はじめに
ディープラーニングを用いた異常検知手法であるALOCCをChainerで実装し,MNISTで実験しました。
全体のコードはGitHubのリポジトリにアップロードしました。
ALOCCについて
ALOCCは画像データに対して異常検知を行うための手法です。
多くの場合,異常データは正常データに比べて極めて少ないか,全く無いです。
そこで,ALOCCでは正常データのみを利用して学習し,その分布から外れたデータを検出します。
学習
ALOCCのモデルは以下のようなオートエンコーダとGANを組み合わせたような構造をしています。
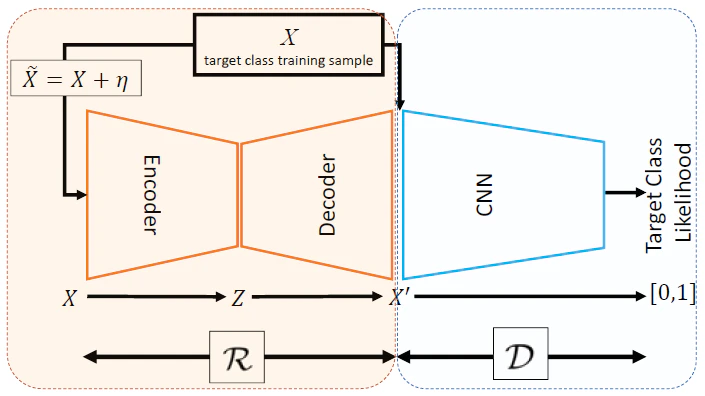
オートエンコーダ部分はGANのGeneratorに相当し,Reconstructor (${\cal R}$) と呼ばれます。
学習時には正常画像にノイズを加えたデータを入力し,元通りに復元することを学習します。
Discriminator (${\cal D}$) の役割はGANと同じで,入力された画像が${\cal R}$の出力なのか本物の正常画像なのかを見分けるように学習します。
以上の事柄を踏まえ,ALOCCの学習は以下の2つの目的関数の最適化によって行われます。
{\cal L}_{{\cal R}+{\cal D}}=\mathbb{E}\left[ \log ({\cal D}(X)) \right]+\mathbb{E}\left[ \log \left( 1-{\cal D}\left( {\cal R}\left( \tilde{X} \right) \right) \right) \right] \\
{\cal L}_{\cal R}=\mathbb{E}\left[ \| X-{\cal R}\left( \tilde{X} \right) \|^2 \right]
ここで$X$は正常画像,$\tilde{X}$はノイズを加えた正常画像を表します。
${\cal L}_{{\cal R}+{\cal D}}$は${\cal R}$の出力を${\cal D}$が見破れたかどうかを表します。
${\cal D}$はこれの最小化を目指し,${\cal R}$は逆に${\cal D}$を欺けるように最大化を目指します。
${\cal R}$は${\cal D}$を欺くだけではダメで,オリジナルに近い画像を復元できる必要があります。
このため,出力とオリジナルの画像が近くなるように${\cal L}_{\cal R}$も同時に最小化します。
異常検知
${\cal D}$の出力に応じて判定します。
出力値が0に近ければ正常,1に近ければ異常と判断します。
ただし,使うのは${\cal D}$だけではありません。${\cal R}$も判定に使うのがALOCCの特徴です。
${\cal R}$はノイズの乗った正常画像の復元のみを学習しているため,その他の画像が入ってくると上手く復元できません。
つまり,${\cal R}$には正常と異常の差異を強調する働きがあります。
したがって,画像$X$が正常かどうかは${\cal D}({\cal R}(\tilde{X}))$の値によって判断します。
実装
全体のコードはこちらです。
モデル
${\cal R}$はConvolutionを4層,Deconvolutionを4層重ねた構造です。
出力層では各画素値を$[0,1]$に収めるためにシグモイド関数を適用しました。
${\cal D}$はConvolutionを5層重ねた構造ですが,出力層で論文とは少し異なる実装をしています。
論文では${\cal D}$の出力はスカラー値でシグモイド関数を通して出力していましたが,今回はソフトマックス関数を通して2次元のベクトルを出力しています。
こうすることでクラス分類器と同じように扱えるので実装が少し簡単になります。
${\cal D},{\cal R}$共通で中間層の活性化関数はLeaky ReLUとし,各層の出力にBatch normalizationを入れています。
以下にモデル部分のコードを示します。
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import Variable, iterators, Chain, optimizers, report
from chainer.training import updaters, Trainer, extensions
class Discriminator(Chain):
def __init__(self):
super().__init__()
with self.init_scope():
kwds = {
"ksize": 4,
"stride": 2,
"pad": 1,
"nobias": True
}
N_CH = 16
self.conv1 = L.Convolution2D(1, N_CH, **kwds) # (14,14)
self.conv2 = L.Convolution2D(N_CH, N_CH*2, **kwds) # (7,7)
self.conv3 = L.Convolution2D(N_CH*2, N_CH*4, ksize=3, stride=1, pad=1, nobias=True) # (7,7)
self.conv4 = L.Convolution2D(N_CH*4, N_CH*8, ksize=3, stride=1, pad=0, nobias=True) # (5,5)
self.conv5 = L.Convolution2D(N_CH*8, 2, ksize=1, stride=1, pad=0)
self.bn1 = L.BatchNormalization(N_CH, eps=1e-5)
self.bn2 = L.BatchNormalization(N_CH*2, eps=1e-5)
self.bn3 = L.BatchNormalization(N_CH*4, eps=1e-5)
self.bn4 = L.BatchNormalization(N_CH*8, eps=1e-5)
def __call__(self, x):
h = F.leaky_relu(self.bn1(self.conv1(x)))
h = F.leaky_relu(self.bn2(self.conv2(h)))
h = F.leaky_relu(self.bn3(self.conv3(h)))
h = F.leaky_relu(self.bn4(self.conv4(h)))
h = self.conv5(h)
h = F.mean(h, axis=(2,3)) # global average pooling
return h
class Generator(Chain):
def __init__(self):
super().__init__()
with self.init_scope():
kwds = {
"ksize": 4,
"stride": 2,
"pad": 1,
"nobias": True
}
N_CH = 16
self.conv1 = L.Convolution2D(1, N_CH, **kwds) # (14,14)
self.conv2 = L.Convolution2D(N_CH, N_CH*2, **kwds) # (7,7)
self.conv3 = L.Convolution2D(N_CH*2, N_CH*4, ksize=3, stride=1, pad=1, nobias=True) # (7,7)
self.conv4 = L.Convolution2D(N_CH*4, N_CH*8, ksize=3, stride=1, pad=0, nobias=True) # (5,5)
self.deconv4 = L.Deconvolution2D(N_CH*8, N_CH*4, ksize=3, stride=1, pad=0, nobias=True) # (7,7)
self.deconv3 = L.Deconvolution2D(N_CH*4, N_CH*2, ksize=3, stride=1, pad=1, nobias=True) # (7,7)
self.deconv2 = L.Deconvolution2D(N_CH*2, N_CH, **kwds) # (14,14)
self.deconv1 = L.Deconvolution2D(N_CH, 1, ksize=4, stride=2, pad=1) # (28,28)
self.bn_conv1 = L.BatchNormalization(N_CH, eps=1e-5)
self.bn_conv2 = L.BatchNormalization(N_CH*2, eps=1e-5)
self.bn_conv3 = L.BatchNormalization(N_CH*4, eps=1e-5)
self.bn_conv4 = L.BatchNormalization(N_CH*8, eps=1e-5)
self.bn_deconv4 = L.BatchNormalization(N_CH*4, eps=1e-5)
self.bn_deconv3 = L.BatchNormalization(N_CH*2, eps=1e-5)
self.bn_deconv2 = L.BatchNormalization(N_CH, eps=1e-5)
def __call__(self, x):
h = F.leaky_relu(self.bn_conv1(self.conv1(x)))
h = F.leaky_relu(self.bn_conv2(self.conv2(h)))
h = F.leaky_relu(self.bn_conv3(self.conv3(h)))
h = F.leaky_relu(self.bn_conv4(self.conv4(h)))
h = F.leaky_relu(self.bn_deconv4(self.deconv4(h)))
h = F.leaky_relu(self.bn_deconv3(self.deconv3(h)))
h = F.leaky_relu(self.bn_deconv2(self.deconv2(h)))
h = F.sigmoid(self.deconv1(h))
return h
学習
手書き数字画像の'1'を正常として学習しました。
テスト時は'0'を異常データとして検出精度を評価します。
GANと同じで${\cal D},{\cal R}$を交互に更新していきます。
以下にパラメータ更新部分のコードを示します。
class GANUpdater(updaters.StandardUpdater):
def __init__(self, iterator, gen_opt, dis_opt, l2_lam, noise_std, n_dis=1, **kwds):
opts = {
"gen": gen_opt,
"dis": dis_opt
}
iters = {"main": iterator}
self.n_dis = n_dis
self.l2_lam = l2_lam
self.noise_std = noise_std
super().__init__(iters, opts, **kwds)
def get_batch(self):
x = self.get_iterator("main").next()
x = np.stack(x)
noise = np.random.normal(0, self.noise_std, size=x.shape).astype(np.float32)
x_noisy = np.clip(x+noise, 0.0, 1.0) # ノイズ付加
x = Variable(x)
x_noisy = Variable(x_noisy)
if chainer.config.user_gpu_mode:
x.to_gpu()
x_noisy.to_gpu()
return x, x_noisy
def update_core(self):
opt_gen = self.get_optimizer("gen")
opt_dis = self.get_optimizer("dis")
gen = opt_gen.target
dis = opt_dis.target
# update discriminator
# 本物に対しては1,偽物に対しては0を出すように学習
for i in range(self.n_dis):
x, x_noisy = self.get_batch()
x_fake = gen(x_noisy)
d_real = dis(x)
ones = dis.xp.ones(d_real.shape[0], dtype=np.int32)
loss_d_real = F.softmax_cross_entropy(d_real, ones)
d_fake = dis(x_fake)
zeros = dis.xp.zeros(d_fake.shape[0], dtype=np.int32)
loss_d_fake = F.softmax_cross_entropy(d_fake, zeros)
loss_dis = loss_d_real + loss_d_fake
dis.cleargrads()
loss_dis.backward()
opt_dis.update()
# update generator
# 生成した画像に対してDが1を出すようにする
x, x_noisy = self.get_batch()
x_fake = gen(x_noisy)
d_fake = dis(x_fake)
ones = dis.xp.ones(d_fake.shape[0], dtype=np.int32)
loss_gen = F.softmax_cross_entropy(d_fake, ones)
loss_gen_l2 = F.mean_squared_error(x, x_fake)
loss_gen_total = loss_gen + self.l2_lam*loss_gen_l2
gen.cleargrads()
dis.cleargrads()
loss_gen_total.backward()
opt_gen.update()
chainer.report({
"generator/loss": loss_gen,
"generator/l2": loss_gen_l2,
"discriminator/loss": loss_dis
})
学習率などの詳しい設定は設定ファイルを参照してください。
結果
テストデータとして'0'(異常), '1'(正常)の画像を使い,学習中の正解率とF値の推移をプロットしました。
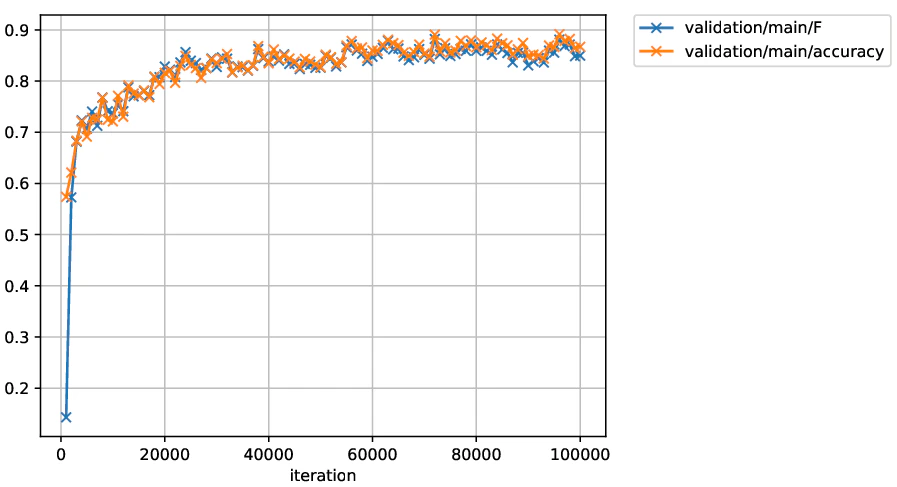
最終的に9割近い精度が出ています!
次に,ノイズを加えた画像を${\cal R}$に入力し,復元できているか確認しました。
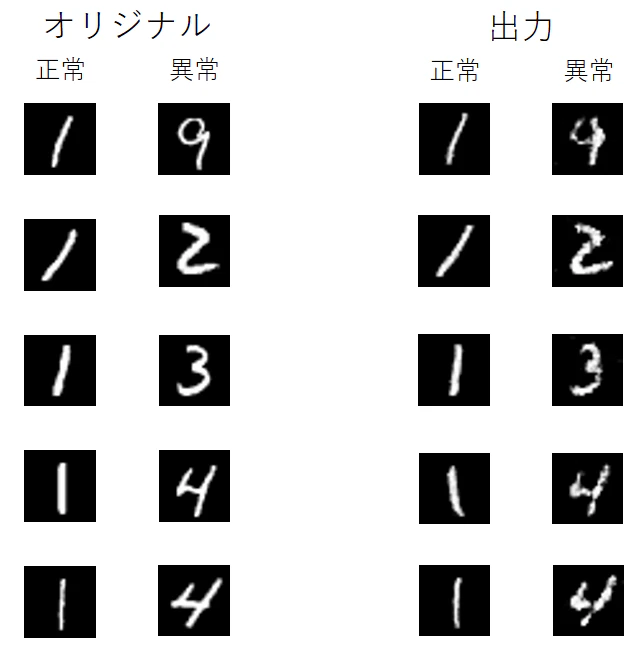
正常データである'1'はほぼ元通りに復元できていますが,その他の数字は学習していないのでガタガタになってうまく復元できていません。
確かに${\cal R}$を通すことで正常と異常の差が強調されていることがわかります。
おわりに
異常検知手法ALOCCを実装し,MNISTで試しました。
生成タスクではなく検出タスクにGANを利用するのは面白いと思いました。