はじめに
こんにちは!ひさふるです。
生成AIの中でも推論モデルってありますよね?
OpenAIのo1-previewによって一気に有名になり、現在ではGPT-5にも推論機能が統合されるなど、すっかり当たり前の存在になりました。
私は今まで「よく考えてくれる頭の良いモデルなんだなぁ」と思って知ったかぶりをしていましたが、いざ他人に説明しようとすると...全然仕組みをわかっていなかったんですよね。
そこで今回は、「推論モデルって何?」という質問にちゃんと解答できるようになるために、仕組みから完全に推論モデルを理解していこうと思います。
そもそも"生成AI"って何...?
大事な前提として、"生成AI"や"LLM"という言葉を正しく理解するところから始めましょう。(何を言いたいかわかる方は飛ばしていただいてOKです!)
まず、現在ではテキストの入出力により対話できるモデル(LLM)のことを生成AIと呼ぶことが多いですが、実際はもう少し広い意味を持ちます。
"生成AI"は、LLMを指すことが多い?
昨今のAIに関連する単語を図にまとめてみました。一旦、これを見ていただくほうが理解が早い気がします。
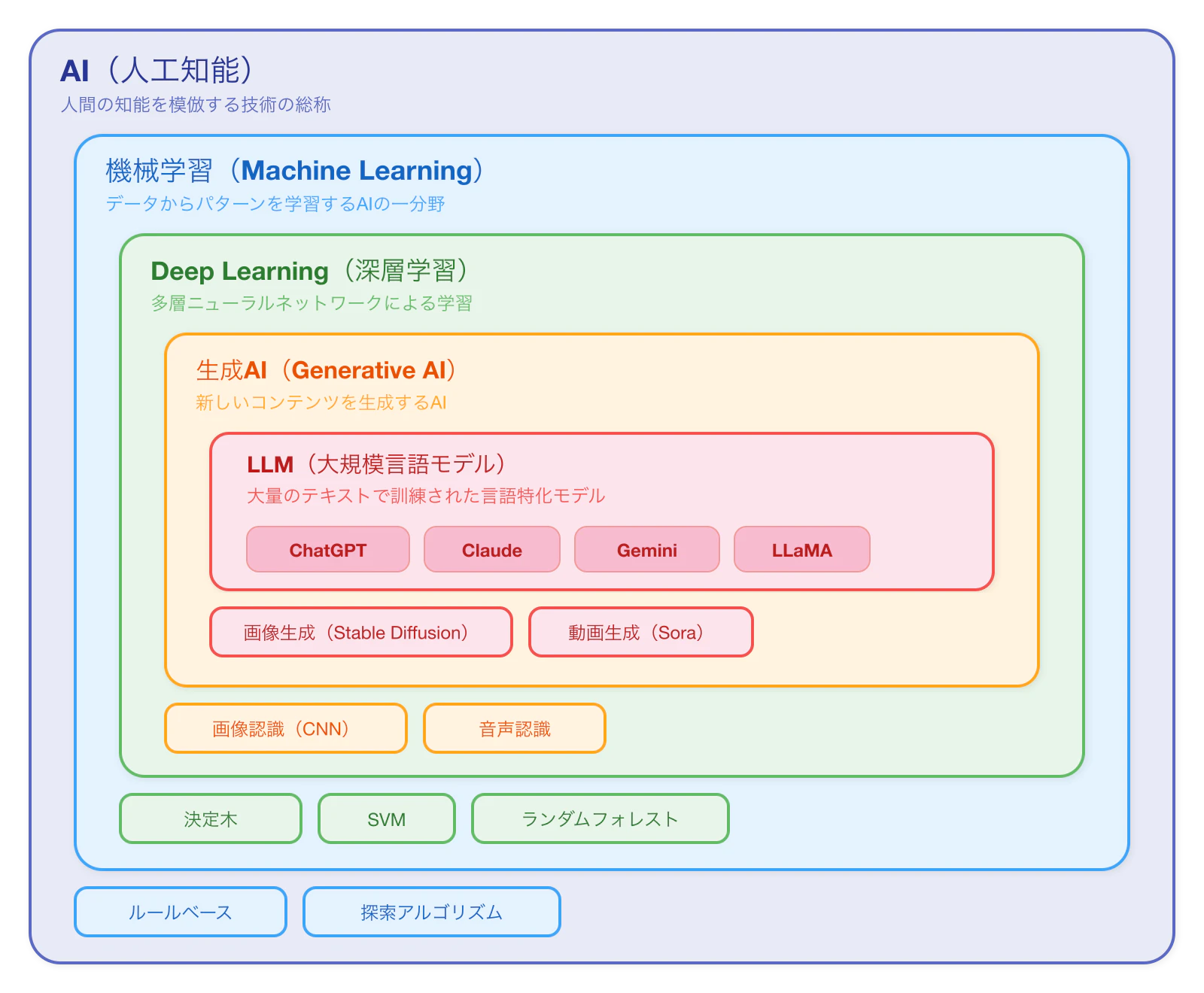
まず、単なるAIという言葉が指す範囲は非常に広いです。というか、指す範囲が広すぎて人によって定義がまちまちになっています。
AIを達成する手法の1つとして、機械学習があります。機械学習は、その名の通り何らかの判断基準をモデルに学習させる手法を言います。
機械学習は決定木やSVMなど様々な種類がありますが、最も有名な手法にニューラルネットワークがあり、その中間層を複数重ねた(層が深い)ニューラルネットをDeep Learning、深層学習と言います。
Deep Learningは画像認識等でも非常に高いスコアを残していますが、画像やテキストの生成にも応用されるようになりました。
これらの何らかのコンテンツを生成するモデルを総称して、生成AIと呼ぶのです。
その中でも、大規模なテキストデータで学習された言語モデルがLLM(Large Language Model: 大規模言語モデル)です。ChatGPTやGeminiもLLMの一種です。
よって、最近は単にAIや生成AIと呼ばれることが多いですが、実態としてはLLMを指していることが非常に多いんですよね。
生成AIは何らかのコンテンツを生成できるモデルのこと
一般的にテキスト入出力を行うLLMを指していることが多い
補足①:ChatGPTとかはテキスト以外も扱えるけど...?
LLMは基本的にはテキストを入力しテキストを出力するものですが、ChatGPT等は画像やファイルを入力したり、逆に画像を出力することも出来ていますよね?
これは、モデル自体がマルチモーダルの入出力に対応している場合と、外部ツールやモデルを使って擬似的に入出力を行っているパターンが存在します。
| 方法 | 説明 |
|---|---|
| マルチモーダル対応のモデル | 一部のモデルは、画像や動画、音声などをそのまま入力し、理解する機能を持っている |
| 外部ツール/モデルを使っている場合 | ・モデルで対応できない形式のファイルは、外部ツールによってテキストに変換することで、間接的に内容を把握する ・テキスト以外の出力をする場合は、別の画像生成モデルをツールとして呼び出し、擬似的に画像を出力している |
一部のモデルはマルチモーダル対応となっており、モデルが直接画像や音声を理解できます。
GPT-5系やClaude 4系は画像入力にネイティブ対応しており、Gemini系は画像に加えて音声・動画もネイティブで扱えるなど、モデルによって対応コンテンツに違いがあります。
それ以外のコンテンツはどうしているのかと言えば、それぞれ専用ツールを使ってテキストや画像などモデル自体が対応している形式に変換した上で、入力しています。
出力に関しても、最近は画像やzipファイルなど様々な形式を出してくれますが、これは別の画像生成モデルを呼び出したりプログラムを実行してファイルを作成することで、間接的に出力するようになっています。
そもそも"ニューラルネットワーク"って...?
先程、生成AIはLLMであり、Deep Learningという手法が使われているというところまで説明しました。
また、Deep Learningはニューラルネットワークというものの一種であるとご説明しましたが、そもそもニューラルネットワークとは何なのでしょうか?
ニューラルネットワークは"ニューロン"の集合体
ニューラルネットワークは、神経細胞(ニューロン)から着想を得て開発された仕組みです。
ニューラルネットワークでは各ノード(ニューロン)が入力を受け付け、一定の規則に従って計算した結果を次のノードに渡す、という挙動を連鎖的に行います。
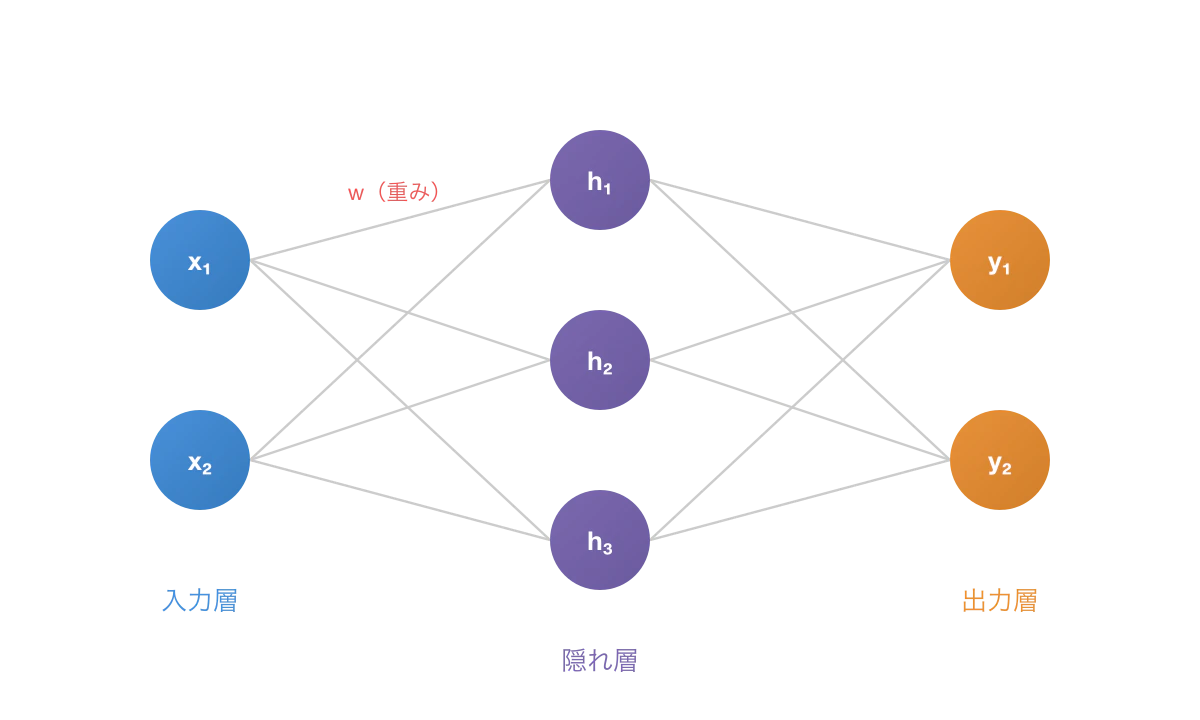
これでどうやってテキストを生成したり画像を生成したりできるようになるの?と思われるかもしれませんが、ここが機械学習のミソで、ある入力に対して特定のテキストや画像を出力できるように内部の計算で使われる値(パラメータ)を頑張って調整していくのです。
この値を調整するのが、所謂"学習"と呼ばれるプロセスです。
学習のためにはニューラルネットワークは非常に大量のデータを必要とし、膨大な計算をして地道にパラメータ調整を続けることによって、データ中に含まれるパターンを学習していきます。
"学習"という言葉の使い方について
最近では、様々な情報をAIが参照したり扱えるようにしたりすることを、広義に"学習"と表現しているのを度々見かけます。
一般的な会話では意味が伝われば良いと思うものの、機械学習の文脈では内部の重み(パラメータ)の調整のみを"学習"と呼ぶことに注意しましょう。
余談:何を指針にパラメータを更新するのか
ここは読み飛ばしても大丈夫です
学習はニューラルネットワーク内部のパラメータを更新することだとお話しました。では、具体的には内部でどのような計算をしているのでしょうか?
内部ではまず、一旦得られた出力と正解データの差分を計算します。この計算を行う関数を誤差関数と呼びます。
この誤差関数に対して誤差逆伝播法という方法を使うと、各パラメータをどれくらい増やしたり減らしたりすれば、出力が正解データに近くなるかを求めることができます。
この計算には線形代数(行列の計算)や微分積分の知識が必要となり、大学1年生レベルの数学が求められますが、興味のある方は以下の記事など読んでみると良いかもしれません。
更に余談:なぜAIにGPUが必要なのか
AIを動かすにはGPU(Graphics Processing Unit)が必要だ、という話を聞いたことがあるかもしれません。
GPUはその名の通り映像(Graphics)の計算を行うためのパーツであり、特に3D映像を扱う際に用いられます。PCでゲームをやったりしている人にとってはおなじみですね。
この3D映像の計算には数学の行列が使われており、GPUは行列の計算を高速で行うことに特化しています。
先ほど少しだけ触れましたが、実はニューラルネットワークも実態としては行列の計算になります。
そのため、GPUを使うことで同じく行列の計算であるニューラルネットワークも高速で動かすことができるのです。
そもそもLLMって、どうやって動いているの?
テキスト生成AIの正体はLLM(Large Language Model)であり、さらにその中身はニューラルネットワークというもので構成されている、というところまでお話しましたね。
次は、実際にLLMがどのように動作しているかを解説します。
LLMの核心:Transformer
現在のLLMのほとんどは、Transformerと呼ばれるアーキテクチャで構成されています。
オリジナルのTransformerはエンコーダ・デコーダ構造のモデルですが、現在主流のGPT系やClaude系のLLMは、デコーダ部分のみを用いた「decoder-only」アーキテクチャを採用しています。
そして、Transformerと言えばSelf-Attention層の発明が画期的だと言われることが多いです。
Self-Attention層は、簡単に言えば文章中の単語同士の関係から、それぞれの持つ意味を理解するためのものです。
例えば、"それ(it)"という単語が持つ意味は、文脈から推測する必要があります。
また、"X"という単語は、単にアルファベットのXなのか、SNSのXなのかは、これも文脈から理解する必要があります。
Self-Attention層では、文章中の単語が、他のどの単語と関連性が強いかを計算することで、文脈を汲み取った文章理解が可能となるのです。
LLMが文章を生成する方法
TransformerがSelf-Attention層により高度な文章理解が可能であることはわかりましたね。
では次に、いよいよ今回の本題であるLLMの仕組みについて解説していきます。
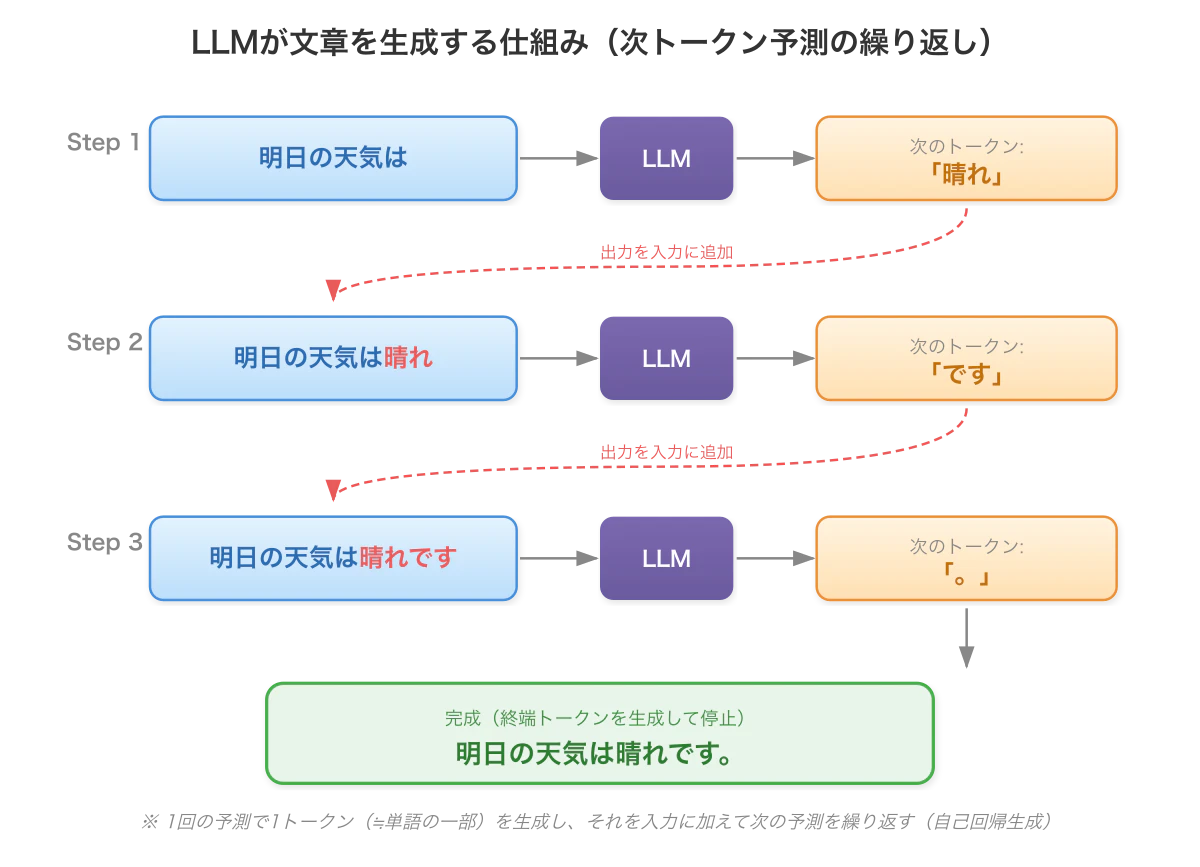
LLMが行っているのは実は非常にシンプルで、現在の文に続く確率が最も高い単語を予測することを繰り返しているだけです。
例えば、「明日の天気は」という文章があったとき、これに続く単語は「晴れ」の確率が高く、まあ「雨」や「曇り」かもしれませんが、少なくとも「タイヤ」である確率は低いですね。
では仮に「晴れ」だと予想したとすると、「明日の天気は晴れ」という文章が完成します。ここで、更に次の単語を予測するなら「です。」を付けて「明日の天気は晴れです。」とするのが、まあ一般的でしょう。
このように、現在の単語に続く語句を次々に予測することで、最終的に文章を完成させるのがLLMというわけです。
本題:推論モデルって何?
それでは本題の推論モデルについて説明していきましょう。
私は最初、推論モデルは根本的に異なるアーキテクチャを持つモデルなのではと予想していましたが、どうやらそうでは無いようです。
推論モデルは"よく考えるクセ"をつけたモデル
推論モデルとは、一言で言うと"よく考えるクセ"をつけたモデルです。
まず前提として、推論モデルのアーキテクチャや基本的な仕組みは通常のモデルと同一です。
では何が違うのかと言うと、入力と出力の間に思考の過程を出力させるよう、トレーニングを行ったのが推論モデルです。
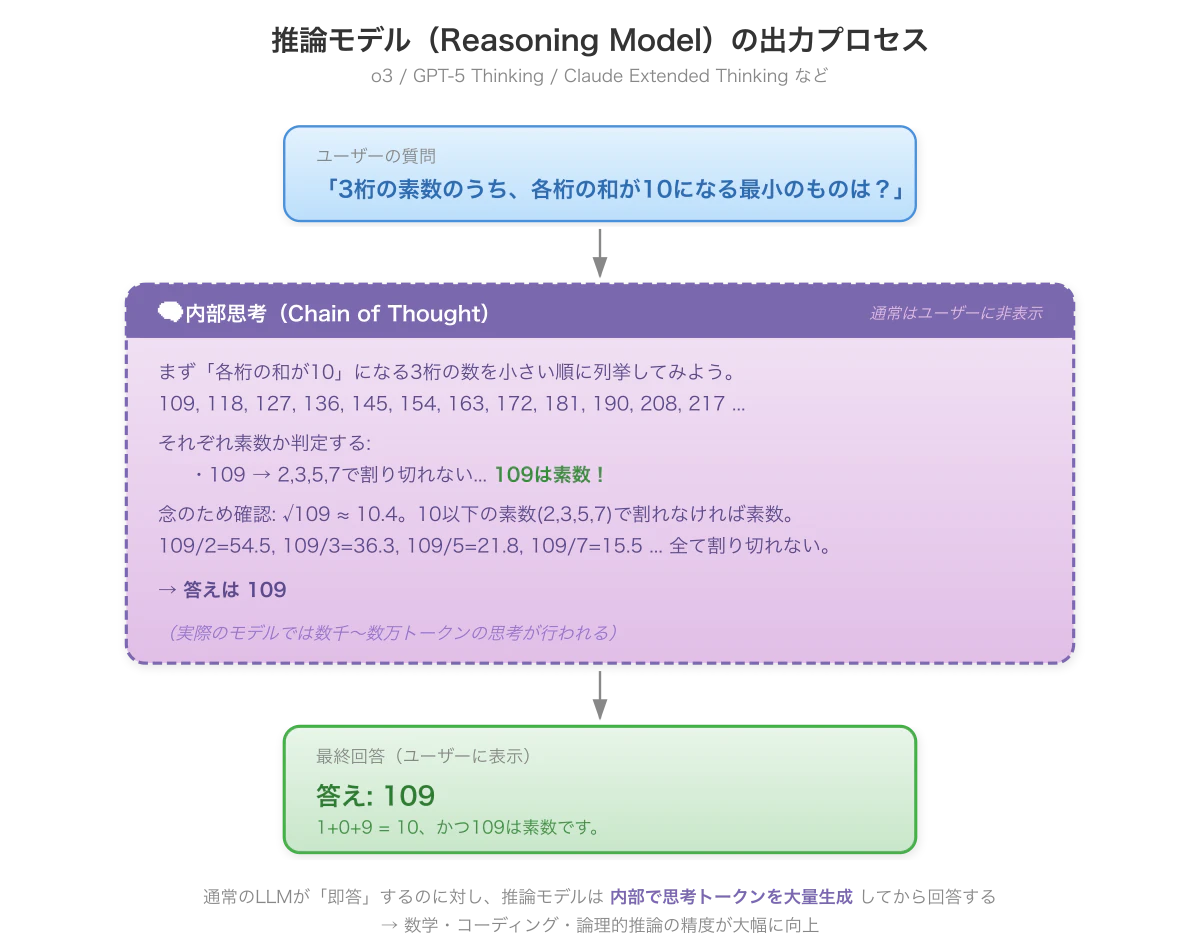
通常のLLMは、入力があるとその続きとして答えをすぐに出力しようとします。
しかし推論モデルでは、その問題に対してどのような考えを持って取り組むのか、思考プロセス自体を一度出力させ、最終的に答えにたどり着くようになっています。
ただし、内部でやっていることは通常のLLMと変わらず、単に続く確率が高い単語を予測するというだけなのですが、その出力傾向を一旦よく考えるように調整しているのです。
最終的に、内部思考の部分はユーザーに見せず、最終回答の部分だけ切り取って表示することで、内部的な挙動は同じだけど、よく考える事ができるモデルが完成するのです。
推論モデルの学習方法は"秘伝のレシピ"?
実行過程だけ見れば上記のように意外とシンプルな推論モデルですが、その学習方法は各社様々な工夫を行っているようです。
例えばDeepSeek-R1は論文で詳細な学習過程まで公開しており、その中でRL(強化学習)を用いてAIの出力に対してフィードバックを与えて学習することで、質の良い思考プロセスを獲得できたことが説明されています。
一方で、OpenAIやAnthropic等の企業は一部の情報は公開しつつも、GPTやClaudeの詳細な学習過程は伏せられています。
おわりに
今回は推論モデルのことだけ解説しようと思っていたら、生成AIの分類から話をはじめてしまい、意外と長くなってしまいました...
正直今回の話は知らなくてもAIは全然活用できるものの、エンジニアとしてはやはり内部の動作まで理解しておくというのは良いことだと思うんですよね。
今後も、AIを中心に様々な情報発信をしていこうと思いますので、引き続きよろしくお願いします!
最後までお読みいただきありがとうございました🙇
参考