はじめに
ひとまずCIFAR-10は画像認識作業用のデータセットです。

画像はサイトにより (https://www.cs.toronto.edu/~kriz/cifar.html)
CIFAR-10は手書き数字のつぎ一番簡単なデータセットだと言われます。手書き数字は逆に簡単すぎて変数を調整しても効果が見づらいです。
今回はTensorflowを使って、いろんな変数を調整し、たくさんの手法を導入して精度を9%から73%に上げて、手法を探索しつつディープラーニングを学びます。ちなみに画像はOpenCVで処理して、one-hotラベルでエンコードします。
この記事は8月にGithubに投稿した記事に基づいて作成します。
https://github.com/leolui2004/cifar_compare
やり方
最初はCNNを使わずDense層だけ使うモデルコードを書きます。これは当然画像認識タスクにとって悪いモデルだけど、ここから徐々に他の手法を導入します。
学習率:0.0005
バッチサイズ:128
訓練回数:10回
ネットワーク:Dense層 x3
最適化:Adam
import tensorflow as tf
tf.device('/cpu:0')
tf.keras.backend.set_floatx('float32')
tf.compat.v1.disable_eager_execution()
import pickle
import numpy as np
c_InputNumber = 3072,
c_OutputNumber = 10
c_Lr = 0.0005 # 学習率
c_Batchsize = 128 # バッチサイズ
c_Epochs = 10 # 訓練回数
c_FolderPath = 'cifar10/'
c_Filepath_Train = f'{c_FolderPath}/dataset/data_batch_1'
c_Filepath_Test = f'{c_FolderPath}/dataset/test_batch'
class DenseModel:
def __init__(self, InputNumber, OutputNumber, Lr):
self.InputNumber = InputNumber
self.OutputNumber = OutputNumber
self.model = self.CreateModel()
self.opt = tf.keras.optimizers.Adam(Lr)
# ネットワークを構築
def CreateModel(self):
input = tf.keras.layers.Input(self.InputNumber)
layer1 = tf.keras.layers.Dense(1024, activation='relu')(input)
layer2 = tf.keras.layers.Dense(256, activation='relu')(layer1)
layer3 = tf.keras.layers.Dense(64, activation='relu')(layer2)
labels = tf.keras.layers.Dense(self.OutputNumber, activation='softmax')(layer3)
return tf.keras.Model(inputs=[input], outputs=[labels])
# ネットワークを作成
def CompileModel(self):
self.model.compile(loss='categorical_crossentropy', optimizer=self.opt, metrics=['accuracy'])
# ネットワークを訓練
def TrainModel(self, x_train, y_train, batch_size, epochs):
self.model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs)
# テストデータで評価
def EvaluateModel(self, x_test, y_test):
score = self.model.evaluate(x_test, y_test)
return score[1]
def Unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
# One-hotエンコード
def Onehot(value):
onehot = np.zeros((10))
onehot[value] = 1
return onehot
dict_train = Unpickle(c_Filepath_Train)
dict_test = Unpickle(c_Filepath_Test)
dense = DenseModel(c_InputNumber, c_OutputNumber, c_Lr)
x_train = dict_train[b'data']
y_train = np.zeros((10000,10))
x_test = dict_test[b'data']
y_test = np.zeros((10000,10))
for i in range(10000):
y_train[i][:] = Onehot(dict_train[b'labels'][i])
y_test[i][:] = Onehot(dict_test[b'labels'][i])
dense.CompileModel()
dense.TrainModel(x_train, y_train, c_Batchsize, c_Epochs)
print('Epoch Test')
accuracy = dense.EvaluateModel(x_test, y_test)
print('Accuracy: ', accuracy)
結果はこちらになります。テストデータの精度は9.26%です。
Train on 10000 samples
Epoch 1/10
10000/10000 - 1s 111us/sample - loss: 121.0524 - accuracy: 0.1384
Epoch 2/10
10000/10000 - 1s 110us/sample - loss: 21.6848 - accuracy: 0.1899
Epoch 3/10
10000/10000 - 1s 110us/sample - loss: 19.7853 - accuracy: 0.1953
Epoch 4/10
10000/10000 - 1s 110us/sample - loss: 12.3984 - accuracy: 0.2081
Epoch 5/10
10000/10000 - 1s 112us/sample - loss: 7.9875 - accuracy: 0.1667
Epoch 6/10
10000/10000 - 1s 117us/sample - loss: 2.3029 - accuracy: 0.0989
Epoch 7/10
10000/10000 - 1s 114us/sample - loss: 2.3013 - accuracy: 0.0985
Epoch 8/10
10000/10000 - 1s 114us/sample - loss: 2.2992 - accuracy: 0.0992
Epoch 9/10
10000/10000 - 1s 114us/sample - loss: 2.2978 - accuracy: 0.1002
Epoch 10/10
10000/10000 - 1s 114us/sample - loss: 2.2962 - accuracy: 0.0988
Epoch Test
Accuracy: 0.0926
そしていろんな中間テストをしました。全部コード出したら長すぎるので結果だけ載せます。
- Dense層からCNN(Conv2D)層に
- カラー - 46.63%
- グレースケール - 47.12%
- 訓練回数50回に、5バッチから1バッチに結合、検証用データ10%に
- CNN(Conv2D)層、カラー - 49.46%
- Resnet層、カラー - 62.89%
- CNN(Conv2D)層、グレースケール - 58.11%
- Resnet層、グレースケール - 60.74%
- 訓練回数100回に、1バッチに結合、検証用データ10%に、学習率指数関数的減衰
- CNN(Conv2D)層、カラー - 70.81%
- Resnet層、グレースケール - 64.32%
- 全部乗せ - 73.69%
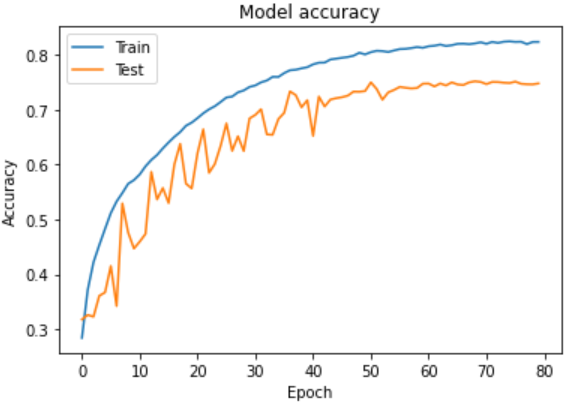
最後に73.69%に上がった手法はこちらです。
- バッチサイズ:32
- 訓練回数:80回
- ネットワーク:Resnet-56
- 最適化:Amsgrad
- 5バッチから1バッチに結合
- 検証用データ10%に
- 学習率指数関数的減衰 (Exponential Decresing)
- データ拡張 (Data Augmentation)
import tensorflow as tf
from tensorflow import keras
from keras.preprocessing.image import ImageDataGenerator # データ拡張用
from sklearn.model_selection import train_test_split
tf.keras.backend.set_floatx('float32')
tf.compat.v1.disable_eager_execution()
import pickle
import numpy as np
import matplotlib.pyplot as plt
c_InputNumber = 32,32,3
c_OutputNumber = 10
c_Lr = 0.0005
c_Batchsize = 32
c_Epochs = 80
c_Filepath_Train = 'data_batch_'
c_Filepath_Test = 'test_batch'
class DenseModel:
def __init__(self, InputNumber, OutputNumber, Lr):
self.InputNumber = InputNumber
self.OutputNumber = OutputNumber
self.model = self.CreateModel()
self.opt = tf.keras.optimizers.Adam(Lr, amsgrad=True) # Amsgradを適用
# 学習率指数関数的減衰
def Scheduler(self, epoch):
# 最初の10回は0.005、その後徐々に下げる
if epoch < 10:
return 0.005
else:
return 0.005 * tf.math.exp(0.1 * (10 - epoch))
# Resnet-56
def CreateModel(self):
channels = [16, 32, 64]
input = tf.keras.layers.Input(self.InputNumber)
x = tf.keras.layers.Conv2D(channels[0], kernel_size=(3, 3), padding='same',
kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(input)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation(tf.nn.relu)(x)
for c in channels:
for i in range(9):
subsampling = i == 0 and c > 16
strides = (2, 2) if subsampling else (1, 1)
y = tf.keras.layers.Conv2D(c, kernel_size=(3, 3), padding='same', strides=strides,
kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(x)
y = tf.keras.layers.BatchNormalization()(y)
y = tf.keras.layers.Activation(tf.nn.relu)(y)
y = tf.keras.layers.Conv2D(c, kernel_size=(3, 3), padding='same',
kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(y)
y = tf.keras.layers.BatchNormalization()(y)
if subsampling:
x = tf.keras.layers.Conv2D(c, kernel_size=(1, 1), strides=(2, 2), padding='same',
kernel_initializer='he_normal', kernel_regularizer=tf.keras.regularizers.l2(1e-4))(x)
x = tf.keras.layers.Add()([x, y])
x = tf.keras.layers.Activation(tf.nn.relu)(x)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Flatten()(x)
labels = tf.keras.layers.Dense(self.OutputNumber, activation='softmax', kernel_initializer='he_normal')(x)
return tf.keras.Model(inputs=[input], outputs=[labels])
def CompileModel(self):
self.model.compile(loss='categorical_crossentropy', optimizer=self.opt, metrics=['accuracy'])
def TrainModel(self, x_train, x_valid, y_train, y_valid, batch_size, epochs):
# データ拡張を適用 (回転、フリップ、シフト)
igen = ImageDataGenerator(rotation_range=10, horizontal_flip=True, width_shift_range=0.1, height_shift_range=0.1)
igen.fit(x_train)
callback = [tf.keras.callbacks.LearningRateScheduler(self.Scheduler)]
history = self.model.fit_generator(igen.flow(x_train, y_train, batch_size=batch_size), steps_per_epoch=len(x_train)/batch_size,
validation_data=(x_valid, y_valid), epochs=epochs, callbacks=callback, verbose=2)
return history
def EvaluateModel(self, x_test, y_test):
score = self.model.evaluate(x_test, y_test)
return score[1]
class Agent:
def __init__(self, InputNumber, OutputNumber, Lr):
self.InputNumber = InputNumber
self.OutputNumber = OutputNumber
self.Lr = Lr
self.dense = DenseModel(self.InputNumber, self.OutputNumber, self.Lr)
def Unpickle(self, file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
def Pixelize(self, flat):
return np.reshape(flat, (32,32,3))
def Onehot(self, value):
onehot = np.zeros((10))
onehot[value] = 1
return onehot
def Encode(self, dict):
x = np.zeros((10000,32,32,3))
y = np.zeros((10000,10))
for i in range(10000):
x[i][:][:][:] = self.Pixelize(dict[b'data'][i])
y[i][:] = self.Onehot(dict[b'labels'][i])
return x, y
def Run(self, Filepath_Test, Filepath_Train, Batchsize, Epochs):
self.dense.CompileModel()
dict_test = self.Unpickle(Filepath_Test)
x_test, y_test = self.Encode(dict_test)
# 5バッチから1バッチに結合
for i in range(1, 6):
dict_train = self.Unpickle(Filepath_Train + str(i))
if i == 1:
x_train, y_train = self.Encode(dict_train)
else:
x, y = self.Encode(dict_train)
x_train = np.vstack((x_train,x))
y_train = np.vstack((y_train,y))
# 検証用データに分ける
x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.1, shuffle=True)
history = self.dense.TrainModel(x_train, x_valid, y_train, y_valid, Batchsize, Epochs)
print('Epoch Test')
accuracy = self.dense.EvaluateModel(x_test, y_test)
print('Accuracy: ', accuracy)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
agent = Agent(c_InputNumber, c_OutputNumber, c_Lr)
agent.Run(c_Filepath_Test, c_Filepath_Train, c_Batchsize, c_Epochs)
もっと上に目指すなら
実は現在SOTAのモデルは既に95%に達しました。しかしそれほとんどは簡単に導入できるモデルではないです。今回はあくまで手法を探索しながら勉強するために書きますので必ずSOTA並みの結果を得る必要がないと思います。
CIFAR-10のリーダーボード
https://paperswithcode.com/sota/image-classification-on-cifar-10
もう一つ
ネットで調べると精度90%以上のサンプルコードがたくさんあります。しかもコードがすごく簡単です。しかし先話した通り、何十行だけのコードならSOTA並みの結果が出る可能性が低いです。そしてなぜか90%以上という結果が出ますか。コードを見るとほぼ100%損失関数の設定が間違いました。
それを再現するために、上記nのプログラムの損失関数をbinary_crossentropyに変わってみます。
Epoch 1/10 45000/45000 - 13s - loss: 2.7665 - accuracy: 0.8200 - val_loss: 2.7680 - val_accuracy: 0.8195
その結果は1回目の訓練にも82%の精度に達しました。明らかに問題がありますね。詳しい説明はこのリンク (https://stackoverflow.com/questions/41327601/why-is-binary-crossentropy-more-accurate-than-categorical-crossentropy-for-multi) に参考してもいいですけど、簡単に言うとbinary_crossentropyは元々2分類作業用の損失関数です。なのでCIFAR-10のような10種類がある画像認識作業で使うと当然正しい結果を表現できないです。