Yoasobiの歌詞で、GCP APIとTransformersの感情分析結果を比較
Github(英語バージョン)
https://github.com/leolui2004/sentiment_compare
2つの手法の紹介
Google Cloud Platform NLP API
GCPは、さまざまな種類のNLP APIを提供します。自分は感情分析をよく使っています。これはスコアとマニチュードの形でテキストの感情を判断できます。
Transformers と BERT
BERTは、Googleが提供する優れたNLP事前トレーニング済みモデルであり、Transformersは、NLPタスクを迅速に開発するための優れたライブラリでもあります。今回は、daigo/bert-base-japanese-sentimentという事前トレーニング済みモデルとbert-base-japanese-whole-word-maskingという事前トレーニング済みトークナイザーを使用しました。
手法の違い
分析結果とは別に、2つの手法の主な違いは次のとおりです。
-
GCP NLP APIは有料です。1か月あたり無料の割り当て(約5,000句)を提供しますが、実際には十分ではないはずです。一方、Transformersと公開の事前トレーニング済みモデルを使用する場合は完全に無料です。ちなみにライブラリを提供するHugging Face社には、プライベートモデルやデータセットのように使用するプランがいくつかあります。
-
GCPによるNLP APIの使用は、コンピューティングリソースを消費することはめったにありません。基本的には、APIを呼び出して結果を取得するだけです。ただし、事前トレーニング済みモデルとTransformerを使用すると、一部のコンピューティングリソースを消費します(Transformerの使用にかかる時間が下記にデモします)。また、モデルのトレーニングまたはモデルの微調整に必要なリソースと比べて、事前トレーニング済みモデルを直接使用して分析する場合の方が当然消費するリソースが圧倒的に少ないです。
プロセス
紹介
GCP NLP APIとTransformersの入手方法についての説明を割愛しますが、 GCP NLP APIの場合、GCPのドキュメントを読んで、サービスアカウントを作成してAPI jsonキーを取得するのに10分もかかりません。Transformersの場合、自分はTensorflow 2を使用しています。互換性について、Transformersの最新バージョンがTensorflow 2をどの程度サポートしているかわかりません。なので古いバージョン(Transformers==2.10.0)を使用しています。
分析対象としては、日本の有名グループYoasobiの歌詞を使用します。歌詞は常にNLP分析の良いターゲットであり、難しいターゲットです。
- 歌詞は時代によって変わる
- 歌詞には珍しい単語が使われている場合があります。
- 歌詞は通常、感情的な文書が多い
- 歌詞は、人によって読むと意味が異なる
そしてテストのために、それは3つの部分に分かれます
- パート1:単語(健全性チェックとして)
- パート2:短い文
- パート3:歌詞の一段落または長文
GCP NLP API サンプルコード
必要なライブラリをインポートする
import time
from google.cloud import language_v1
import os
APIを定義し、APIの制限に触れないようにするために、常に0.1秒のバッファーを追加します
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "nlp.json"
client = language_v1.LanguageServiceClient()
def api_call(text):
document = language_v1.Document(content=text, type_=language_v1.Document.Type.PLAIN_TEXT, language='ja')
response_sentiment = client.analyze_sentiment(request={'document': document, 'encoding_type': language_v1.EncodingType.UTF8})
result = []
result.append(text)
result.append(response_sentiment.document_sentiment.score)
time.sleep(0.1)
return result
ワードリスト(パート1)
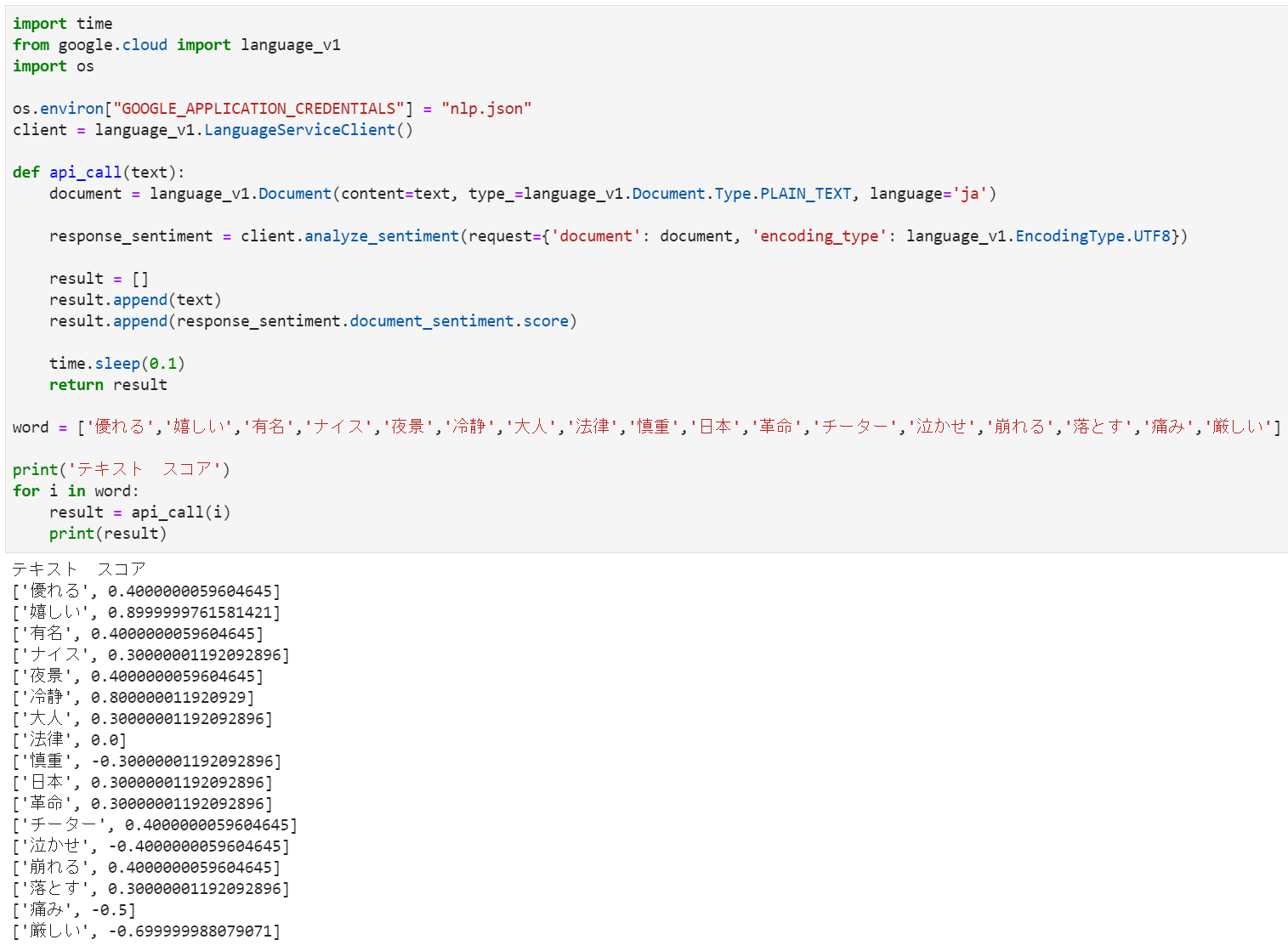
word = ['優れる','嬉しい','有名','ナイス','夜景','冷静','大人','法律','慎重','日本','革命','チーター','泣かせ','崩れる','落とす','痛み','厳しい']
テストを行う
print('テキスト スコア')
for i in word:
result = api_call(i)
print(result)
Transformers サンプルコード
必要なライブラリをインポートする
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer
2つの事前トレーニング済みモデルを使用してパイプラインを構築します
model = AutoModelForSequenceClassification.from_pretrained('daigo/bert-base-japanese-sentiment')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer)
ワードリスト(パート1)
word = ['優れる','嬉しい','有名','ナイス','夜景','冷静','大人','法律','慎重','日本','革命','チーター','泣かせ','崩れる','落とす','痛み','厳しい']
テストを行う
print('テキスト スコア')
for i in word:
print(nlp(i))
歌詞サンプル
文リスト(パート2、3)
lyrics_short = ['素敵な日になっていく', # もう少しだけ
'喜びはめぐる',
'慌ただしく過ぎる朝',
'気持ちが沈んでいく朝',
'もう少しだけ',
'喜びが広がる',
'小さな幸せを見つけられますように',
'涙流すことすら無いまま', # たぶん
'目を閉じたまま考えてた',
'悪いのは誰だ 分かんないよ',
'誰のせいでもない',
'一人で迎えた朝',
'仕方がないよきっと',
'優しさの日々を辛い日々と感じてしまった',
'少し冷えた朝だ']
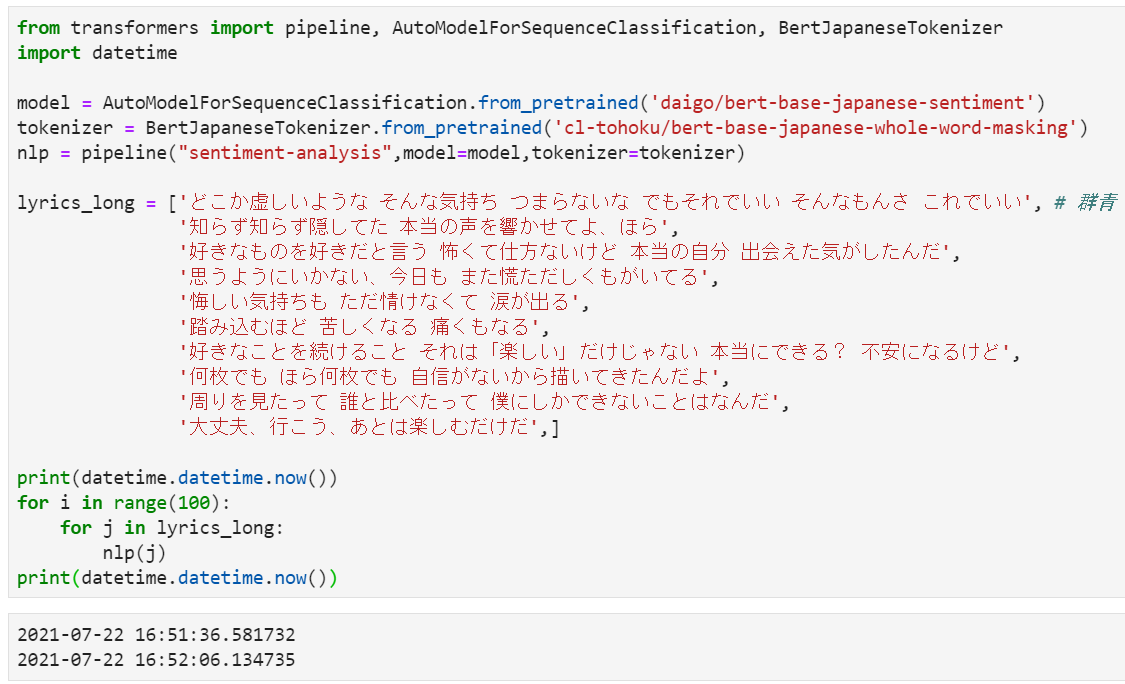
lyrics_long = ['どこか虚しいような そんな気持ち つまらないな でもそれでいい そんなもんさ これでいい', # 群青
'知らず知らず隠してた 本当の声を響かせてよ、ほら',
'好きなものを好きだと言う 怖くて仕方ないけど 本当の自分 出会えた気がしたんだ',
'思うようにいかない、今日も また慌ただしくもがいてる',
'悔しい気持ちも ただ情けなくて 涙が出る',
'踏み込むほど 苦しくなる 痛くもなる',
'好きなことを続けること それは「楽しい」だけじゃない 本当にできる? 不安になるけど',
'何枚でも ほら何枚でも 自信がないから描いてきたんだよ',
'周りを見たって 誰と比べたって 僕にしかできないことはなんだ',
'大丈夫、行こう、あとは楽しむだけだ',
'さよならだけだった', # 夜に駆ける
'初めて会った日から 僕の心の全てを奪った',
'どこか儚い空気を纏う君は 寂しい目をしてたんだ',
'涙が零れそうでも ありきたりな喜びきっと二人なら見つけられる',
'見惚れているかのような恋するような そんな顔が嫌いだ',
'君の為に用意した言葉どれも届かない',
'終わりにしたい だなんてさ 釣られて言葉にした時 君は初めて笑った',
'騒がしい日々に笑えなくなっていた 僕の目に映る君は綺麗だ',
'明けない夜に溢れた涙も 君の笑顔に溶けていく',
'繋いだ手を離さないでよ 二人今、夜に駆け出していく',
'ただその真っ黒な目から 涙溢れ落ちないように', # 怪物
'この間違いだらけの世界の中 君には笑ってほしいから',
'もう誰も傷付けない 強く強くなりたいんだよ 僕が僕でいられるように',
'ありのまま生きることが正義か 騙し騙し生きるのは正義か 僕の在るべき姿とはなんだ 本当の僕は何者なんだ 教えてくれよ',
'不器用だけれど いつまでも君とただ 笑っていたいから']
結果
結果を画像で表示
これはテストを実行した後の結果ですが、結果を確認するのは難しいので、表に入れて、いくつかの可視化を追加します
パート1結果(ワード)
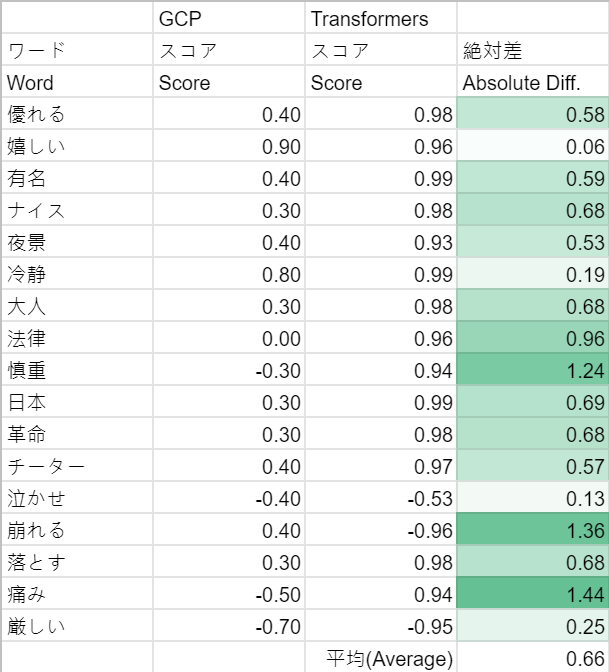
結果は驚くべきものであり、2つの事前トレーニング済みモデルを使用するTransformersは、一部の単語分析で失敗しました。ネガティブな言葉であるはずの「痛み」、ニュートラルな言葉であるはずの「大人」、「日本」のような言葉ですが、適切にスコアリングできませんでした。
GCP NLP APIもそれほど完璧ではありませんが(たとえば、「崩せる」の場合は+0.4)、パート1では基本的に良好な結果が得られました。
パート2結果(短い文)
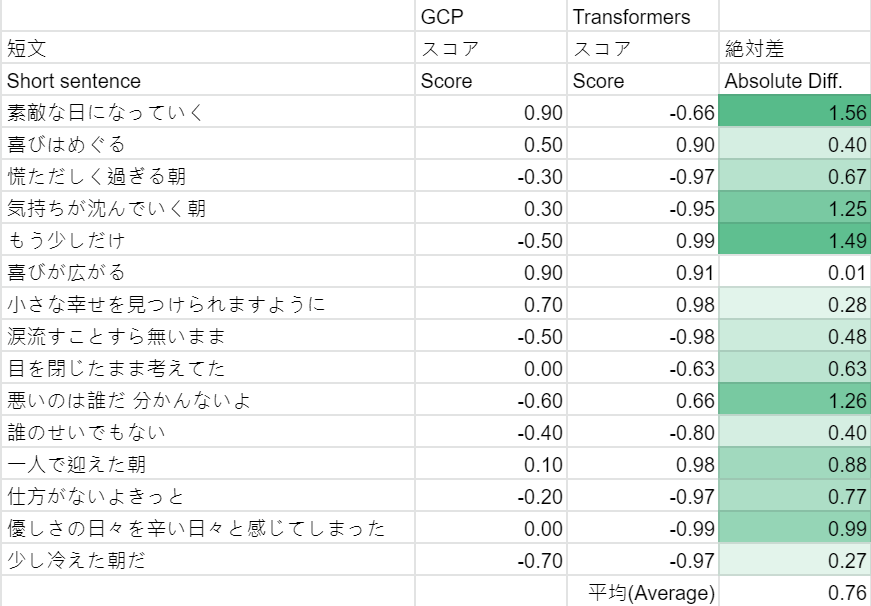
短い文になると、平均絶対スコアの差はさらに大きくなります。ただし、今回はGCPとTransformersの両方でそれぞれ良い結果と悪い結果が得られます。ここで、さらに説明するためにいくつか取り上げます。
-
素敵な日になっていく
GCPのスコアは+0.90でしたが、Transformersのスコアは-0.66でした。完全に間違っています。 -
気持ちが沈んでいく朝
GCPが「気持ちが沈む」という単語を認識できなかった可能性があります。今回、Transformersはうまく機能しました。 -
悪いのは誰だ 分かんないよ
これは興味深いことです。GCPとTransformers両方が完全に反対の方向にスコアリングされています -
優しさの日々を辛い日々と感じてしまった
これもトリッキーで、ポジティブな単語(「優しさ」)とネガティブな単語(「辛い」)両方が文に含まれており、GCPは文の構造を認識できませんでした
パート3結果(歌詞の一段落または長文)

パート3は最も難しい部分であり、人によって解釈が異なる場合があります。 1つずつ説明するつもりはありませんが、傾向としてGCPはより保守的であり、約半分は+ 0.2〜-0.2のスコアであり、一方、Transformersは常に高いスコア(ポジティブ、ネガティブでも)を示します。
パフォーマンス(速度)テスト
最後に、Transformersの速度テストも行い、分析を1,000回繰り返しました。これは、APIを使用するのと同じくらい高速で、30秒未満でタスクを完了したことを示しています。