機械学習を実際のプロダクションで使う時に大切な概念として serving というものがあります。以下、このservingの概要にさらっと触れ、つい最近しれっとリリースされたMS社製のOSS、ONNX Runtimeでのservingについてまとめたいと思います。

Servingとは?
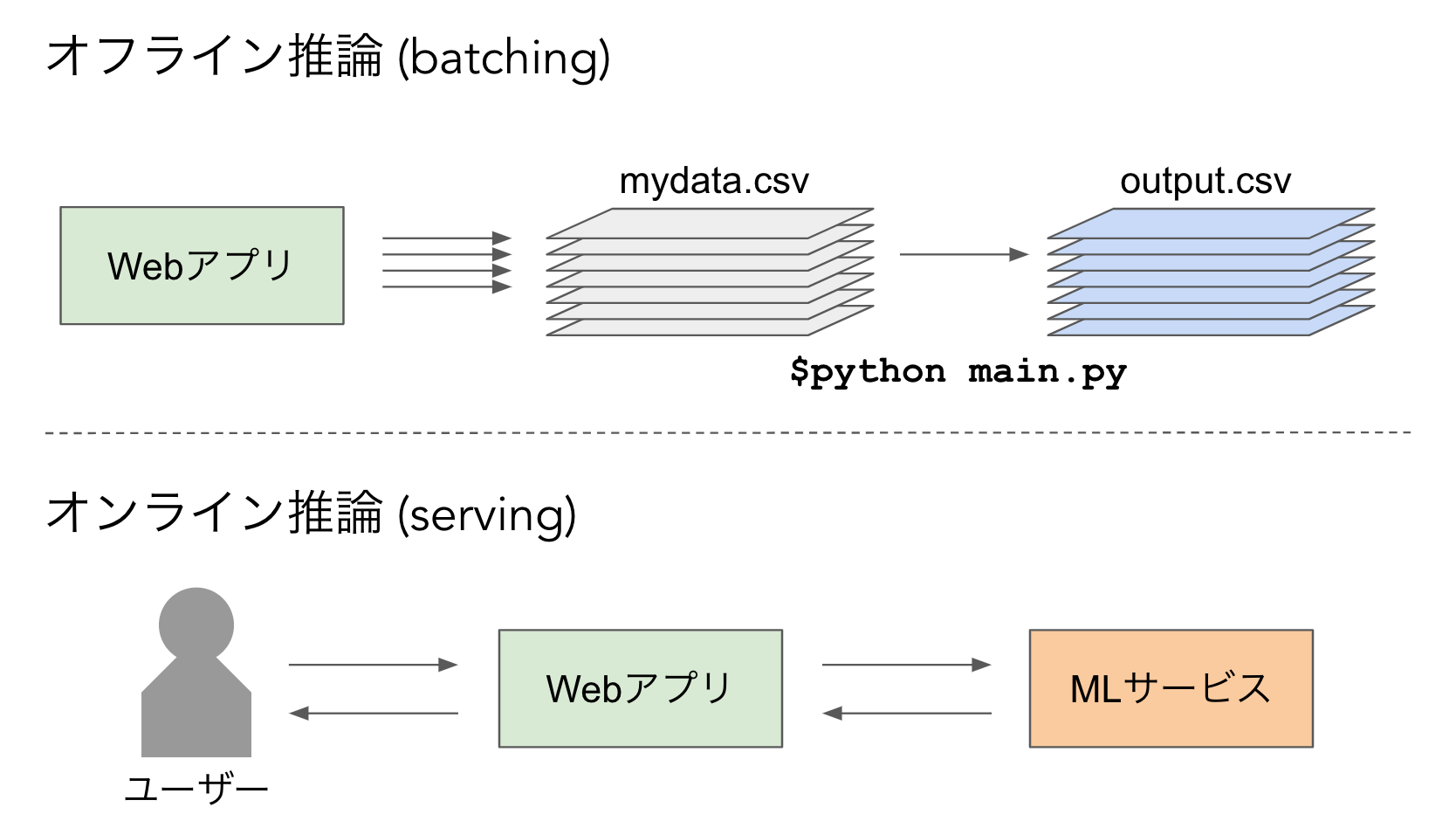
機械学習の実応用において、**推論(inference)**をコスパ良く行うことは、モデルの精度を高めることと同様に重要です。というのも、オフラインで実行するのならともかく、現在稼働しているWebサービスなどのシステム上でオンラインで実行する時は、モデルからのレスポンスの速さやその運用コストがサービスのボトルネックになることが多いからです。
学習済みのモデルをサービスとしてデプロイしてオンラインの推論APIを提供することを広くservingと呼びます。servingと対になるのはオフライン実行ですね。例えばデータの塊を持ってきて、 python main.py --data-path ./data/mydata.csv --save-path ./data/output.csv みたいに人がマニュアル実行するのがそれです。
それに対してservingは、オンラインで稼働してエンドポイントを用意しておき、 curl -X POST http://endpoint/predict -H 'Content-Type: application/json' -d @payload.json などのようにHTTPやgRPCのリクエストを送ることで推論結果を得られるようにしておきます。こうすることで、Webアプリなどから機械学習サービスにリアルタイムでアクセスできるようになります。
Servingの実装
servingを行う上でまず真っ先に思いつくのは、 REST APIを何らかの方法で立ててその中で推論を行う、というのがあると思います。PythonでFlaskなどを用いて実装することが多いのではないかと思います。この方法は簡単に実装できていいのですが、主に以下のようなデメリットがあります。
- Pythonの実行環境を用いているのでREST部分や推論部分がそもそも遅い
- モデルに応じて都度実装を書き換えないといけない
- モデルのバージョニング、ロールアウトが自動で行えない
これらの問題を解決するために、 TensorFlow Serving というservingに特化したTensorflowのAPIが存在しています。(Serving a TensorFlow Model)学習済みのTensorFlow(Kerasでも可)モデルの計算グラフを saved_model.pb というprotocol buffer形式にdumpし、それをC++で実装された実行環境に読み込ませることで高速なservingを実現します。HTTPとgRPCのサーバーもC++で実装されているため通信も高速で、高負荷時でもマシンリソースを効率よく使って低レイテンシなサービスを提供できます。(このTensorFlow Servingの性能についても近いうちにまとめたいです。)モデルのバージョニングもできるようになっています。
じゃあTensorFlow Servingを使えばいいじゃないか!となるかもしれませんが、いつだってTensorFlowのモデルを使いたいわけではないですよね。
- PyTorchやChainerで書いて作ったモデルもservingしたい
- そもそもservingしたいモデルがNeural Networkじゃない
ていうかTensorFlow 2.0がいつまで経っても出ないしAPIがめちゃめちゃだからもう使いたくない
といった状況は割と多いと思います。これまでは、そういったモデルをservingしようと思うと、自前で都度サーバーを書かなければいけませんでした。この問題に対して、 ONNX Runtime Server を使えば、ONNX形式に変換されたモデルならばTensorFlow Servingのようにservingすることができるようになって無事解決!ということで、このONNX Runtime Serverについて使い方も含めて紹介をしていきたいと思います。
ONNX Runtime Server
ONNX Runtime
ONNX Runtime Serverの説明に入る前に、まずONNX Runtimeとは何かを説明しないとですね。ONNX RuntimeとはONNX形式のモデルの実行環境(ランタイム)で、C、C#、Python、C++など、様々な言語環境下でONNX形式のモデルを実行できるようにAPIが実装されています。ChainerのMenohを想像してもらえればわかりやすいかもです。

例えばPythonのAPIは以下のようにして使います。
import numpy as np
import torch
from torchvision.models import densenet121
import onnxruntime
# モデルの作成
model = densenet121(pretrained=True, num_classes=1000) # 入力サイズ: (N, 3, 224, 224)
# ONNX形式で保存
x_dummy = torch.rand(input_size) # 入力サイズを合わせたダミーのtensorを作成
model_path = 'mymodel.onnx' # 保存先のパス
input_names = ['input_0'] # 入力層の名前
output_names = ['output_0'] # 出力層の名前
torch.onnx.export(model, x_dummy, model_path, export_params=True,
input_names=input_names, output_names=output_names)
# ONNX Runtimeでの推論
sess = onnxruntime.InferenceSession(model_path) # *.onnxの読み込み
input_array = np.random.rand(1, 3, 224, 224).astype(np.float32) # 保存時に用いたダミー入力と同じshape
outputs = sess.run(['output_0'], {'input_0': input_array})[0] # 保存時に指定した入力層と出力層の名前を用いる
ONNXでサポートされているOperationはほぼ全てカバーしているため、独自のモジュールを実装しない限り大体のケースで互換が効きます。PyTorchやChainerなどから簡単にONNX形式に変換でき、ランタイムの性能(推論速度)はなんとCaffe2よりも速いため、サーバーサイドでTensorFlow以外のニューラルネットワークモデルをservingするときのデファクトになってもいいんじゃないかなと個人的には思います。Microsoftすげえ。余談ですが、Microsoft社製ゆえにC#もサポートしてるので、Unityで学習済みモデルを読み出して画像処理とかさせることもできます。
ニューラルネットワーク以外のモデルについても、ONNXMLToolsというものを使えば、例えばscikit-learn形式のモデルなどもONNX形式に変換できるので同様にservingできます。
ONNX Runtime Server
こんな感じでONNX Runtimeはとてもいい感じなのですが、これまではあくまで自分でserving用のサーバーを実装しないといけませんでした。しかし、つい最近、ONNX Runtimer Serverがしれっと開発されてmaster pushされて使えるようになっていました。トップのドキュメントに書いとけよ! 一応ここに本当に簡潔にですが使い方が書いてあります。(2019/5/24時点)
Server APIのビルド
ONNX Runtime Serverを使うためには、まずONNX RuntimeをServerサポート付きでビルドしないといけません。このビルドが結構面倒臭くて、バージョンを合わせるためにCMakeをマニュアルインストールしたり、localeを適切に設定しておいたりしないとうまくいきません。とりあえず今この記事を書いている時点でちゃんとビルドできる(はずの)Dockerfileをここに置いておくので、みなさまもよかったらビルドしてみてください。ちなみに下記Dockerfileのビルド済みのイメージとして lain21/onnxruntime-server:0.4.0 を公開しておいたので、ビルドがめんどくさいっていう人はこれをとりあえず使ってみてください。
# Python > 3.5 is needed to build onnxruntime
FROM python:3.6.8
# Install dependencies and set locale properly
RUN apt-get update && apt-get install -y wget git libgomp1 locales locales-all
RUN locale-gen en_US.UTF-8
RUN update-locale LANG=en_US.UTF-8
# Install higher version cmake manually to build onnxruntime
ENV CMAKE_VERSION 3.14.4
RUN mkdir -p /src
WORKDIR src
RUN wget https://github.com/Kitware/CMake/releases/download/v${CMAKE_VERSION}/cmake-${CMAKE_VERSION}.tar.gz
RUN tar -xvzf cmake-${CMAKE_VERSION}.tar.gz && \
cd cmake-${CMAKE_VERSION} && \
./bootstrap && \
make -j$(nproc) && \
make install
# Build onnxruntime with server support
RUN git clone --recursive https://github.com/Microsoft/onnxruntime
WORKDIR onnxruntime
RUN ./build.sh --config RelWithDebInfo --build_server --use_openmp --parallel
# Make onnxruntime_server available via command line
RUN cp /src/onnxruntime/build/Linux/RelWithDebInfo/onnxruntime_server /usr/local/bin/
# REST
EXPOSE 8001
# Set where models should be stored in the container
ENV MODEL_BASE_PATH=/models
RUN mkdir -p ${MODEL_BASE_PATH}
ENV MODEL_PATH=model.onnx
ENV NUM_HTTP_THREADS=8
RUN echo '#!/bin/bash \n\n\
onnxruntime_server --http_port=8001 --num_http_threads=${NUM_HTTP_THREADS} \
--model_path=${MODEL_BASE_PATH}/${MODEL_PATH}' > /usr/bin/onnxruntime_serving_entrypoint.sh \
&& chmod +x /usr/bin/onnxruntime_serving_entrypoint.sh
ENTRYPOINT ["/usr/bin/onnxruntime_serving_entrypoint.sh"]
ビルドが無事完了すると、ビルドの出力が onnxruntime/build/Linux/RelWithDebInfo というディレクトリにまとめて入れられます。(Linuxの場合)このディレクトリに、 predict_pb2.py と onnx_ml_pb2.py というスクリプトも生成されています。これらのスクリプトはprotocol bufferからビルド時に自動で作成されたものなのですが、後々推論のリクエストをONNX Runtime Serverに送るときに必要になるものなので、自分のモジュール内にコピーしたりPYTHONPATHを通しておいてください。ビルドが面倒臭くてとりあえず使ってみたいという人は、私がビルドして作ったやつを下記に公開しておいたので、もしよければどうぞ。
使い方
ビルド後の実行ファイルも、上記の onnxruntime/build/Linux/RelWithDebInfo に onnxruntime_server という名前で入っています。忘れずにパスを通しておきましょう。下記のようにオプションとONNXモデルへのパスを指定して実行します。
$ onnxruntime_server \
--model_path=< *.onnx へのパス> \
--address=<HTTPアドレス(0.0.0.0がデフォルト)>
--http_port=<リクエストを受けるポート番号> \
--num_http_threads=<HTTPリクエストをさばく処理のスレッド数>
上記コマンドを実行してモデルの読み込みが成功すると、下記のようなログを残してサーバーが立ち上がります。
$ onnxruntime_server --model_path=/mymodel.onnx --http_port=8001 --num_http_threads=8
2019-05-24 13:08:39.156095221 [I:onnxruntime:ServerApp, main.cc:26 main] Model path: /mymodel.onnx
2019-05-24 13:08:39.244389885 [W:onnxruntime:ServerApp, graph.cc:2225 CleanUnusedInitializers] 725 exists in this graph's initializers but it is not used by any node
2019-05-24 13:08:39.244440752 [W:onnxruntime:ServerApp, graph.cc:2225 CleanUnusedInitializers] 719 exists in this graph's initializers but it is not used by any node
...
...
...
2019-05-24 13:08:39.303093092 [W:onnxruntime:InferenceSession, session_state_initializer.cc:417 SaveInputOutputNamesToNodeMapping] Graph input with name 719 is not associated with a node.
2019-05-24 13:08:39.303104595 [W:onnxruntime:InferenceSession, session_state_initializer.cc:417 SaveInputOutputNamesToNodeMapping] Graph input with name 725 is not associated with a node.
2019-05-24 13:08:39.303678809 [I:onnxruntime:InferenceSession, inference_session.cc:491 Initialize] Session successfully initialized.
2019-05-24 13:08:39.304003573 [I:onnxruntime:ServerApp, main.cc:50 operator()] Listening at: http://0.0.0.0:8001
立ち上がったサーバーの推論APIを使用するには、protocol bufferのメッセージをJSON形式かバイナリ形式で下記エンドポイントへ送ります。
http://<IPアドレス>:<ポート番号>/v1/models/<読み込んだ *.onnx の * 部分>/versions/1:predict
JSON形式で送る場合は Content-Type: application/json 、バイナリ形式で送る場合は Content-Type: application/octet-stream をリクエストのヘッダーにつける必要があります。
(*この記事の執筆時点(2019/5/24)ではまだHTTPサーバーしか実装されておらず、TensorFlow ServingのようにgRPCサーバーを使うことはできません。)
肝心のリクエストのメッセージはprotocol bufferとして用意する必要があります。先ほどの predict_pb2.py と onnx_ml_pb2.py を使うことで作成することができます。(バイナリ形式で送るときのみ)先ほどのONNX RuntimeのPython APIの使用例で作成した mymodel.onnx (DenseNet121)を読み込ませたサーバーへのリクエストとして、JSON形式のものとバイナリ形式のものの例を下記に載せておきます。
import requests
import base64
import numpy as np
from onnx import numpy_helper
from google.protobuf.json_format import MessageToJson
import predict_pb2, onnx_ml_pb2
ENDPOINT = 'http://localhost:8001/v1/models/mymodel/versions/1:predict'
json_request_headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
pb_request_headers = {
'Content-Type': 'application/octet-stream',
'Accept': 'application/octet-stream'
}
# JSON形式のリクエスト
input_array = np.random.rand(1, 3, 224, 224).astype(np.float32)
tensor_proto = numpy_helper.from_array(input_array) # ONNXのutility関数でTensorProtoを作成
json_str = MessageToJson(tensor_proto, use_integers_for_enums=True) # TensorProtoをJSON形式に変換
data = json.loads(json_str)
inputs = {}
inputs['input_0'] = data # 保存時に指定した入力層の名前
output_filters = ['output_0'] # 保存時に指定した出力層の名前
payload = {} # リクエストで送るペイロードの作成、 inputs と outputFilter のフィールドをそれぞれ埋める
payload["inputs"] = inputs
payload["outputFilter"] = output_filters
res = requests.post(ENDPOINT, headers=json_request_headers, data=json.dumps(payload))
raw_data = json.loads(res.text)['outputs']['output_0']['rawData'] # 生データを取得
outputs = np.frombuffer(base64.b64decode(raw_data), dtype=np.float32) # 生データはbase64でencodeされたバイナリ列なので適切にdecode
print(outputs.shape) # (1, 1000)
# バイナリ形式のリクエスト
input_array = np.random.rand(1, 3, 224, 224).astype(np.float32)
onnx_tensor_proto = numpy_helper.from_array(input_array) # ONNXのutility関数でTensorProtoを作成
tensor_proto = onnx_ml_pb2.TensorProto() # ビルド時に作成されたスクリプトからTensorProtoを作成、次で中身をコピー
tensor_proto.ParseFromString(onnx_tensor_proto.SerializeToString()) # 回りくどいが、実は生データで初期化する方がちょっと遅い
predict_request = predict_pb2.PredictRequest() # リクエスト用のprotocol buffer
predict_request.inputs['input_0'].CopyFrom(tensor_proto) # 保存時に指定した入力層の名前のフィールドへTensorProtoをコピー
predict_request.output_filter.append('output_0') # 保存時に指定した出力層の名前をoutput_filterに登録
payload = predict_request.SerializeToString() # リクエストとして送るためにstring型へdump
res = requests.post(ENDPOINT, headers=pb_request_headers, data=payload)
actual_result = predict_pb2.PredictResponse() # リクエストのレスポンス用のprotocol buffer
actual_result.ParseFromString(res.content)
outputs = np.frombuffer(actual_result.outputs['output_0'].raw_data, dtype=np.float32) # バイナリ列が入ってるのでdecode
print(outputs.shape) # (1, 1000)
JSONの処理とProtocol Bufferの処理では後者の方がはるかに早いので、実用上はバイナリ形式でのリクエストを用いることをお勧めします。
推論性能
ちょっと長くなりすぎてしまうので別記事で詳細は述べますが、簡潔にまとめると、
- TensorFlow Servingと遜色ない推論性能
- Inception系のモデル(広い分岐の多いモデル)でなければTensorFlow Servingよりかなり速い
- 高負荷時でもCPUを効率よく使い切るためレイテンシー増加がゆるやか(Python+RESTでは得られない性能)
となります。執筆時点ではモデルのバージョニング機能は残念ながら未実装ですが、実用に十分耐えうる性能だと思います。
まとめ
機械学習モデルのservingは、自分たちが提供するMLサービスに要求される性能に応じて柔軟に選択する必要があります。高負荷下において低レイテンシーが求められる状況においては高速なservingの実装はとても重要です。これまでは、それを実現できるOSSライブラリではTensorFlow Servingしか選択肢がありませんでした。(たぶん)そんな中で、様々なフレームワークで学習されたモデルを一貫したONNX形式に変換し、それを直接servingできるONNX Runtime Serverの登場は、個人的にはとても嬉しいニュースでした。当該OSSのGitHubプロジェクトは日々更新されていてなかなかまだ安定はしていませんが、精力的に開発が進められていることはわかるので、今後も注視していきたいと思います。
Appendix
MIMO(Multi-Input, Multi-Output)なモデル
シンプルな画像モデル以外の、より複雑な入出力を持ったモデルのONNX Runtime Serverでのservingについてここに追記しておきます。
モデルの作成、保存
まず、下記のような入出力のモデルを考えます。
入力
- テキスト(トークン列)
- 画像
出力
- 最終層一つ手前の特徴量
- 最終層の出力(確率値)
かなり適当ですが、下記のように実装して、ダミーの入力、入出力の名前とともに mimo_model.onnx として保存し、ONNX Runtime Servingに読み込ませます。
import numpy as np
import torch
import torch.nn as nn
from torchvision.models import resnet18
class MIMOModel(nn.Module):
def __init__(self, max_vocab=5000, seq_len=60):
super(MIMOModel, self).__init__()
self.embedding = nn.Embedding(max_vocab, 128)
self.conv_sequence = nn.Conv1d(128, 128, 3, padding=1)
self.pool_sequence = nn.AvgPool1d(seq_len)
self.image_forward = resnet18(pretrained=False, num_classes=128)
self.features = nn.Sequential(
nn.Linear(256, 128),
nn.ReLU()
)
self.output_layer = nn.Sequential(
nn.Linear(128, 1000),
nn.Softmax(dim=1)
)
def forward(self, input_text, input_image):
# Extract text features
x_text = self.embedding(input_text) # (batch_size, seq_len, hidden_dim)
x_text = torch.transpose(x_text, 2, 1) # (batch_size, hidden_dim, seq_len)
x_text = self.conv_sequence(x_text)
x_text = self.pool_sequence(x_text) # (batch_size, hidden_dim, 1)
text_features = x_text.view(-1, 128) # (batch_size, hidden_dim) *squeeze cannot be used!!
# Extract image features
image_features = self.image_forward(input_image)
# Concatenate features and feed into higher layer
concat_features = torch.cat((text_features, image_features), dim=1)
output_feature = self.features(concat_features) # (batch_size, 128)
output_proba = self.output_layer(output_feature) # (batch_size, 1000)
return output_feature, output_proba
model = MIMOModel()
x_dummy_text = torch.LongTensor(np.random.randint(0, 4999, 60).reshape(1, -1))
x_dummy_image = torch.FloatTensor(np.random.rand(1, 3, 224, 224).astype(np.float32))
input_names = ['input_text', 'input_image']
output_names = ['output_feature', 'output_proba']
torch.onnx.export(model,
(x_dummy_text, x_dummy_image),
'mimo_model.onnx',
export_params=True,
input_names=input_names,
output_names=output_names)
コードを見てもらえればわかると思いますが、 forward の引数の順番で input_names を指定して、それに対応するように torch.onnx.export のダミー入力にも同じ順番のタプルを入れて保存すればOKです。コメントにも書きましたが、 forward の途中でTensorのSizeを帰る際には squeeze や unsqueeze は使えないようなので気をつけてください。(saveはできるけど推論時にRuntimeErrorが出る)
リクエスト
特に複雑なことはなく、入力は型と次元を合わせたTensorProtoをそれぞれ作成して対応する名前でprotocol bufferに入れ、出力の名前もそれぞれ output_filter に追加して登録しておくだけです。下記のように書くことで推論を行うことができます。
import requests
import numpy as np
from onnx import numpy_helper
import predict_pb2, onnx_ml_pb2
ENDPOINT = 'http://localhost:8001/v1/models/mimo_model/versions/1:predict'
input_array_1 = np.random.randint(0, 4999, 60).astype(np.int64).reshape(1, -1)
input_array_2 = np.random.rand(1, 3, 224, 224).astype(np.float32)
onnx_tensor_proto_1 = numpy_helper.from_array(input_array_1)
onnx_tensor_proto_2 = numpy_helper.from_array(input_array_2)
tensor_proto_1 = onnx_ml_pb2.TensorProto()
tensor_proto_1.ParseFromString(onnx_tensor_proto_1.SerializeToString())
tensor_proto_2 = onnx_ml_pb2.TensorProto()
tensor_proto_2.ParseFromString(onnx_tensor_proto_2.SerializeToString())
predict_request = predict_pb2.PredictRequest()
predict_request.inputs['input_text'].CopyFrom(tensor_proto_1)
predict_request.inputs['input_image'].CopyFrom(tensor_proto_2)
predict_request.output_filter.append('output_feature')
predict_request.output_filter.append('output_proba')
data = predict_request.SerializeToString()
res = requests.post(ENDPOINT, headers=pb_request_headers, data=data)
actual_result = predict_pb2.PredictResponse()
actual_result.ParseFromString(res.content)
output_feature = np.frombuffer(actual_result.outputs['output_feature'].raw_data, dtype=np.float32)
output_proba = np.frombuffer(actual_result.outputs['output_proba'].raw_data, dtype=np.float32)
print('Output shape - output_feature: {}, output_proba: {}'.format(output_feature, output_proba))
# Output shape - output_feature: (128,), output_proba: (1000,)
SparseTensor を扱うレイヤーやRecurrentなレイヤーが入ったものについてはまだ未検証です。すいません。何か知見が得られたら共有していただけると嬉しいです!