はじめに
本記事では私が2019年にツイートしたDeep Learning関連の論文紹介の中から、インプレッションが高かったものを月ごとに取り上げて振り返っていきます。本記事は後編(7月〜12月)になります。前編はこちらをご覧ください。
7月
### タイトル Jeff Donahue and Karen Simonyan (DeepMind), "**Large Scale Adversarial Representation Learning**," NeurIPS2019. ### 手法概要BiGANとBigGANの組み合わせによる表現学習手法。BiGANにおけるdiscriminatorでは潜在変数と画像の組が入力となるが、提案手法では潜在変数あるいは画像のみを受け取るdiscriminatorを追加することで性能を向上。SOTAの一つである画像の回転量予測による表現学習と比べImageNetの識別性能を5%以上改善 https://t.co/Yc5oPRirRa
— Kazuyuki Miyazawa (@kzykmyzw) July 8, 2019
 BiGAN (bidirectional GAN) を使った表現学習において、BigGANを導入することで性能を改善したBigBiGANを提案。一般的なGANは潜在変数からデータを生成するgeneratorと、データのreal/fakeを見分けるdiscriminatorで構成されるが、BiGANではさらにencoderが追加されており、データから潜在変数へのマッピングを学習する。このencoderは特徴抽出器として有効であることが知られていたが、提案手法ではBiGANの原論文でGCGANベースだったgeneratorを多クラス画像生成のSoTAであるBigGANに置き換えることで性能改善を図っている。また、従来はdiscriminatorは潜在変数とそれに対応するデータとのペアを入力として受け取っていたが、提案手法ではこれに加えて潜在変数のみ、およびデータのみを受け取ってそれぞれにreal/fake判定のロスを適用している。
### 評価実験
BiGAN (bidirectional GAN) を使った表現学習において、BigGANを導入することで性能を改善したBigBiGANを提案。一般的なGANは潜在変数からデータを生成するgeneratorと、データのreal/fakeを見分けるdiscriminatorで構成されるが、BiGANではさらにencoderが追加されており、データから潜在変数へのマッピングを学習する。このencoderは特徴抽出器として有効であることが知られていたが、提案手法ではBiGANの原論文でGCGANベースだったgeneratorを多クラス画像生成のSoTAであるBigGANに置き換えることで性能改善を図っている。また、従来はdiscriminatorは潜在変数とそれに対応するデータとのペアを入力として受け取っていたが、提案手法ではこれに加えて潜在変数のみ、およびデータのみを受け取ってそれぞれにreal/fake判定のロスを適用している。
### 評価実験
 表現学習で獲得された特徴量に対し、線形識別器を適用することで得られる識別精度を表現学習の性能として評価。上図はImageNetを用いて従来手法との比較を行った結果である。encoderのアーキテクチャとしてはResNet-50およびその拡張を用いている。図中のRotationは、画像をある特定の角度に回転させ、その角度を推測するというpretraining手法として強力であることが知られているものだが、同アーキテクチャでの比較で55.4%から60.8%まで精度を改善している。
### 実装
著者らにより学習済みモデルがTensorFlow HubでColab notebookのデモと共に公開されている。
表現学習で獲得された特徴量に対し、線形識別器を適用することで得られる識別精度を表現学習の性能として評価。上図はImageNetを用いて従来手法との比較を行った結果である。encoderのアーキテクチャとしてはResNet-50およびその拡張を用いている。図中のRotationは、画像をある特定の角度に回転させ、その角度を推測するというpretraining手法として強力であることが知られているものだが、同アーキテクチャでの比較で55.4%から60.8%まで精度を改善している。
### 実装
著者らにより学習済みモデルがTensorFlow HubでColab notebookのデモと共に公開されている。
8月
### タイトル Ziteng Gao, Limin Wang, and Gangshan Wu (Nanjing University), "**LIP: Local Importance-based Pooling**," ICCV2019. ### 手法概要従来のpoolingは特徴マップの局所的な重要性を考慮していないことを指摘し、これを陽に表現するLocal Importance-based Poolingを提案。入力特徴マップに対して各特徴の重要度を出力する層を挿入し、得られた重要度に従ってpoolingを行う。MSCOCOでの物体検出において定常的に1.4%以上の性能向上を達成 https://t.co/uT3I6O2vFP
— Kazuyuki Miyazawa (@kzykmyzw) August 14, 2019
 CNNで一般的に用いられる様々なpooling手法をlocal importanceの観点から統一的なフレームワークで表現して課題を明らかにし、より効果的なpooling手法としてLocal Importance-based Pooling (LIP) を提案。上図は本論文が提案するLocal Aggregation and Normalization (LAN) と呼ばれるフレームワークであり、入力となる特徴マップ*I*をimportance map *F*(*I*)に基づいて集約し、正規化するという形で種々のpoolingを表現している。例えばaverage poolingでは*F*(*I*)=1、max poolingでは*F*(*I*)=exp(*βI*)で*β*を無限大にしていると考えることができる。本論文で提案するLIPでは、*F*(*I*)=exp(*g*(*I*))とし、*g*をFCN (Fully Convolutional Nets) とすることで入力に対して適応的にimportance mapを決定できるようにしている。このようにすることで、従来のようなヒューリスティックな基準によることなく、タスクに応じて最も識別性能が高い特徴を選ぶことが可能となる。
### 評価実験
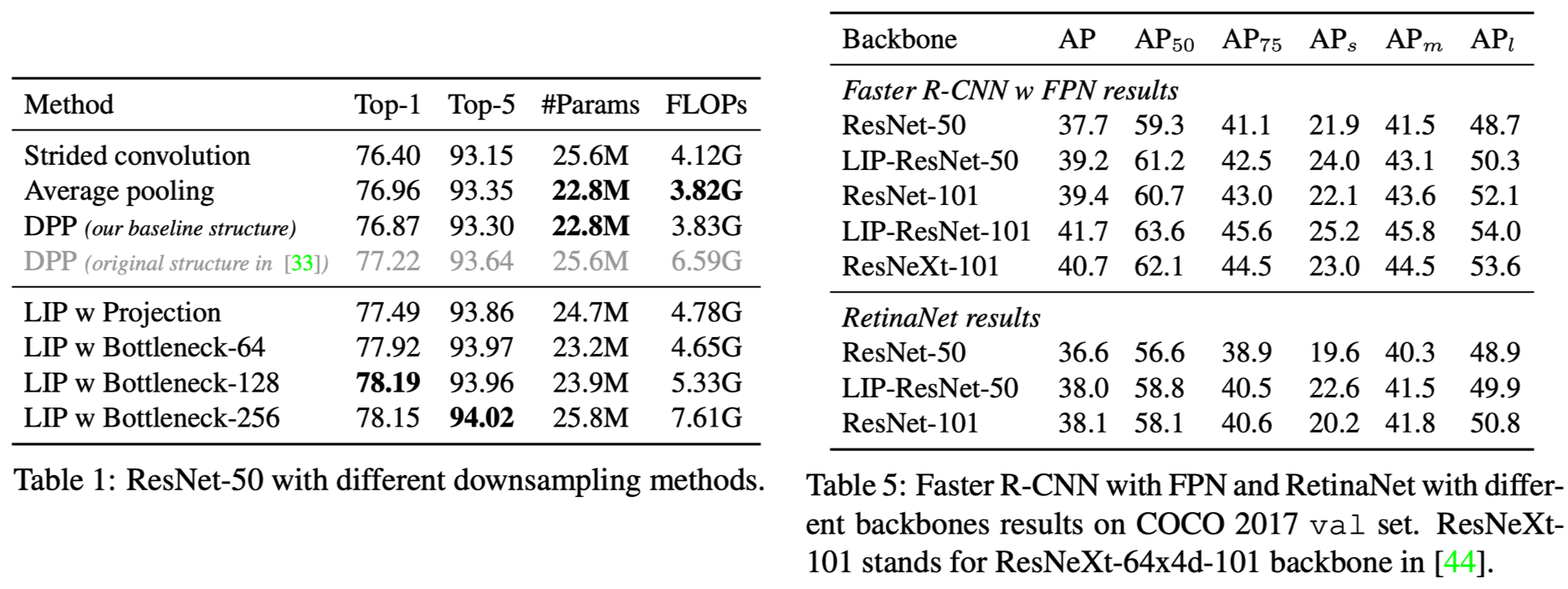
ImageNetにおけるクラス分類精度およびMS COCOでの物体検出精度を従来のpooling手法と比較。結果を上図左と右にそれぞれ示す。クラス分類ではベースアーキテクチャはResNet-50であり、図中のProjectionはLIPにおけるFCNを1x1 convolutionとしたもの、Bottleneck-xはresidual blockを設けたものである (xは入力チャネルの数)。結果を見るとLIPの利用によりベースラインから最低でもTop-1精度で0.5%以上の改善が得られていることがわかる。また、物体検出ではFaster R-CNN (w/ FPN) およびRetinaNetで比較を行っているが、上図右からわかるようにやはりLIPの導入によりベースラインから性能改善が得られている。
### 実装
著者による実装が公開されている。
CNNで一般的に用いられる様々なpooling手法をlocal importanceの観点から統一的なフレームワークで表現して課題を明らかにし、より効果的なpooling手法としてLocal Importance-based Pooling (LIP) を提案。上図は本論文が提案するLocal Aggregation and Normalization (LAN) と呼ばれるフレームワークであり、入力となる特徴マップ*I*をimportance map *F*(*I*)に基づいて集約し、正規化するという形で種々のpoolingを表現している。例えばaverage poolingでは*F*(*I*)=1、max poolingでは*F*(*I*)=exp(*βI*)で*β*を無限大にしていると考えることができる。本論文で提案するLIPでは、*F*(*I*)=exp(*g*(*I*))とし、*g*をFCN (Fully Convolutional Nets) とすることで入力に対して適応的にimportance mapを決定できるようにしている。このようにすることで、従来のようなヒューリスティックな基準によることなく、タスクに応じて最も識別性能が高い特徴を選ぶことが可能となる。
### 評価実験

ImageNetにおけるクラス分類精度およびMS COCOでの物体検出精度を従来のpooling手法と比較。結果を上図左と右にそれぞれ示す。クラス分類ではベースアーキテクチャはResNet-50であり、図中のProjectionはLIPにおけるFCNを1x1 convolutionとしたもの、Bottleneck-xはresidual blockを設けたものである (xは入力チャネルの数)。結果を見るとLIPの利用によりベースラインから最低でもTop-1精度で0.5%以上の改善が得られていることがわかる。また、物体検出ではFaster R-CNN (w/ FPN) およびRetinaNetで比較を行っているが、上図右からわかるようにやはりLIPの導入によりベースラインから性能改善が得られている。
### 実装
著者による実装が公開されている。
9月
### タイトル Qi Qian, Lei Shang, Baigui Sun, Juhua Hu, Hao Li, and Rong Jin (Alibaba, University of Washington), "**SoftTriple Loss: Deep Metric Learning Without Triplet Sampling**," ICCV2019. ### 手法概要  距離学習では一般的にtripletサンプリングが必要となるが、これが不要なsoftmax lossであってもtriplet lossの特殊ケースとみなせることを示し、その拡張としてSoftTriplet lossを提案。最後のFC層における各クラスの中心が一つであるとすると、softmax lossから導出できるtriplet制約は入力サンプル、所属クラスの中心、および他クラスの中心との間で定義することができる。しかし、上図左のように各クラスで中心が一つしか存在しないという制約は実データにおけるクラス内のバリエーションを考えると非現実的であるため、これを拡張して複数中心の存在を仮定したSoftTriplet lossを提案。上図右のように、FC層から得られる特徴ベクトルの次元を各クラスに存在する中心の個数に応じて拡張したうえでsoftmaxを適用する。各クラスの中心の個数についてはあらかじめ決定することが困難であるため、最初に十分大きな個数を与え、距離が近い中心については統合していくことで最適な個数を求めるというアプロチーチをとっている。 ### 評価実験  CUB-2011、Cars196、SOPの3データセットにおいてInceptionをbackboneとしたfine-grainedクラス分類で性能を評価。上図はCUB-2011における結果である。左は特徴の埋め込み次元を64とした場合であるが、単純にsoftmaxを用いるだけでも従来手法よりも高い性能が得られており、さらに提案手法であるSoftTripleにより従来手法から10%近く性能が改善している。また、上図右は埋め込み次元を512まで大きくした場合の結果であるが、こちらでもSoftTripleが最も高い性能を示している。 ### 実装 著者によるものか不明であるが、いくつか実装が公開されている。距離学習におけるtripleロスの最小化は、各クラスのクラスタ中心が一つである場合のsoftmaxロスの最小化に等しいことを証明。さらにクラス内分布の多様性に対応するためクラスタ中心が複数存在する場合に拡張したSoftTripleロスを提案。tripletのサンプリングが不要で、クラスタ中心の数も自動的に決定 https://t.co/YJiVrpSAFr
— Kazuyuki Miyazawa (@kzykmyzw) September 13, 2019
10月
### タイトル Guohao Li, Matthias Müller, Guocheng Qian, Itzel C. Delgadillo, Abdulellah Abualshour, Ali Thabet, and Bernard Ghanem (KAUST), "**DeepGCNs: Making GCNs Go as Deep as CNNs**," ICCV2019[^1]. [^1]: 正確には本論文はICCVに採録された[論文](https://arxiv.org/abs/1904.03751)のextended version(ジャーナル査読中)である。 ### 手法概要勾配消失の問題があるため従来2〜4層程度であったGCNにCNNにおけるresidual/dense接続の概念を取り入れ、100層以上での学習を実現。3次元点群のセグメンテーションではPointNet等を上回る性能を達成し、PPIを使ったグラフノードの分類でもCluster-GCNをわずかに上回っている https://t.co/2yQyt9CPWy
— Kazuyuki Miyazawa (@kzykmyzw) October 17, 2019

CNN同様、GCN (Graph Convolutional Nets) においても層を増やしていくと勾配消失などの問題が発生するが、深いGCNをうまく学習させる方法はこれまで提案されておらず、GCNの総数は一般的に4層以下にとどまっていた。本論文では、CNNの総数を増やすことに大きく貢献したResNetにおけるresidual接続、およびResNetから層間の接続をさらに増やしたDenseNetにおけるdense接続をGCNに導入することで、GCNの総数を最大112層まで増やすことに成功している。また、総数を増やすとpoolingの反復によって空間方向の情報が失われるという問題への解決策の一つとしてCNNで使われているdilated convolutionについてもGCNへ導入している。
評価実験
 3次元点群のセグメンテーション、およびグラフデータのノード分類をタスクとして性能を評価。上図はS3DISを使った3次元点群のセグメンテーションにおいて総数を増やしていったときにresidual接続の有無で性能がどのように変化するかを調査した結果である。residual接続を持たないPlainGCNは総数を増やしていくと性能が大きく落ちていくのに対し、residual接続を持つResGCNは安定的に性能が向上していくことがわかる。
3次元点群のセグメンテーション、およびグラフデータのノード分類をタスクとして性能を評価。上図はS3DISを使った3次元点群のセグメンテーションにおいて総数を増やしていったときにresidual接続の有無で性能がどのように変化するかを調査した結果である。residual接続を持たないPlainGCNは総数を増やしていくと性能が大きく落ちていくのに対し、residual接続を持つResGCNは安定的に性能が向上していくことがわかる。
 また上図は、S3DISにおける3次元点群セグメンテーションの性能を28層のResGCNと他手法とでカテゴリごとに比較したものであるが、ResGCNが多くのカテゴリで最も高い性能を示していることがわかる。
また上図は、S3DISにおける3次元点群セグメンテーションの性能を28層のResGCNと他手法とでカテゴリごとに比較したものであるが、ResGCNが多くのカテゴリで最も高い性能を示していることがわかる。
 その他、グラフデータにおけるノード分類ではPPIと呼ばれるデータセットを用いて従来手法との比較を行っているが、上図に示す通りこちらでも提案手法が最も高い性能を示している。
### 実装
著者らによる実装がPyTorchとTensorFlowのそれぞれで公開されている。
その他、グラフデータにおけるノード分類ではPPIと呼ばれるデータセットを用いて従来手法との比較を行っているが、上図に示す通りこちらでも提案手法が最も高い性能を示している。
### 実装
著者らによる実装がPyTorchとTensorFlowのそれぞれで公開されている。
- [lightaime/deep_gcns_torch] (https://github.com/lightaime/deep_gcns_torch)
- [lightaime/deep_gcns] (https://github.com/lightaime/deep_gcns)
11月
### タイトル Cihang Xie, Mingxing Tan, Boqing Gong, Jiang Wang, Alan Yuille, and Quoc V. Le (Google, Johns Hopkins University), "**Adversarial Examples Improve Image Recognition**," arXiv, 2019. ### 手法概要敵対的サンプルの学習で性能を向上させるAdvPropを提案。敵対的サンプルは通常と分布が異なるため、BNが共通だと適切に学習できない。そこで、学習時に通常サンプルと敵対的サンプルでBNを分離。モデルサイズが大きいほど効果も大きく、EfficientNet-B7をさらに大きくしたB8でImageNet 85.5%を達成 https://t.co/gcX18cehcT
— Kazuyuki Miyazawa (@kzykmyzw) November 25, 2019
 敵対的サンプルを学習データに加えることでオーバーフィッティングを回避するAdvPropを提案。敵対的サンプルをモデルの性能向上のために用いるというアプローチはいくつか提案されていたが、効果は限定的でMNISTなどの小規模データセットにとどまっており、ImageNetなどの大規模データセットの場合は通常の画像に対して逆に性能が落ちることが知られていた。本論文では、その原因が通常サンプルと敵対的サンプルとでデータ分布が異なるためであると仮定し、両データでbatch normalization (BN) を分離することを提案している。つまり、上図 (b) のように通常のBNとAuxiliary BNの2ブランチを用意し、ミニバッチが通常サンプルか敵対的サンプルかに応じて通過するブランチを切り替えながら学習する。推論時にはAuxiliary BNを削除し、通常のBNのみを用いる。
### 評価実験
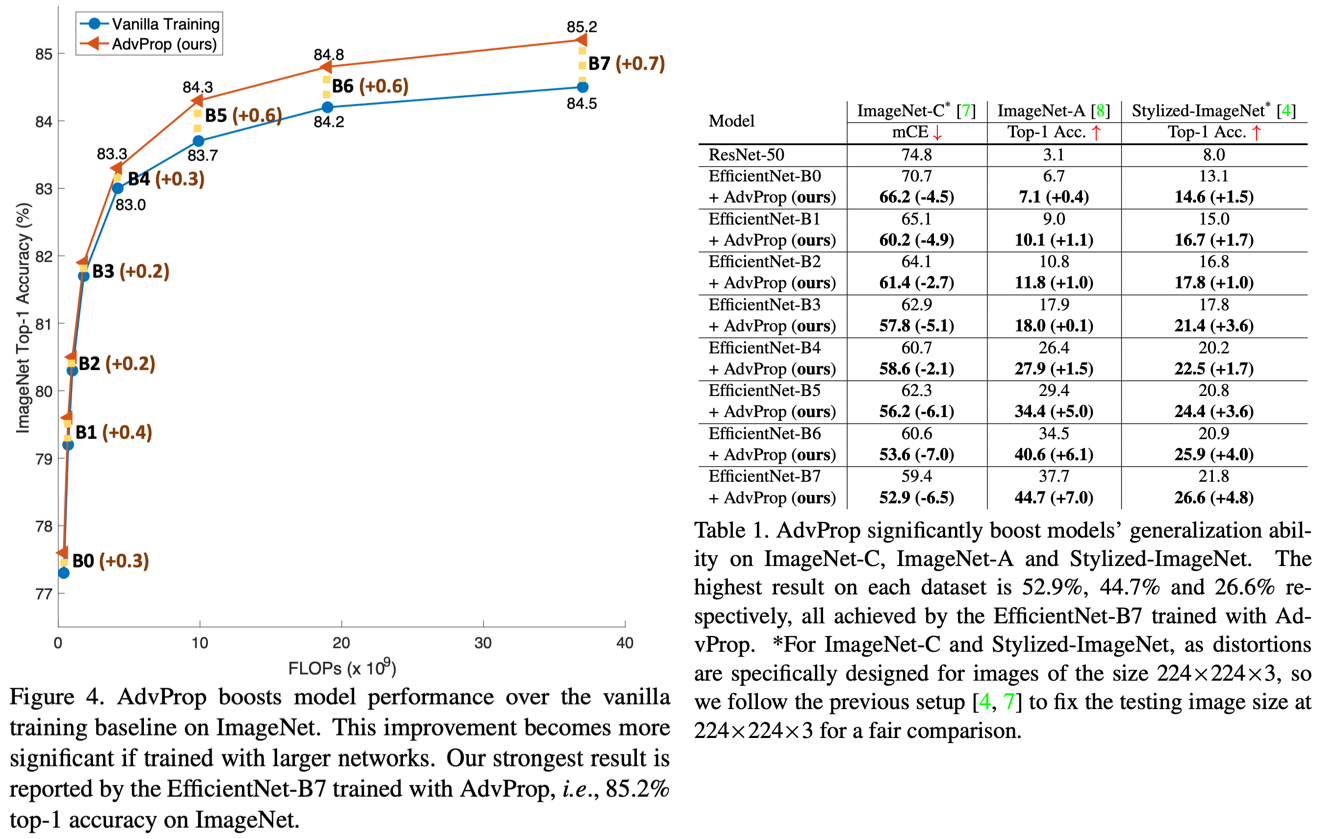
EfficientNetの様々なサイズに対してImageNetによるクラス分類の性能を評価。上図左はモデルサイズごとにAdvPropの利用でどれだけ性能が向上するかを示したものであり、モデルサイズが大きい方が向上幅が大きいことがわかる。また上図右は汎化性能を調べるため、distortionやstylizationを加えてImageNetの難易度を上げたバージョンであるImageNet-C、ImageNet-A、Stylized-ImageNetで性能を評価した結果である。こちらでもAdvPropの利用により性能が向上しており、特にEfficientNet-B7の性能(ImageNet-C: 52.9%、ImageNet-A: 44.7%、Stylized-ImageNet: 26.6%)は論文公開時点で世界最高である。
### 実装
EfficientNetのリポジトリにてAdvPropで学習したcheckpointが公開されている。
敵対的サンプルを学習データに加えることでオーバーフィッティングを回避するAdvPropを提案。敵対的サンプルをモデルの性能向上のために用いるというアプローチはいくつか提案されていたが、効果は限定的でMNISTなどの小規模データセットにとどまっており、ImageNetなどの大規模データセットの場合は通常の画像に対して逆に性能が落ちることが知られていた。本論文では、その原因が通常サンプルと敵対的サンプルとでデータ分布が異なるためであると仮定し、両データでbatch normalization (BN) を分離することを提案している。つまり、上図 (b) のように通常のBNとAuxiliary BNの2ブランチを用意し、ミニバッチが通常サンプルか敵対的サンプルかに応じて通過するブランチを切り替えながら学習する。推論時にはAuxiliary BNを削除し、通常のBNのみを用いる。
### 評価実験

EfficientNetの様々なサイズに対してImageNetによるクラス分類の性能を評価。上図左はモデルサイズごとにAdvPropの利用でどれだけ性能が向上するかを示したものであり、モデルサイズが大きい方が向上幅が大きいことがわかる。また上図右は汎化性能を調べるため、distortionやstylizationを加えてImageNetの難易度を上げたバージョンであるImageNet-C、ImageNet-A、Stylized-ImageNetで性能を評価した結果である。こちらでもAdvPropの利用により性能が向上しており、特にEfficientNet-B7の性能(ImageNet-C: 52.9%、ImageNet-A: 44.7%、Stylized-ImageNet: 26.6%)は論文公開時点で世界最高である。
### 実装
EfficientNetのリポジトリにてAdvPropで学習したcheckpointが公開されている。
12月
### タイトル Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick (FAIR), "**PointRend: Image Segmentation as Rendering**," arXiv, 2019. ### 手法概要  領域に応じてサンプリング密度を変えることで品質を落とさずに計算効率を上げるCGのレンダリングに倣い、インスタンス/セマンティックセグメンテーションにおいて物体境界の精度を向上させるPointRend (Point-based Rendering) を提案。従来手法では一般的に解像度を落とした特徴マップ上でセグメンテーションが行われるため、周波数の高い物体境界は正しく表現できない。これに対しPointRendでは、上図左に示すようにまず低い解像度の特徴マップで粗いセグメンテーションを行った後、必要な画素においてのみ高解像度な特徴マップを参照して再度推論を行う。これを繰り返すことで、演算量の増加を抑えつつ物体境界の精度を改善することができる。具体的にはadaptive subdivisionと呼ばれるCGにおける古典的手法を用いており、上図右に示すように最初に例えば4x4の特徴マップ上でセグメンテーションを行い、これを8x8に補間拡大したうえでconfidenceの低い点だけを選んで推論をやり直すことでわずかな点の再計算のみで解像度を向上させている。 ### 評価実験  ベースラインとしてMask R-CNNを利用し、COCOおよびCityscapesを用いてインスタンスセグメンテーションおよびセマンティックセグメンテーションの性能を評価。上図左の評価結果において、4x convがデフォルトのMask R-CNNであるが、PointRendの利用により性能が向上していることがわかる。上図右はPointRendの計算効率の高さを示したものであるが、例えば224x224の高解像度な推論を行う場合、PointRendは通常の一様サンプリングに比べて演算量を1/30以下に抑えることができる。CGにおけるレンダリング効率化の仕組みをセグメンテーションに応用。従来セグメンテーションに使われていた粗い特徴マップから適応的に点を選択し、その点についてのみ高解像度な特徴マップを参照して解像度を上げる。これを所望の解像度に達するまで繰り返すことで低演算量で物体境界の分離精度を改善 https://t.co/15Ck4XmUAT pic.twitter.com/gMmhzpuh4N
— Kazuyuki Miyazawa (@kzykmyzw) December 18, 2019
 また上図はいくつかのサンプルについて通常のMask R-CNNとPointRendのセグメンテーション結果を比較したものであるが、PointRendの方が物体境界を高精度に表現できていることがわかる。
### 実装
第三者による実装が公開されている。
また上図はいくつかのサンプルについて通常のMask R-CNNとPointRendのセグメンテーション結果を比較したものであるが、PointRendの方が物体境界を高精度に表現できていることがわかる。
### 実装
第三者による実装が公開されている。
また、detectron2のissueにて、1ヶ月以内に公開するとのコメントが12月末に投稿されている。
おわりに
前編と合わせて2019年のDeep Learning系論文(ほぼCV)11本の論文を振り返りました。私がそういう論文を選んでいるというのもありますが、基本的にはトップカンファレンスの論文が多いですね。また、おかげ様で少しずつフォロワー数が増えているせいか、後半の方があぁやっぱこれだよね、みたいな論文が選ばれているように思います(気のせいかも)。というわけでどしどしフォローをよろしくお願いします〜。2019年の振り返りと言っておきながら2020年になってしまったわけですが、特に他に良い方法も思いつかないので今年も引き続きarXivチェックを続けていきます!が、もう少しがっつり細部まで読み込む論文の数を増やしたいですね。やはりさらっと流して終わりだと理解も記憶も不十分なので… 2020年は浅くと深くを意識的に使い分けて論文フォローをやっていきたいと思います。
おまけ
2019年のインプレッション1位はインプレッション26,286のこちらの論文でした!従来がせいぜい4層だったのを一気に100層以上ということでインパクト大きかったんですかね〜 ちなみに私はグラフなにもわからない
勾配消失の問題があるため従来2〜4層程度であったGCNにCNNにおけるresidual/dense接続の概念を取り入れ、100層以上での学習を実現。3次元点群のセグメンテーションではPointNet等を上回る性能を達成し、PPIを使ったグラフノードの分類でもCluster-GCNをわずかに上回っている https://t.co/2yQyt9CPWy
— Kazuyuki Miyazawa (@kzykmyzw) October 17, 2019