はじめに
Azure の AI 学習のために Azure AI Foundry を用いた RAG を用いた生成 AI アプリの開発を体験してみたいと思います。
本記事は、Azure の初心者向けです。
生成 AI に関連する基本的な言語は理解している前提で進めていきます。
RAG を用いた生成 AI アプリの開発
1. Azure AI Foundry ハブとプロジェクトの作成
https://ai.azure.com/managementCenter/allResources にアクセスし、「新規作成」をクリック。

「AI ハブ リソース」を選択し、「次へ」をクリック。

図の通り、必要事項を入力および選択し、「作成」をクリック。

2. モデルのデプロイ
「マイアセット」の「モデル + エンドポイント」を開き「モデルのデプロイ」より「基本モデルをデプロイする」をクリック。

「text-embedding-ada-002」を選択し、「確認」をクリック。

図の通り、必要事項を入力および選択し、「デプロイ」をクリック。


同じように「gpt-4.1」を選択し、「確認」をクリック。

図の通り、必要事項を入力および選択し、「デプロイ」をクリック。


3. プロジェクトにデータを追加
「データとインデックス」から「データファイル」の「新しいデータ」をクリック。

今回は先日発表された iphone 17 の製品情報をアップロードしておきます。アップロードが完了したら「次へ」をクリック。

「データ名」には適当に iphone-17 とでも入力し、「作成」。

4. データのインデックスを作成
「データとインデックス」から「インデックス」の「新しいインデックス」をクリック。

データソースは先程作成した「iphone-17」を選択し、「次へ」をクリック。

「新しい Azure AI Search リソースを作成」から作成し作した Azure AI Search Service のリソースを選択。「ベクターインデックス」は適当に iphone-17-index と入力しておき、「次へ」をクリック。

ベクター設定: この検索リソースにベクター検索を追加する
「Azure OpenAI 接続」には、ハブの既定の Azure OpenAI リソースを選択し、「埋め込みモデル」と「埋め込みモデルのデプロイメン」は先程有効化した text-embedding-ada-002 のモデルを選択し「次へ」をクリック。

「ベクターインデックスを作成する」をクリック。

5. プレイグラウンドでテスト
「プレイグラウンド」で「チャット プレイグラウンドを試す」をクリック。

「gpt-4.1」を選択し、システムプロンプトには あなたは Apple の iphone の開発者です。 としておきます。インデックスには先程作成した「iphone-17-index」を選択し、検索の種類は「ハイブリッド(ベクトル + キーワード)」にします。


iphone 17 についてと質問を投げてみると参照されたデータを基に回答がされたことを確認しました。



6. RAG クライアントアプリの作成
Azure OpenAI SDK を使用してクライアントアプリケーションから呼び出してみるため、3 つのファイルを準備します。
.env
# Azure OpenAI Configuration
OPEN_AI_ENDPOINT=
OPEN_AI_KEY=
CHAT_MODEL=gpt-4.1
EMBEDDING_MODEL=text-embedding-ada-002
API_VERSION=2024-12-01-preview
# Azure AI Search Configuration
SEARCH_ENDPOINT=
SEARCH_KEY=
INDEX_NAME=iphone-17-index
OPEN_AI_ENDPOINT と OPEN_AI_KEY は「概要」から確認します。

SEARCH_ENDPOINT と SE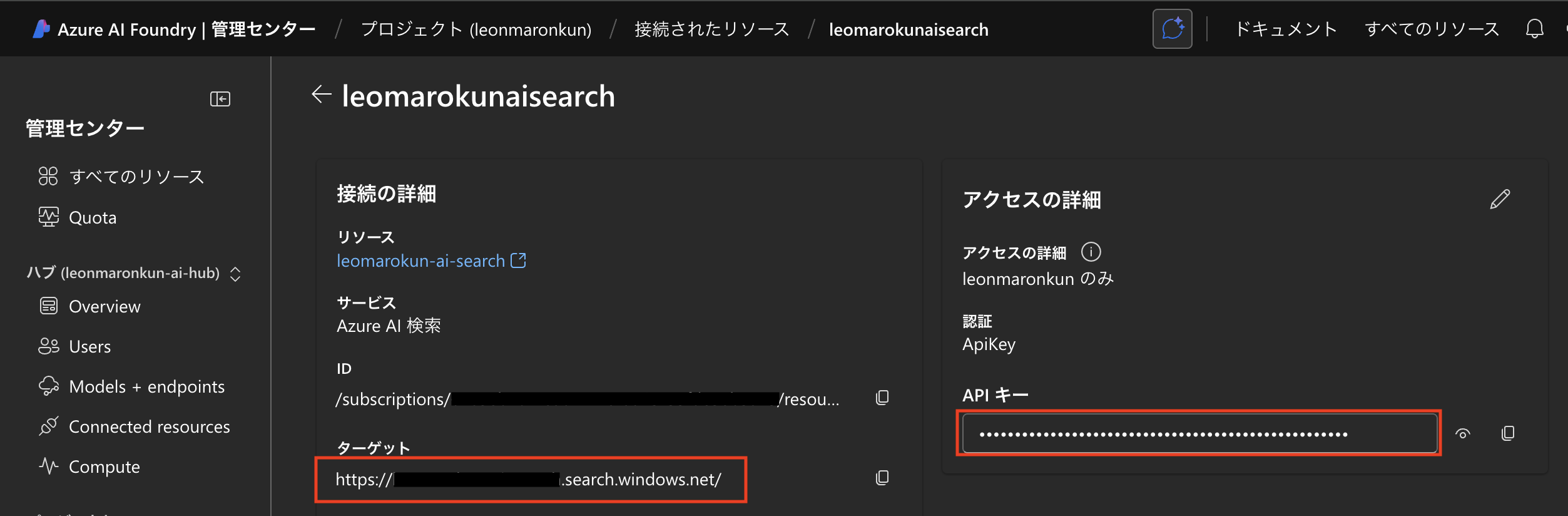 ARCH_KEY は「管理センター」の「Azure AI 検索」から確認します。
rag-app.py
import os
from dotenv import load_dotenv
from openai import AzureOpenAI
from typing import Dict, Any
class AzureRAGChatApp:
"""
Azure OpenAI RAG(Retrieval-Augmented Generation)チャットアプリケーション
"""
def __init__(self):
"""初期化とクライアント設定"""
self.load_environment_variables()
self.validate_configuration()
self.setup_client()
self.initialize_conversation()
def load_environment_variables(self):
"""環境変数の読み込み"""
load_dotenv()
# 必須の環境変数
self.open_ai_endpoint = os.getenv("OPEN_AI_ENDPOINT")
self.open_ai_key = os.getenv("OPEN_AI_KEY")
self.chat_model = os.getenv("CHAT_MODEL")
self.embedding_model = os.getenv("EMBEDDING_MODEL")
self.search_url = os.getenv("SEARCH_ENDPOINT")
self.search_key = os.getenv("SEARCH_KEY")
self.index_name = os.getenv("INDEX_NAME")
# オプションの環境変数(デフォルト値付き)
self.api_version = os.getenv("API_VERSION")
self.system_message = "あなたは Apple 製品に関する情報を提供する優秀な開発者です"
def validate_configuration(self):
"""設定の検証"""
required_vars = {
"OPEN_AI_ENDPOINT": self.open_ai_endpoint,
"OPEN_AI_KEY": self.open_ai_key,
"CHAT_MODEL": self.chat_model,
"EMBEDDING_MODEL": self.embedding_model,
"SEARCH_ENDPOINT": self.search_url,
"SEARCH_KEY": self.search_key,
"INDEX_NAME": self.index_name
}
missing_vars = [var for var, value in required_vars.items() if not value]
if missing_vars:
raise ValueError(f"以下の環境変数が設定されていません: {', '.join(missing_vars)}")
print("✓ 設定の検証が完了しました")
def setup_client(self):
"""Azure OpenAIクライアントの設定"""
try:
self.chat_client = AzureOpenAI(
api_version=self.api_version,
azure_endpoint=self.open_ai_endpoint,
api_key=self.open_ai_key
)
print("✓ Azure OpenAIクライアントが正常に初期化されました")
except Exception as e:
raise RuntimeError(f"Azure OpenAIクライアントの初期化に失敗しました: {str(e)}")
def initialize_conversation(self):
"""会話履歴の初期化"""
self.conversation_history = [
{"role": "system", "content": self.system_message}
]
print("✓ 会話履歴が初期化されました")
def create_rag_parameters(self) -> Dict[str, Any]:
"""RAGパラメータの作成"""
return {
"data_sources": [
{
"type": "azure_search",
"parameters": {
"endpoint": self.search_url,
"index_name": self.index_name,
"authentication": {
"type": "api_key",
"key": self.search_key,
},
"query_type": "vector",
"embedding_dependency": {
"type": "deployment_name",
"deployment_name": self.embedding_model,
},
# 追加の検索パラメータ
"top_n_documents": 5, # 取得する文書数
"strictness": 3, # 検索の厳密性
}
}
],
}
def get_chat_response(self, user_input: str) -> str:
"""
ユーザー入力に対するチャット応答を取得
Args:
user_input (str): ユーザーからの入力
Returns:
str: AIからの応答
"""
try:
# ユーザーメッセージを会話履歴に追加
self.conversation_history.append({"role": "user", "content": user_input})
# RAGパラメータを作成
rag_params = self.create_rag_parameters()
# チャット完了APIを呼び出し
response = self.chat_client.chat.completions.create(
model=self.chat_model,
messages=self.conversation_history,
extra_body=rag_params,
temperature=0.7, # 応答の創造性を調整
max_tokens=1000, # 最大トークン数
)
# レスポンスから内容を抽出(エンコーディング処理を追加)
assistant_response = response.choices[0].message.content
# UTF-8エンコーディングエラー対応
if assistant_response:
try:
# レスポンスがbytes型の場合、適切にデコード
if isinstance(assistant_response, bytes):
assistant_response = assistant_response.decode('utf-8', errors='replace')
# 文字列の場合、問題のある文字を置換
elif isinstance(assistant_response, str):
assistant_response = assistant_response.encode('utf-8', errors='replace').decode('utf-8')
except (UnicodeDecodeError, UnicodeEncodeError) as e:
print(f"⚠️ エンコーディングエラーが発生しました: {e}")
assistant_response = "申し訳ありません。応答の処理中にエンコーディングエラーが発生しました。"
else:
assistant_response = "申し訳ありません。応答を取得できませんでした。"
# アシスタントの応答を会話履歴に追加
self.conversation_history.append({"role": "assistant", "content": assistant_response})
return assistant_response
except Exception as e:
error_msg = f"チャット応答の取得中にエラーが発生しました: {str(e)}"
print(f"エラー: {error_msg}")
return f"申し訳ありません。処理中にエラーが発生しました。再度お試しください。"
def display_conversation_stats(self):
"""会話の統計情報を表示"""
user_messages = len([msg for msg in self.conversation_history if msg["role"] == "user"])
assistant_messages = len([msg for msg in self.conversation_history if msg["role"] == "assistant"])
print(f"\n📊 会話統計:")
print(f" ユーザーメッセージ: {user_messages}")
print(f" アシスタントメッセージ: {assistant_messages}")
print(f" 総会話ターン: {min(user_messages, assistant_messages)}")
def clear_console(self):
"""コンソールをクリア"""
os.system('cls' if os.name == 'nt' else 'clear')
def run_chat_loop(self):
"""メインのチャットループ"""
self.clear_console()
print("=" * 60)
print("🏖️ Apple RAG チャットボット")
print("=" * 60)
print("Apple 製品に関するご質問をお気軽にどうぞ!")
print("終了するには 'quit', 'exit', または 'q' と入力してください。")
print("会話履歴をクリアするには 'clear' と入力してください。")
print("=" * 60)
while True:
try:
# ユーザー入力を取得
user_input = input("\n💬 あなた: ").strip()
# 終了コマンドのチェック
if user_input.lower() in ['quit', 'exit', 'q']:
self.display_conversation_stats()
print("\n👋 ご利用ありがとうございました!")
break
# 会話履歴クリアコマンド
if user_input.lower() == 'clear':
self.initialize_conversation()
self.clear_console()
print("🗑️ 会話履歴がクリアされました。\n")
continue
# 空入力のチェック
if len(user_input) == 0:
print("⚠️ 質問を入力してください。")
continue
# チャット応答を取得して表示
print("\n🤖 アシスタント:", end=" ")
response = self.get_chat_response(user_input)
print(response)
except KeyboardInterrupt:
print("\n\n👋 チャットを終了しました。")
break
except Exception as e:
print(f"\n❌ 予期しないエラーが発生しました: {str(e)}")
print("再度お試しください。")
def main():
"""メイン関数"""
try:
# RAGチャットアプリを初期化して実行
app = AzureRAGChatApp()
app.run_chat_loop()
except Exception as e:
print(f"❌ アプリケーションの初期化に失敗しました: {str(e)}")
print("\n📝 .envファイルに以下の環境変数が正しく設定されているか確認してください:")
print(" - OPEN_AI_ENDPOINT")
print(" - OPEN_AI_KEY")
print(" - CHAT_MODEL")
print(" - EMBEDDING_MODEL")
print(" - SEARCH_ENDPOINT")
print(" - SEARCH_KEY")
print(" - INDEX_NAME")
if __name__ == '__main__':
main()
requirements.txt
openai>=1.12.0
python-dotenv>=1.0.0
azure-search-documents>=11.4.0
azure-identity>=1.15.0
requests>=2.31.0
仮想環境の作成と必要なライブラリをインストールしておきます。
python3 -m venv path/to/venv
source path/to/venv/bin/activate
pip install -r requirements.txt
アプリケーションを実行してみます。
python rag-app.py
プレイグラウンドでテストした時と同じように iPhone 17 について質問し、回答が返ってくれば完了です。
