はじめに
みなさんどうやってDeep Learningの最新論文をフォローしているでしょうか。私は特に工夫することもなくarXivをチェックする毎日です。基本的に自分の専門分野であるコンピュータビジョンに関連するComputer Vision and Pattern Recognitionの新着だけを見ています。大体1日に50〜100件くらいの新規投稿があります。タイトルと著者(の所属)とアブストラクトをざっと見て、気になったものはもうちょっと読みます。で、たまにその紹介をツイートします。
さて、2019年も終わりということで、ツイートした論文紹介からピックアップして補足する形で2019年のDeep Learning論文の振り返りをしてみようと思います。ピックアップにはTwitter公式のアナリティクスを使いました。といっても単に各ツイートのインプレッション1を取得し、インプレッションが高かった論文紹介ツイートを選んだだけです。アナリティクスでは他にもエンゲージメント2などの数値も取れますが、今回はあまり考えずにインプレッションを使いました。当然ながらフォロワー数が増えるほどインプレッションも大きくなりやすいはずなので、本当は何らか正規化したうえで1年分の上から順に見るべきなのですが、面倒なので月ごとにインプレッションをソートして見ていくことにしました。まぁ1ヶ月の間ではそんなにフォロワー数も変わらんだろうということで。本記事は前編で、2月から6月までを振り返ります。2月始まりなのは、単に私が論文紹介をツイートし始めたのが2月頃だからです。それでは順に振り返っていきましょう。
後編はこちら
2月
### タイトル Bin Yang, Wenjie Luo, and Raquel Urtasun (Uber Advanced Technologies Group, University of Toronto), "**PIXOR: Real-time 3D Object Detection from Point Clouds**," CVPR2018. ### 手法概要  リアルタイムにLiDAR点群からの物体検出を行うPIXOR (**OR**iented 3D object detection from **PIX**el-wise neural network predictions) を提案。まず、3次元点群を鳥瞰図 (BEV) に変換することで2次元化し、データ量を削減。ただし、高さ方向にスライスする形で複数のBEVを作ることで高さ情報が完全に失われることを防ぐ。これら複数のBEVを多チャネル画像とみなしてCNNに入力し、BEV上で物体の位置と向きを検出する。ネットワーク構成は大きくbackboneとheaderに分けられ、backboneではFPN (Feature Pyramid Nets) のようなtop-downブランチを採用している。headerはclassificationとregressionのマルチタスクで、各画素に対して物体クラスと、bounding boxのパラメータを出力する。bounding boxのパラメータは、当該画素からbox中心までの距離 (2次元)、boxの傾き角度 (cosとsinで2次元)、幅 (1次元)、高さ (1次元) の合計6次元である。ロスはclassificationに対してはcross-entropy (class imbalanceに対応するためfocal lossを採用)、regressionに対してはsmooth L1を用いている。推論時には各画素に対して得られる出力のうちconfidenceが閾値以上のものだけを採用し、NMSを行なって最終的な検出結果を得る。 ### 評価実験  KITTIにおけるBEV Object Detection Benchmarkにより性能を評価。比較対象とした従来手法はVeloFCN、3D FCN、MV3Dであり、上図はKITTI公式の評価尺度に加えてIoUの閾値を0.7とした独自尺度でのAPを示したものである。この結果を見ると、特にIoU閾値0.7、距離レンジ70mにおいてPIXORは他手法を大きく上回る性能を達成しており、2位と比べても9%の精度向上が得られている。また、処理時間も従来手法と比べて大幅に小さく、28 fps以上での検出が可能である。 ### 実装 著者らによる実装は見当たらないが、第三者による実装が公開されている。3次元点群からの物体認識。点群を2次元の鳥観図に変換してからFPNライクなネットワークに入力。最後はConfidenceとLocalizationの2出力構成。KITTIでMV3Dを精度、速度で上回る。[1902.06326] PIXOR: Real-time 3D Object Detection from Point Clouds https://t.co/ethnDtrQsp
— Kazuyuki Miyazawa (@kzykmyzw) February 19, 2019
3月
### タイトル Yifan Liu, Changyong Shu, Jingdong Wang, and Chunhua Shen (The University of Adelaide, Nanjing Institute of Advanced Artificial Intelligence, Microsoft Research), "**Structured Knowledge Distillation for Dense Prediction**," CVPR2019. ### 手法概要Semantic segmentationにおけるDistillation手法。最終出力を画素単位で一致させる一般的なロスに加え、中間層での特徴マップを一致させるロス、さらにTeacherとStudentのどちらが出した答えなのかを当てるDiscriminatorのロスを導入。提案手法の利用により性能が5%以上向上。CVPR19 https://t.co/YfoeOTaZlU
— Kazuyuki Miyazawa (@kzykmyzw) March 14, 2019
 semantic segmentationなど、画素単位での密なpredictionが必要なタスクに特化したdistillation手法を提案。従来手法は画像分類におけるdistillation手法をそのまま踏襲しているため画素単位に独立した処理となっているのに対し、提案手法では画像全体の構造を考慮してdistillationを行う。提案手法はpair-wise distillationとholistic distillationに分けられ、pair-wise distillationでは教師ネットワークと生徒ネットワークの特徴マップを一致させるようなロスを用いている。具体的には、特徴マップにおいて各ノードが空間位置、ノード間のつながりが特徴の類似性を表すようなグラフを構築し、両ネットワークの特徴マップから得られるこれらのグラフの差異をロスとして定義している。一方、holistic ditillationではGANの枠組みを導入しており、教師ネットワークの推論結果をreal、生徒ネットワークの推論結果をfakeとみなして両者を識別するdiscriminatorからのロスを利用している。
### 評価実験
semantic segmentationなど、画素単位での密なpredictionが必要なタスクに特化したdistillation手法を提案。従来手法は画像分類におけるdistillation手法をそのまま踏襲しているため画素単位に独立した処理となっているのに対し、提案手法では画像全体の構造を考慮してdistillationを行う。提案手法はpair-wise distillationとholistic distillationに分けられ、pair-wise distillationでは教師ネットワークと生徒ネットワークの特徴マップを一致させるようなロスを用いている。具体的には、特徴マップにおいて各ノードが空間位置、ノード間のつながりが特徴の類似性を表すようなグラフを構築し、両ネットワークの特徴マップから得られるこれらのグラフの差異をロスとして定義している。一方、holistic ditillationではGANの枠組みを導入しており、教師ネットワークの推論結果をreal、生徒ネットワークの推論結果をfakeとみなして両者を識別するdiscriminatorからのロスを利用している。
### 評価実験
 semantic segmentation、depth estimation、object detectionの3タスクで性能を評価。上図はCityscapesを用いたsemantic segmentationにおいて、教師ネットワークをPSPNet (w/ ResNet101)、生徒ネットワークをESPNet-C、ESPNet、ResNet18、MobileNetV2Plusとした場合にスクラッチでの学習と提案手法によるdistillationとを比較した結果である。いずれもスクラッチでの学習よりも提案手法によるdistillationの方が高性能となっており、ESPNet-CやResNet18では6〜7%の性能向上を達成している。また、表中のMDは従来手法であり、用いている生徒ネットワークはMobileNetであるが、提案手法において類似条件となるMobileNetV2Plusへのdistillationはより高い性能を示している。
### 実装
著者らによる実装が公開されている。
semantic segmentation、depth estimation、object detectionの3タスクで性能を評価。上図はCityscapesを用いたsemantic segmentationにおいて、教師ネットワークをPSPNet (w/ ResNet101)、生徒ネットワークをESPNet-C、ESPNet、ResNet18、MobileNetV2Plusとした場合にスクラッチでの学習と提案手法によるdistillationとを比較した結果である。いずれもスクラッチでの学習よりも提案手法によるdistillationの方が高性能となっており、ESPNet-CやResNet18では6〜7%の性能向上を達成している。また、表中のMDは従来手法であり、用いている生徒ネットワークはMobileNetであるが、提案手法において類似条件となるMobileNetV2Plusへのdistillationはより高い性能を示している。
### 実装
著者らによる実装が公開されている。
4月
### タイトル Chen Wang, Jianfei Yang, Lihua Xie, and Junsong Yuan (Nanyang Technological University, State University of New York), "**Kervolutional Neural Networks**," CVPR2019. ### 手法概要kernel trickによりconvolutionを非線形化したkervolution (kernel convolution) を使ったKNN (Kervolutional Neural Nets) を提案。重み共有や位置ずれ不変といったconvolutionの利点は残しつつ表現能力を向上。非線形化により、活性化関数をなくしても性能が落ちない。ResNet18のCNNを置き換えた場合、ImageNetでの性能向上は1%弱。CVPR19 https://t.co/OQ4i8HBvwO
— Kazuyuki Miyazawa (@kzykmyzw) April 10, 2019
 線形な畳み込み演算の結果を活性化関数に入力することで非線形性を獲得している従来のCNNに対し、畳み込み処理自体を非線形化したkervolution (kernel convolution) を提案。原理的には入力ベクトルとフィルタ係数の双方を非線形マッピングしてから畳み込み演算を計算するというものだが、演算量が膨大となってしまうためカーネルトリックを利用している。CNNの利点である重み共有や位置ずれ不変といった性質を維持しつつ、非線形化によってパラメータ増加なしで表現能力を向上させることができる。カーネル関数としては様々なものを用いることができるが、論文中ではLp-Normやpolynominal、Gaussianなどが取り上げられている。例えばpolynominalカーネルは線形項とさらに高次の項の組み合わせとなるが、線形の部分については既存のCNNと同様のふるまいをすると考えられる。上図はこれを確認するため、MNISTを学習して得られた重みをpolynominal KNNとCNNの双方で可視化したものであるが、両者はかなり似通っていることがわかる。
### 評価実験
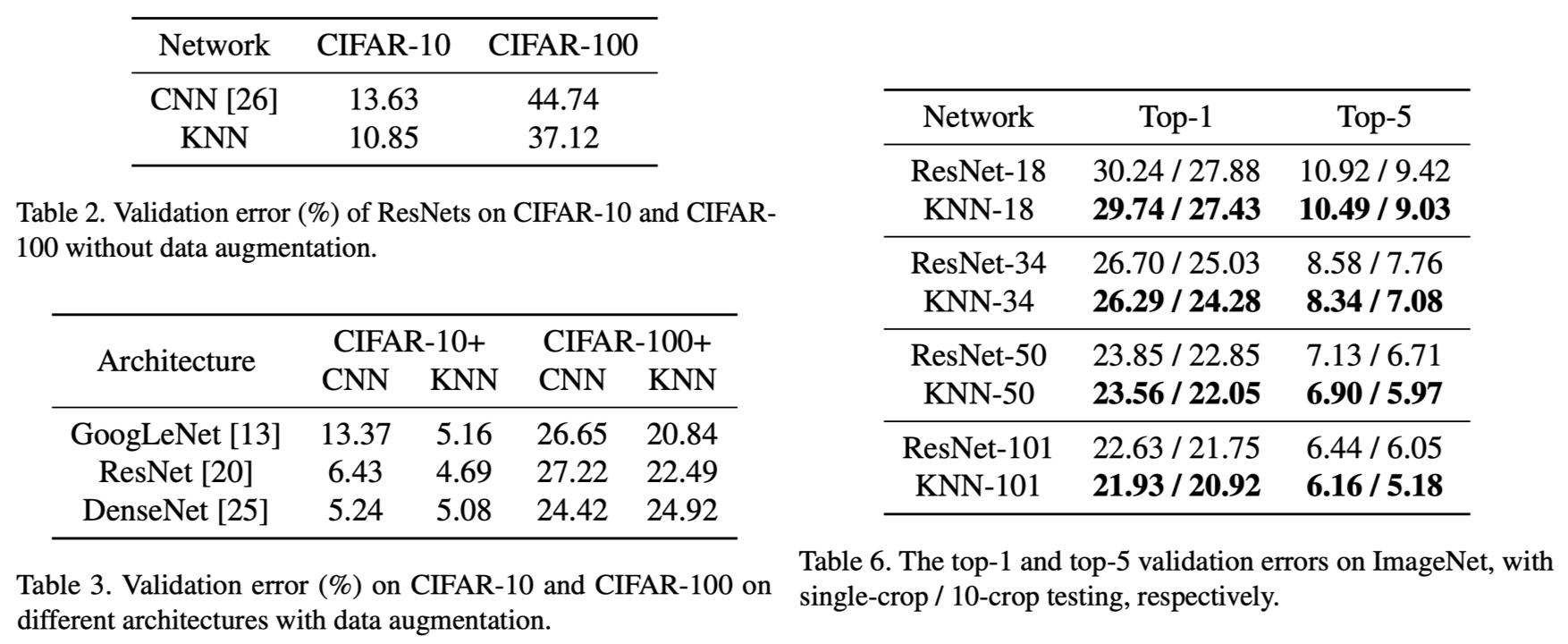
CIFAR-10/100、ImageNetを用いて画像分類精度をCNNとKNNで比較しているが、deepなモデルにおいてKNNの最適なアーキテクチャを探すことは極めて困難らしく、既存のCNNアーキテクチャの最初の畳み込み層だけをkervolutionに置き換えて比較実験を行なっている。したがって実験条件が最適とは言えないが、上図の通りKNNの利用により性能が向上していることは確認できる。また、非常に小規模なモデル (LeNet-5) ではあるものの、CNNにおいて活性化関数を取り去って非線形をなくすとMNISTの精度が98%から92.22%に落ちるのに対し、非線形性を維持できるKNNでは99.11%と高い精度が達成できることも報告されている。
### 実装
おそらく第三者によるものと思われる実装がいくつか公開されている。
線形な畳み込み演算の結果を活性化関数に入力することで非線形性を獲得している従来のCNNに対し、畳み込み処理自体を非線形化したkervolution (kernel convolution) を提案。原理的には入力ベクトルとフィルタ係数の双方を非線形マッピングしてから畳み込み演算を計算するというものだが、演算量が膨大となってしまうためカーネルトリックを利用している。CNNの利点である重み共有や位置ずれ不変といった性質を維持しつつ、非線形化によってパラメータ増加なしで表現能力を向上させることができる。カーネル関数としては様々なものを用いることができるが、論文中ではLp-Normやpolynominal、Gaussianなどが取り上げられている。例えばpolynominalカーネルは線形項とさらに高次の項の組み合わせとなるが、線形の部分については既存のCNNと同様のふるまいをすると考えられる。上図はこれを確認するため、MNISTを学習して得られた重みをpolynominal KNNとCNNの双方で可視化したものであるが、両者はかなり似通っていることがわかる。
### 評価実験

CIFAR-10/100、ImageNetを用いて画像分類精度をCNNとKNNで比較しているが、deepなモデルにおいてKNNの最適なアーキテクチャを探すことは極めて困難らしく、既存のCNNアーキテクチャの最初の畳み込み層だけをkervolutionに置き換えて比較実験を行なっている。したがって実験条件が最適とは言えないが、上図の通りKNNの利用により性能が向上していることは確認できる。また、非常に小規模なモデル (LeNet-5) ではあるものの、CNNにおいて活性化関数を取り去って非線形をなくすとMNISTの精度が98%から92.22%に落ちるのに対し、非線形性を維持できるKNNでは99.11%と高い精度が達成できることも報告されている。
### 実装
おそらく第三者によるものと思われる実装がいくつか公開されている。
5月
### タイトル Chuming Li, Yuan Xin, Chen Lin, Minghao Guo, Wei Wu, Wanli Ouyang, and Junjie Yan (SenseTime, The University of Sydney), "**AM-LFS: AutoML for Loss Function Search**," ICCV2019. ### 手法概要ロス関数の探索のためのAutoML手法。soft maxロスに2種類の変換を導入することで既存の様々なロスを近似し、その変換パラメータを探索する。探索はモデルの性能を報酬とした強化学習により行われ、並行してモデル自体も学習する。soft maxロスに対する性能向上はCIFAR10で約2%。顔認識とReIDでも評価 https://t.co/sEHrSY1V2M
— Kazuyuki Miyazawa (@kzykmyzw) May 21, 2019
 ロス関数の探索に特化したAutoMLであるAM-LFS (AutoML for Loss Function Search) を提案。softmax loss、margin-based softmax loss、focal lossを対象として解析を行い、softmax lossに2つの変換を適用することでこれらを一般化でき、クラス内距離とクラス間距離のバランス、および難易度の異なるサンプル間のバランスを調整可能であることを示している。これらの変換の候補は区分線形関数で表すことができ、AM-LFSではこの線形関数のパラメータをaccuracyやmAPを報酬とした強化学習により探索する。上図は提案手法における最適化フレームワークであるが、inner loopとouter loopの2つを設けており、inner loopで対象となるニューラルネットワークを学習し、その結果を基にouter loopでロス関数を最適化している。これを繰り返すことで、ネットワークの学習とロス関数の最適化を同時に実施することができる。
### 評価実験

画像分類、顔認識、Person ReIDにおいて一般的なロス関数や既存手法と提案手法を比較している。上図の左上は画像分類における比較結果であるが、標準的なcross-entropy (CE) や従来手法 (L2T-DLF) と比較して提案手法の方が高精度な結果となっている。また、左下が顔認識、右がPerson ReIDでの比較結果であるが、いずれにおいても提案手法が最も高い性能を示している。
# 6月
ロス関数の探索に特化したAutoMLであるAM-LFS (AutoML for Loss Function Search) を提案。softmax loss、margin-based softmax loss、focal lossを対象として解析を行い、softmax lossに2つの変換を適用することでこれらを一般化でき、クラス内距離とクラス間距離のバランス、および難易度の異なるサンプル間のバランスを調整可能であることを示している。これらの変換の候補は区分線形関数で表すことができ、AM-LFSではこの線形関数のパラメータをaccuracyやmAPを報酬とした強化学習により探索する。上図は提案手法における最適化フレームワークであるが、inner loopとouter loopの2つを設けており、inner loopで対象となるニューラルネットワークを学習し、その結果を基にouter loopでロス関数を最適化している。これを繰り返すことで、ネットワークの学習とロス関数の最適化を同時に実施することができる。
### 評価実験

画像分類、顔認識、Person ReIDにおいて一般的なロス関数や既存手法と提案手法を比較している。上図の左上は画像分類における比較結果であるが、標準的なcross-entropy (CE) や従来手法 (L2T-DLF) と比較して提案手法の方が高精度な結果となっている。また、左下が顔認識、右がPerson ReIDでの比較結果であるが、いずれにおいても提案手法が最も高い性能を示している。
# 6月
### タイトル Adam Gaier and David Ha (Google), "**Weight Agnostic Neural Networks**," NeurIPS2019. ### 手法概要学習をせずに高い性能を出せるアーキテクチャを探索。多様なrandom weightsに対して性能が出るよう最適化するため、学習が不要なのに加え、得られたアーキテクチャに複数の重みを与えることでアンサンブルによる性能向上が可能。強化学習と画像分類タスクで性能を確認。MNISTでは学習なしで精度90%以上 https://t.co/m4RD4VpfJB
— Kazuyuki Miyazawa (@kzykmyzw) June 12, 2019
 Neural Architecture Search (NAS) において、重みを一切学習しなくても高い性能が出せるWeight Agnostic Neural Nets (WANN) を探索する手法を提案。まず、最小限の構成を持つシンプルなネットワークを複数生成し、それぞれに対して共通の重みを設定したうえで対象タスクでの性能評価を行う。そして、得られた性能とアーキテクチャの複雑性に応じてネットワークを順位付けし、上位となったネットワークのアーキテクチャに一部変更を加えて新たなネットワーク群を生成する。これを繰り返すことで徐々に性能の高いネットワークを獲得していく。探索時にアーキテクチャに加える変更は、(i) 新たなノードの追加、(ii) ノード間の接続の追加、(iii) 活性化関数の変更、のいずれかである。評価時にはあらかじめ複数の共通した重みを用意しておき、それぞれの重みを適用した際の性能を平均化したものをそのネットワークの性能として用いている。これと併せ、よりシンプルなアーキテクチャが優先されるようにしているが、場合によっては複雑なアーキテクチャも許容できるよう、複雑性の評価は確率的に実行されるようにしている。
### 評価実験
Neural Architecture Search (NAS) において、重みを一切学習しなくても高い性能が出せるWeight Agnostic Neural Nets (WANN) を探索する手法を提案。まず、最小限の構成を持つシンプルなネットワークを複数生成し、それぞれに対して共通の重みを設定したうえで対象タスクでの性能評価を行う。そして、得られた性能とアーキテクチャの複雑性に応じてネットワークを順位付けし、上位となったネットワークのアーキテクチャに一部変更を加えて新たなネットワーク群を生成する。これを繰り返すことで徐々に性能の高いネットワークを獲得していく。探索時にアーキテクチャに加える変更は、(i) 新たなノードの追加、(ii) ノード間の接続の追加、(iii) 活性化関数の変更、のいずれかである。評価時にはあらかじめ複数の共通した重みを用意しておき、それぞれの重みを適用した際の性能を平均化したものをそのネットワークの性能として用いている。これと併せ、よりシンプルなアーキテクチャが優先されるようにしているが、場合によっては複雑なアーキテクチャも許容できるよう、複雑性の評価は確率的に実行されるようにしている。
### 評価実験
 制御問題および画像分類において性能を評価。上図は制御問題における評価結果であり、3つの問題(CartPoleSwingUp、BipedalWalker-v2、, CarRacing-v0)においてWANNと通常の固定的なアーキテクチャを以下4つの条件で比較している。
制御問題および画像分類において性能を評価。上図は制御問題における評価結果であり、3つの問題(CartPoleSwingUp、BipedalWalker-v2、, CarRacing-v0)においてWANNと通常の固定的なアーキテクチャを以下4つの条件で比較している。
- Random Weights: ランダムな重みを適用
- Random Shared Weight: 重みはランダムだがネットワーク全体で同じ値を共有
- Tuned Shared Weight: Random Shared Weightの中で最大性能となったもの
- Tuned Weight: 重みを学習
上の結果からわかるように、通常通り重みを学習した場合 (Tuned Weight) には及ばないものの、WANNでは重みを一切学習しなくても高い性能が得られている。

また、上図はMNISTを用いて画像分類の精度を評価した結果であるが、やはりWANNはランダムな重みでも高い性能を示している。また、上図右は与える重みによって各数字の認識精度が変化する様子を示しているが、このように異なる重みを与えたネットワークを複数用意してその推論結果を統合することで、単一アーキテクチャでアンサンブルを行い精度を向上させることも可能である(上図左のEnsemble Weigths)。
実装
著者実装ではなさそうだがGoogleにより実装が公開されている。
おわりに
そもそも私がツイートしている論文に偏りがあり、またフォロワー数も少ないので (follow me please!) 、ツイートのインプレッションが高いといっても各月で分野を代表するような超有名論文が選ばれているかというと全くそんなことはないですね。記事のタイトルに誇張があることをお詫び申し上げます。ただこうして振り返ってみると、わずか1年の間であるにも関わらず、話題になっていたけれども今では全く聞くことがない、とか、すでに異なるアプローチが主流となっている、というようなものも見られ、この分野のスピードにあらためて驚かされます。やはり日々arXivをチェックする生活はまだまだ続けないとならないようです。それでは後半(7月〜12月)をお楽しみに〜