しく入力する。
2-2. アプリケーションの作成
OCIメニュー → Analytics & AI → Data Lake → Data Flow → Create application
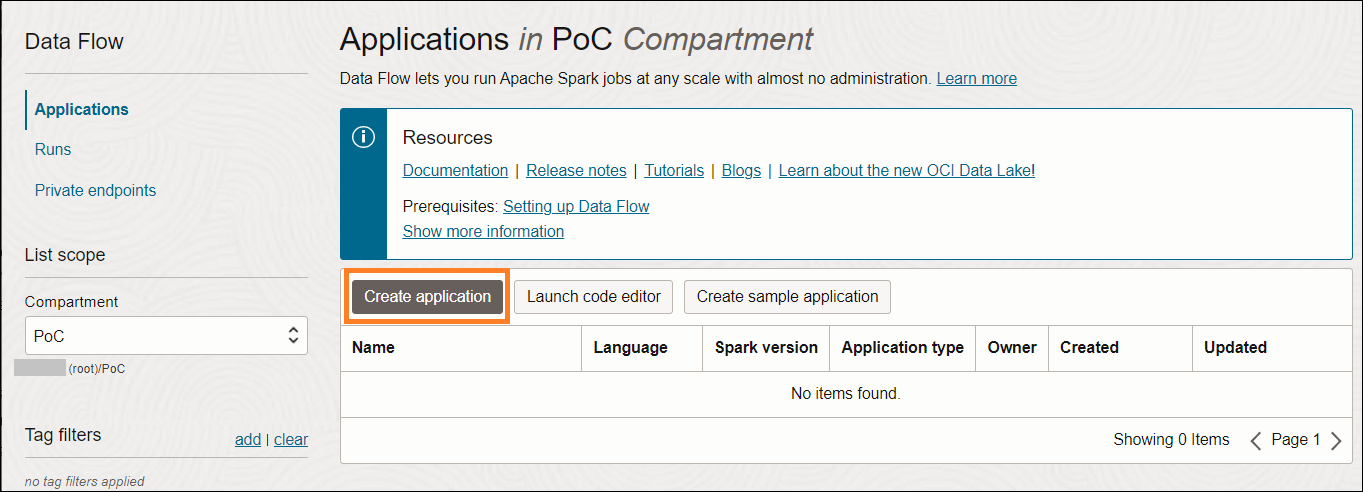
アプリケーション名を入力し、Sparkバージョンとシェイプを選択します。
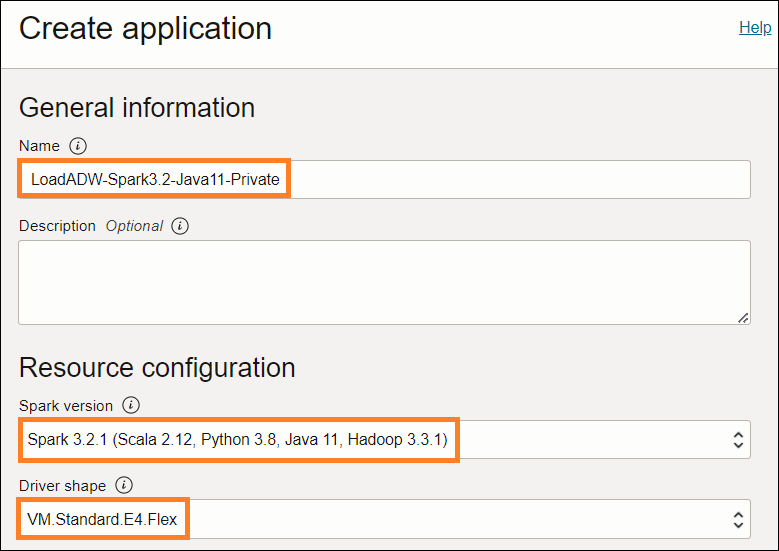
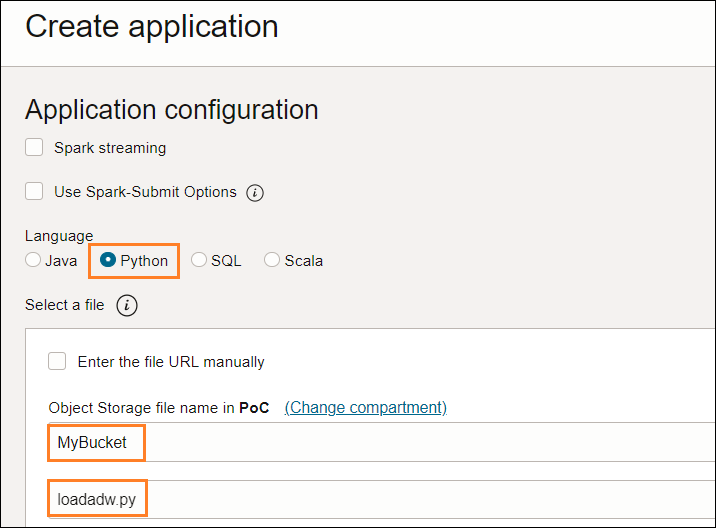
プログラムのタイプ(Python)と置き場所を指定してください。
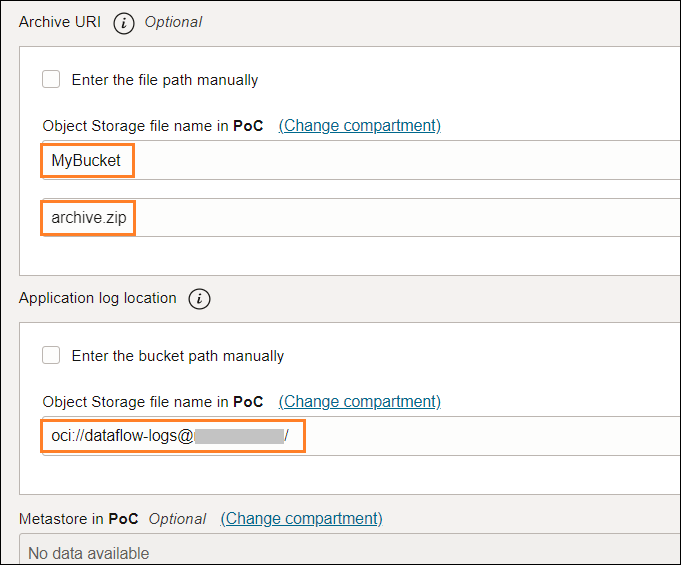
アーカイブファイルとログの置き場所を指定します。(dataflow-logsというバケットを事前に作成しておく)。
アプリケーション・ログ:oci://<bucket-name>@<Object_Storage_Namespace>
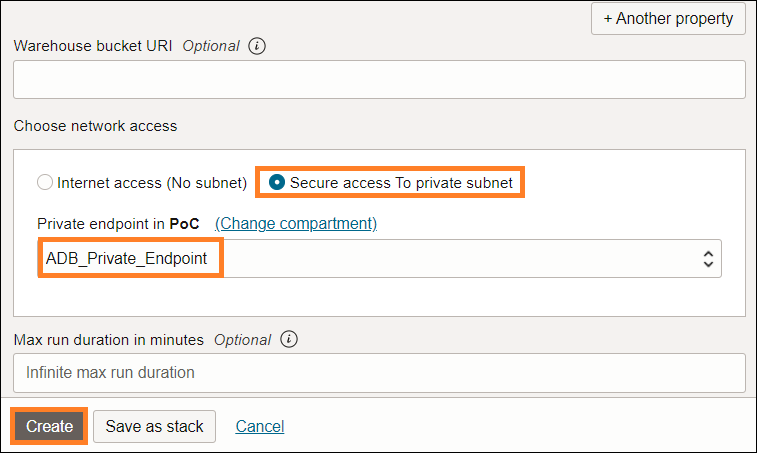
画面下部のShow advanced optionsをクリックし、プライベート・エンドポイントを選択してから、作成を開始します。
2-3. アプリケーションの実行
アプリケーション詳細画面に、Run (実行)をクリックして、実行を開始します。
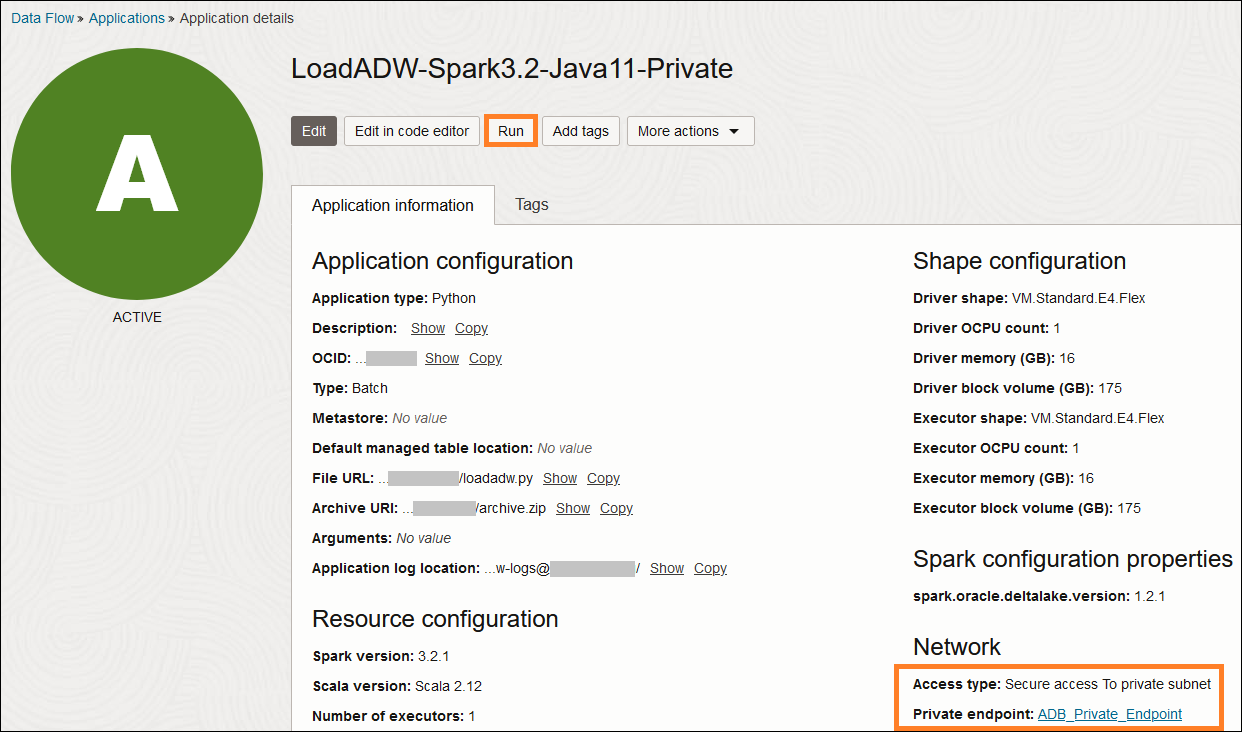
実行する前、シェイプの指定ができますが、この例ではデフォルトのままで進みます。
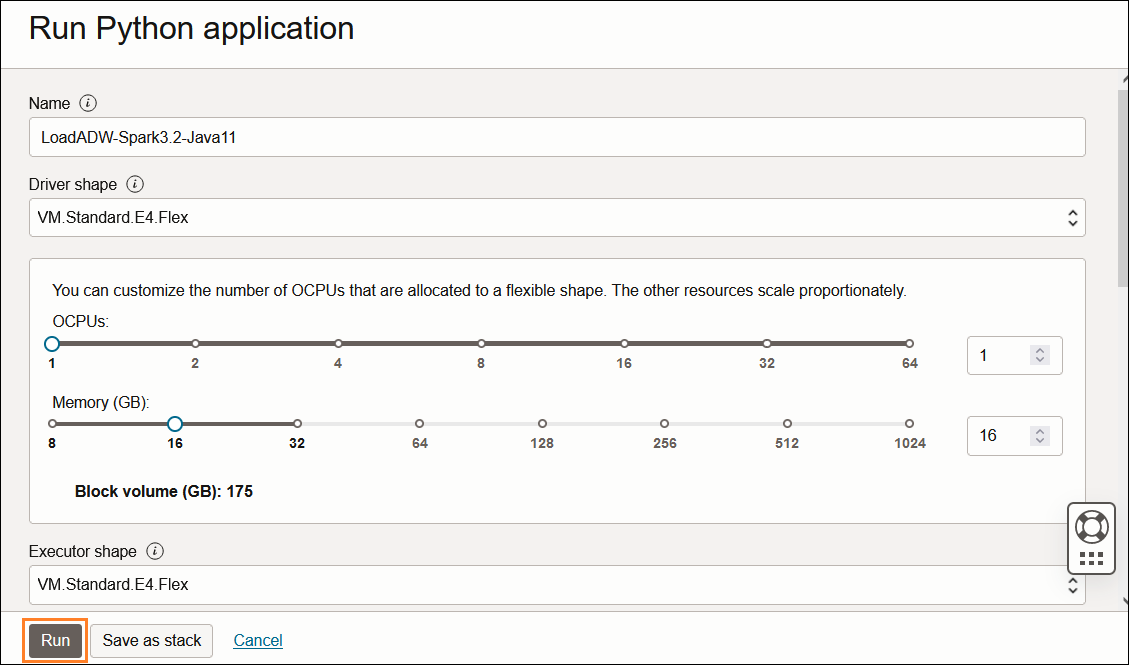
実行ステータス:
Accepted (受入れ済) → In progress (進行中) → Succeed (成功)、或いは Failed (失敗)
この例では、受入れ済から進行中まで約10分間かかり、進行中から成功完了までの実行時間(Duration)は、2分34秒でした。

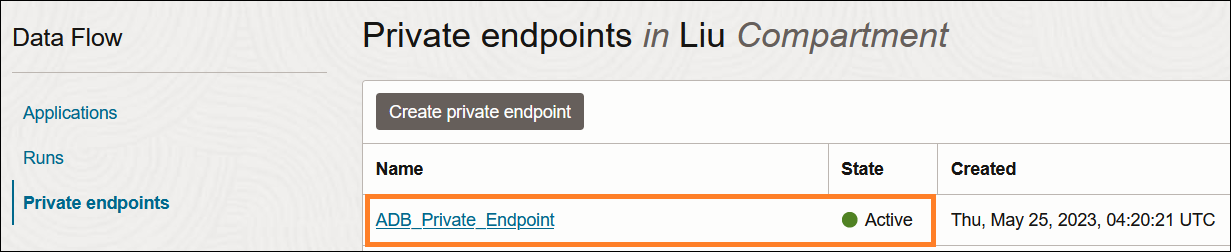
アプリケーション実行後、プライベート・エンドポイントの状態は、"Inactive"から"Active"に変わりました。
実行成功後、テーブルの中身を確認します。
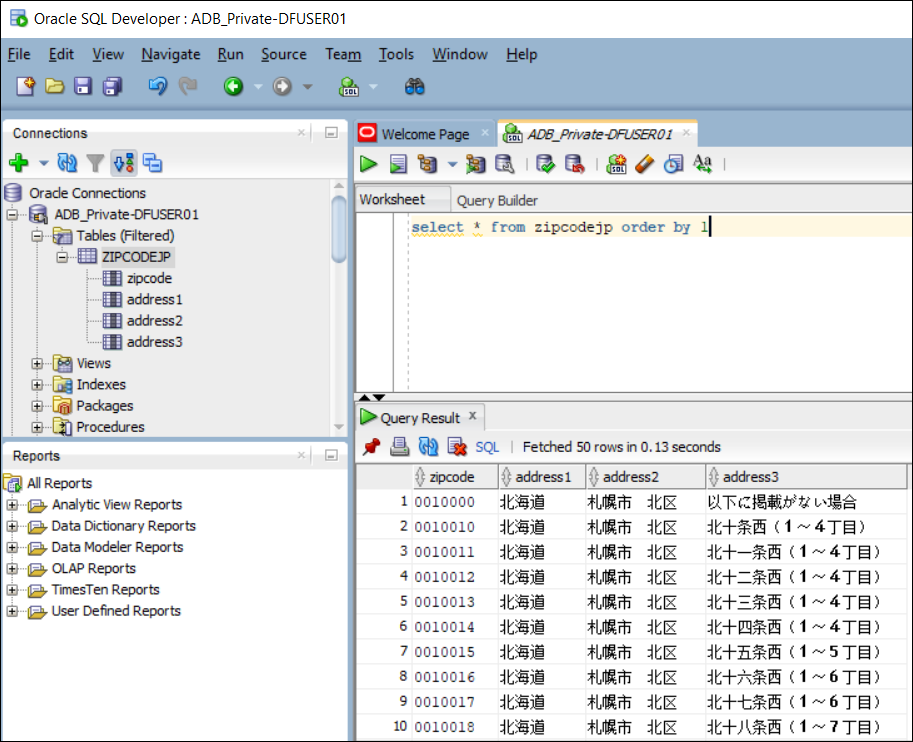
以上です。
関連記事
クラウド技術ブログ一覧
OCI Data Flowを使ってオブジェクト・ストレージからADBへデータをロードする -- Part 1
OCI Data Flowを使ってオブジェクト・ストレージからADBへデータをロードする -- Part 2
OCI データ・フロー・ドキュメント
製品サイト
オフィシャル・ドキュメント
データ・フロー・チュートリアル
データ・フロー・アプリケーションへのサードパーティ・ライブラリの追加
プライベート・ネットワークへのデータ・フローのアクセスの許可