Kaggle Advent Calendar 13日目の投稿です。
初めまして、Lain(@lain_m21)と申します。Qiita初投稿です!
今回はKaggle関連のトピックで何か短いのを一本書こうと思い、私が普段行なっているコンペ用の環境構築についていくつか良いなと思ったtipsをシェアしたいです。
先に結論からまとめておくと、
- ローカルPCよりクラウドの計算資源をうまく使おう
- AWSもいいけど、GCPの方が目的に応じてインスタンススペックを細かくチューニングできるので良いぞ
- 今後のクラウドの環境構築をスムーズにするためにdockerを使おう
といった感じです。昨今のコンペの規模を考えるとクラウドで計算することが増えると思うのですが、いちいちコンペごとに環境構築したりめんどくさいと思うので、できるだけdockerで自動化して楽しよう!というのが趣旨になります。
一応順を追って説明しますが、「GCPって何?」の状態だとちょっと苦しいので、そういった方はあらかじめこちらの記事の第一回と第二回を先に読んでおいてもらえるとスムーズだと思います。
また、GCPを使う際はコマンドラインツールのCloud SDK経由で作業すると便利なことが多いので、こちらの手順に従って先にインストールしておかれることをお勧めします。
ローカルPC VS クラウドインスタンス
昨今のKaggleはデータサイズが大きいコンペが多く、なかなか手元の自分のマシンだけでコンペを戦うのは厳しい環境になってきているのではないでしょうか。例えば、今年開催されたAvito Demand Prediction Challengeというコンペでは、100万件を超えるテーブルデータ、自然言語データ、画像データをフルに活用しなければなりませんでした。100万件に満たないテーブルデータのみのコンペでさえ、大量の特徴量を生成してモデルの比較を高速に回したいとなると、どうしてもマシンパワーが必要になってきます。
自分のローカルPCで強いものを組むのも有り(ロマン的な意味でも)ですが、コンペで使っていないときはちょっともったいないですし、実際に家で動かすと「マシンを作るお金」だけでなく「マシンを動かすお金(=電気代)」もかかってきます。また、一度組み立てちゃうとスペックの微調整などが難しいですよね。パワフルすぎるマシンは配電盤からいじらないといけなくなるかもしれません。
一方、クラウドの計算機リソースを使うと、ローカルの環境と比べて以下のようなメリットがあります。
- コンペに合わせてマシンパワーを調整できる
- 必要になればインスタンスを大量に立ち上げて一気に追い込みもかけられる
- コンペ用データがローカル環境を圧迫することがない
- 何か変なことが起きて使えなくなっても、最悪インスタンスを消せば良い
特に1と2が魅力的ですよね。データの種類やコンペのステージ(序盤か終盤か)で欲しいリソース量は変わってきます。最初のEDA(Exploratory Data Analysis)の時点で64core 416GB RAM 4xTesla P100とか絶対いらないですよね。
というわけで、クラウドの計算資源を上手く使ってコンペを戦っていきましょう!
クラウドで計算したいとなると、AWS、Azure、GCPなどが主な選択肢になるかとは思うのですが、私のオススメは断然GCPです。

GCPが提供するGCE(Google Cloud Engine)では、インスタンスの性能を細かくチューニングすることができます。CPU数、GPU数、メモリの3点は、用途に合わせて調整することでコストを大きく削減できます。しかも、この調整はインスタンスを一度作成した後でも可能です。さらにそれ以外にも、Google BigQuery/Cloud Storageとの連携がやり易かったり、Cloud SDKというコマンドラインツールが使い易かったりなど良いことが色々あるんですが、今回は環境構築にフォーカスするのであまり触れないでおきます。また機会があったらそこらへんについても書きたいです。
とりあえず使ってみよう!の前に、ざっくりコスト感、どんな感じになるのか気になりますよね。そこで、以下のテーブルによくありそうなユースケースごとのコストをまとめておきましたので参考にしてみてください。
| ユースケース | マシンスペック | 1時間あたり | 1日ずっと使った時 | 1ヶ月ずっと使った時 |
|---|---|---|---|---|
| EDA | CPU 8 cores, 52GB RAM | $0.33 | $7.92 | $242.41 |
| テーブルデータコンペ (序盤) |
CPU 32 cores, 208GB RAM | $0.66 | $15.84 | $484.82 |
| テーブルデータコンペ (終盤) |
CPU 96 cores, 624GB RAM | $3.98 | $95.52 | $2904.52 |
| 画像コンペ(序盤) | CPU 8 cores, 52GB RAM, Tesla P100 x1 |
$1.35 | $32.40 | $988.47 |
| 画像コンペ(終盤) | CPU 16 cores, 104GB RAM, Tesla P100 x4 |
$4.75 | $114.00 | $3373.00 |
・・・なかなか良いお値段ですね(辛い)でも常に起動し続けるわけでもないので、状況によって必要スペックを使い分けていきましょう。
また、GCPにはプリエンプティブインスタンスというものもあり、さらに値段を抑えることもできます。
GCPとDockerで環境構築してみよう
ここからが本題です。一つ例をとってKaggle用の計算環境を実際に構築してみましょう。
実際のコンペではなく、今回は以下のような仮想コンペに取り組んでいる状況を想定します。
- 自然言語処理コンペ
- データサイズ:全体で3.0GBくらい
- カーネル提出型ではない
生のデータサイズはそこまで大きくないですが、自然言語処理はメモリを多く必要とする場面が多いので、メモリは大きめにとっておいたほうがよさそうです。
また、最近はLSTMをはじめとしてNeural Networkでの系列モデリングが主流になっているので、GPUも使えるようにしておきたいですね。
というわけで、以下のようなインスタンスを立ち上げます。
- CPU 16 cores
- 104GB RAM
- GPU Tesla P100 x1
ここから先は以下のようなワークフローで作業をしていきます。
- GCEインスタンスを作成して立ち上げる
- Dockerでベースイメージを引っ張ってきて環境構築をする
- 環境構築済みのイメージをGCRにプッシュして、最後の追い込みや、今後別のコンペでも使い回せるようにする
それではひとつ一つ見ていきましょう。
GCEインスタンスの作成
さて、GPUを使ったインスタンスなのですが、**「あれ、もしかしてCUDAをいちいちインストールしないといけないのか...?」**って思われるかもしれません。結論から言うと、その必要は全くないです。すでにCUDAとNvidia Driverがインストールされた状態のインスタンスを作成することができます!
GCPのコンソールのタブからCompute Engineを選ぶと、以下のようなリストが表示されます。
ここで赤く囲ったMarketplaceをクリックすると、すでにいろんなものがインストールされたマシンイメージを探して、好きなイメージから直接インスタンスを立ち上げることができます。
試しにMarketplaceをクリックして検索タブに deep learning と打ち込むと、以下のようなイメージが見つかります。
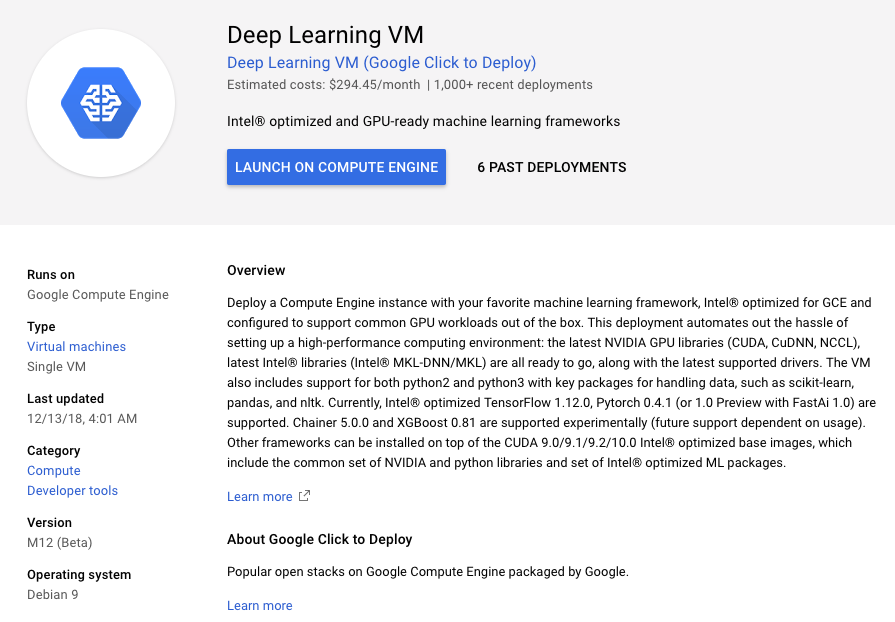
これをベースにマシンスペックをチューニングしていきましょう。
上の画像のLAUNCH ON COMPUTE ENGINEをクリックすると、以下のようにインスタンスのスペックを設定する画面が出てきます。
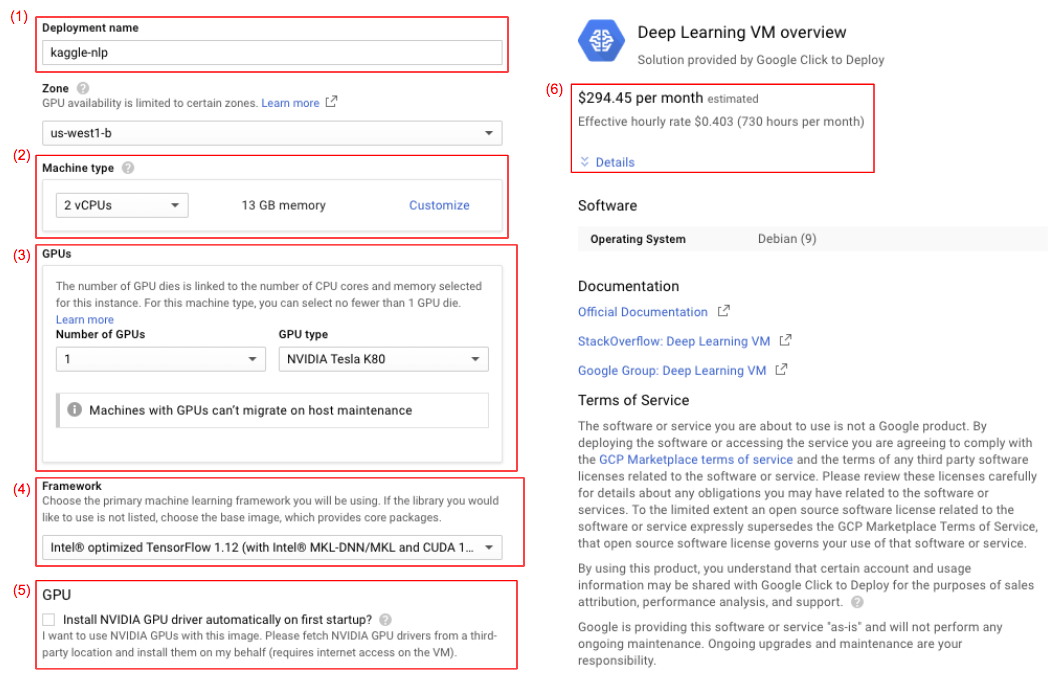
入力・確認すべき大事なところ(赤く囲ったところ)をひとつひとつ説明していきますね。
(1) Deployment name
これから立ち上げようとしているインスタンスの名前になります。Deep Learning VMでは、ここに打ち込んだ名前 + -vmがインスタンス名になるので、今回の場合はkaggle-nlp-vmがインスタンス名ですね。このインスタンス名はCloud SDKを使ってローカルからsshするときに使います。
(2) Machine type
ここでGPUとストレージ以外のマシンスペックを決めます。Customizeをクリックすることで細かく設定できるようになります。
(3) GPUs
ここでGPUの種類と数を決めます。ただひとつ問題が!GCEでは、コア数に応じて設置できるGPUの下限が決まっています。例えば、32 coresに設定していると、Tesla P100は2枚以上設置しないといけません。なので、少ないGPU数で済ませるためにはcore数も小さく設定しなければなりません。
(4) Framework
これはMarketplaceで選んだDeep Learning VMのマシンイメージ特有の設定項目です。このタブから、あらかじめインストールしてもらうCUDAのバージョンを決められるのと、あらかじめTensorFlowなどのフレームワークをインストールしてもらうことができます。ただ、例えば自分でAnacondaなどを入れてそのPythonを使うとなるとフレームワークは別途インストールしないといけません。
今回は、とりあえずIntel®︎ optimized Base (with Intel®︎ MKL and CUDA 10.0)を選びます。というのも、どうせ後々dockerで環境構築するので別に今フレームワークが入っていなくてもいいからです。
(5) GPU
このチェックボックスはかならずチェックをつけましょう。あらかじめNVIDIA GPU driverをインストールしてくれます。
(6) price
ここでざっくりとした1ヶ月間ずっと立ち上げっぱなしにした際のコストが見れます。必ず確認しましょう!
これら以外に、ストレージのタイプ(SSDかそうでないか)なども決められます。コンペのデータの種類・量で決めましょう。(e.g. 画像データでメモリに載せきれない量ならSSDにしてIOを早くする、など)
一通り設定を終えたら、最後に一番下のDeployを押せばインスタンスが作成されます。(なぜかDeployment Managerのコンソールに飛ばされるので、Compute Engineのコンソールに戻って待機します。)
立ち上がったインスタンスへはsshで接続できますが、Cloud SDKをインストールしておけば以下のコマンドだけで鍵認証など気にせずにアカウントと紐付け手簡単に接続できます。
$ gcloud compute ssh --zone {インスタンスのゾーン} "{インスタンス名}"
また、インスタンス上で立ち上げたJupyter Notebookを直接手元で見ていじりたい!というときは、以下のようにしてport forwardingしましょう。
$ gcloud compute ssh --zone {インスタンスのゾーン} "{インスタンス名}" -- -N -f -L 28888:localhost:8888
これで手元のブラウザでlocalhost:28888へアクセスするとインスタンス上で立ち上がっているJupyterに繋がります。
さあ次は環境構築!なのですが、後々作成したdockerイメージをGCR(Google Container Registry)にpushできるようにするために、立ち上げたインスタンスを一度停止させてGCS(Google Cloud Storage)への読み書きの権限を付与しましょう。

コンソール上でインスタンス名をクリックするとインスタンスの詳細の画面に移ります。そこでEditタブを押して編集モードに入り、上の画像にあるように最後の方のStorageの項目のプルダウンでFullを選択してsaveします。これでGCSへの読み書きがこのインスタンスから直接できるようになりました。
ちなみに、このインスタンスの編集モードで、先ほどちょっと言及したインスタンス立ち上げ後のマシンスペックの調整もできます。試してみてください。
Dockerで環境構築
再びインスタンスを立ち上げ直して接続したら、いよいよ環境構築です!
通常なら直接インスタンス上でガシガシいろんなものをインストールしていくかと思うのですが、今回は後々別のインスタンスを立てたりした時などに同じ環境構築を繰り返さないように、Dockerで環境構築をして自動化できるようにしましょう!
さて、dockerで環境構築というと身構えてしまう人も多いかと思うのですが、具体的にやることはじつはこれだけです:
-
Dockerfileを書く(apt-getでライブラリ入れたりビルドしたりpip installしたり) -
docker buildして、Dockerfileに書いた手順通りの環境構築を自動で行なったdockerイメージを作る -
docker runでイメージからコンテナを起動する。docker execでそのコンテナ上で作業する
Dockerfileは普段シェル上で実行するコマンドをほぼそのまま貼り付ける形で書けるので、一度慣れてしまえば本当に簡単なんです。ということで、早速やっていきましょう!٩( 'ω' )و
Dockerfile を書く
Dockerfileに書いた処理でインストールされたライブラリや作成されたディレクトリ、設定された環境変数などは、そのままdockerイメージへと固定されます。逆に、Dockerfileに書かれておらず、コンテナを立ち上げた後でインストールされたものは docker commit をしない限りdockerイメージに反映されません。よって、このDockerfileは、
今後様々な状況で必ず使いまわすことになるものを明示的に設定する
ためにあると考えていいと思います。(例えば、Python、Anaconda、共通して用いる計算ライブラリ(numpy, pandas, scikit-learn、deep learningのフレームワーク、いちいちビルドするのがめんどくさいLightGBMなど)
逆に、ある特別な状況でのみ活躍するようなものは、コンテナを立ち上げた後で入れてもいいということです。ただ、何回も使う可能性が出てきたらDockerfileを修正してビルドしなおしましょう。
Dockerfileは、主に以下のようなフォーマットに従って書きます。
FROM {ベースイメージ}
ENV {ビルド時の環境変数}
ADD {ローカルのファイルパス} {そのファイルのコピー先になるdockerイメージ上のディレクトリ}
RUN {シェルコマンド}
この他にもARGでビルド時に引数を渡したり、USERで実行するユーザーを指定したりできるわけなんですが、今回はこの4つだけわかれば十分です。
何はともあれ例を見た方が早いと思うので、早速書いていきます。今回はGPUを使っているのでNvidiaのCUDAのイメージをベースに作成します。
FROM nvidia/cuda:10.0-cudnn7-devel-ubuntu16.04
# install basic dependencies
RUN apt-get update && apt-get upgrade -y && apt-get install -y --no-install-recommends \
sudo git wget cmake nano vim gcc g++ build-essential ca-certificates software-properties-common \
&& rm -rf /var/lib/apt/lists/*
# install python
RUN add-apt-repository ppa:deadsnakes/ppa \
&& apt-get update \
&& apt-get install -y python3.6 \
&& wget -O ./get-pip.py https://bootstrap.pypa.io/get-pip.py \
&& python3.6 ./get-pip.py \
&& ln -s /usr/bin/python3.6 /usr/local/bin/python3 \
&& ln -s /usr/bin/python3.6 /usr/local/bin/python
# install common python packages
ADD ./requirements.txt /tmp
RUN pip install pip setuptools -U && pip install -r /tmp/requirements.txt
# install pytorch
RUN pip install https://download.pytorch.org/whl/cu100/torch-1.0.0-cp36-cp36m-linux_x86_64.whl \
torchvision
# set working directory
WORKDIR /root/user
# config and clean up
RUN ldconfig \
&& apt-get clean \
&& apt-get autoremove
まず、最初のFROM句で参照するベースイメージですが、docker hubというところで検索すると色々と出てきます。Pythonで機械学習をするという人であれば、nvidia/cudaのイメージか、公式のpythonを覚えておけば十分でしょう。コロン以下はそのイメージの具体的なバージョンなどを示しています。今回はCUDA 10.0をインスタンス作成時にインストールしてもらっているので、それに合わせます。(注意:dockerでCUDAを使うときは、元のマシンに入っているCUDAと同じバージョンを入れないと動きません!)
次に、おなじみのapt-getでよく使うコマンドやビルドに必要なものなどを入れていきます。LightGBMなどをDockerfileでビルドしたいときは、そのdependenciesもここに書いておきます。
**nvidia/cudaのイメージにはPythonが入っていません。**ので、ここでバージョンまで指定して入れておきます。デフォルトでpipも入っていないのでそれも入れます。いちいちpython3.6と打つのはめんどうくさいので、シンボリックリンクを作ってpythonでpython 3.6が立ち上がるようにしてあります。
Dockerfileが実行される空間は今現在の空間とは異なり、基本的に空っぽです。なので、今手元にあるファイルでビルドに必要なものはあらかじめADD句を使って移しておきましょう。今回はpip installするライブラリ群をまとめたrequirements.txtだけ/tmp下にコピーしておきます。ここに記載できないものは別途RUN句でpip installすれば大丈夫です。今回はせっかく最新版がリリースされたばかりということで、PyTorchをインストールしています。ちなみに、だいたいよく使いそうなライブラリをまとめたrequirements.txtを置いておいたので参考に書き換えたり足していったりしてください。
pip==18.1
setuptools==39.1.0
wheel==0.30.0
jupyter==1.0.0
matplotlib==2.2.2
seaborn==0.8.1
scikit_learn==0.20.0
scipy==1.1.0
numpy==1.15.2
pandas==0.23.4
gensim==3.6.0
kaggle==1.4.7.1
あとはちょっとお掃除したりworking directoryを設定したりしているだけです。
Dockerfileのデバッグ
上に書いたDockerfile、最初から書いたものが一発で通ることはあまりなく、デバッグのためにはビルドし直さないといけないのか!不便だ!って思われるかもしれません。ここはたぶん始めてDockerfileを書く人がつまづきがちなところだと思うので、参考になるリンクをここに貼っておきます。
簡単にまとめると、「ベースイメージをまずはビルドして、そこで環境構築して、それで成功したコマンド群をDockerfileにまとめようぜ!」って感じです。上記のようなシンプルなDockerfileならまだいいですが、ちょっと複雑なことをいろいろやろうとすると必ずどこかで躓くので、逐次的に作成しましょう。
docker build してdockerイメージを作る
上に書いたDockerfileとrequirements.txtだけ同じディレクトリに置いておけば準備完了です!そのディレクトリ内で以下のコマンドを実行すればビルドが始まります。
$ docker build ./ -t {イメージ名}
-t以下にはイメージの名前を書きます。今回はkaggle_baseとでもしておきましょうか。
無事にビルドが完了したら、docker imagesでちゃんとビルドしたイメージができているか確認しましょう。
REPOSITORY TAG IMAGE ID CREATED SIZE
kaggle_base latest cfd528c7ac4d 10 seconds ago 5.99GB
docker run でコンテナを起動する
さて、環境構築済みのイメージができたので、そのイメージを元にコンテナを作成します。コンテナはdocker runで立ち上げることができ、同時に複数のコンテナを動かすことができます。
試しに、このコマンドを打ってコンテナをバックグラウンドで起動してみましょう。
$ $ mkdir project
$ $ docker run --runtime=nvidia -p 8888:8888 -d -v ~/project:/root/user/project --name test kaggle_base /sbin/init
-
--runtime=nvidianvidia-dockerで、dockerのコンテナ内でもGPUを使えるようにする大事なオプションです。 -
-p 8888:8888インスタンスのポート8888をコンテナのポート8888にマップしています。ポートフォワーディングでローカルPCからコンテナ上で走るJupyter Notebookなどにつなぐ際に必要になります。 -
-dコンテナをバックグラウンドで走らせるオプションです。 -
-v現在手元にあるディレクトリを、コンテナ上のディレクトリへとマウントします。 -
--name testコンテナの名前を指定します。今回はtestという名前にしました。これを入れないとランダムで面白い名前をつけられます。 -
kaggle_baseコンテナの元になるイメージの名前です。さっきビルドしたやつですね。 -
/sbin/initコンテナを立ち上げた際に実行されるプログラムです。これを実行しておくと後でdocker execで中に入って作業できます。ここをpythonのコマンドやjupyter notebook立ち上げコマンドに置き換えることもできます。
-vオプションは結構大事で、これを使うことでコンテナとホストでファイルのやりとりができるようになります。コンテナ上で走らせたプログラムで生成されたファイルをホスト側からも参照したり、追加のデータをホスト側に加えてコンテナ側から使うことができます。Kaggleをやる場合はコンペ用のディレクトリを作ると思うので、それを忘れずにマウントしましょう。
上のコマンドを実行して、docker container ls -aと打つと、以下のように表示されると思います。確かに立ち上がっているようですね!
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5246668f4817 kaggle_base "/sbin/init" 4 seconds ago Up 3 seconds 0.0.0.0:8888->8888/tcp test
docker exec でコンテナに入って作業する、コンテナ内でプログラムを実行する
先ほどdocker runで立ち上げたコンテナにdocker execで入って作業することができます。まずは以下のコマンドを実行してみてください。
$ docker exec -it test /bin/bash
これを行うと、コンテナ内に入って作業することができます。-itオプションはインタラクティブモードで実行するよ!ということで、コンテナ側での入出力がちゃんと手元に表示されるようになるものです。最後についている/bin/bashは立ち上がっているコンテナで実行したいコマンドで、ここをpython {スクリプト}.pyなどにするとそれが実行されます。
コンテナ内では、通常通りの作業ができます。試しにjupyter notebookを立ち上げて、ローカルPCからポートフォワードで繋いで、先ほどマウントしたprojectディレクトリ上で作業してみましょう。
$ cd project
$ mkdir code data
$ jupyter notebook --ip=0.0.0.0 --allow-root
$ gcloud compute ssh "kaggle-nlp-vm" -- -N -f -L 28888:localhost:8888
これで手元のPCのブラウザでlocalhost:28888へアクセスすると、インスタンス上のコンテナで立ち上がったjupyter notebookを見て編集することができるようになります。
(注意:jupyter notebookを立ち上げる際に見慣れないオプションがついていると思いますが、これが無いとコンテナ上でjupyter notebookを起動できないので、必ず付けてください。)
project/codeディレクトリ内でplayground.ipynbという適当なノートブックを作ってそこで作業し、中間ファイルをproject/dataへと吐き出してみます。
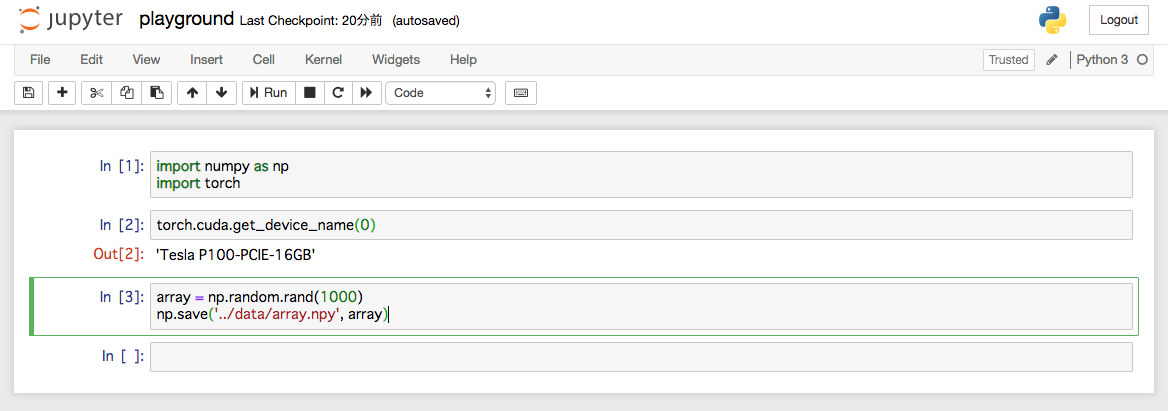
ついでにインストールしたPyTorchがコンテナ上でちゃんとGPUを使えるかの確認もしています。無事に使えそうですね!
ここで生成したproject/data/array.npyや作成したnotebookは、コンテナ内だけでなくちゃんとホスト側からも見てアクセスすることができます。
$ ls ~/project/code ~/project/data
project/code:
playground.ipynb
project/data:
array.npy
こんな感じでいつも通りの感覚でコンテナ上でも作業できるので、あとはガシガシコンペをやっていきましょう!
GCRにdockerイメージを登録して再利用できるようにする
GCPには、Google Container Registry(GCR)という、GCPのプロジェクト上で使い回すdockerイメージを登録できるサービスがあります。
先ほどビルドしたdockerイメージを登録しておけば、似たようなコンペを新たに始める場合や、コンペの終盤でインスタンスを複数立てて一気に実験して追い込む際に再利用できて便利です!
というわけで登録すればいいのですが、こんな感じで簡単に登録できます。
$ gcloud auth configure-docker # dockerをgcloudを介さず使うため、[Y/n]を聞かれるのでYを選択
$ docker tag kaggle_base gcr.io/{GCPのプロジェクトID}/kaggle_base
$ docker push gcr.io/{GCPのプロジェクトID}/kaggle_base
これで、以下のようにGCRにイメージを登録することができました!このイメージは同じGCPプロジェクト内で立ち上げるどのインスタンスからでも利用可能です。

新しく別のインスタンスを立ち上げた際は、
docker pull gcr.io/{GCPのプロジェクトID}/kaggle_base
で簡単にビルド済みのイメージを取ってくることができます。あとはこのイメージに対して上記のように docker run すれば同じように環境開発済みのコンテナで作業することができます!
まとめ
Kaggleに取り組む上で、適切なマシンスペックを整えたり、環境構築をスムーズに行えるのは大きなアドバンテージになります。
また、実務ではこういったクラウド上の計算資源をうまく使うこと、環境構築の自動化などはほぼ必須となってきています。
いずれも最初のラーニングコストは高い技術ではありますが、一度覚えてしまえば自転車のように便利に使いこなせるようなものなので、ぜひみなさんもGCPやdockerを活用してみてください!