0. はじめに
Deep Learningを活用した生成技術の一つに、GAN(Generative Adversarial Network)というものがあります。
これは、GeneratorとDiscriminatorという2つのネットワークを同時に学習させることによって、あたかも本物のようなダミーデータを生成する技術で、画像生成や文章生成、音声合成などに応用されています。
例えば以下の画像は、実際の海外セレブの顔写真を使ってモデルを学習し、実在しない人物の顔を生成した例です。

出典:https://arxiv.org/pdf/1710.10196.pdf
今回はこのGANを使って、歴代の元号を基に新元号を生成したら、どんな元号ができるか試してみました。
※ あくまでお遊びですので、ご理解の程よろしくお願いします。
1. 開発環境
学習を高速に行うため、GPUを無料で利用できるGoogle Colaboで開発を行いました。
Google Colaboの使い方は、以下のページなどが参考になります。
【秒速で無料GPUを使う】TensorFow(Keras)/PyTorch/Chainer環境構築 on Colaboratory
2. 元号画像の準備
GANの学習には、以下のような元号の文字画像を使用します。

このように文字の画像を使ってGANを学習させた場合、モデルは漢字の形そのものを模倣するようになるため、実在しない変な漢字が生成されてしまう可能性があります。
しかし学習がうまく進み、元の画像と見分けのつかないような画像を生成できるようになれば、実在する漢字に非常に近い文字が生成されるようになると考えられます。
このとき、GANでは複数の本物データと生成画像の差異を合計(平均)して誤差を計算するため、元号に多く使われている漢字(「永」、「元」など)を生成したほうがトータルの誤差が小さくなり、モデルはそのような漢字を優先的に生成するようになると予想されます。
すなわち、元号での頻出漢字が生成画像により出現しやすくなるということです。
また、元号のほとんどは漢字2文字であるため、1文字目の漢字と2文字目の漢字が別々に模倣されれば、これまでに無いような新たな組み合わせの漢字2文字(「平成」の平+「昭和」の和=「平和」など)が生成できるのではないかと思われます。
すなわち、歴代の元号の文字画像を使ってGANを学習することで、「実在する漢字を使った」、「より元号っぽい」、「新たな組み合わせの」元号が生成できるのではないかと考えました。
(実際はそんなに都合良く行くとは思えないですが・・)
それでは、実際に元号の文字画像を作成していきます。
2-1. 元号一覧の取得
初めに、国立公文図書館デジタルアーカイブから和暦元号の一覧を読み込みました。
このとき、Pandasのread_html関数を使用することで、Web上のテーブルをPandasのDataFrameに簡単に変換することができます。
また、昔の元号には漢字4文字のもの(「神護景雲」、「天平神護」など)が一部あるのですが、学習時にノイズになると考えられるため、今回は漢字2文字の元号のみに絞ることとしました。
絞り込みの結果、歴代の元号は全部で242通りとなりました。
2-2. フォントのダウンロード
上記の元号一覧を基に、PILライブラリを使用して文字画像を作成します。
ただし、PILのImageは標準で日本語出力に対応していないため、日本語フォントを別途用意して指定する必要があります。
複数のフォントを使用したほうが学習データに多様性が出て良いと思ったので、今回は以下の9つの漢字対応フォント(全てフリー)をダウンロードして使用しました。
参考までに、各フォントの「平成」の文字画像を載せておきます。

2-3. 元号画像の作成
日本語フォントが用意できたら、いよいよ元号の文字画像を作成します。
PILのImageDrawで画像を作成し、ImageFontで文字のフォントを指定した上で、ImageDraw.Draw.text関数を使用して文字を出力します。
参考:PILで日本語の文字を書く
上記9つのフォントそれぞれについて、全元号の画像(242×9=2178枚)を作成しました。
学習データの画像サイズは、大きければ大きいほど鮮明な画像を生成できますが、それだけ学習にかかる時間も増えることとなります。
今回は、生成画像の質と学習時間とのバランスを考えて、画像サイズを128×128としました。
作成した画像は、Google Colabo上の適当なフォルダ(datasets/gengo/など)にまとめて置いておきます。
3. GANの実行
ここ数年のGANの発展は目覚ましく、学習の安定化や生成データの多様化などを実現するために様々な手法が提案されていますが、今回はGANを使った画像生成の草分け的存在であるDCGANを使用したいと思います。
DCGANは、GeneratorとDiscriminatorにCNNを使用したモデルで、安定的に学習を行うための工夫が盛り込まれています。
参考:はじめてのGAN
より最新の手法と比較すると、モデルの構造が単純なため、比較的早く学習を行うことができます。
3-1. プログラムのダウンロード
DCGANのプログラムは、carpedm20さんが開発したTensorFlowのコードを使用させていただきました。
Google Colabo上で、以下のようにしてGithubからプログラムをダウンロードし、フォルダ内に移動します。
!git clone https://github.com/carpedm20/DCGAN-tensorflow/
os.chdir('DCGAN-tensorflow')
3-2. 学習
ソースコードの説明に従って、1で作成した元号画像のパスと画像サイズを指定し、学習を実行します。
python main.py --dataset=gengo --data_dir=../datasets/ --input_fname_pattern="*.png" --input_height=128 --output_height=128 --train
デフォルトでは、バッチサイズ64、エポック数25で学習が行われるようです。
実行する時間帯などにも寄るとは思いますが、私の環境では数分程度で学習が完了し、画像が生成されました。
3-3. 生成結果
学習完了後の生成画像は、以下のようになりました。

・・・何とも言えないですね。
一部「元」などの文字が生成されているように見えますが、全体的に漢字にすらなっていない画像が多いです。
GeneratorとDiscriminator
の損失は、以下のようになっていました。
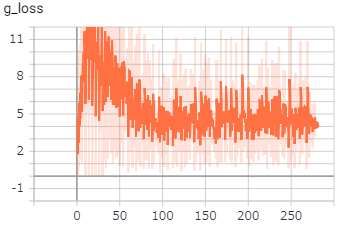
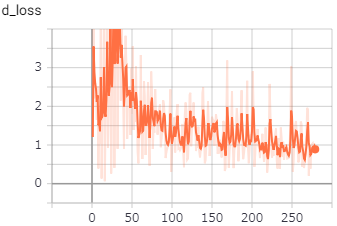
Discriminatorの損失が段々と下がり続けているので、学習が収束しきっていないのかもしれません。
4. 考察
画像生成がうまくいかなかった原因としては、以下のようなことが考えられます。
4-1. DCGANのネットワークが単純すぎる
DCGANは元々、学習が十分に安定しておらず、モードの崩壊(モデルが局所解に陥ったような状態になって、同じような画像ばかりが生成されてしまうこと)が起きやすいことが知られています。
上記の生成画像を見ると、明らかなモードの崩壊は起きていませんが、学習がうまく進んでいないような印象を受けます。
より複雑なモデル(SAGAN, PGGANなど)を使用すれば、学習が安定し、もう少しまともな漢字が生成できるかもしれません。
4-2. 漢字の形状が複雑すぎる
漢字は、数字やひらがな、カタカナ、アルファベットなどと比較して複雑な形状をしており、生成自体が難しいのではないかと思われます。
実際、GANで手書き数字(mnist)やカタカナを生成した例はあるようですが、漢字を生成した例はあまり無いようです。
また、例えば人の顔であれば、全画像に共通点(どの画像も目があって鼻があって・・など)がありますが、漢字にはそのような共通構造があまり無いため、上記のような何とも言えない字が生成されてしまったものと考えられます。
4-3. GANがタスクに向かない
これは身も蓋もない話ですが、今回のように「実在する漢字を使っていて、かつ入力データには存在しないような組み合わせの2文字を生成する」というタスクには、GANは向いていないのかもしれません。
たまたま「大」という字から「太」という字が生成されること等はあるかもしれませんが、実在する漢字の構造には限りがあるため、GANに自由に字を書かせると、入力データと全く同じ漢字が生成されるか、実在しない漢字が生成される可能性の方がはるかに高くなると思われます。
4-4. 画像データの使用
そもそも文字を画像として扱うという方法自体が、あまり良く無い可能性もあります。
画像データを使用する以外の方法として、テキストベースの予測を行うことも考えられます。
例えば、歴代の元号や一般的なコーパスを使用することで、元号に使われやすい漢字や、ある漢字と一緒に使われることの多い漢字(「安」と「明」は同じ文書に出現しやすい、など)を学習し、それら二つの漢字が繋がった新たな元号(「安明」)を生成できるのではないかと思いました。
しかし、私自身が自然言語処理の専門では無いことと、GANによる文章生成はまだ発展途上ということもあり、今回は試していません。
(どなたか知見のある方がいたら、試していただければと思います・・)
5. まとめ
残念ながら、今回はGANを使用して新しい元号を予測することができませんでした。
次回は、より安定的に高解像度画像を生成できるモデルを使用して、もう一度元号生成に挑戦してみたいと思います。
巷では、次の元号は「安久」になる等の噂もありましたが、一体どうなるのでしょうか?発表が待ち遠しいばかりです。