こんにちは。ITエンジニアのきゅうです。
前回、生成AIについて簡単に触れてみて、『Amazon Bedrock』の『Titan』を使うのが一番スマートではないかという結論に至りました。
ということで、今回はその『Amazon Bedrock』の『Titan』と連携して、生成AIに色々質問してみたいと思います。
今回作成するシステム構成図です。
※前回の記事をお読みでない方は、以下の記事を一読いただいてから、続きをお読みいただくことを推奨しております。
Amazon Bedrockに接続してみよう。
ということで、早速『Amazon Bedrock』に接続してみましょう。
1.Bedrockに利用申請する
使用するサービス:Amazon Bedrock
使用する機能:―
ということで『Amazon Bedrock』にアクセスしてみますが、こちらのサービスも「●●を作成」というボタンがありません。
ですので、事前設定みたいなものは必要ありませんが、事前に使用するLLMに対して利用申請する必要があります。
以下、利用申請手順です。
『使用を開始』をクリック
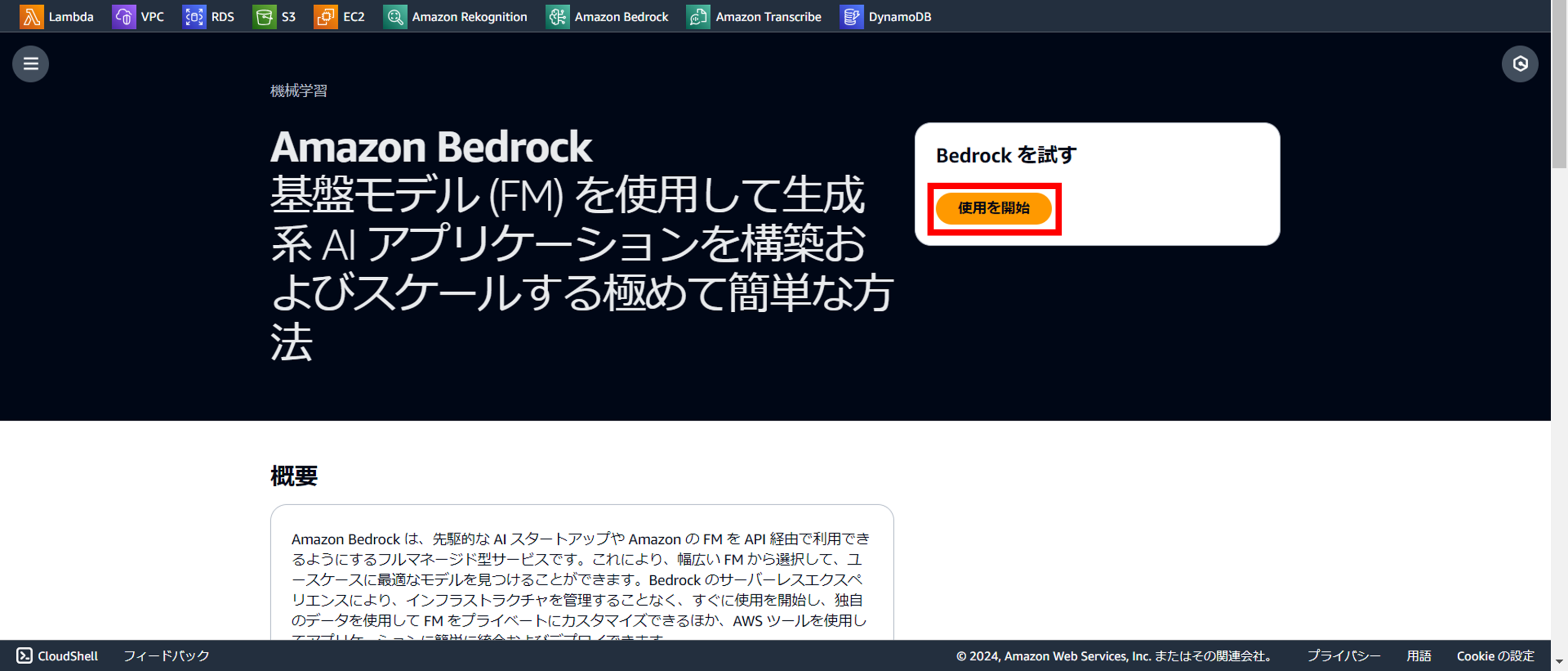
利用申請する基盤モデルを選択する
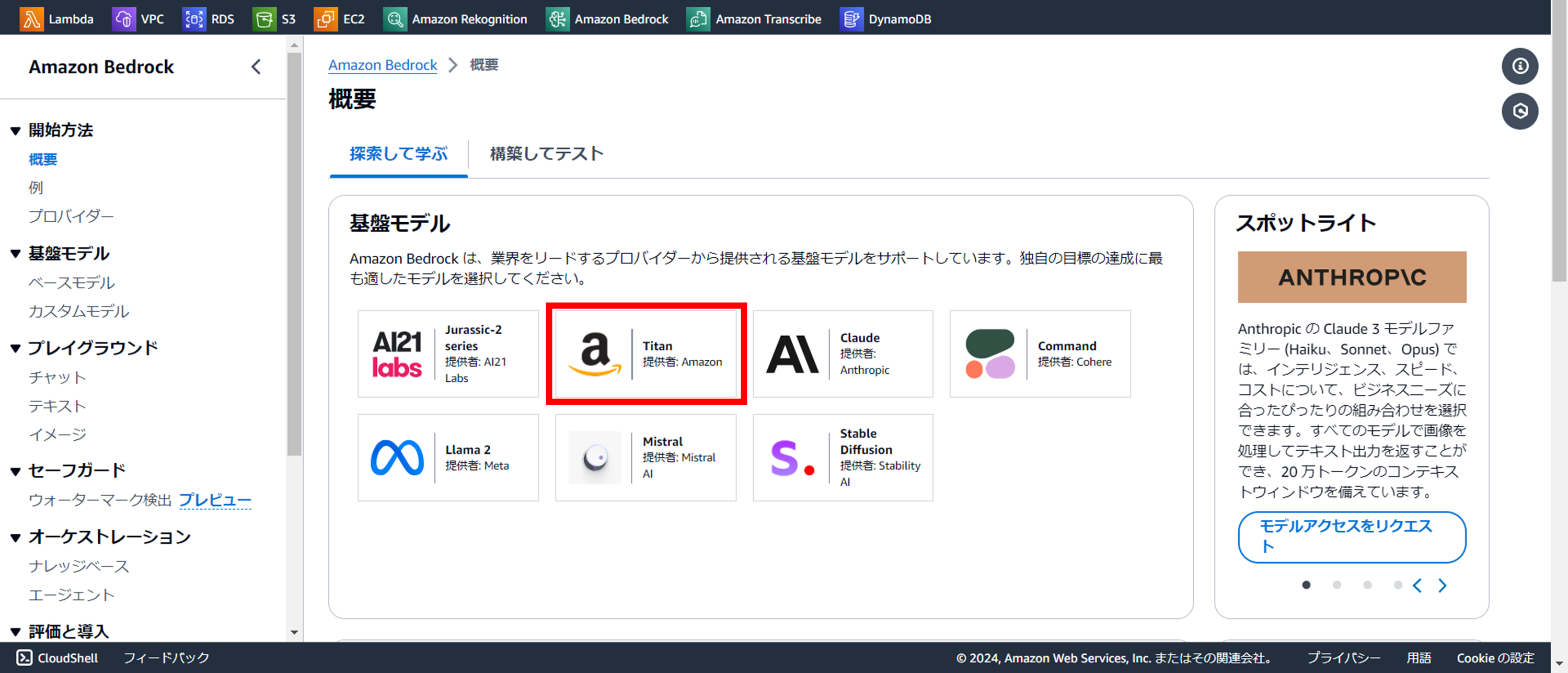
『モデルアクセスをリクエスト』をクリック
こちらのページでは詳しく基盤モデルについて紹介してくれておりますので、必要であれば目を通して頂き、ページ半ばにある『モデルアクセスをリクエスト』をクリックします。
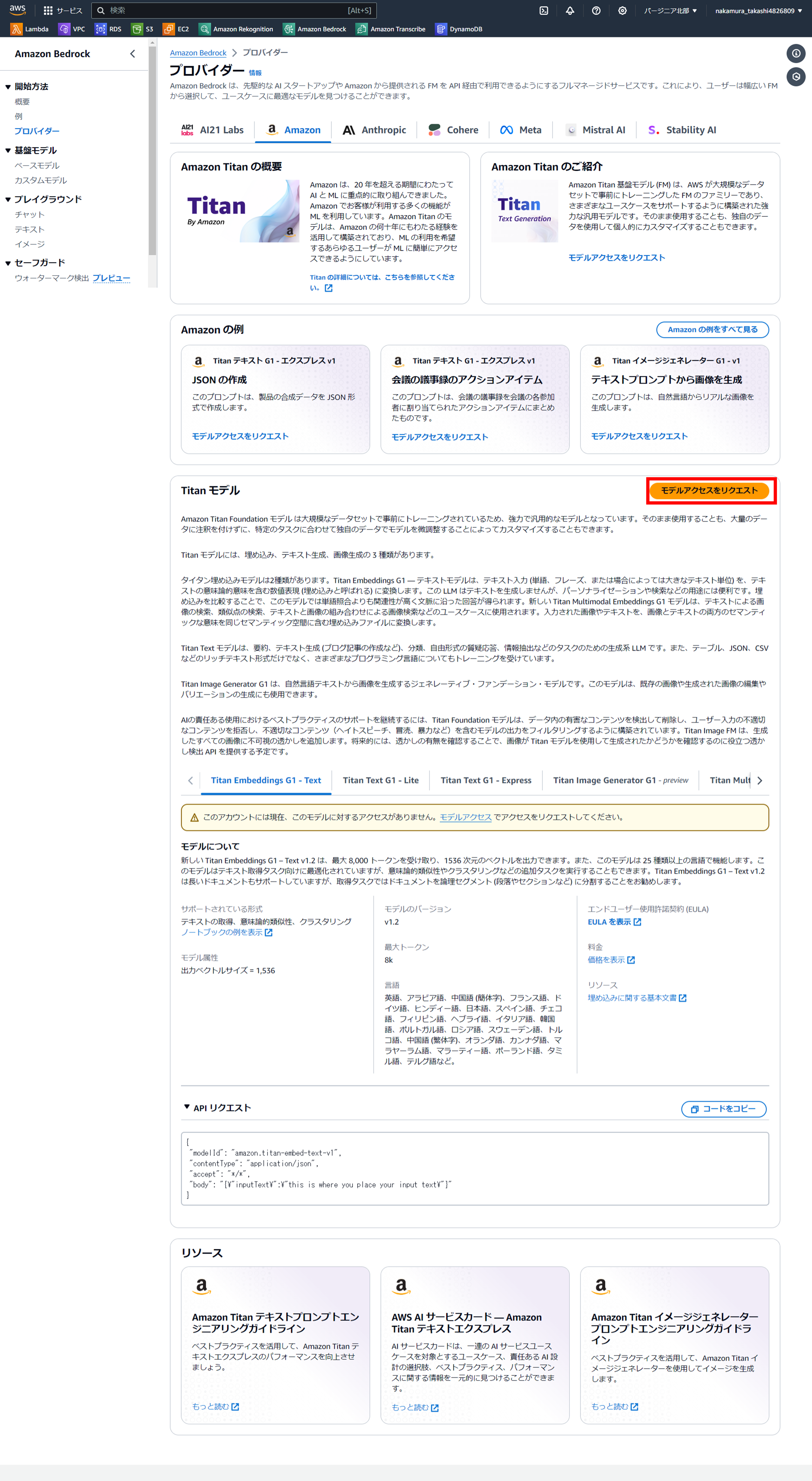
『モデルアクセスを管理』をクリックします。
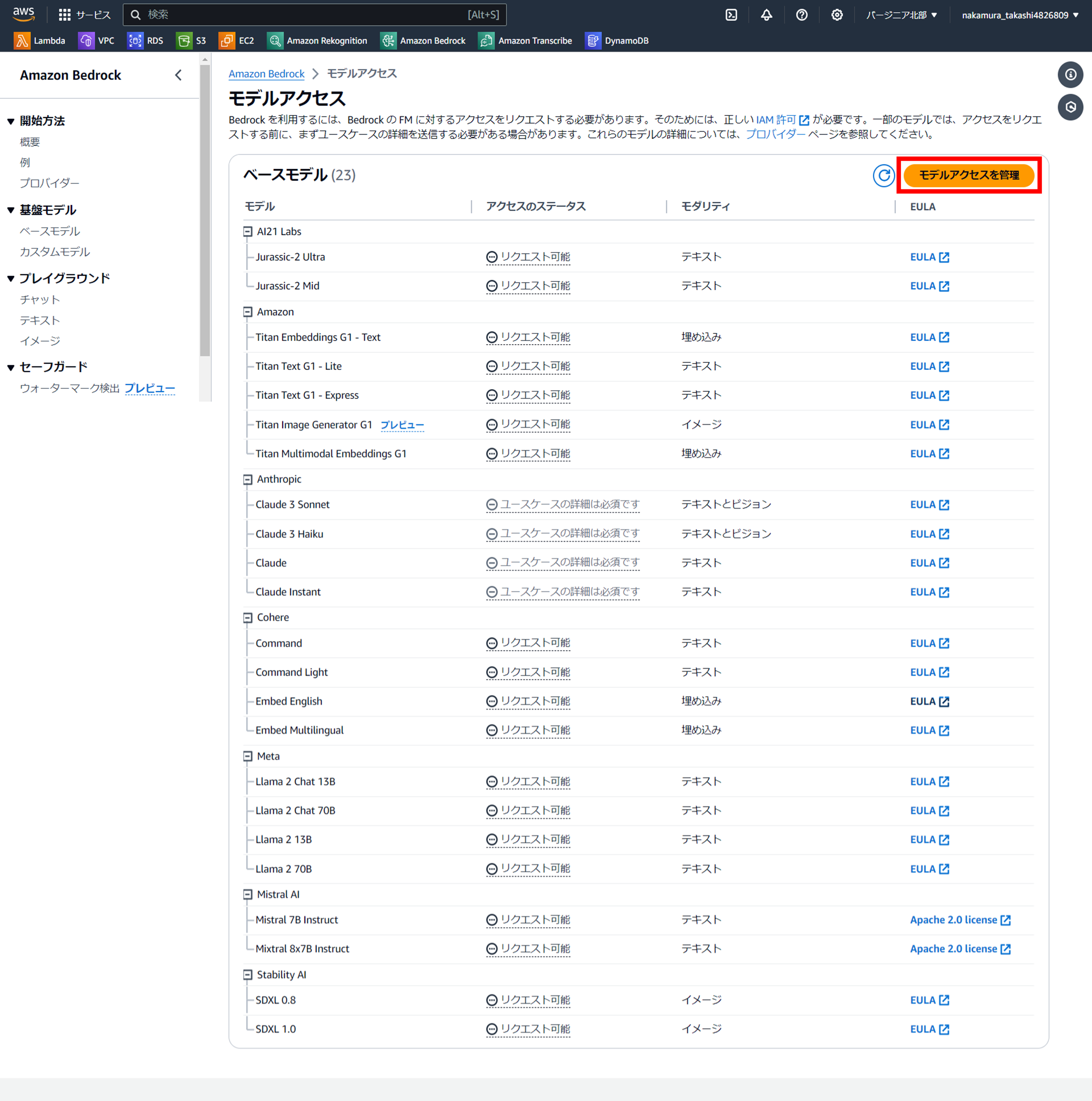
使用するモデルのチェックをつけ『モデルアクセスをリクエスト』をクリックします。
すると、画面表示はあまり変わりませんが、各モデルの横にチェックボックスが表示されますので、今回使用するモデルをチェックします。
とりあえずここでは『Amazon(Titan)』のモデルすべてに対してチェックを入れ、『モデルアクセスをリクエスト』をクリックしました。
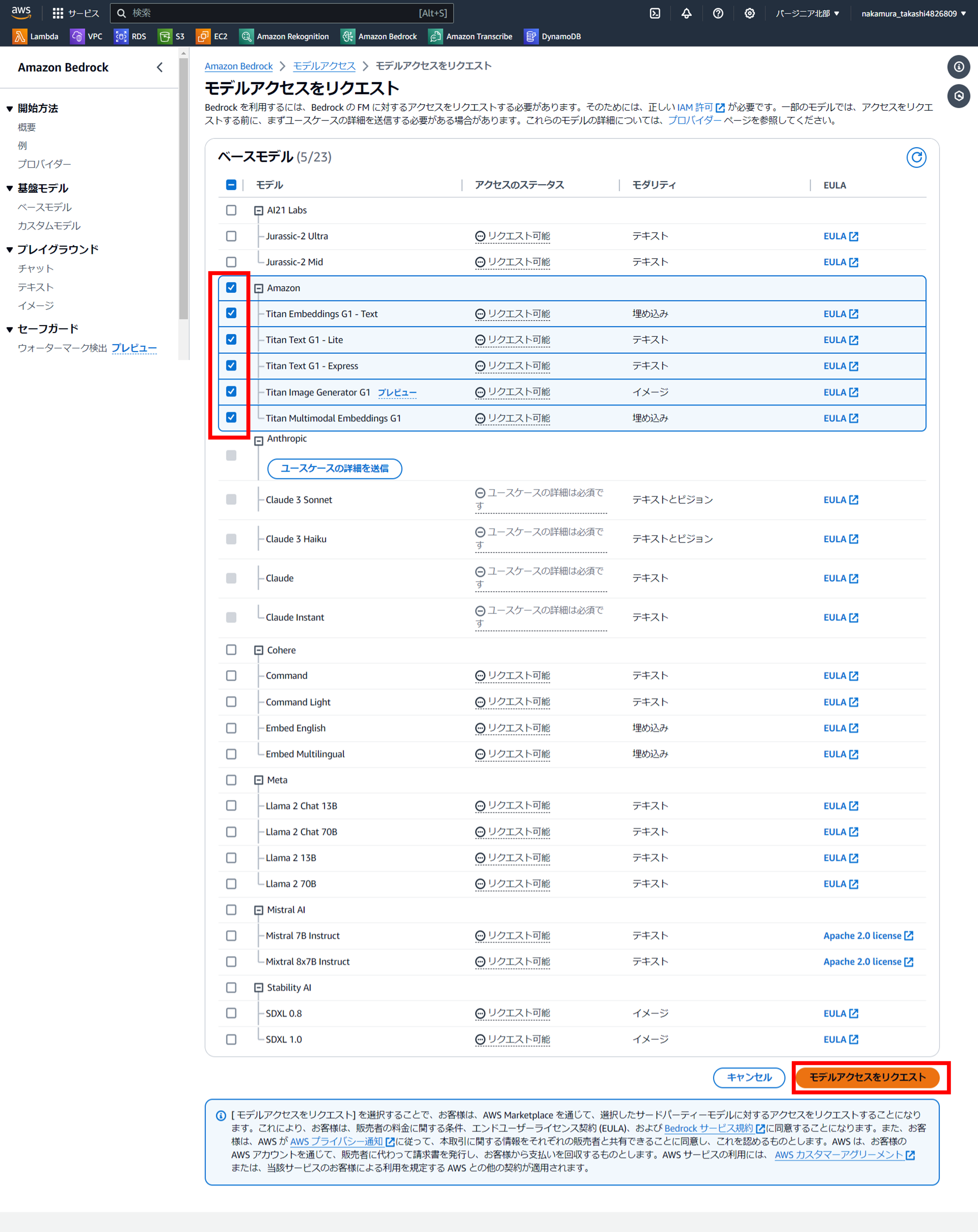
アクセス付与されたことを確認。
上記の『モデルアクセスをリクエスト』を押して一瞬で付与されました。
今回は『Amazon(Titan)』を選択したからかもしれませんので、他の基盤モデルを選択する場合は時間がかかるかもしれませんので、注意が必要ですよ!!
2.ロールの作成
使用するサービス:IAM
使用する機能:ロール
『ロールを作成』ボタンを押下
ユースケースで「Lambda」を選択
「信頼されたエンティティタイプ」で「AWS のサービス」を、
「ユースケース」で「Lambda」を選択し、「次へ」を押下
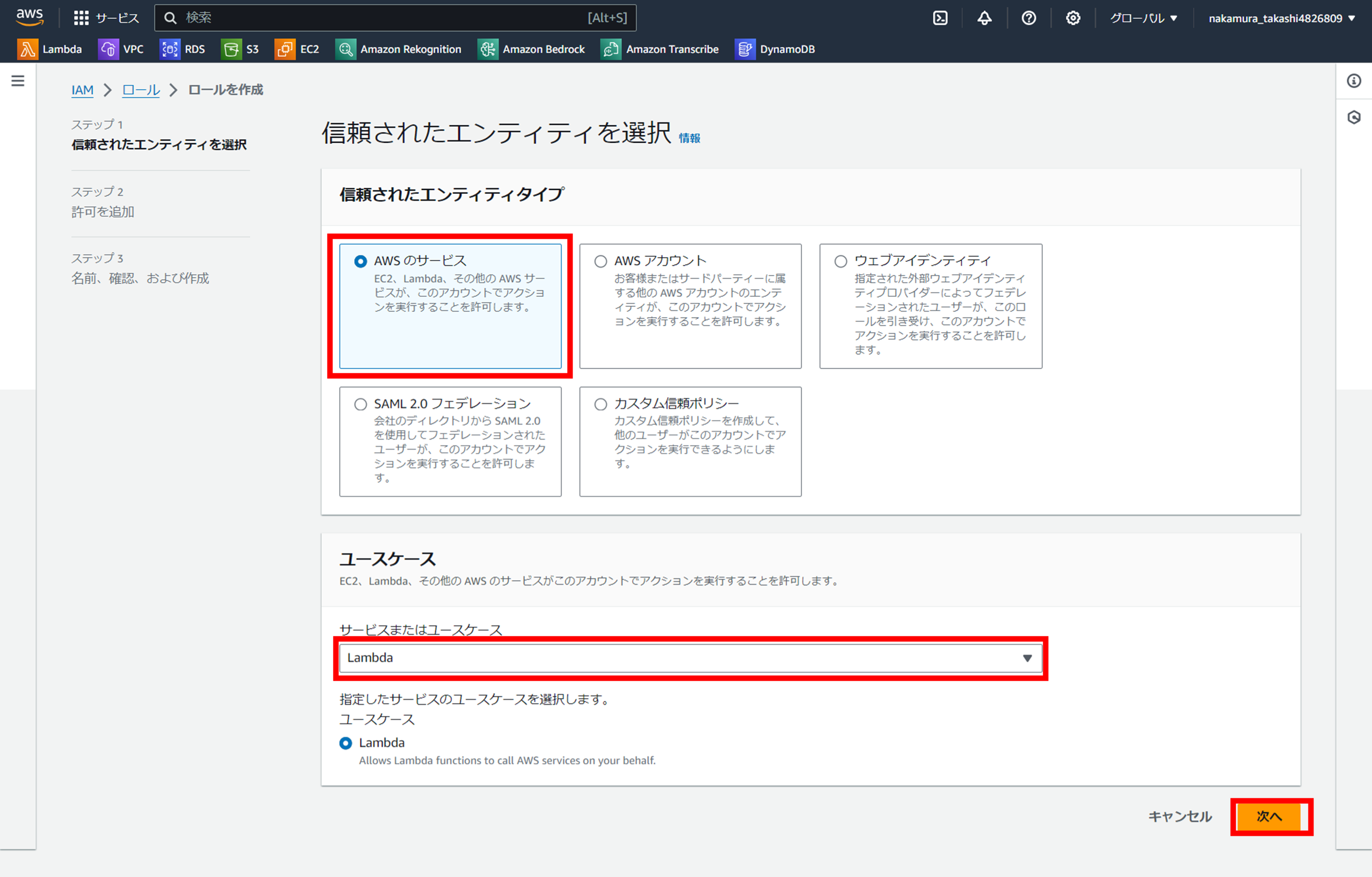
許可ポリシーでBedrockを選択
「許可ポリシー」の検索ボックスに「Bedrock」と入力し、
「AmazonBedrockFullAccess」と「AmazonBedrockReadOnly」を選択します。
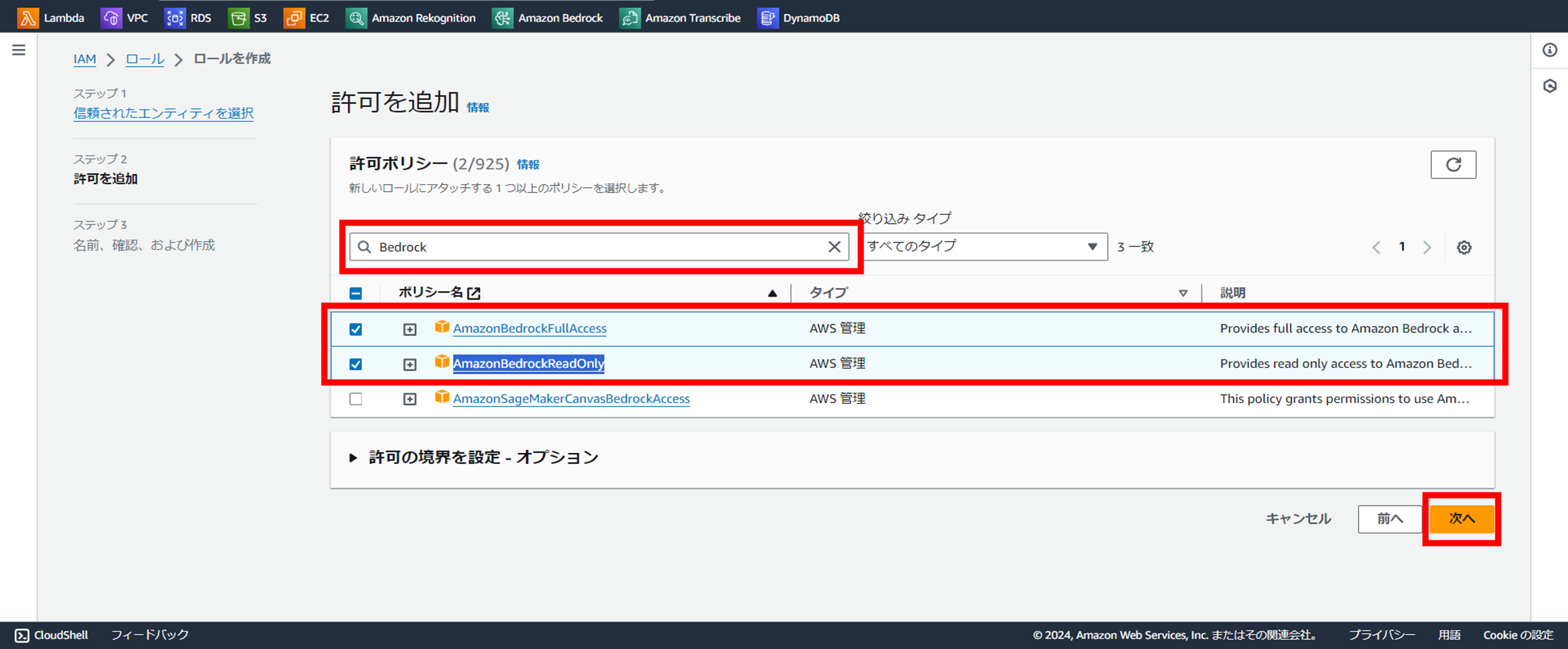
ロール名を任意でつける
ロール名を任意でつけて、一番下の『ロールを作成』を押下
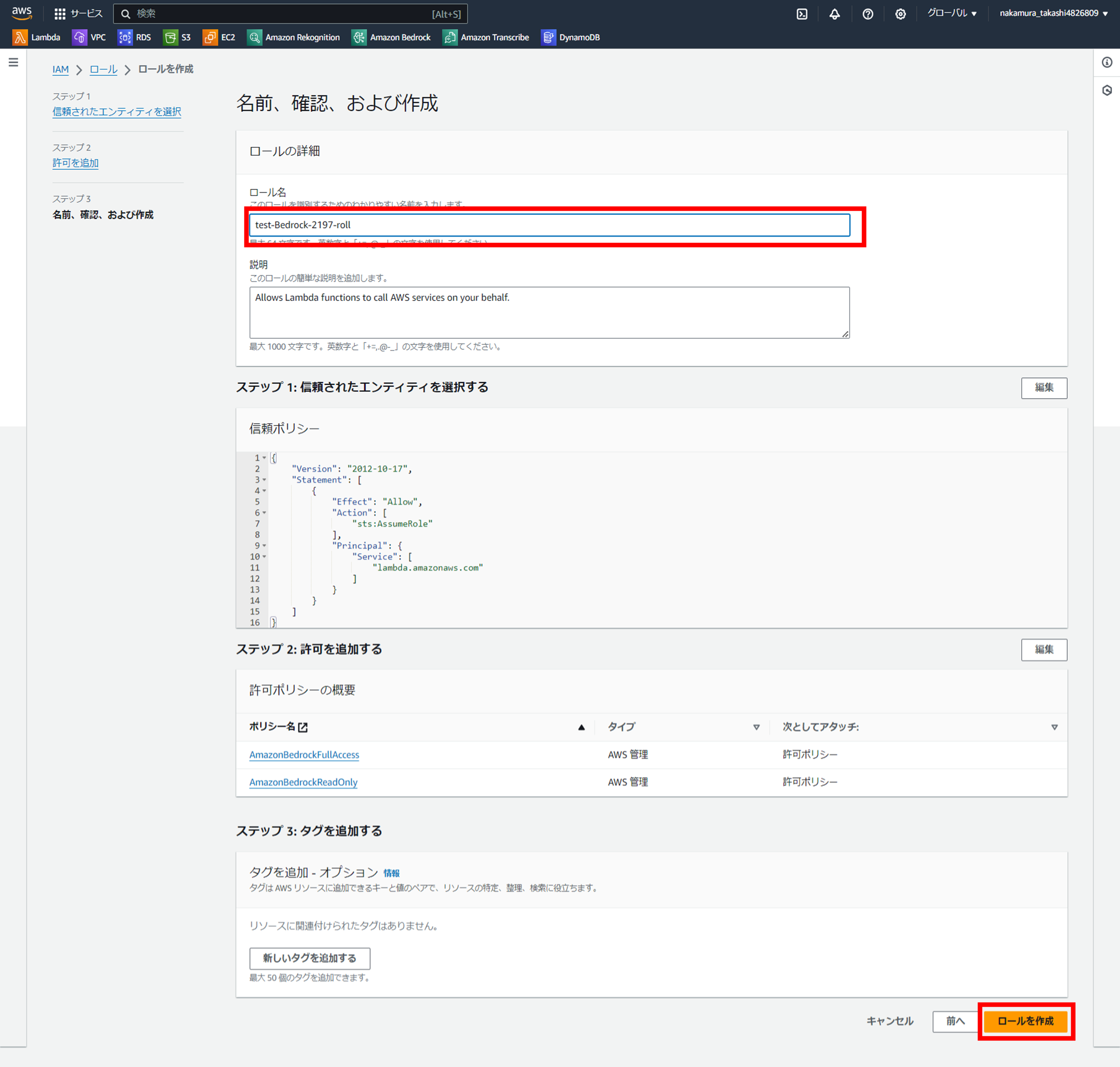
3.関数を作成する
使用するサービス:Lambda
使用する機能:関数
関数の設定をする
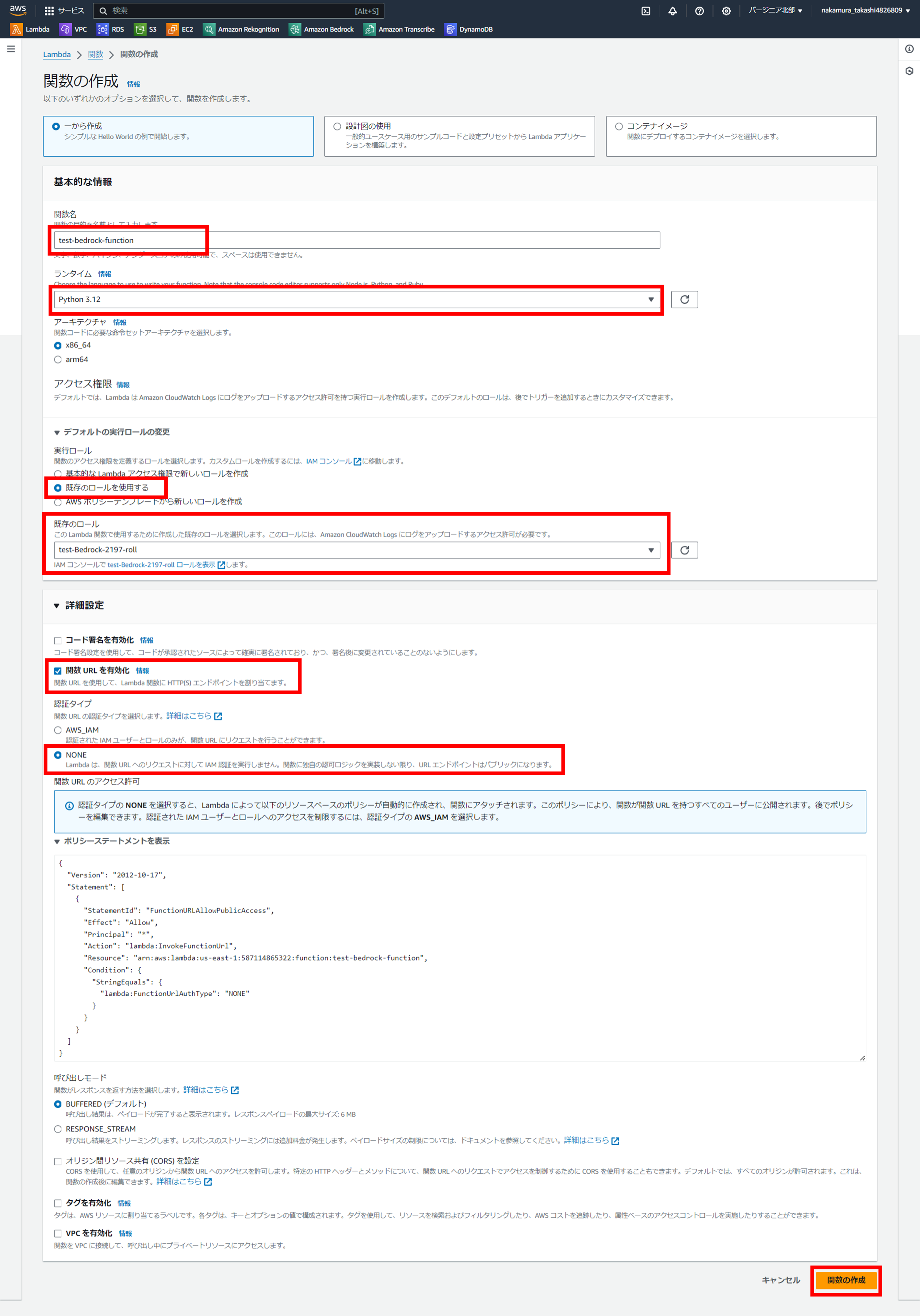
Lambdaのコンソールから『関数の作成』をクリックし、
設定画面に画面キャプチャーのように登録する。
そして、一番下の「関数の作成」をクリックします。
デフォルトの実行ロールの変更では「既存のロールを使用する」を選択し、上で選択したロールを選びます。
4.Lambdaのソースをコーディングする
使用するサービス:Lambda
使用する機能:関数
ソースコードのコピペ
-import json
-
-def lambda_handler(event, context):
- # TODO implement
- return {
- 'statusCode': 200,
- 'body': json.dumps('Hello from Lambda!')
- }
+import json
+import boto3
+
+
+### Amazon titan呼び出し関数
+### Args:model_id (str):基盤モデル(モデル)のID
+### body (str) : 基盤モデルに投げるbody
+def generate_text(model_id, body):
+
+ # bedrockを使う時のおまじない。
+ bedrock = boto3.client(service_name='bedrock-runtime')
+ accept = "application/json"
+ content_type = "application/json"
+
+ # bedrockの実行
+ response = bedrock.invoke_model(
+ body=body, modelId=model_id, accept=accept, contentType=content_type
+ )
+ # レスポンスデータから戻り値を取得
+ response_body = json.loads(response.get("body").read())
+
+ # エラーの処理
+ finish_reason = response_body.get("error")
+ if finish_reason is not None:
+ raise ImageError(f"Text generation error. Error is {finish_reason}")
+
+ return response_body
+
+
+
+def lambda_handler(event, context):
+
+ try:
+ # bedrockで使用する基盤モデルの指定
+ # 今回はAmazonのtitanを選択。
+ model_id = 'amazon.titan-text-express-v1'
+
+ # プロンプトの設定
+ prompt = """Amazon Bedrockがどのようなサービスなのか、説明してください"""
+
+ # jsonデータへ変換
+ body = json.dumps({
+ "inputText": prompt,
+ "textGenerationConfig": {
+ "maxTokenCount": 4096,
+ "stopSequences": [],
+ "temperature": 0,
+ "topP": 1
+ }
+ })
+
+ # 『Amazon titan呼び出し関数』の呼び出し
+ response_body = generate_text(model_id, body)
+ print(f"Input token count: {response_body['inputTextTokenCount']}")
+
+ for result in response_body['results']:
+ print(f"Token count: {result['tokenCount']}")
+ print(f"Output text: {result['outputText']}")
+ print(f"Completion reason: {result['completionReason']}")
+
+ except ClientError as err:
+ message = err.response["Error"]["Message"]
+ logger.error("A client error occurred: %s", message)
+ print("A client error occured: " +
+ format(message))
+ except ImageError as err:
+ logger.error(err.message)
+ print(err.message)
+
+ else:
+ print(
+ f"Finished generating text with the Amazon &titan-text-express; model {model_id}.")
+
+
+ return {
+ 'statusCode': 200,
+ 'body': json.dumps('Hello from Lambda!')
+ }
↓↓↓ コピー用です ↓↓↓
import json
import boto3
### Amazon titan呼び出し関数
### Args:model_id (str):基盤モデル(モデル)のID
### body (str) : 基盤モデルに投げるbody
def generate_text(model_id, body):
# bedrockを使う時のおまじない。
bedrock = boto3.client(service_name='bedrock-runtime')
accept = "application/json"
content_type = "application/json"
# bedrockの実行
response = bedrock.invoke_model(
body=body, modelId=model_id, accept=accept, contentType=content_type
)
# レスポンスデータから戻り値を取得
response_body = json.loads(response.get("body").read())
# エラーの処理
finish_reason = response_body.get("error")
if finish_reason is not None:
raise ImageError(f"Text generation error. Error is {finish_reason}")
return response_body
def lambda_handler(event, context):
try:
# bedrockで使用する基盤モデルの指定
# 今回はAmazonのtitanを選択。
model_id = 'amazon.titan-text-express-v1'
# プロンプトの設定
prompt = """Amazon Bedrockがどのようなサービスなのか、説明してください"""
# jsonデータへ変換
body = json.dumps({
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 4096,
"stopSequences": [],
"temperature": 0,
"topP": 1
}
})
# 『Amazon titan呼び出し関数』の呼び出し
response_body = generate_text(model_id, body)
print(f"Input token count: {response_body['inputTextTokenCount']}")
for result in response_body['results']:
print(f"Token count: {result['tokenCount']}")
print(f"Output text: {result['outputText']}")
print(f"Completion reason: {result['completionReason']}")
except ClientError as err:
message = err.response["Error"]["Message"]
logger.error("A client error occurred: %s", message)
print("A client error occured: " +
format(message))
except ImageError as err:
logger.error(err.message)
print(err.message)
else:
print(
f"Finished generating text with the Amazon &titan-text-express; model {model_id}.")
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
5.ソースの実行
早速テストを設定して、実行しました!!
が、下記のような『Task timed out after 3.01 seconds』というエラーが発生しました。。。
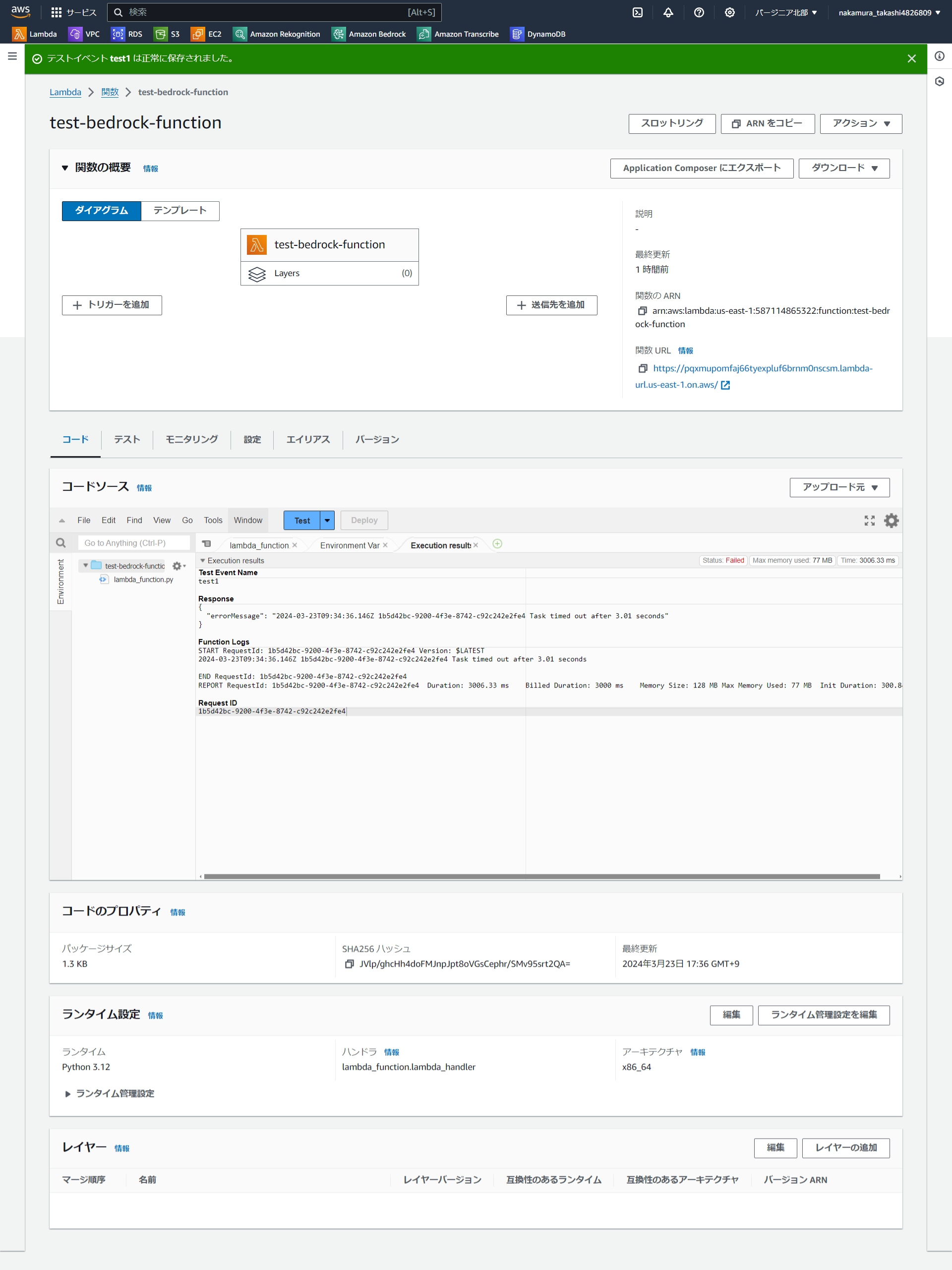
6.タイムアウト設定を延ばす
とりあえず、1分にタイムアウト設定を変更してみました。
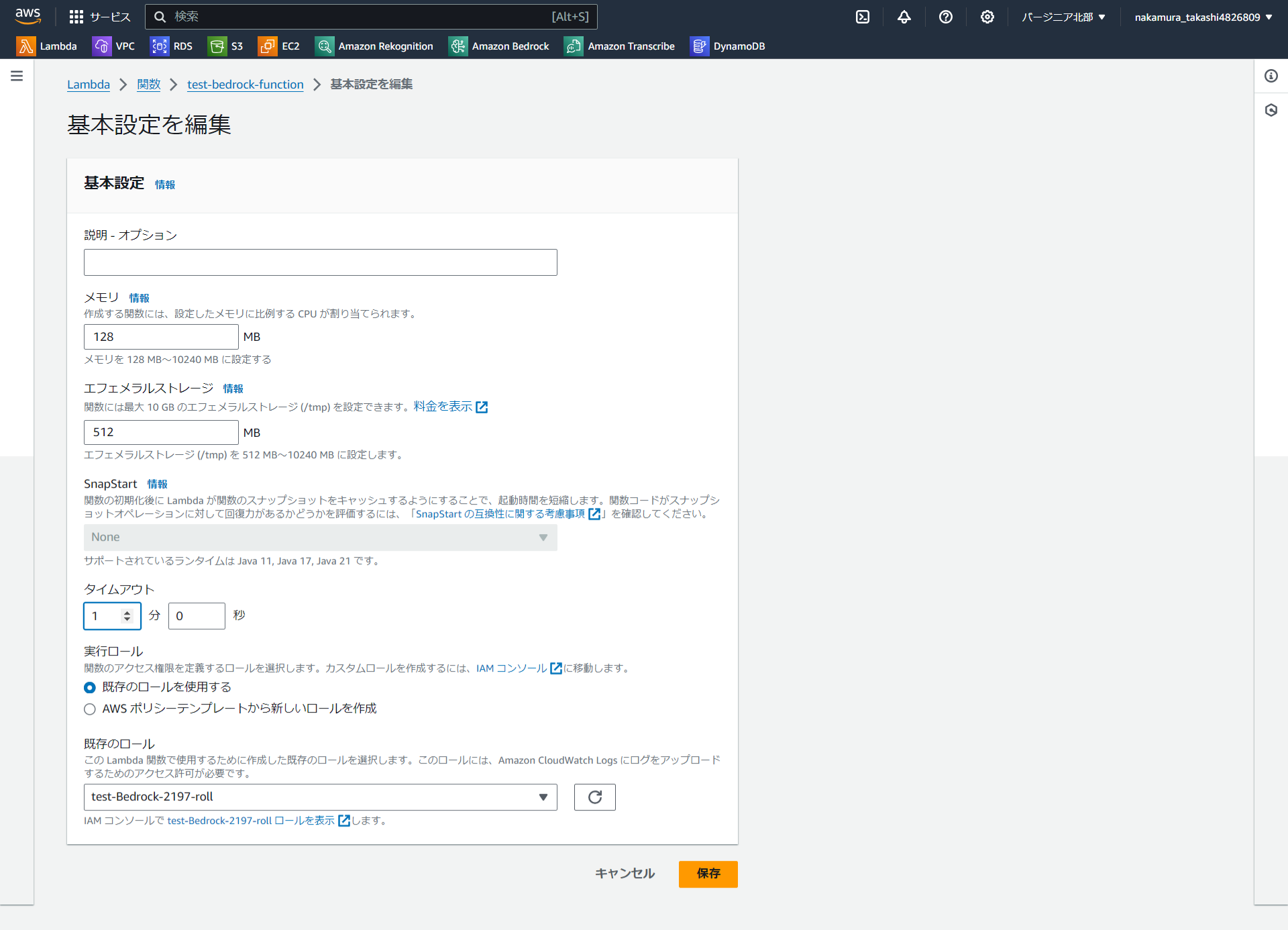
7.実行成功!!
はい、ということで実行成功しました!!
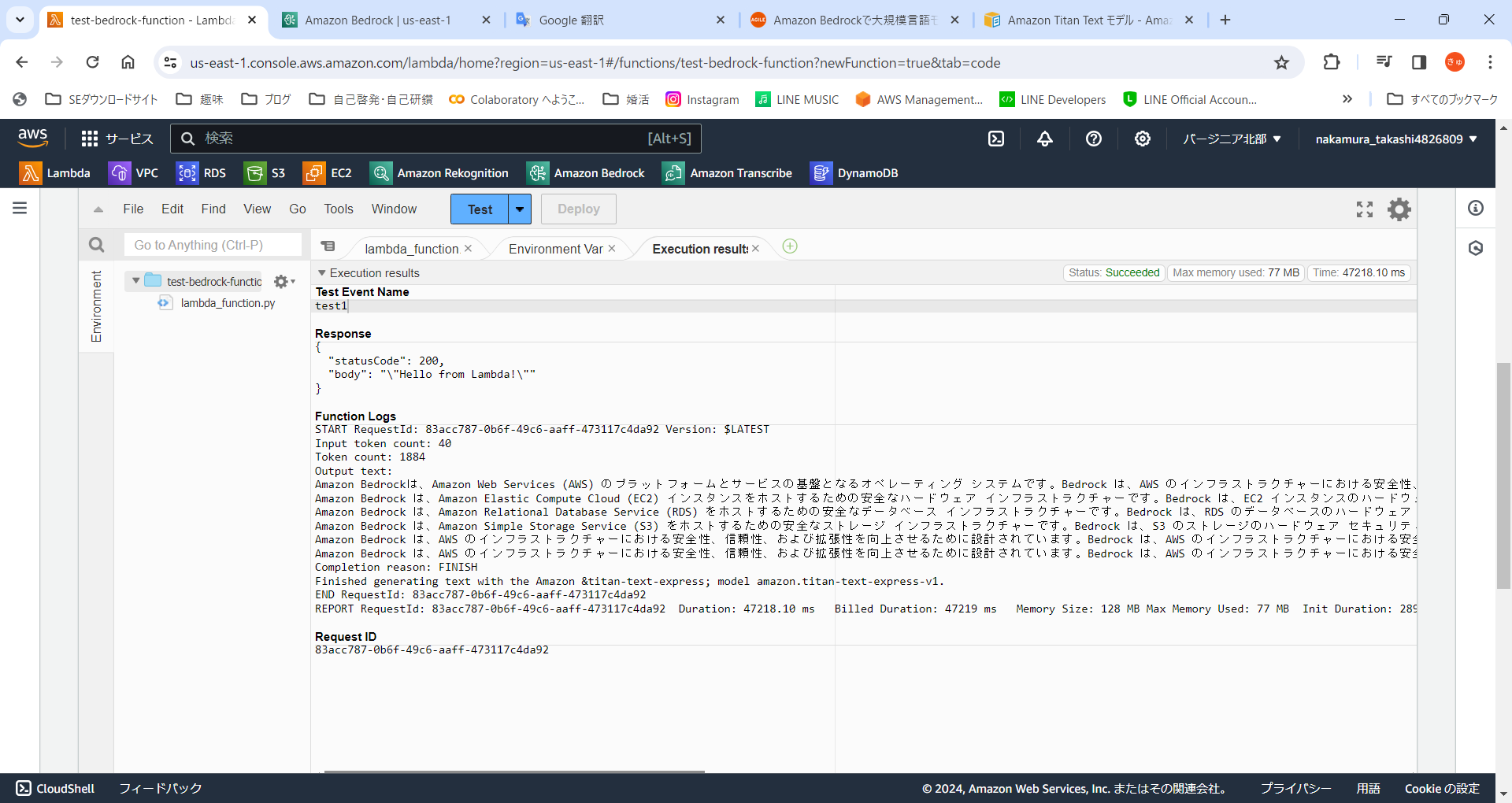
『Amazon Bedrockがどのようなサービスなのか、説明してください』という質問に対して以下の5つの回答を頂きました。。。
* Amazon Bedrockは、Amazon Web Services (AWS) のプラットフォームとサービスの基盤となるオペレーティング システムです。Bedrock は、AWS のインフラストラクチャーにおける安全性、信頼性、および拡張性を向上させるために設計されています。
* Amazon Bedrock は、Amazon Elastic Compute Cloud (EC2) インスタンスをホストするための安全なハードウェア インフラストラクチャーです。Bedrock は、EC2 インスタンスのハードウェア セキュリティ、メンテナンス、およびアップグレードを管理するためのツールとサービスを提供します。Bedrock は、EC2 インスタンスのハードウェア インフラストラクチャーの問題を軽減し、管理を容易にするために、リソースの管理、メンテナンス、およびアップグレードの自動化をサポートします。
* Amazon Bedrock は、Amazon Relational Database Service (RDS) をホストするための安全なデータベース インフラストラクチャーです。Bedrock は、RDS のデータベースのハードウェア セキュリティ、メンテナンス、およびアップグレードを管理するためのツールとサービスを提供します。Bedrock は、RDS のデータベースの問題を軽減し、管理を容易にするために、リソースの管理、メンテナンス、およびアップグレードの自動化をサポートします。
* Amazon Bedrock は、Amazon Simple Storage Service (S3) をホストするための安全なストレージ インフラストラクチャーです。Bedrock は、S3 のストレージのハードウェア セキュリティ、メンテナンス、およびアップグレードを管理するためのツールとサービスを提供します。Bedrock は、S3 のストレージの問題を軽減し、管理を容易にするために、リソースの管理、メンテナンス、およびアップグレードの自動化をサポートします。
* Amazon Bedrock は、AWS のインフラストラクチャーにおける安全性、信頼性、および拡張性を向上させるために設計されています。Bedrock は、AWS のインフラストラクチャーにおける安全性と信頼性を向上させるために、ハードウェア セキュリティ、データベースのハードウェア セキュリティ、およびストレージのハードウェア セキュリティを強化します。Bedrock は、AWS のインフラストラクチャーにおける拡張性を向上させるために、インスタンスの管理とアップグレードを容易にするために、ツールとサービスを提供します。
合って・・・いるのか??笑笑
というこで、もう少し分かりやすい質問に・・・
「ロサンゼルスの観光スポットを教えてください。」
という質問に変更した所、
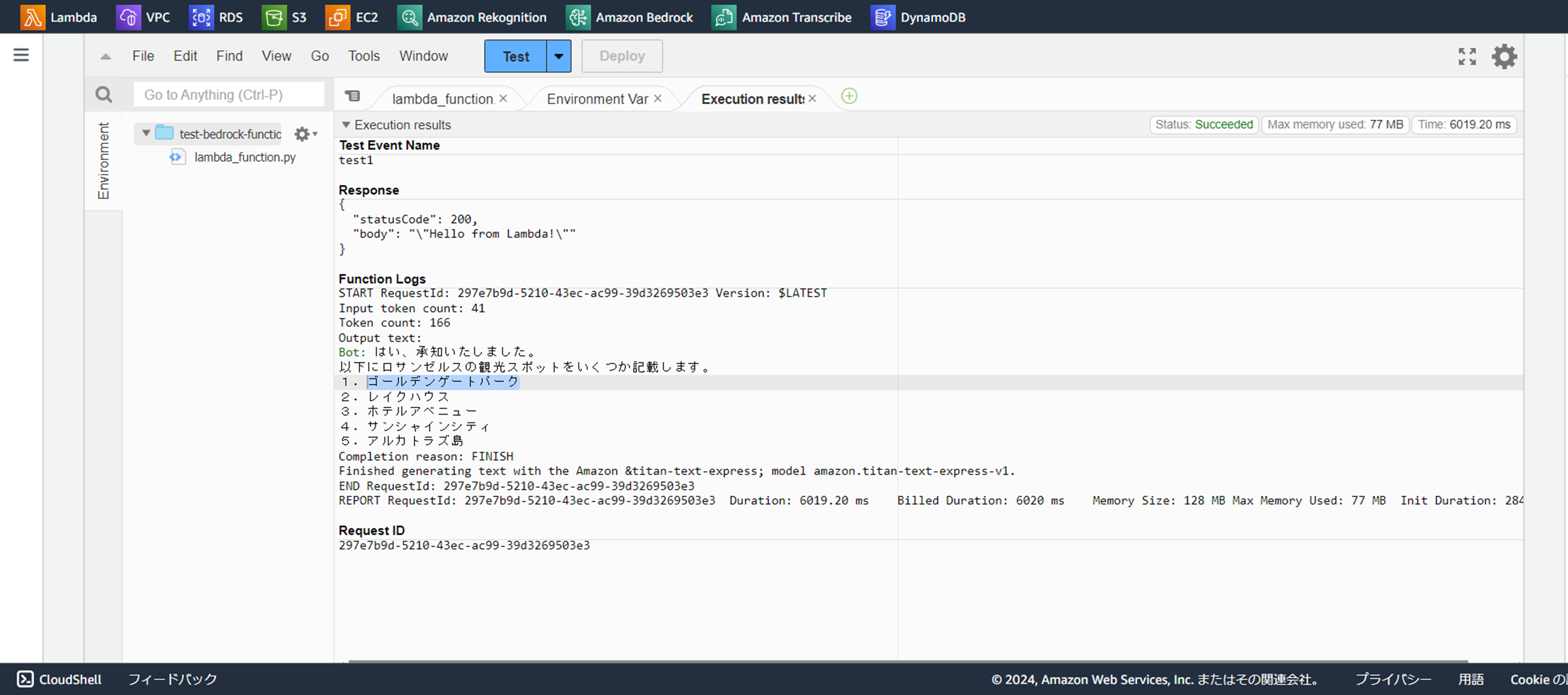
Output text:
Bot: はい、承知いたしました。
以下にロサンゼルスの観光スポットをいくつか記載します。
1.ゴールデンゲートパーク
2.レイクハウス
3.ホテルアベニュー
4.サンシャインシティ
5.アルカトラズ島
と返答があったので、良さそうです。。。
ちなみに、最初の質問の返答には47秒かかりましたが、ロサンゼルスの観光スポットを聞いた質問は6秒ほどで返ってきたので、質問の難易度でレスポンスの速さが変わってきそうですね。。。
補足
ちなみに、今回はソースコードで基盤モデルを『model_id = 'amazon.titan-text-express-v1'』と指定しましたが、画像生成をしたい場合は『model_id = 'amazon.titan-image-generator-v1'』と変更し、bodyの内容を変更すると画像生成も行うことが出来ます。
ちなみに『body』の各パラメータの説明は以下です。
* temperature :レスポンスのランダム性を減らすには、値を低く設定します。(デフォ:0.0、0.0~1.0で選択)
* topP :低い値を使用すると、可能性の低いオプションを無視し、レスポンスの多様性を低下させます。(デフォ:1.0)
* maxTokenCount:レスポンスで生成するトークンの最大数を指定します。(デフォ:512、Max:8,000)
最後に
はい、ということで、今回はここまでとなります。
次回は上記のtitanに対して、「ファインチューニング」「継続的な事前学習」「RAG」をして、カスタマイズしたい気持ちもありますが、ハッカソンの短い期間中にそこまでやる時間を考えると、難しい所があるので、それよりも『プロンプトチューニング』を行った方が良いと思いますので、一旦は、生成AIはここまでとし、別の技術について触れたいなぁと考えております。
(いずれかはプロンプトチューニングなどにも触れると思いますが。。。)
最後までお読みいただきありがとうございました。