はじめに
AI ツールのトークン消費、最近やたら気になります。
削減のテクニック自体は論文を漁ればいくらでも出てきます。
-
プロンプトを圧縮する系: (LLMLinguaが有名で、最大 20 倍圧縮しても性能低下は 1.5 pt くらい)
-
エージェントのコンテキストを賢く間引く系: (Less Context, Better AgentsとかA-Mem)
-
プロンプトキャッシュを再利用する系: (Don't Break the Cache)
そもそも自分が毎日使っているツールが、今どれだけトークンを食ってるのかを一回ちゃんと見てみることにしました。
対象は Claude Code です。
Claude Code はセッションのやり取りは全部ローカルに JSONL で残しており、各リクエストの usage(input / output / cache_read / cache_creation) が入っているので、これを集計して確認してみます。
ログの場所と中身
macOS だとここに溜まっていました。
~/.claude/projects/<エンコードされたパス>/<セッションUUID>.jsonl
1 行 1 イベントで、アシスタントの返答(type: "assistant")の行にこういうusageがぶら下がっています。
{
"type": "assistant",
"message": {
"model": "claude-opus-4-8",
"usage": {
"input_tokens": 12,
"cache_read_input_tokens": 18002,
"cache_creation_input_tokens": 320,
"output_tokens": 414
}
}
}
-
input_tokens… キャッシュに乗らなかった新規入力。フルプライス。 -
cache_read_input_tokens… キャッシュから読めた分。単価は 0.1 倍。 -
cache_creation_input_tokens… キャッシュに書いた分。単価は書込TTL で変わり、5 分なら 1.25 倍、1 時間なら 2 倍。
TTL の話は後でもう一度出てきます。私は Claude サブスクで使っていて、その場合 Claude Code は自動で 1 時間 TTL を使うので、この記事では書込を 2 倍として計算しています。
この比率を見れば、コストの実態が分かるはずです。
とりあえず全部足してみる
手元の全 JSONL を舐めてスクリプトで集計させてみます。やってることは単純で、assistant 行の usage を拾って足すだけです。
スクリプト
import json, glob, os
from collections import defaultdict
ROOT = os.path.expanduser("~/.claude/projects")
def iter_assistant_usages(path):
with open(path, encoding="utf-8") as fh:
for line in fh:
line = line.strip()
if not line:
continue
try:
d = json.loads(line)
except json.JSONDecodeError:
continue
if d.get("type") != "assistant":
continue
u = d.get("message", {}).get("usage")
if u:
yield d["message"].get("model", "unknown"), u
files = glob.glob(os.path.join(ROOT, "*", "*.jsonl"))
tot = defaultdict(int)
for f in files:
for model, u in iter_assistant_usages(f):
tot["input"] += u.get("input_tokens", 0)
tot["output"] += u.get("output_tokens", 0)
tot["cr"] += u.get("cache_read_input_tokens", 0)
tot["cw"] += u.get("cache_creation_input_tokens", 0)
total_in = tot["input"] + tot["cr"] + tot["cw"]
print(f"fresh input : {tot['input']:>14,} ({tot['input']/total_in*100:5.1f}%)")
print(f"cache_read : {tot['cr']:>14,} ({tot['cr']/total_in*100:5.1f}%)")
print(f"cache_creation: {tot['cw']:>14,} ({tot['cw']/total_in*100:5.1f}%)")
print(f"output : {tot['output']:>14,}")
私の環境(104 ファイル、97 セッション、アシスタントの応答 5,529 回分)で回した結果がこれです。
| 項目 | 値 |
|---|---|
| 新規入力(fresh input) : | 3,521,265 |
| キャッシュ読込(cache_read): | 542,306,960 |
| キャッシュ書込(cache_creation) : | 25,066,436 |
| 出力(output) : | 5,909,232 |
| 入力側合計 : | 570,894,661 |
| キャッシュヒット率(read 比): | 95.0% |
入力が合計 5.7 億トークンありますが、そのうち 95 %がキャッシュからの読み込みということでしょうか。
(数字はある時点のスナップショットです。集計対象にはこの解析をやっている今のセッション自体も入るので、回すたびに少しずつ増えます。)
お金に直すといくらか
コストに換算してみます。
なお私はサブスクで使っているので、実際にはトークン単位の課金は発生していません(プラン内)。なのでここでの金額は「もし API 従量課金だったらいくらか」の試算として置き換えます。
Claudeの料金
(Opus 4.8 で input $5 / output $25 per 1M、cache_read はその 0.1倍=$0.50、cache_creationはサブスクの1時間TTL なので2倍=$10)
を当てはめます。
もしプロンプトキャッシュが無くて毎回 input + cache_read + cache_creation を全部フルプライスで払っていたらという仮想ケースと比べてみます。
| 項目 | 値 |
|---|---|
| API 従量換算(キャッシュ有) : | $ 702.93 |
| 仮想コスト(キャッシュ無) : | $ 3068.44 |
| キャッシュによる削減 : | $ 2365.51 (77.1 % 削減) |
キャッシュが無ければ約 3,000 ドル相当のところを、実際は約 700 ドル相当で済んでいるという計算で、8 割弱(77 %)の削減というところでしょうか。
Don't Break the Cache という論文(タイトルがそのまま「キャッシュを壊すな」)が、エージェントの長時間タスクではプロンプトキャッシュの効きがコストを大きく左右する、と論じています。まさにそれを地で行く結果のように思えます。
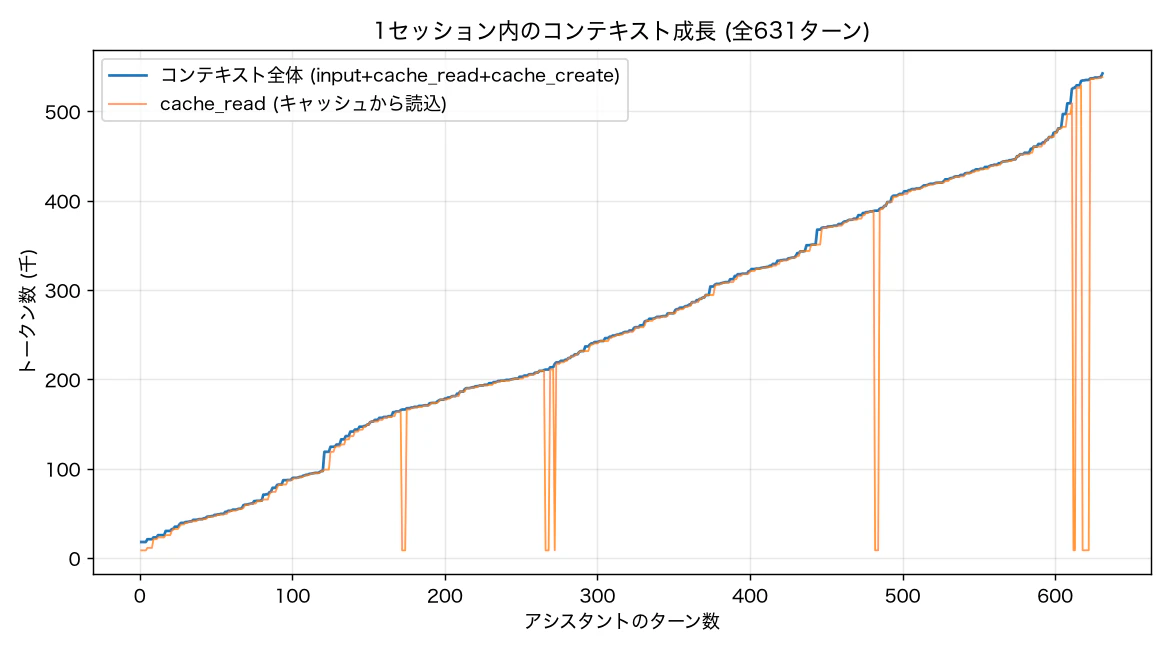
ターンごとのコンテキスト成長を描いてみる
合算だと平均の話になってしまうので、一番ターン数が多かったセッション(631 ターン)を取り出して、ターンごとのコンテキストサイズを input + cache_read + cache_create で計算してグラフにしてみます。
青がコンテキスト全体(input+cache_read+cache_create)、
オレンジが cache_read です。
見どころが 3 つあります。
まず、青線がほぼ直線で伸びている。
631 ターンで 18,000 トークンから 542,000 トークンまで膨らんでいます。
これがいわゆる ReAct 型の「毎ターン全履歴を積む」やつで、コンテキストが線形に増えていく。
先に挙げた Less Context, Better Agents はこの線形成長を問題視していて、Context Folding という手法だと「100 ターンでも 7 K 未満」のサブリニアに抑えられると報告しています。
次に、オレンジ線が青線にぴったり張り付いている。
これはキャッシュが理想的に機能している証拠です。
コンテキストが 50 万トークンに膨らもうが、その大半は 0.1 倍単価で読まれている。
だからさっきの「8 割弱の削減」が成立します。
最後に、たまにオレンジ線が谷底(8,000くらい)までストンと落ちる。
ターン 172、266、482、612 あたりです。
これがキャッシュ失効のタイミングです。プロンプトキャッシュの TTL は認証方法で変わって、API キーだと標準 5 分、私のような Claude サブスクだと Claude Code が自動で 1 時間に延ばしてくれます。とはいえ無限ではないので、その TTL を超えて中断したり、履歴が変わって失効したりすると、次のリクエストはキャッシュを読めず、コンテキスト全体を書き直すことになります。
谷の直後のターンは cache_creation がドカッと跳ねていました。
結局、何をすればいいのか
ここまでの数字を踏まえて、今のところはサブスクリプションですのであまり気にしませんが自分みたいな Claude Code のヘビーユーザーが手っ取り早くやれることを、効きそうな順に書いておきます。
一番効くのは キャッシュを壊さないこと の気がします。
具体的には、
- TTL を意識して、長い離席を減らす。サブスクなら 1 時間なのでだいぶ余裕がありますが、それでも超えれば書き直しです
- 会話履歴を途中でいじらない。プレフィックス一致が崩れた瞬間、それ以降が全部キャッシュミスになります - (プロンプトキャッシュの仕様)
- モデルを頻繁に切り替えない。キャッシュはモデル単位なので、切り替えると全書き直しになります
ちなみに TTL は自分で変えられます。API キーで使っていて中断が多いなら、環境変数 ENABLE_PROMPT_CACHING_1H=1 で 1 時間に延ばせます(サブスクは最初から 1 時間)。~/.claude/settings.json の env ブロックに書いても OK。 - (Claude Code のプロンプトキャッシュのドキュメント)
次に効きそうなのがコンテキストを積みすぎないことです。
グラフがあれだけきれいな直線になっている以上、積みっぱなしを減らすのが順当な一手です。
巨大なログやファイルを丸ごと貼らずに必要な箇所だけにするとか、長いタスクは適度に区切るとか - (Active Context Compressionあたりの発想)。
プロンプト圧縮そのもの(LLMLingua みたいなやつ)は、自前で RAG やエージェントを組むなら有効だと思いますが、Claude Code を使うだけなら上の 2 つを意識しておけば十分な気がします。
/usage
Claude Code に /usage コマンドがあるじゃん、と思うかもしれません。
/usage で見られるのは、現在のセッションのコスト、プランの使用量上限、それに直近 24 時間 / 7 日間のアクティビティ内訳(スキル・サブエージェント・プラグイン・MCP サーバー別)です(公式ドキュメント)。普段の使用量を把握するにはこれで十分便利です。
ただ、今回やった
- 過去の全セッションを横断した集計
- 入力を input / cache_read / cache_creation に分解
- キャッシュが無かった場合の反実仮想コスト
- ターンごとの成長カーブ
あたりは /usage の範囲外です。内訳の切り口がスキルやサブエージェント別であって、キャッシュ階層別やターン単位ではないからです。こういう独自の角度で見たいときは、結局のところ生ログを自前で叩くのが早そうです。
ちなみに集計だけなら OSS の ccusage という同じ JSONL を読むツールで、日次やモデル別の集計を手軽に出せます。これ使ってみたけど結構いいですよ。
おわりに
現実の主役はほとんどがプロンプトキャッシュ(8 割弱の削減)かと思われます。
で、次に効くのも派手なアルゴリズムではなく、キャッシュを壊さないとか積みすぎないとか、けっこう地味な運用の話に落ち着きそうな気がします。