はじめに
本記事はTerraformをこれから使う方向けにモジュールとは何かについて理解を深める内容となっています。
私自身もTerraformを実務で使ったことがないため、モジュールを初めて理解するという方の目線で書いていきたいと思います。
モジュールとは
構築の現場では必ず開発環境や本番環境など、環境が分かれて存在します。
その間環境別の構築するためのコードを分けて管理するのは冗長になります。
それをモジュール化することで、共通部分のコードは一つに集約して管理することができます。
この説明だけでは理解が難しいと思うので、どういうディレクトリ構成でTerraformのファイルを作っているかを見ていきましょう。
ディレクトリ構成
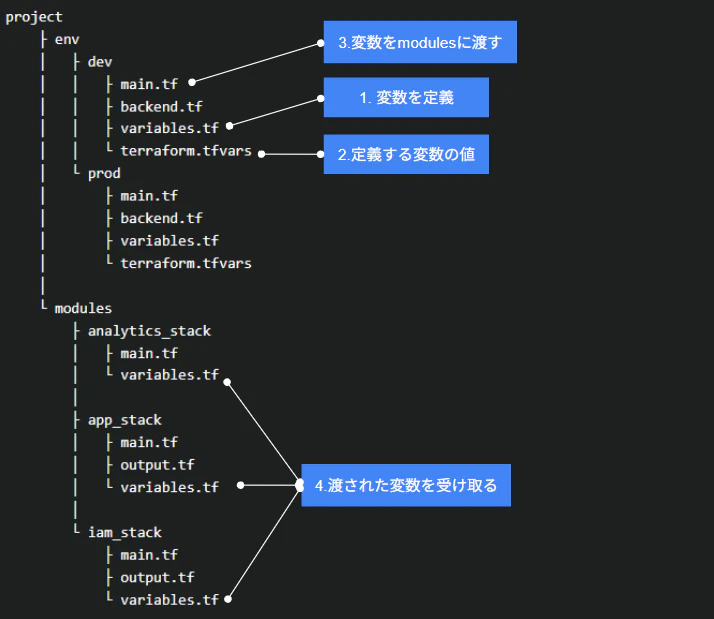
開発と本番で分ける場合のディレクトリ構成は以下になります。
(私が今回初めてTerraformで作った基盤構築の際の構成です)
順番にみていきます。
project
├ env
│ ├ dev
│ │ ├ main.tf
│ │ ├ backend.tf
│ │ ├ variables.tf
│ │ └ terraform.tfvars
│ └ prod
│ ├ main.tf
│ ├ backend.tf
│ ├ variables.tf
│ └ terraform.tfvars
│
└ modules
├ analytics_stack
│ ├ main.tf
│ └ variables.tf
│
├ app_stack
│ ├ main.tf
│ ├ output.tf
│ └ variables.tf
│
└ iam_stack
├ main.tf
├ output.tf
└ variables.tf
まず環境別にproject/env/dev, project/env/prodなどとディレクトリを分けておきます。
検証環境等別の環境が存在する場合はenv配下にstgなどディレクトリを作成すれば良いです。
各ファイルの内容は以下GitHubに公開しています。
各ディレクトリにある.tfファイルの役割を説明していきます。
env/dev/main.tf (env/prod/main.tfも同様)
# modules/app_stack/main.tf の先頭に追加
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 5.0"
}
}
}
# 現在実行しているリージョンの情報を取得
data "aws_region" "current" {}
# 現在のAWSアカウントIDを取得
data "aws_caller_identity" "current" {}
output "region_name" {
value = data.aws_region.current.name
}
output "account_id" {
value = data.aws_caller_identity.current.account_id
}
# アプリ基盤の作成 (S3, Lambda, Glue)
module "app" {
source = "../../modules/app_stack"
env = var.env
lambda_execution_role_arn = module.iam.lambda_execution_role_arn
region = data.aws_region.current.name
account_id = data.aws_caller_identity.current.account_id
}
# IAMロールの定義
module "iam" {
source = "../../modules/iam_stack"
env = var.env
region = data.aws_region.current.name
account_id = data.aws_caller_identity.current.account_id
s3_bucket_name = module.app.s3_bucket_name
}
# 分析基盤の作成 (Glue, Athena)
module "analytics" {
source = "../../modules/analytics_stack"
env = var.env
s3_bucket_name = module.app.s3_bucket_name
crawler_role_arn = module.iam.glue_crawler_role_arn
}
このmain.tfは各モジュールを呼び出し、主にモジュールへのデータの受け渡しをする役割を担っています。
パラメータを注入やモジュール間でのデータの受け渡しとは具体的にどういう意味なのか?
以下はコメントにも記載にある通り、currentのリージョンとAWSアカウントIDを取得する構文です。
# 現在実行しているリージョンの情報を取得
data "aws_region" "current" {}
# 現在のAWSアカウントIDを取得
data "aws_caller_identity" "current" {}
ここでカレントで実行しているリージョンとAWSアカウントID情報を取得し、module側に取得した値を受け渡します。
# アプリ基盤の作成 (S3, Lambda, Glue)
module "app" {
source = "../../modules/app_stack"
env = var.env
lambda_execution_role_arn = module.iam.lambda_execution_role_arn
region = data.aws_region.current.name # -> カレントリージョン情報をapp_stackへ受け渡し
account_id = data.aws_caller_identity.current.account_id # -> アカウントID情報をapp_stackへ受け渡し
}
# IAMロールの定義
module "iam" {
source = "../../modules/iam_stack"
env = var.env
region = data.aws_region.current.name # -> カレントリージョン情報をapp_stackへ受け渡し
account_id = data.aws_caller_identity.current.account_id # -> アカウントID情報をapp_stackへ受け渡し
s3_bucket_name = module.app.s3_bucket_name
}
# 分析基盤の作成 (Glue, Athena)
module "analytics" {
source = "../../modules/analytics_stack"
env = var.env
s3_bucket_name = module.app.s3_bucket_name
crawler_role_arn = module.iam.glue_crawler_role_arn
}
リージョン情報とアカウントID情報以外にも環境識別子やリソース名、ARNなどの受け渡しもしているが、これも順を追って見ていきたいと思います。
env/dev/variables.tf
まずenv = var.envについてはvariables.tfでenvの変数を定義し、terraform.tfvarsで変数に代入する値を定義します。
variable "env" {
type = string
}
env = "dev"
これを/env/dev/main.tfからかくモジュールに受け渡しすることで、/env/dev/ディレクトリでterraform applyを実施することでdev環境のAWSリソースとして作成することができます。
modules/xxx_stack/variables.tf
受け取る側、つまりmodule側はvariables.tfで以下のように定義し、受け皿を作って置き、main.tfで変数を使用する。
# envディレクトリの変数を受け取るための空の変数を定義
variable "env" {
type = string
}
variable "region" {
type = string
}
variable "account_id" {
type = string
}
locals {
app_name = "shogi"
name_prefix = "${var.env}-${local.app_name}"
}
# Pythonコードを保管するS3バケットの定義
resource "aws_s3_bucket" "analysis_data_bucket" {
bucket = "${local.name_prefix}-analysis-data-${var.account_id}"
}
# CloudWatch Logsのカスタムポリシー(インラインポリシー)
resource "aws_iam_role_policy" "cloudwatch_logs" {
name = "${local.name_prefix}-cloudwatch-logs-policy"
role = aws_iam_role.shogi_data_processor_role.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = "logs:CreateLogGroup"
Resource = "arn:aws:logs:${var.region}:${var.account_id}:*"
},
{
Effect = "Allow"
Action = [
"logs:CreateLogStream",
"logs:PutLogEvents"
]
Resource = [
"arn:aws:logs:${var.region}:${var.account_id}:log-group:/aws/lambda/shogi-data-processor:*"
]
}
]
})
}
モジュールの受け渡しについてはここまでで理解できたでしょうか?
もう一つの疑問は、以下main.tfでlambda_execution_role_arn = module.iam.lambda_execution_role_arn, s3_bucket_name = module.app.s3_bucket_name, crawler_role_arn = module.iam.glue_crawler_role_arnはどこで定義されたものを渡しているの?と思うのですが、これはoutputs.tfで定義されたものを渡しています。
# modules/app_stack/main.tf の先頭に追加
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 5.0"
}
}
}
# 現在実行しているリージョンの情報を取得
data "aws_region" "current" {}
# 現在のAWSアカウントIDを取得
data "aws_caller_identity" "current" {}
output "region_name" {
value = data.aws_region.current.name
}
output "account_id" {
value = data.aws_caller_identity.current.account_id
}
# アプリ基盤の作成 (S3, Lambda, Glue)
module "app" {
source = "../../modules/app_stack"
env = var.env
lambda_execution_role_arn = module.iam.lambda_execution_role_arn
region = data.aws_region.current.name
account_id = data.aws_caller_identity.current.account_id
}
# IAMロールの定義
module "iam" {
source = "../../modules/iam_stack"
env = var.env
region = data.aws_region.current.name
account_id = data.aws_caller_identity.current.account_id
s3_bucket_name = module.app.s3_bucket_name
}
# 分析基盤の作成 (Glue, Athena)
module "analytics" {
source = "../../modules/analytics_stack"
env = var.env
s3_bucket_name = module.app.s3_bucket_name
crawler_role_arn = module.iam.glue_crawler_role_arn
}
AWSリソースは色々なリソースに依存して作成されるため、あるmain.tfで定義した値を別のmain.tfで定義したいといったことが頻繁に起こります。
例えば以下は/env/modules/main.tfのリソースを定義している内容ですが、Guleのクローラーを作成するリソースでroleとS3のpath (prefix)を指定しなければいけないですが、roleとS3については別のmoduleで定義していることから値をoutputs -> modulesと受け渡しをする必要があります。
role = var.crawler_role_arnpath = "s3://${var.s3_bucket_name}/data/"
各定義元~外だし~受け渡すまでをまとめると以下
■S3バケット, IAM Roleの定義元
app_stack/main.tf
iam_stack/main.tf
■定義したS3, IAM Roleの外だし
app_stack/outputs.tf
iam_stack/outputs.tf
■外だししたS3, IAM Roleの受け渡し
dev/main.tf
S3バケット, IAM Roleの定義元
■S3の定義元
# Pythonコードを保管するS3バケットの定義
resource "aws_s3_bucket" "analysis_data_bucket" {
bucket = "${local.name_prefix}-analysis-data-${var.account_id}"
}
■IAM Role(Crawler用ロール)の定義元
# Glue Crawler用ロールの作成
resource "aws_iam_role" "glue_crawler_role" {
name = "${local.name_prefix}-glue-crawler-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Principal = {
Service = "glue.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "${var.account_id}"
}
}
}
]
})
}
■定義したS3, IAM Roleの外だし
output "s3_bucket_name" {
value = aws_s3_bucket.analysis_data_bucket.id
}
output "glue_crawler_role_arn" {
value = aws_iam_role.glue_crawler_role.arn
description = "ARN of the Glue Crawler role"
}
■外だししたS3, IAM Roleの受け渡し
# IAMロールの定義
module "iam" {
source = "../../modules/iam_stack"
env = var.env
region = data.aws_region.current.name
account_id = data.aws_caller_identity.current.account_id
s3_bucket_name = module.app.s3_bucket_name # -> iam_stackのポリシーのリソース作成の際にGlueのポリシー作成にS3名が必要なため受け渡し
}
# 分析基盤の作成 (Glue, Athena)
module "analytics" {
source = "../../modules/analytics_stack"
env = var.env
s3_bucket_name = module.app.s3_bucket_name # -> Glueのリソース作成の際にCrawlerがDBの見に行く先のS3(プレフィックス)が必要なため受け渡し
crawler_role_arn = module.iam.glue_crawler_role_arn # -> Glueクローラーのリソース作成の際に、S3へのアクセス権限、Glueのマネージドポリシーが必要なため受け渡し
}
上記をディレクトリ構成から図解してみましょう。
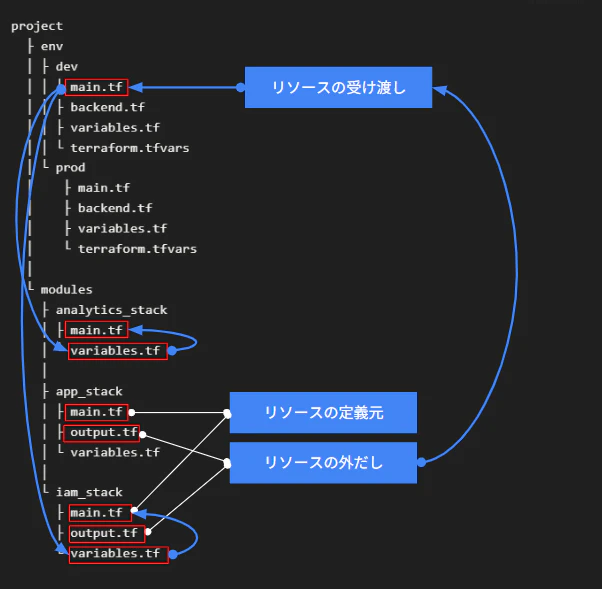
- 「情報の公開」: 作成したリソースのIDやARNを output.tf から外へ出します
- 「他への連携」: env/dev/main.tf がその情報を受け取り、次のモジュールの variables.tf(入口)へと繋ぎます
- 「情報の受付」: variables.tf でリソース作成に必要な材料(環境名やバケット名など)を受け取ります
- 「リソースの作成」: main.tf が、受け取った材料を使って実際にAWS上にリソースを組み立てます
図解することでどういう流れでリソース情報を受け渡したりしているということが視覚化されてわかりやすくなりますよ。
というより私は図解しないと理解できませんでした。
最後に
Terraformのモジュールについて深掘りしてみました。
はじめにモジュールの説明を動画等で聞いた時は頭が混乱してしまいましたが、一つ一つひも解けば理解できるようになりますね。
とはいえリソース情報が増えてくると複雑にはなってきますので、ここは使って慣れていくしかないかなと思います。