Entity Embeddingsという深層学習の手法があります。深層学習がよく使われる画像分析や音声分析などのデータとは違う、カテゴリ変数や順序変数の特徴量を学習する時に使います。
Entity Embeddingsが広く知られるようになったきっかけは、KaggleのRossmann Store Salesコンペでした。1位と2位のチームがドメイン知識をフル活用したアプローチをしたのに対し、この手法を活用したチームはドメイン知識の無い中なんと3位に入賞しました。コンペの説明と、使われた手法については、3位のNeokami Incのインタビュー記事、使われたソースコード、コンペ後に発表した手法に関する論文などで学ぶことができます。
タイタニック号生存者予測コンペのサンプルデータに対し、このEntity Embeddingsを実装するにはどうすれば良いのでしょうか。
0. 環境構築
環境構築に私はPipenvを使っています。venv、conda、pip+virtualenv、pyenvなど、他のツールを使っている方はそれを使ってください。今回はPipenvを使った書き方のみ紹介します。
Python3.6を使います。今回使うTensorflow (v1.12)がPython3.7以降と互換性が無いため(執筆時)です。また、データ読み込み、前処理、表示などのためにpandasもインストールします。
pipenv --python 3.6
pipenv install tensorflow pandas
Jupyter Notebook で実行するときは、インストールして起動しましょう。
```shell pipenv install jupyter pipenv run jupyter notebook ```1. データを読み込む
使うデータはタイタニックコンペのデータです。リンクからデータをダウンロードして、解凍しておきます。
```python import pandas as pdtrain = pd.read_csv("./train.csv")
test = pd.read_csv("./test.csv")
train.head(2)
<table>
<thead>
<tr>
<th></th>
<th>PassengerId</th>
<th>Survived</th>
<th>Pclass</th>
<th>Name</th>
<th>Sex</th>
<th>Age</th>
<th>SibSp</th>
<th>Parch</th>
<th>Ticket</th>
<th>Fare</th>
<th>Cabin</th>
<th>Embarked</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1</td>
<td>0</td>
<td>3</td>
<td>Braund, Mr. Owen Harris</td>
<td>male</td>
<td>22.0</td>
<td>1</td>
<td>0</td>
<td>A/5 21171</td>
<td>7.2500</td>
<td>NaN</td>
<td>S</td>
</tr>
<tr>
<th>1</th>
<td>2</td>
<td>1</td>
<td>1</td>
<td>Cumings, Mrs. John Bradley (Florence Briggs Th...</td>
<td>female</td>
<td>38.0</td>
<td>1</td>
<td>0</td>
<td>PC 17599</td>
<td>71.2833</td>
<td>C85</td>
<td>C</td>
</tr>
</tbody>
</table>
<p>各項目の説明は<a href="https://www.kaggle.com/c/titanic/data" target="_blank" rel="noopener noreferrer">コンペページ</a>で説明がされています。</p>
<h3>2. データの前処理</h3>
<ul>
<li>Null値に適当な値を代入</li>
<li>文字列データは、カテゴリ変数(数字)に変換する</li>
<li>データから新しい特徴を見つけ、データを増やす</li>
</ul>
<p>
今回は比較的簡単な処理のみをしています。詳細については割愛しますが、python + pandas ではこんなに少ない行数で様々な処理を実行できます。
</p>
```python
data = pd.concat([train.drop(columns="Survived"), test]).reset_index(drop=True)
data["Pclass"] -= 1
data["FamSize"] = data["SibSp"] + data["Parch"]
data["IsAlone"] = data["FamSize"] == 0
data["Embarked"].fillna(data["Embarked"].mode()[0], inplace=True)
data["Age"].fillna(data["Age"].median(), inplace=True)
data["Fare"].fillna(data["Fare"].median(), inplace=True)
data.drop(columns=["Cabin", "Ticket", "Name"], inplace=True)
for c in ["Sex", "Embarked"]: data[c] = data[c].astype("category").cat.codes
for c in ["Pclass", "Sex", "Age", "SibSp", "Parch", "Embarked", "FamSize", "IsAlone"]: data[c] = data[c].astype(int)
train_X = data.join(train["Survived"], how="inner").drop(columns=["PassengerId", "Survived"])
train_Y = train[["Survived"]]
test_X = data.loc[data["PassengerId"].isin(test["PassengerId"])]
全て数字のデータができました。
train_X.head(2)
| Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | FamSize | IsAlone | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 1 | 22 | 1 | 0 | 7.2500 | 2 | 1 | 0 |
| 1 | 0 | 0 | 38 | 1 | 0 | 71.2833 | 0 | 1 | 0 |
test_Y.head(2)
| Survived | |
|---|---|
| 0 | 0 |
| 1 | 1 |
3. Entity Embeddingを用いた深層学習モデルを作る
Embeddingを作る対象は、「カテゴリ変数」と「順序変数」です。前処理後のタイタニックデータの中では、「Fare」をのぞいて全てが当てはまります。
今回はTensorflowの中のKeras APIを使います。Functional APIという記法を使って以下のように書きます。
from tensorflow.keras.layers import Input, Embedding, Flatten
x = Input(shape=(1,)) # 入力層。
x = Embedding("カテゴリ数", "埋め込み次元数")(x) # 入力されるカテゴリ数と埋め込み次元数をそれぞれ指定する。
x = Flatten()(x) # 次ステップで組み合わせるときのために形を整える。
上記で1ブロックとなり、これを各項目ごとに作ります。残りのステップは、
- 埋め込みブロックの出力を全て組み合わせて(Concatenate層)、
- 何層か全結合(Dense層)+ReLU層(Dense層の引数で指定)を足し、
- 二値分類(生存したか、していないか)のため、最後をSigmoid層(Dense層の引数で指定)にして完成。
「Pclass」のEmbeddingブロックを作る過程で詳しく説明します。
イ. まずは、Input層を使って入力層を作ります。
from tensorflow.keras.layers import Input
input_Pclass = Input(shape=(1,), name="input_Pclass")
name引数を使って、層に名前をつけておきます(後ほど使用します)。
尚、入力する形(shape引数)が (1,) なのは、データ1単位あたり必ず1つの数字のみが入力されるためです。つまり、タイタニック乗客一人に対して
`Pclass = [1]`このようなデータの単位を持っているからです。例えば、
`data = [0, 1, 3]`上記が単位あたりのデータの場合、入力する形は (3,)。
`data = [[0, 2], [3, 1], [4, 0]]`この場合は (3, 2) です。
ロ. 次に、Embedding層を使い、Embeddingベクトルを割り当てます。
from tensorflow.keras.layers import Embedding
embed_Pclass = Embedding(3, 2, name="embed_Pclass")(input_Pclass)
Pclassのカテゴリ数は、「0 か 1 か 2」 の「3つ」。尚、埋め込み次元数はハイパーパラメーターのため、正解が無く、試行錯誤する必要があります。
埋め込み次元数で推奨される大きさは、Googleのチュートリアルでは「カテゴリー数**0.25」、大元の論文(セクションV. 5段落目)では、「カテゴリ数〜カテゴリ数-1の間の数字で試しながら決める」などと書かれており、まだベストプラクティスが決まっていない状態です。今回は、3つのPclassのカテゴリ変数に対して、大きさ「2」のベクトルをそれぞれ割り当てます。
ハ. 最後に、Flatten層を使って、後ほど他のEmbeddingブロックと結合するときのために形を整えます。
from tensorflow.keras.layers import Flatten
flatt_Pclass = Flatten(name="flatt_Pclass")(embed_Pclass)
以上で1ブロック完成です。以下が全ての項目でこの操作をしたコードです。まず、各項目の最小値、最大値、ユニークな値の数を調べ、それを元に埋め込み次元数を決めていきます。
# データの各項目の「最小値」、「最大値」、「ユニークな値数」を表示
data.agg(["min", "max", "nunique"]).T
| min | max | nunique | |
|---|---|---|---|
| PassengerId | 1.0 | 1309.0000 | 1309.0 |
| Pclass | 0.0 | 2.0000 | 3.0 |
| Sex | 0.0 | 1.0000 | 2.0 |
| Age | 0.0 | 80.0000 | 73.0 |
| SibSp | 0.0 | 8.0000 | 7.0 |
| Parch | 0.0 | 9.0000 | 8.0 |
| Fare | 0.0 | 512.3292 | 281.0 |
| Embarked | 0.0 | 2.0000 | 3.0 |
| FamSize | 0.0 | 10.0000 | 9.0 |
| IsAlone | 0.0 | 1.0000 | 2.0 |
# 上記のデータを元に各カテゴリ数や埋め込み次元を決めてブロックを作っていく
from tensorflow.keras.layers import Input, Embedding, Flatten
input_Pclass = Input(shape=(1,), name="input_Pclass")
embed_Pclass = Embedding(3, 2, name="embed_Pclass")(input_Pclass)
flatt_Pclass = Flatten(name="flatt_Pclass")(embed_Pclass)
input_Sex = Input(shape=(1,), name="input_Sex")
embed_Sex = Embedding(2, 4, name="embed_Sex")(input_Sex)
flatt_Sex = Flatten(name="flatt_Sex")(embed_Sex)
input_Age = Input(shape=(1,), name="input_Age")
embed_Age = Embedding(81, 15, name="embed_Age")(input_Age)
flatt_Age = Flatten(name="flatt_Age")(embed_Age)
input_SibSp = Input(shape=(1,), name="input_SibSp")
embed_SibSp = Embedding(9, 7, name="embed_SibSp")(input_SibSp)
flatt_SibSp = Flatten(name="flatt_SibSp")(embed_SibSp)
input_Parch = Input(shape=(1,), name="input_Parch")
embed_Parch = Embedding(10, 8, name="embed_Parch")(input_Parch)
flatt_Parch = Flatten(name="flatt_Parch")(embed_Parch)
input_Embarked = Input(shape=(1,), name="input_Embarked")
embed_Embarked = Embedding(4, 3, name="embed_Embarked")(input_Embarked)
flatt_Embarked = Flatten(name="flatt_Embarked")(embed_Embarked)
input_FamSize = Input(shape=(1,), name="input_FamSize")
embed_FamSize = Embedding(11, 6, name="embed_FamSize")(input_FamSize)
flatt_FamSize = Flatten(name="flatt_FamSize")(embed_FamSize)
input_IsAlone = Input(shape=(1,), name="input_IsAlone")
embed_IsAlone = Embedding(2, 4, name="embed_IsAlone")(input_IsAlone)
flatt_IsAlone = Flatten(name="flatt_IsAlone")(embed_IsAlone)
Fareだけは連続値のため、別の処理をします。今回は全結合層(Dense)のみです。全結合層は形が他のEmbeddingブロックの出力層と一緒になるため整える必要はありません。
from tensorflow.keras.layers import Dense
input_Fare = Input(shape=(1,), name="input_Fare")
dense_Fare = Dense(30, name="fc_Fare")(input_Fare)
全ての層をConcatenate層を使って一つの層にします。「flatt_」で始まる層と、FareのDense層を全てまとめます。
from tensorflow.keras.layers import Concatenate
concat_layers= [
flatt_Pclass,
flatt_Sex,
flatt_Age,
flatt_SibSp,
flatt_Parch,
flatt_Embarked,
flatt_FamSize,
flatt_IsAlone,
dense_Fare,
]
x = Concatenate()(concat_layers)
Activation層を使って活性化関数(ReLU)を適用してから、全結合+ReLUのブロックを3つ繋げてみます。全結合層のニューロンの数(第一引数)は適当に選び、トレーニングをしながらチューニングします。
from tensorflow.keras.layers import Activation
x = Activation("relu")(x)
x = Dense(96, activation="relu")(x)
x = Dense(48, activation="relu")(x)
x = Dense(24, activation="relu")(x)
最終出力は、二値分類のため、ニューロンを1つだけ持った全結合層にSigmoid層を組み合わせたブロックです。
output_layer = Dense(1, activation="sigmoid")(x)
ここまでで作った層を全てまとめて、モデルを定義します。Modelクラスに入力層と出力層を渡すと自動で中身の層を繋げてくれます。以下のように入力します。
from tensorflow.keras.models import Model
input_layers = [
input_Pclass,
input_Sex,
input_Age,
input_SibSp,
input_Parch,
input_Embarked,
input_FamSize,
input_IsAlone,
input_Fare
]
model = Model(input_layers, output_layer)
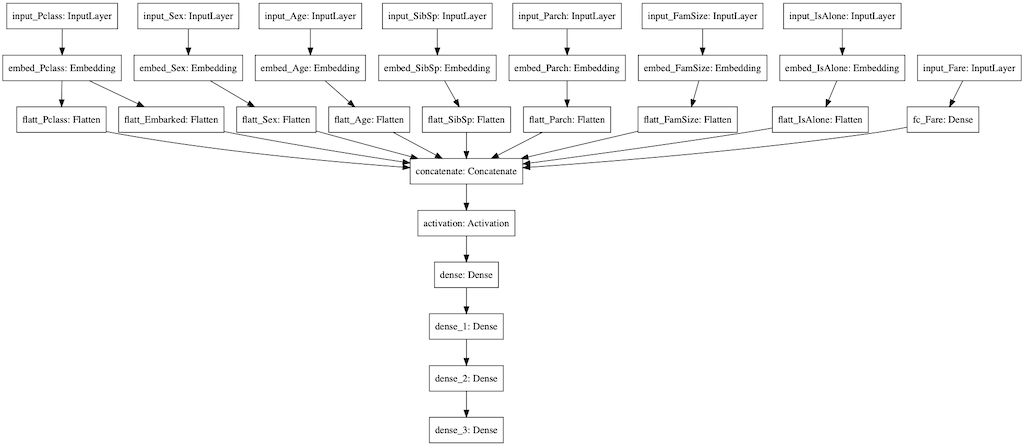
これを図にすると以下のようになります。(このコードを実行するには、実行環境にGraphvizがインストールされている必要があります。参考リンク)
from tensorflow.keras.utils import plot_model
plot_model(model, to_file='model.png')
4. 作成したモデルで学習
学習の際には、いくつかの変数を手動で設定する必要があります。
- 損失関数は二値分類のため「binary-crossentropy」
- 勾配法は「Adam」
- モデルのパフォーマンスは「accuracy」
Modelクラスのcompile関数で全て設定できます。
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
トレーニングにはModelクラスのfit関数を使います。今回引数に渡す変数について:
- x: 入力データ。pythonのdictionary型を使うことで、各Input層でつけていた名前を使い項目ごとのデータを指定することができます。尚、入力の形を各項目で(batch_size, 1)としたいため、PandasのDataFrame項目の選択の仕方を工夫してます。
X = {
"input_Pclass": train_X[["Pclass"]],
"input_Sex": train_X[["Sex"]],
"input_Age": train_X[["Age"]],
"input_SibSp": train_X[["SibSp"]],
"input_Parch": train_X[["Parch"]],
"input_Embarked": train_X[["Embarked"]],
"input_FamSize": train_X[["FamSize"]],
"input_IsAlone": train_X[["IsAlone"]],
"input_Fare": train_X[["Fare"]],
}
- y: 目的変数。つまり生存したかしていないかのデータ項目。これはDataFrame型で、入力の形が(batch_size, 1)となるためそのまま使います。
train_Y.head(2)
| Survived | |
|---|---|
| 0 | 0 |
| 1 | 1 |
- validation_split: 機械学習では、モデルが「過学習」を起こしていないかモニタリングするために、データを「トレーニング用」と「検証用」に分けます。fit関数では、ここに分割する割合を入れると自動で分割してくれます。2割のデータをテスト用に分割して分けておく場合:
validation_split = 0.2
- epochs: 全データを一周学習することを「1 epoch(エポック)学習する」と言います。何epoch学習するか入力します。
epochs = 100
1~4の変数をfit関数に引数として渡します。その他はデフォルトを使います。尚、fit関数からは「History」オブジェクトというものが返ります(詳細は後述)。
history = model.fit(x=x, y=train_Y, validation_split=validation_split, epochs=epochs)
出力:
Train on 712 samples, validate on 179 samples
Epoch 1/100
712/712 [==============================] - 1s 2ms/step - loss: 0.9792 - acc: 0.5281 - val_loss: 0.6805 - val_acc: 0.3855
Epoch 2/100
.....
5. 可視化
Historyオブジェクトには、トレーニング経過の記録(history)や、モデル(model)、トレーニングに用いたハイパーパラメーター(params)などが格納されています。これを用いて、トレーニング経過の記録を可視化します。
History のうち、history を pandas の DataFrame にして、plot関数でプロットしてみます。この関数は裏でmatplotlib を使っているため、使うにはmatplotlibをインストールした上で、Jupyter Notebook で使う際にはマジックコマンド(%matplotlib inline)を実行します。
pipenv install matplotlib
%matplotlib inline
results = pd.DataFrame(history.history)
results.head(2)
| val_loss | val_acc | loss | acc | |
|---|---|---|---|---|
| 0 | 0.680474 | 0.385475 | 0.979209 | 0.528090 |
| 1 | 0.656121 | 0.687151 | 0.696029 | 0.558989 |
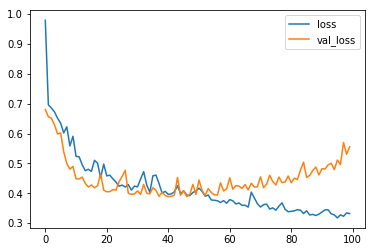
損失関数のプロット。過学習気味のようです。
results[["loss", "val_loss"]].plot()
精度のプロット。二値分類で検証データに対しておよそ8割の精度が出ているようです。
results[["acc", "val_acc"]].plot()

また、埋め込み層を可視化することもできます。方法は、Embedding Projector プロジェクトページに書いてあります。
おわりに
Entity Embeddingを使うと、カテゴリ変数がメインのSQLテーブルやエクセルなどのデータから学習する深層学習モデルを作ることができます。
ただし、この手法が必ず良い結果になるとは限りません。実際上記のモデルのKaggleでのsubmission scoreはおよそ0.7で、非常に悪いです。一方で、scikit-learnのRandomForestRegressorとGridSearchCVを使った簡単な方法でおよそ0.8強の精度(上位10%ライン)が出ます。
Entity Embeddingがもっとも光るのは、以下のケースでは無いかと思っています。
- データが膨大すぎて、決定木などのナイーブな方法ではモデルが大きくなり過ぎる等対処ができないとき。
- データに関するドメイン知識が無いことから、Feature Engineeringがあまりできないとき。
Kaggleのコンペは構造化データを扱うコンペが多いため、Entity Embeddingを使った解法を作ることができる場合が多いと思います。しかし、ランダムフォレストやSVMなどの方が精度が出る可能性もあることを認識しておくのは大事だと思います。
もし上記が間違っている、他のパターンの使い道がある、などあればぜひ教えてください![]()