Chat with your document とは
ナレッジベース (KB) の新機能。
単一のドキュメントにおける RAG の回答であれば、データベースを作成することなく、RAG の仕組みを簡単に利用できるよ。
今までのは、ベクトルデータベースに、Amazon OpenSearch Serverless などが必要。
使い方
PDF などのファイルをアップロードするか、S3 ファイルパスを指定するだけ。
制約事項
- ファイルサイズは 10 MB まで
- 文章中の画像は読み込みしません
- 表のある文章を読んだ時に、表の構造を正しく理解しないことがある
確認してみる(コンソール)
Model は「Claude 3 Sonnet」を選択。

今回はローカルから直接アップロード。
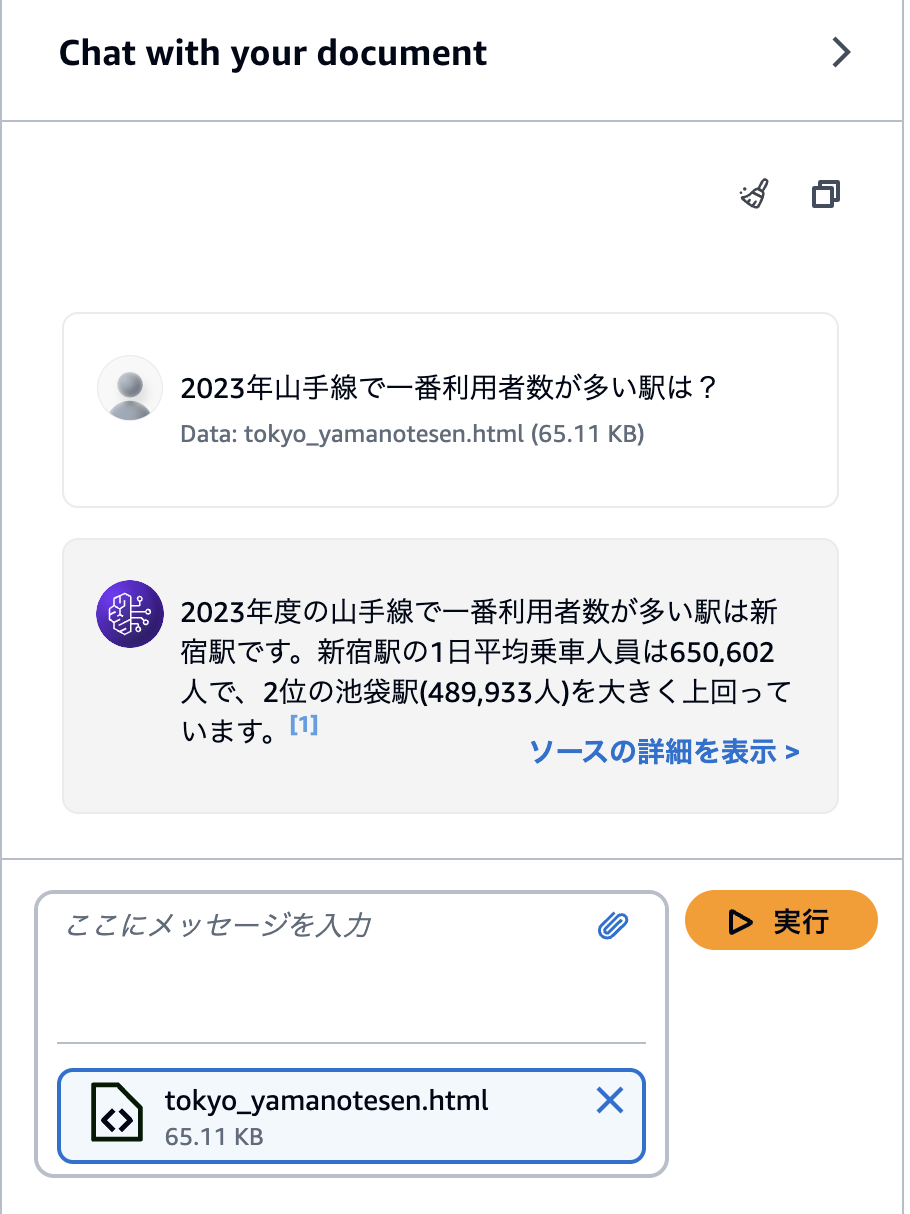
「2023年山手線で一番利用者数が多い駅は?」と聞いてみる。
確認してみる(SDK)
AWS ブログにサンプルがありましたので試してみます。
今回は document_uri に自身の S3 URI を指定します。
import boto3
bedrock_client = boto3.client(service_name='bedrock-agent-runtime')
model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
document_uri = "your_s3_uri_here"
def retrieveAndGenerate(input_text, sourceType, model_id, document_s3_uri=None, data=None):
region = 'us-west-2'
model_arn = f'arn:aws:bedrock:{region}::foundation-model/{model_id}'
if sourceType == "S3":
return bedrock_client.retrieve_and_generate(
input={'text': input_text},
retrieveAndGenerateConfiguration={
'type': 'EXTERNAL_SOURCES',
'externalSourcesConfiguration': {
'modelArn': model_arn,
'sources': [
{
"sourceType": sourceType,
"s3Location": {
"uri": document_s3_uri
}
}
]
}
}
)
else:
return bedrock_client.retrieve_and_generate(
input={'text': input_text},
retrieveAndGenerateConfiguration={
'type': 'EXTERNAL_SOURCES',
'externalSourcesConfiguration': {
'modelArn': model_arn,
'sources': [
{
"sourceType": sourceType,
"byteContent": {
"identifier": "testFile.txt",
"contentType": "text/plain",
"data": data
}
}
]
}
}
)
response = retrieveAndGenerate(
input_text="2023年山手線で一番利用者数が多い駅は?",
sourceType="S3",
model_id=model_id,
document_s3_uri=document_uri
)
print(response['output']['text'])
コンソールの時と同じ結果が返却されました。
$ python3 chat_with_your_document.py
2023年度の山手線で一番利用者数が多い駅は新宿駅です。新宿駅の1日平均乗車人員は650,602人で、2位の池袋駅(489,933人)を大きく上回っています。
ドキュメントなど