1 S3(input)##
音声用ファイルのS3バケットを作成しておく。
2 Lambda##
s3-get-object-pythonを利用していきます。
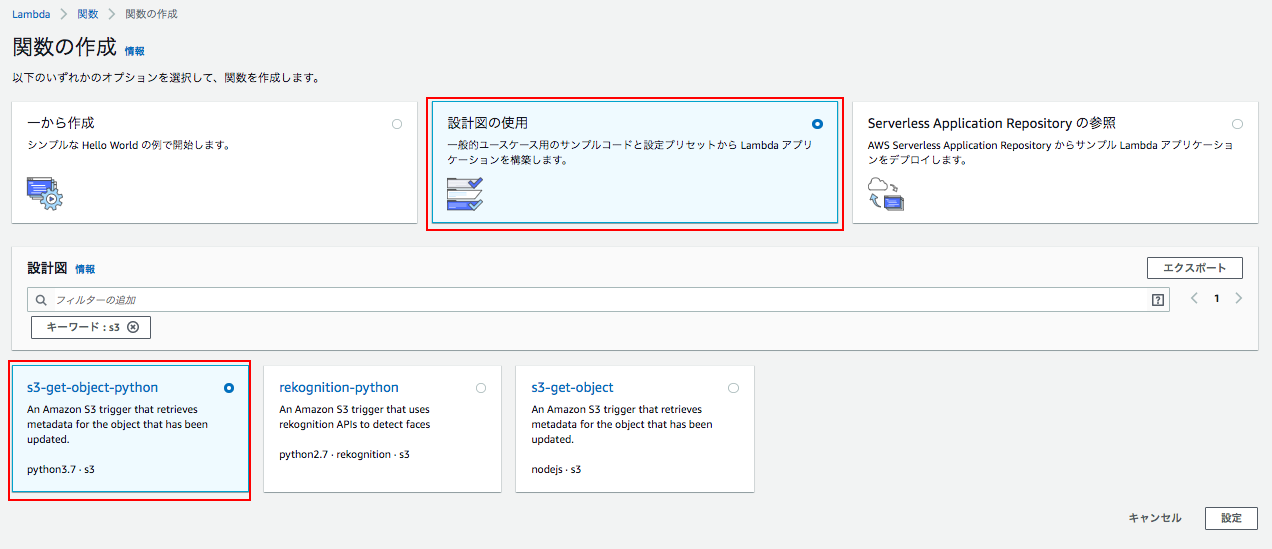
「1 S3(input)」で作成したS3バケットを選択し、「トリガーの有効化」にチェックを入れる。
import json
import urllib.parse
import boto3
print('Loading function')
s3 = boto3.client('s3')
def lambda_handler(event, context):
print("Received event: " + json.dumps(event, indent=2))
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
response = s3.get_object(Bucket=bucket, Key=key)
print("CONTENT TYPE: " + response['ContentType'])
return response['ContentType']
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
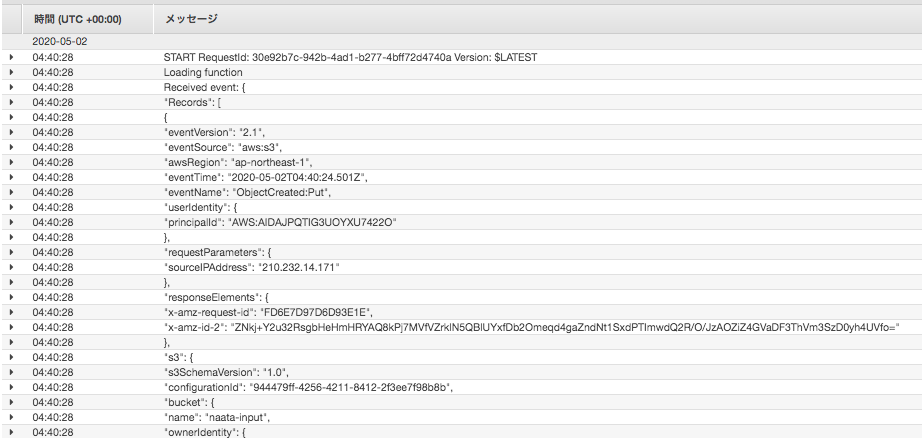
音声ファイルをS3バケットにアップロードし、CloudWatch Logsで動作していることを確認しておく。
3 S3(output)##
文字起こし用ののS3バケットを作成しておく。
4 Lambda修正##
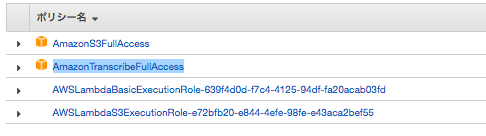
まず、実行ロールにAmazonTranscribeFullAccessとAmazonS3FullAccessを付与してあげる。
※TranscribeService
を参考にLambda functionを編集する。
import json
import urllib.parse
import boto3
import datetime
s3 = boto3.client('s3')
transcribe = boto3.client('transcribe')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
transcribe.start_transcription_job(
TranscriptionJobName= datetime.datetime.now().strftime('%Y%m%d%H%M%S') + '_Transcription',
LanguageCode='ja-JP',
Media={
'MediaFileUri': 'https://s3.ap-northeast-1.amazonaws.com/' + bucket + '/' + key
},
OutputBucketName='naata-ouput'
)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
5 Transcription#
「1 S3(input)」にmp3ファイルをアップロードし、
TranscriptionのOutput data locationに出力された「3 S3(output)」で
文字起こしされているかを確認する。