今回、RDS Storage Auto Scalingを実施したので、注意点も含め記事にしたいと思います。
https://aws.amazon.com/about-aws/whats-new/2019/06/rds-storage-auto-scaling/?nc1=h_ls:embed:cite
・今までRDSにアタッチしているEBSはある程度の重要予測とIOPSを考慮しサイズを決めるオンプレミスライクな仕様でしたが、任意の容量を設定しておくだけで、適宜自動スケールするサービスが開始されました。設定の有効化は非同期処理されてI/O中断も発生しないので、メリットしかないですね。ただし、認識しておきたい箇所があります。
- 一度に大きなデータが取り込まれるときはスケールに時間がかかるので機能低下が発生する可能性がある
- スケール後、6時間あるいはDBインスタンスステータスが [Storage-optimization] の間のいずれか長い方の間はスケールしない
- 2017年11月からストレージ構成に修正を加えていない場合には、割り当てるストレージを増加するためにDBインスタンスを編集するときに数分間の短い停止が発生することがある
・1と2は検証が必要だし発生確率は低く、運用でカバーできますが、3が怖いですね...これ何を言ってるかというと対象のRDSがElasticVolumeでなかった場合はI/O中断することがあるやん?ってことです。
しかも不便なのがElasticVolumeなのかどうかをCLIやGUIでは参照できないという...
なので、2017年11月以前から起動しているRDSは必ず確認して実行しないとI/O中断する可能性があります。ちゃんとドキュメント読んで確認しないとダメージを受けてしまいます。
https://aws.amazon.com/jp/about-aws/whats-new/2017/11/amazon-rds-now-supports-database-storage-size-up-to-16tb-and-faster-scaling-for-mysql-mariadb-oracle-and-postgresql-engines/:embed:cite
・今回、Created timeがThu Jun 02 2016 10:32:42 GMT+0900 (日本標準時)というRDSに対してStorage Auto Scalingを有効化してみました。
結果として、I/O中断は発生しませんでしたが、スケーリング時にボリューム間でのデータの移行が発生しWriteIOPSとReadIOPSがスパイクしました。
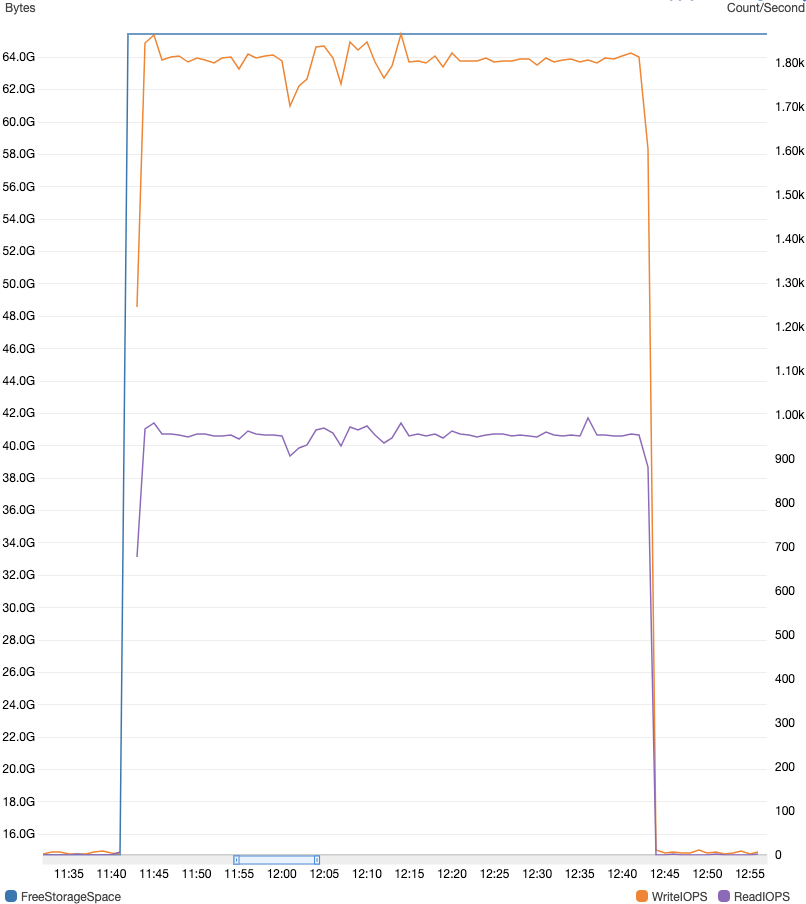
・当該RDSインスタンスは理論上ベースラインパフォーマンスは1200IOPS(gp2のバーストは最大3000IOPS)なので、クレジットが枯渇したとしてもサービス影響はないのですが、アラートが発火するので精神的にネガティブニュースです。結局、400GiBのElasticVolumeへの移行は65分ほど要しました。
・最新のアップデートは過去の複数のアップデートが絡んでいるので、注意深く見ることが必要だと再認識しました。焚き火して精神をスケールさせたいです...