目的
使用するデータ数が少ない場合にも精度を上げる方法がないか考える
制約
- 改良前のモデル構造は保つ
- endtoendに学習できるようにする(autoencoderとcnnを一つのモデルとして作る)
- ganやその他data augmentationを行わない。
- データにはmnistを使い、各ラベル100枚ずつ100*10の1000枚で行う
データの取り出しやモデルのfitの書き方は記述しないので、データの取り出し方はこちら、fit,compileの書き方はこちらを参照してください。
コード全体はこちら
dataの前処理
前処理としてもよくある、255で割りスケーリングするだけです。
x_train = x_train / 255
x_test = x_test / 255
改良前
改良前の分類モデルは簡単にチューニング等やりましたが、これ以上に精度が出る方法もあると思います。
model構造
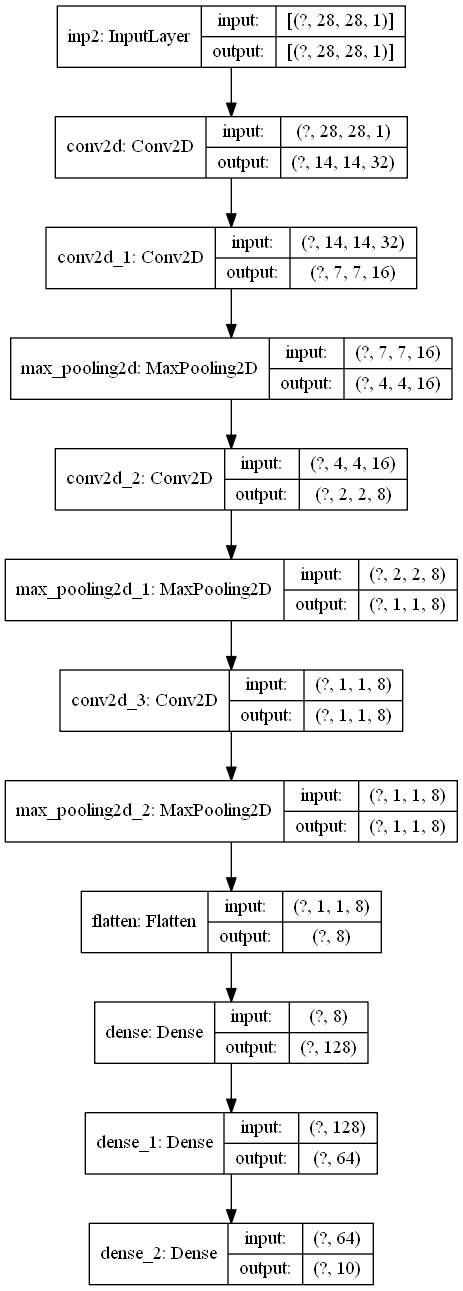
modelコード
inp = Input(shape=(28,28,1),name="inp2")
p3 = Conv2D(32,2,2,padding="same")(inp)
p3 = Conv2D(16,2,2,padding="same")(p3)
p3 = MaxPooling2D(2,2,padding="same")(p3)
p3 = Conv2D(8,2,2,padding="same")(p3)
p3 = MaxPooling2D(2,2,padding="same")(p3)
p3 = Conv2D(8,2,2,padding="same")(p3)
p3 = MaxPooling2D(2,2,padding="same")(p3)
p3 = Flatten()(p3)
p3 = Dense(128,activation="relu")(p3)
p3 = Dense(64,activation="relu")(p3)
out = Dense(10,activation="softmax")(p3)
後から構造が同じことを確認しやすいように名前や変数名を後と同じにしています。
dataの前処理
改良前は28*28のサイズをそのまま入力できるので特に行うことはありません。
条件は以下のように学習しました。
- optimizer : adam
- loss : categorical crossentropy
- metrics : acc
- earlystoping : { monitor : val loss , min delta : 0.00001 , patience : 10 , mode : auto }
- batch size : 8
- val size : 0.2
この条件は改良後も同じにしています。
学習
Epoch 1/10000
100/100 [==============================] - 0s 4ms/step - loss: 2.2860 - acc: 0.1250 - val_loss: 2.2386 - val_acc: 0.1500
Epoch 2/10000
100/100 [==============================] - 0s 2ms/step - loss: 1.9977 - acc: 0.2575 - val_loss: 1.7996 - val_acc: 0.3200
Epoch 3/10000
100/100 [==============================] - 0s 3ms/step - loss: 1.6415 - acc: 0.3825 - val_loss: 1.6337 - val_acc: 0.3650
Epoch 4/10000
100/100 [==============================] - 0s 2ms/step - loss: 1.4488 - acc: 0.4475 - val_loss: 1.4533 - val_acc: 0.4500
Epoch 5/10000
100/100 [==============================] - 0s 2ms/step - loss: 1.2776 - acc: 0.5325 - val_loss: 1.3028 - val_acc: 0.5000
Epoch 6/10000
100/100 [==============================] - 0s 2ms/step - loss: 1.1254 - acc: 0.5863 - val_loss: 1.2225 - val_acc: 0.5450
Epoch 7/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.9990 - acc: 0.6275 - val_loss: 1.1432 - val_acc: 0.6000
Epoch 8/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.8964 - acc: 0.6812 - val_loss: 1.1002 - val_acc: 0.6600
Epoch 9/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.8101 - acc: 0.7237 - val_loss: 1.0833 - val_acc: 0.6550
Epoch 10/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.7583 - acc: 0.7300 - val_loss: 1.0636 - val_acc: 0.6700
Epoch 11/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.6986 - acc: 0.7625 - val_loss: 1.0313 - val_acc: 0.6450
Epoch 12/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.6530 - acc: 0.7650 - val_loss: 1.0362 - val_acc: 0.6800
Epoch 13/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.5929 - acc: 0.7962 - val_loss: 1.0390 - val_acc: 0.6850
Epoch 14/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.5830 - acc: 0.7887 - val_loss: 1.0353 - val_acc: 0.6700
Epoch 15/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.5379 - acc: 0.8163 - val_loss: 1.0150 - val_acc: 0.6900
Epoch 16/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.5073 - acc: 0.8288 - val_loss: 1.0049 - val_acc: 0.6750
Epoch 17/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.4809 - acc: 0.8325 - val_loss: 1.0357 - val_acc: 0.7100
Epoch 18/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.4510 - acc: 0.8438 - val_loss: 1.0232 - val_acc: 0.6900
Epoch 19/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.4356 - acc: 0.8438 - val_loss: 1.0402 - val_acc: 0.6700
Epoch 20/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.4083 - acc: 0.8625 - val_loss: 1.0361 - val_acc: 0.7000
Epoch 21/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.4188 - acc: 0.8537 - val_loss: 0.9956 - val_acc: 0.6900
Epoch 22/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.3855 - acc: 0.8675 - val_loss: 1.0222 - val_acc: 0.7050
Epoch 23/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.3491 - acc: 0.8863 - val_loss: 1.0171 - val_acc: 0.7000
Epoch 24/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.3160 - acc: 0.8900 - val_loss: 1.0814 - val_acc: 0.7050
Epoch 25/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.3231 - acc: 0.8813 - val_loss: 1.0660 - val_acc: 0.7000
Epoch 26/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.3102 - acc: 0.8813 - val_loss: 1.1023 - val_acc: 0.7150
Epoch 27/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.2892 - acc: 0.8988 - val_loss: 1.0896 - val_acc: 0.7100
Epoch 28/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.2597 - acc: 0.9087 - val_loss: 1.1387 - val_acc: 0.6900
Epoch 29/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.2442 - acc: 0.9175 - val_loss: 1.1421 - val_acc: 0.7250
Epoch 30/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.2295 - acc: 0.9162 - val_loss: 1.1753 - val_acc: 0.7100
Epoch 31/10000
100/100 [==============================] - 0s 2ms/step - loss: 0.2035 - acc: 0.9287 - val_loss: 1.2142 - val_acc: 0.7300
test dataに対する予測
pred_labels = model.predict(x_test)
pred = []
for label in pred_labels:
idx = label.argmax()
pred.append(idx)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,pred))
0.7464
テストサイズに対するaccスコアは0.7464を出しました。
次にautoencoderを組み込んで改良してみます。
改良後
model 構造

model コード
# autoencoder部
input_img = Input(shape=(784,),name="inp1")
x= Dense(256, activation="relu")(input_img)
x = Dense(128,activation="relu")(x)
encoded = Dense(128, activation="relu")(x)
z = Dense(128, activation="relu")(encoded)
decoded = Dense(784, activation="sigmoid",name="decoded")(z)
# autoencoderの中間層からの出力を受け取り全結合
p2 = Dense(128,activation="relu")(encoded)
p2 = Dense(64,activation="relu")(p2)
# 比べる対象cnn model、構造は改良前と同一なもの
inp = Input(shape=(28,28,1),name="inp2")
p3 = Conv2D(32,2,2,padding="same")(inp)
p3 = Conv2D(16,2,2,padding="same")(p3)
p3 = MaxPooling2D(2,2,padding="same")(p3)
p3 = Conv2D(8,2,2,padding="same")(p3)
p3 = MaxPooling2D(2,2,padding="same")(p3)
p3 = Conv2D(8,2,2,padding="same")(p3)
p3 = MaxPooling2D(2,2,padding="same")(p3)
p3 = Flatten()(p3)
p3 = Dense(128,activation="relu")(p3)
p3 = Dense(64,activation="relu")(p3)
p = Add()([p2,p3])
p = Dense(32,activation="relu")(p)
predictor = Dense(10,activation="softmax",name="predictor")(p)
考え方
autoencoderを別で学習させて、encoderの出力を特徴量としてmodelの精度を上げるものはweb上に多く存在した。
- 画像そのものとautoencoderからのencodeの二つを入力とすればよりよいのでは。
- どうせならendtoendで一つのmodelとして実装したらどうか
この考えで作成しました。
dataの前処理
前処理は配列の構造を変えるだけで水増しはしません。改良前はloadしたmnistをそのままのサイズで入力できましたが、autoencoderに入力する際にはフラットにします。また、入力層は二つあるので二つ用意します。同様にlabelには分類用の分類ラベルとautoencoder用の入力画像と同じ画像の二つを用意します。
x_train_1 = x_train.reshape(len(x_train),784,1)
x_train_2 = x_train.reshape(len(x_train),28,28,1)
x_val_1 = x_val.reshape(len(x_val),784,1)
x_val_2 = x_val.reshape(len(x_val),28,28,1)
fit時のxとyは以下のように指定します。
- x = {"inp1":x_train_1,"inp2":x_train_2}
- y={"decoded":x_train_1,"predictor":y_train}
条件は改良前と一緒にします。
学習
Epoch 1/10000
100/100 [==============================] - 0s 5ms/step - loss: 1.5771 - decoded_loss: 0.0945 - predictor_loss: 1.4826 - predictor_acc: 0.5038 - val_loss: 1.1179 - val_decoded_loss: 0.0599 - val_predictor_loss: 1.0580 - val_predictor_acc: 0.6600
Epoch 2/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.6398 - decoded_loss: 0.0569 - predictor_loss: 0.5829 - predictor_acc: 0.8200 - val_loss: 0.8113 - val_decoded_loss: 0.0530 - val_predictor_loss: 0.7583 - val_predictor_acc: 0.7650
Epoch 3/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.4338 - decoded_loss: 0.0524 - predictor_loss: 0.3814 - predictor_acc: 0.8700 - val_loss: 0.7595 - val_decoded_loss: 0.0507 - val_predictor_loss: 0.7088 - val_predictor_acc: 0.7500
Epoch 4/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.3216 - decoded_loss: 0.0505 - predictor_loss: 0.2710 - predictor_acc: 0.9225 - val_loss: 0.5286 - val_decoded_loss: 0.0489 - val_predictor_loss: 0.4797 - val_predictor_acc: 0.8250
Epoch 5/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.2043 - decoded_loss: 0.0491 - predictor_loss: 0.1551 - predictor_acc: 0.9588 - val_loss: 0.4416 - val_decoded_loss: 0.0473 - val_predictor_loss: 0.3943 - val_predictor_acc: 0.8600
Epoch 6/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.1560 - decoded_loss: 0.0477 - predictor_loss: 0.1083 - predictor_acc: 0.9650 - val_loss: 0.6524 - val_decoded_loss: 0.0464 - val_predictor_loss: 0.6061 - val_predictor_acc: 0.8350
Epoch 7/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.1374 - decoded_loss: 0.0463 - predictor_loss: 0.0911 - predictor_acc: 0.9737 - val_loss: 0.6657 - val_decoded_loss: 0.0461 - val_predictor_loss: 0.6197 - val_predictor_acc: 0.8450
Epoch 8/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.1535 - decoded_loss: 0.0456 - predictor_loss: 0.1079 - predictor_acc: 0.9675 - val_loss: 0.5291 - val_decoded_loss: 0.0432 - val_predictor_loss: 0.4860 - val_predictor_acc: 0.8600
Epoch 9/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.1218 - decoded_loss: 0.0440 - predictor_loss: 0.0779 - predictor_acc: 0.9737 - val_loss: 0.7133 - val_decoded_loss: 0.0428 - val_predictor_loss: 0.6705 - val_predictor_acc: 0.8600
Epoch 10/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.0800 - decoded_loss: 0.0428 - predictor_loss: 0.0372 - predictor_acc: 0.9900 - val_loss: 0.6788 - val_decoded_loss: 0.0414 - val_predictor_loss: 0.6374 - val_predictor_acc: 0.8550
Epoch 11/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.0590 - decoded_loss: 0.0409 - predictor_loss: 0.0181 - predictor_acc: 0.9962 - val_loss: 0.4702 - val_decoded_loss: 0.0396 - val_predictor_loss: 0.4306 - val_predictor_acc: 0.8850
Epoch 12/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.0586 - decoded_loss: 0.0398 - predictor_loss: 0.0188 - predictor_acc: 0.9962 - val_loss: 0.5544 - val_decoded_loss: 0.0392 - val_predictor_loss: 0.5152 - val_predictor_acc: 0.8600
Epoch 13/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.0398 - decoded_loss: 0.0383 - predictor_loss: 0.0014 - predictor_acc: 1.0000 - val_loss: 0.5413 - val_decoded_loss: 0.0376 - val_predictor_loss: 0.5037 - val_predictor_acc: 0.8800
Epoch 14/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.0376 - decoded_loss: 0.0371 - predictor_loss: 5.6022e-04 - predictor_acc: 1.0000 - val_loss: 0.5456 - val_decoded_loss: 0.0371 - val_predictor_loss: 0.5085 - val_predictor_acc: 0.8750
Epoch 15/10000
100/100 [==============================] - 0s 3ms/step - loss: 0.0362 - decoded_loss: 0.0359 - predictor_loss: 3.1317e-04 - predictor_acc: 1.0000 - val_loss: 0.5563 - val_decoded_loss: 0.0361 - val_predictor_loss: 0.5202 - val_predictor_acc: 0.8700
test dataに対する予測
pred_img ,pred_labels = model.predict({"inp1":x_test_1,"inp2":x_test_2})
pred = []
for label in pred_labels:
idx = label.argmax()
pred.append(idx)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,pred))
0.9055
autoencoderのencode出力
# autoencoderの出力
for i in range(5):
fig , ax = plt.subplots()
x_test = x_test.reshape(len(x_test),28,28)
ax.imshow(x_test[i])
fig , ax = plt.subplots()
pred_img = pred_img.reshape(len(pred_img),28,28)
ax.imshow(pred_img[i])
plt.show()


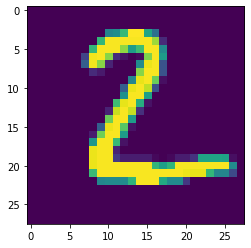




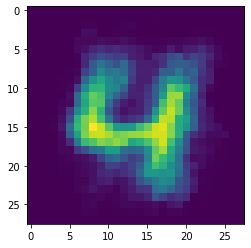

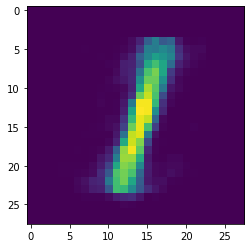
テストデータに対するacc scoreは0.9055を出力しました。
autoencoder自体もなんとなく(すごい微妙に)再現できているように見えます。しかし、autoencoderの再現自体はcnn modelをくっ付けない方が良く再現できます(今回は記述しませんが)。
まとめ
両方のacc scoreをまとめました。
- 改良前 : 0.7464
- 改良後 : 0.9055
改良前から約0.2近くの精度改善が見られました。autoencoderを付け加えることで、(タスクにもよりますが)mnistでは精度の改善ができるといえるのではないでしょうか。
最後
bacth normalizationを今回は使用しないmodelを使用しましたが、batch normalizationのlayerを付け加えることでより良い精度が見られると思います。
また今回はmnistで精度の改善が見られましたが、cifar-10などのような情報量の多い画像を扱う場合には精度が上がるかどうかはやってみないとわからないと思います。