はじめに
技術的な話メインというよりは、技術を用いて身近な課題を解決した例の1つとして、どういう思考プロセスがあったかを中心とした作業記録としてお読みください。
課題:技術記事の情報収集がつらい
ITエンジニアとして日々の研鑽を怠ってはいけない、ということで以前は毎朝以下の作業を行っていました。
- TechFeedから送られるおすすめ記事チェック
- Qiita/Zennのトレンドに一通り目を通して気になる記事をチェック
しかし続けているうちに気になる点がいくつか出てきました。
TechFeed
- メールでしか受け取れない
- AI関連記事が半分以上を占める
Qiita/Zenn
- 量が多く時間がかかる
- 毎日チェックすると同じ記事を何度も見る
これら1つ1つは些細なことですが、毎日行うことは最適化するに越したことはありません。
そしてこれら全てを解決するような都合の良いサービスは(筆者の知る限り)存在しません。
ということで、自分自身のための開発を開始しました。
作ったもの
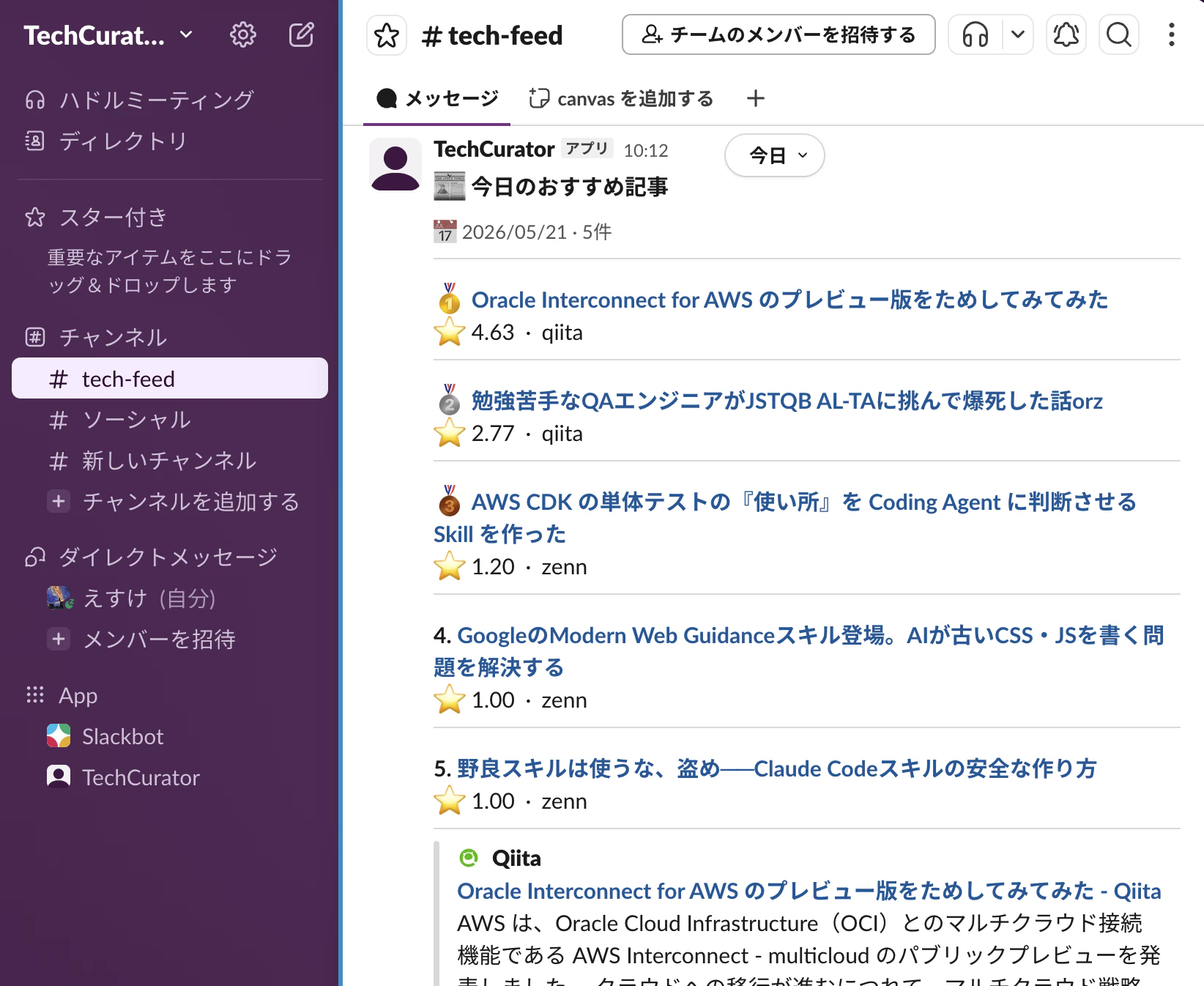
TechCuratorという名前にしました。
このように、Slackに毎朝Botからおすすめ記事が届きます。
フローは以下のようになっています。
使い方
セットアップ後は自動的に定期実行されるので、基本的には何もする必要はありません。
自分も使いたいからセットアップ手順を知りたいという方は リポジトリ のREADME.mdをご覧ください。あるいは直接ご質問いただけたら可能な限りお答えします。
キーワードと重みづけをYAML形式で定義すれば、その重みや記事のいいね数に基づきスコアが計算され、上位N件が推薦されます。
セットアップ後に唯一やる作業は、この設定の調整です。
fetch_days: 3 # 過去N日間の記事を取得
keywords:
TypeScript: 1.0
React: 1.0
AWS: 1.0
LLM: 1.5 # 重みを上げると優先度が上がる
...(中略)
exclude_keywords: # 除外したいキーワード
- 初心者
- 入門
threshold: 0.5 # この値以上のスコアの記事のみ通知
top_k: 5 # 通知する最大件数
自作Botによって課題がどう解決されたか
TechFeed
- メールでしか受け取れない
-> Slackで受け取れるようになりました。Slackアプリは常に開いているのでアクセスまでの手間が小さいのと、メールボックスがごちゃごちゃにならずに済むのが嬉しいポイントです。 - AI関連記事が半分以上を占める
-> 運用する中で重みを適宜調整していくことによって、自分の好みのバランスにできます。
Qiita/Zenn
- 量が多く時間がかかる
-> 自分でカスタマイズした数だけの記事に絞れます。 - 毎日チェックすると同じ記事を何度も見る
-> 推薦済みの記事は除去されるので、同じ記事を何度も見ることはありません。
設計判断
ユーザは自分一人の前提で作っているため、動作の完全性や拡張性の改善点などは基本放置しています。
投稿済み記事の状態管理
ソースコードと運用のシンプルさ優先で、DBを使わず過去の投稿履歴を使用することにしました。
例えば fetch_days: 3 と設定したら過去3日間のQiitaやZennの記事を取得することを意味します。
したがってSlack上でも過去3日間の投稿をチェックすればOKとしています。
しかし挙動の完全性の観点においてこの設計には穴があり、設定変更した場合に齟齬が発生します。
DBに投稿記事を保存したりあるいはちゃんとロジックを組めば回避できるかもしれませんが、そんなに頻繁に変更しないだろうというのと影響も致命的ではないというので放置でOKとしました。
重み設定の保存
こちらもシンプルさ優先でDBを使わない判断にしました。
またソースコード本体に入れてしまうと重み調整の度にコミットすることになって面倒です。
よってGitHubのRepository Variablesに CONFIG という名前でYAMLをそのまま書くことにしました。
開発にどれくらいかかった?
トータルで8時間ぐらいです。
Claude CodeとSuperpowersを使って設計からデプロイまで対話的に進めたら、大きなバグもなく完成しました。
未解決課題
スコアリングアルゴリズムの検証可能性の向上
実際のスコア計算は
\text{score} = \sum_{k \in \text{matched keywords}} w_k + \log(\text{likes} + 1)
となっています。
この計算式に対して物申したい方はおそらくたくさんいらっしゃるかと思われます。
ですがもっと深い問題として、この計算式を改善しようとしたとして、実際に改善されたかどうかを検証する術は今の所ないというのがあります。
例えば記事のクリック率をデータとして収集すること自体は可能です。しかし、ユーザが自分一人の状況では母数が小さすぎて誤差の範囲かどうかの判定ができません。
キーワードマッチが部分文字列一致になっている問題の解決
例えば"Go"をキーワードに入れると"Google"や"Django"にもマッチしてしまいます。筆者が現在設定しているキーワードでは特に問題ないので放置していますが、他の人にも使ってもらう場合や好みが変わった場合は対応が必要です。
まとめ
思ったよりさくさく作れて、使い心地もシンプルでいい感じにできました。
また、AIとの共同開発にてやたら綺麗で拡張性や信頼性などに富んだ設計を薦めてくるのに対して、過剰にならないよう適切にブロック(?)しつつ手早くまとめられたのではないかと思います。
普段の開発においては大変ありがたいのですが、ケースバイケースで適切な付き合い方をしていきたいものです。
今回は自分だけが使うための開発だったので、次は広く使ってもらえるような個人開発に挑戦したいです。