はじめに
Amazon Bedrock でも Claude Sonnet 4.5 が利用可能になったとのことなので調べてみました。
本家の Claude
本家の Claude でもデフォルトで Sonnet 4.5 が指定されています。
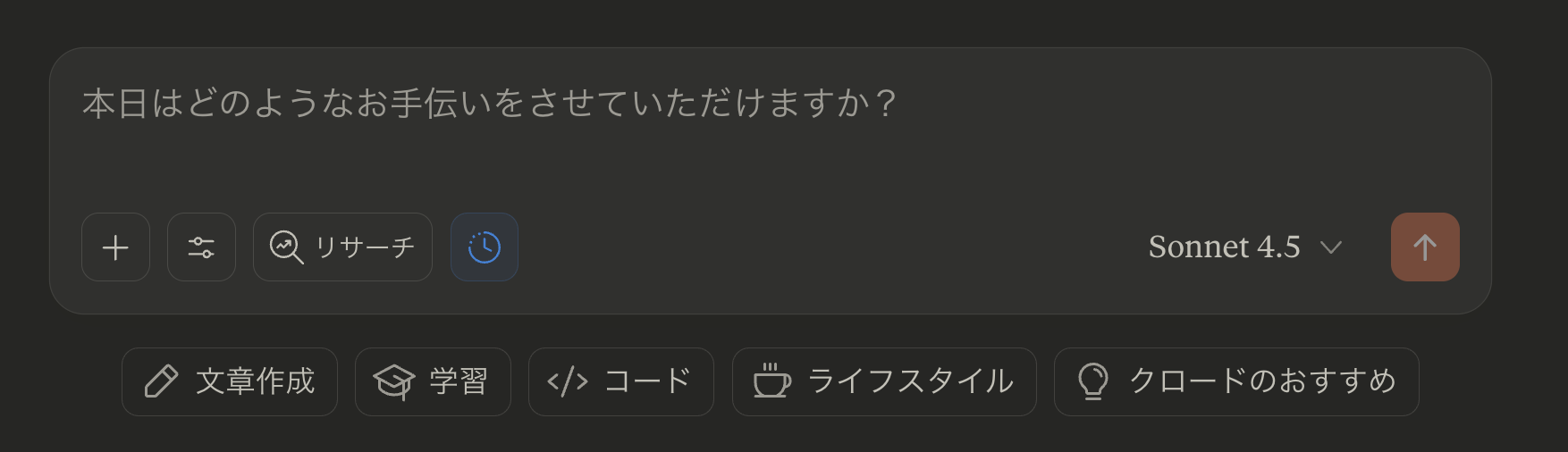
数値比較
数値だけをみる限り、ほとんどの分野で Claude Opus 4.1 も上回っているようです。また、Claude Sonnet 4.5 と GPT-5 を比較すると、Claude Sonnet 4.5 は実用的なタスク実行、複雑な操作、長時間のエージェント処理する「実行型AI」、GPT-5 は純粋な推論力、視覚理解、理論的問題解決に適する「思考型AI」といったところでしょうか?
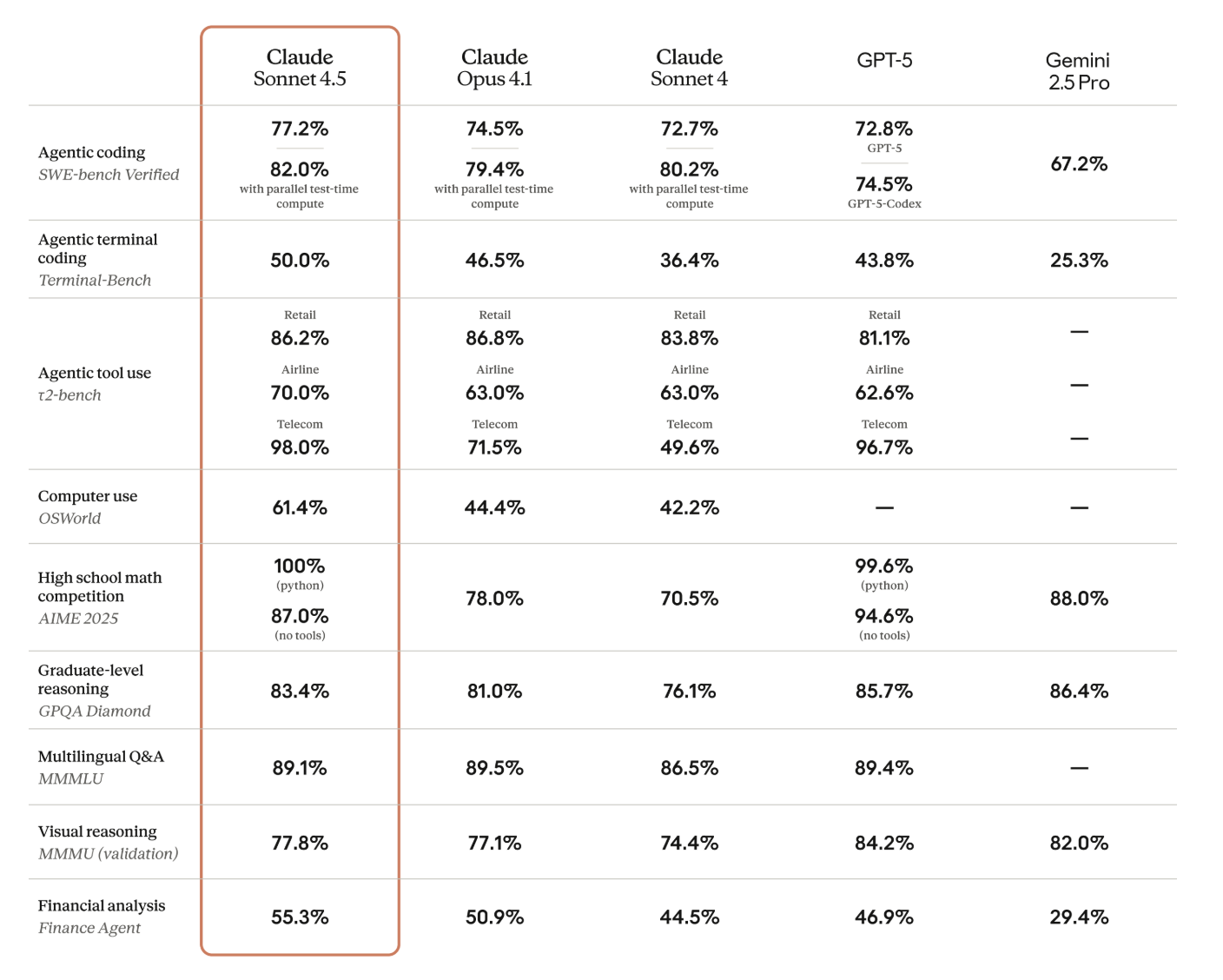
Global Claude Sonnet 4.5 と JP Anthropic Claude Sonnet 4.5
Global Claude Sonnet 4.5 はサポートされているすべての AWS リージョンにわたって、Claude Sonnet 4.5 へのリクエストをグローバルにルーティングします。これは、Claude Sonnet 4 からあったものです。
新たに、JP Anthropic Claude Sonnet 4.5 はリクエストを 日本のリージョンの Claude Sonnet 4.5 にルーティングするようです。
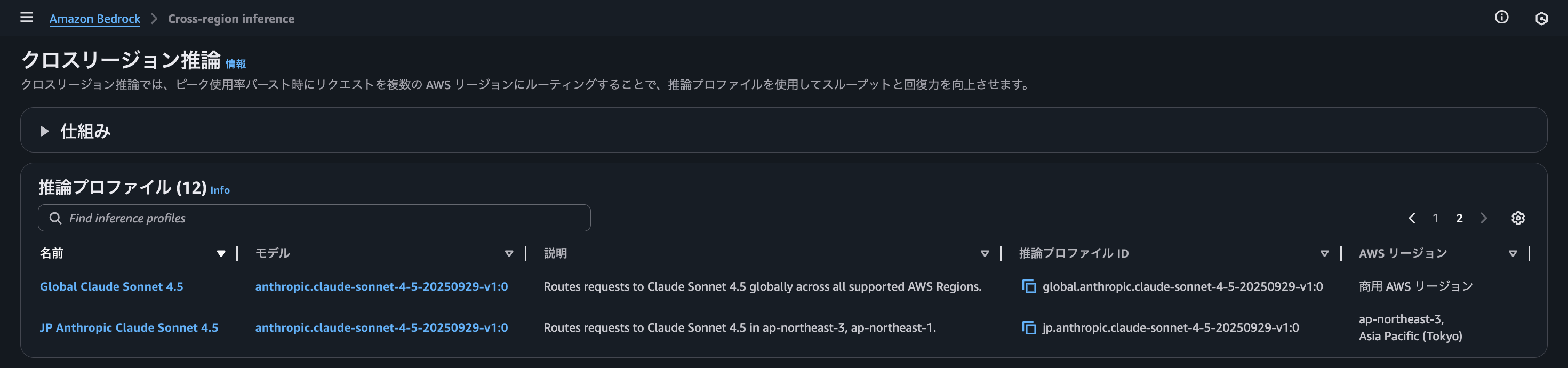
料金
Claude Sonnet 4.5 と Claude Sonnet 4.5 - Long Context の記載がありました。
Amazon Bedrock の価格表のページではないですが、こちらの記事によると、以下の通り記載されていたので、長いトークンを扱う場合一定のトークン数を超えると、Claude Sonnet 4.5 - Long Context の料金になるといったところでしょうか?
Anthropicは、最大20万トークンのプロンプトに対し、API入力は100万トークンあたり3ドル、出力は100万トークンあたり15ドルと設定しています。20万トークンを超える大規模なプロンプトの場合、料金は入力が100万トークンあたり6ドル、出力が100万トークンあたり22.50ドルに調整されます。
また、Global Cross-region Inference (JP Anthropic Claude Sonnet 4.5) の場合、微妙に Geo and In-region Cross-region Inference (Global Claude Sonnet 4.5) と比べて割高になるようです。
Amazon Bedrock API の Sonnet 4.5 の機能
-
スマートコンテキストウィンドウ管理: コンテキストウィンドウ(一度に処理できる情報量)の上限に達した際、会話が長くなりこの上限に達すると、従来はエラーを返して処理を停止していたが、利用可能な上限まで応答を生成
-
ツール使用履歴の消去に夜効率化: 長い会話で複数のツールの呼び出しが発生した際、古いツール結果を自動的に削除し最近のものだけを保持することで、不要なトークン消費を防ぎコストを削減しながら会話品質を維持
-
会話間メモリ: セッションをまたいで重要な情報をローカルファイルに保存・参照できるため、以前の会話の文脈を保持したまま継続的に作業可能
Amazon Bedrock Converse API を使って呼び出してみる
実装は、AWS ブログを参考に実装します。とはいっても、実装は今までと変わらず単に Claude Sonnet 4.5("jp.anthropic.claude-sonnet-4-5-20250929-v1:0") を呼び出すだけですが。
普段はオレゴンリージョンを使いますが、せっかくなので、JP Anthropic Claude Sonnet 4.5 を呼び出すようにしてみます。
import boto3
import json
from datetime import datetime
session = boto3.Session(region_name="ap-northeast-1", profile_name="default")
client = session.client(
"bedrock-runtime",
endpoint_url="https://bedrock-runtime.ap-northeast-1.amazonaws.com",
)
with open("prompt.md") as prompt:
prompt_content = prompt.read()
question = prompt_content
convesation = [
{
"role": "user",
"content": [{"text": question}]
}]
model_id = "jp.anthropic.claude-sonnet-4-5-20250929-v1:0"
response = client.converse(
modelId= model_id,
messages= convesation
)
output = response["output"]["message"]["content"][0]["text"]
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
response_data = {
"response": output,
"full_response": response
}
with open(f"claude_response_{timestamp}.md", "w", encoding="utf-8") as f:
f.write(f"Response:\n{output}")
単純な質問ではなくそれなりの質問を投げたいので、本家の Claude Sonnet 4.5 を使って、prompt を生成させ、prompt.md として保存しておきます。(画面の prompt は一部です)
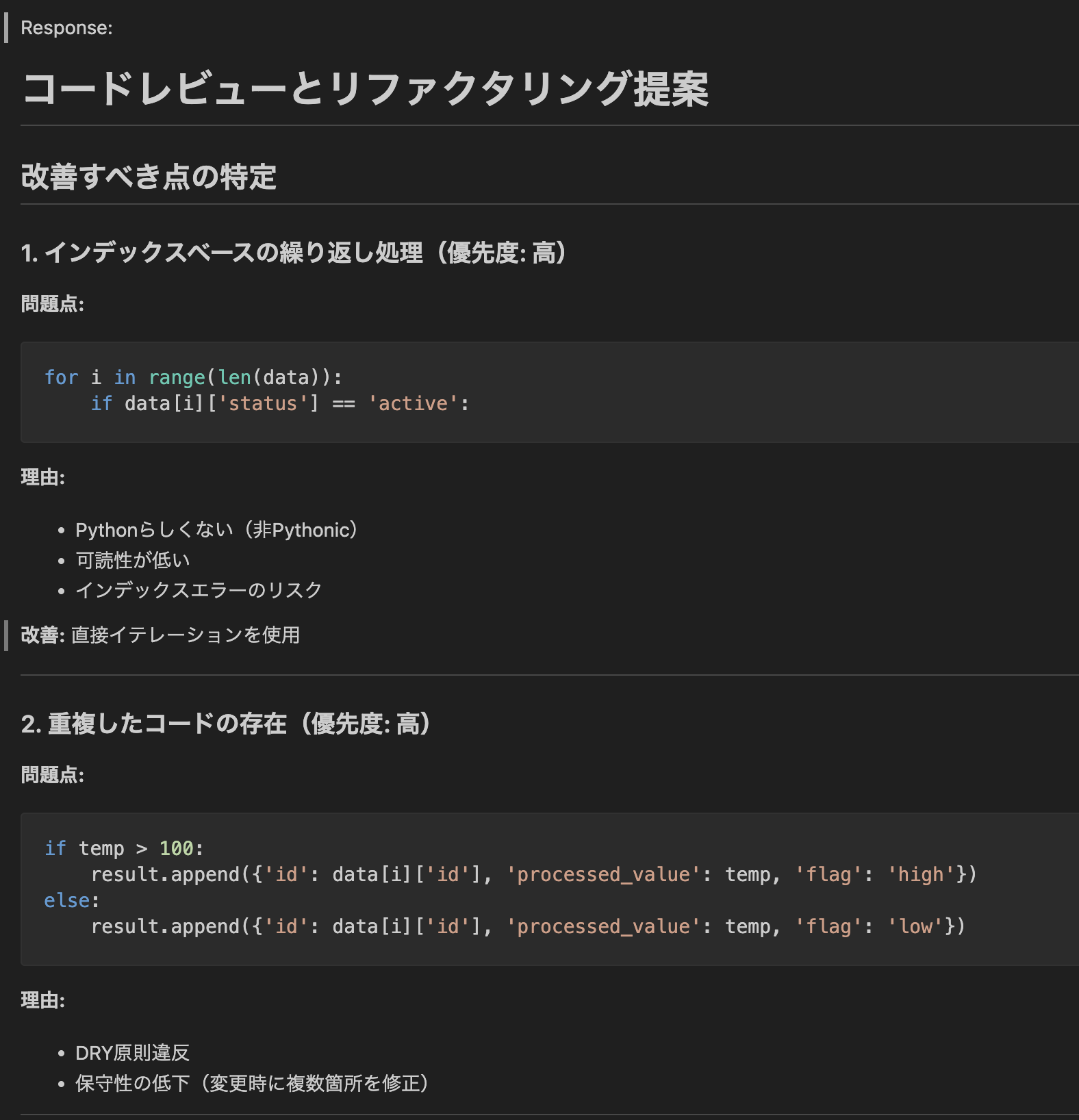
実行し結果を確認します。今回は結果が長いので別ファイルに書き込みようしています。(画面の結果は一部です)
python claude-sonet45.py
比較のため一つ前のモデル、Claude Sonnet 4(global.anthropic.claude-sonnet-4-20250514-v1:0)に変えて実行してみます。
python claude-sonet45.py

ぱっと見、Claude Sonnet 4.5 の方がより具体的に問題点を指摘してくれている感じでしょうか?色々な場面でもう少し試してみたいですね。