はじめに
大手クラウドのLLMプロバイダーでは、大抵プロンプトキャッシュ機能を提供しています。
プロンプトキャッシュ機能というのは、LLMの計算内部計算過程を保存しておき再利用することでコストやレイテンシを抑える機能のことです。
プロンプトキャッシュ機能が適用されるとコストが大幅に(9割も!)削減されて、安くなるのは非常に嬉しいのですが、何か異様に安くなり過ぎているような感覚がしていて、逆に普段がぼったくられているのではないかという気持ちになってしまい、ずっと気持ちの悪さを感じていました。
今回はプロンプトキャッシュ機能が適用されるとなぜ安くなるかについて納得がいくように調べてみました。
大手クラウドのプロンプトキャッシュ機能
例えば主要三社(AWS、Azure、Google Cloud)のプロンプトキャッシュ機能については以下の通り。
微妙に機能の名称や使い勝手は違いますが、同じような機能が存在することがわかります。
| クラウドプロバイダー | LLMサービス | 機能名 | 公式ドキュメントリンク | 備考・対応モデルの例 |
|---|---|---|---|---|
| AWS | Amazon Bedrock | Prompt Caching | Prompt caching for faster model inference | コストを90%削減する。Anthropic ClaudeモデルファミリーやAmazon Novaモデルなどで利用可能。API経由で明示的にチェックポイント(cachePoint)を指定して利用する。 |
| Microsoft Azure | Azure AI Foundry | Prompt Caching | Prompt caching with Azure OpenAI 価格表 | コストを90%削減する。GPT-4o以降のLLMモデルで利用可能。プロンプトの先頭1,024トークン以上が一致する場合に、特別な設定不要で自動的に適用(キャッシュヒット)されます。 |
| Google Cloud | Vertex AI | Context Caching (Gemini) | Context caching overview (Gemini) | コストを90%削減する。Geminiモデル向けには、デフォルトで自動適用される「暗黙的キャッシュ(Implicit)」と、APIでTTLを指定して保存する「明示的キャッシュ(Explicit)」を提供しています。また、Vertex AI上のClaude向けにもプロンプトキャッシュをサポートしています。 |
Transformerで使われているAttentionを理解する
結論から言うと、コストの大幅な削減は、Transformerの構成要素であるAttentionの入力クエリー・キー・バリューにおいて、クエリは最新のトークンを計算するのに過去のトークンを必要とせず、計算するキーとバリューをキャッシュ(KVキャッシュ)して再利用することで、計算量を大幅に減らしているということでした。
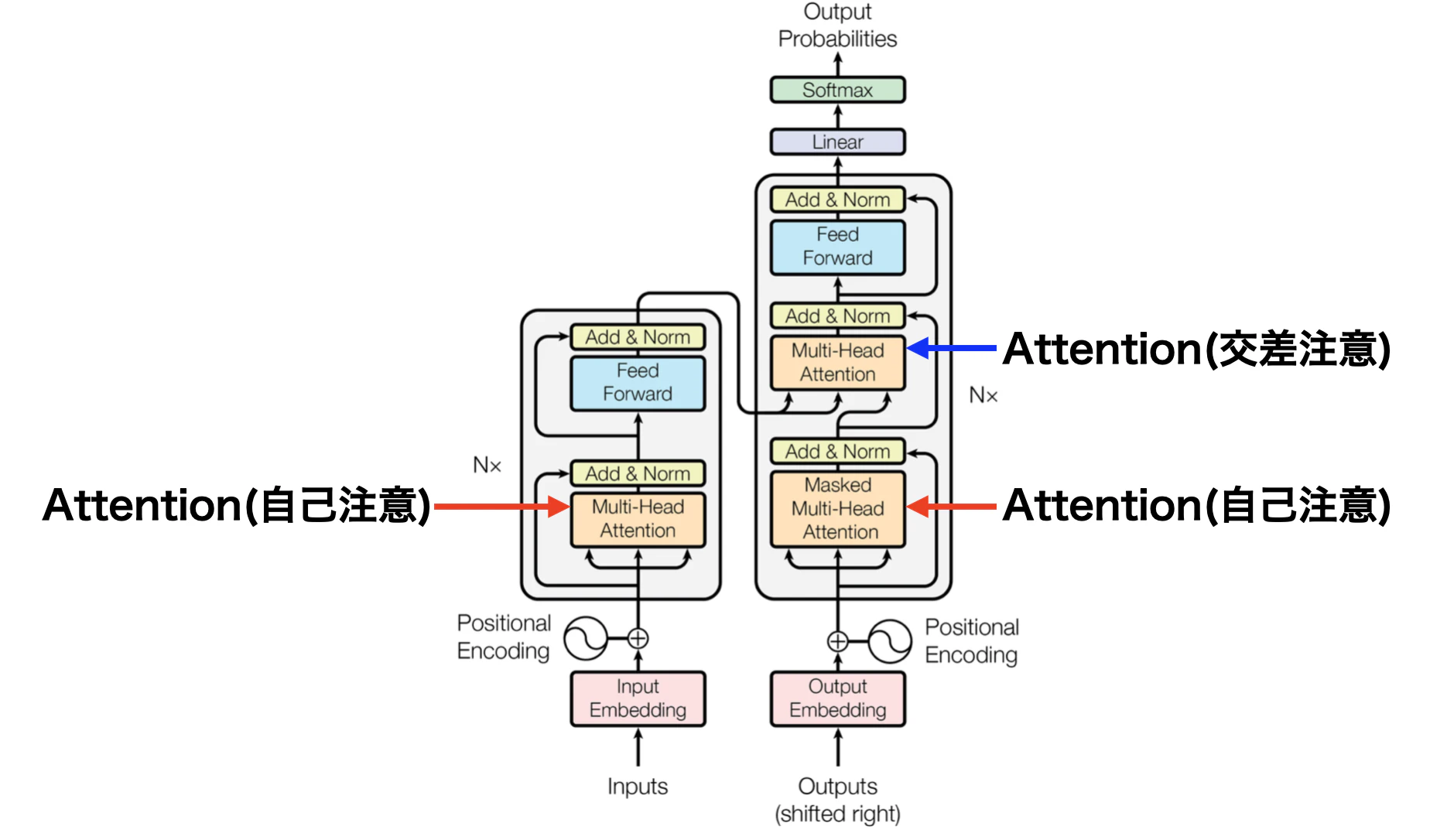
上図はTransformerがデビューした有名論文『Attention Is All You Need』から引っ張ってきたものです。
Attentionには2種類あって、一つは「自己注意(Self-Attention)」と「交差注意(Cross-Attention)」というものがありますが、プロンプトキャッシュによるコスト削減の話題のときには特にその差を気にする必要はありません。
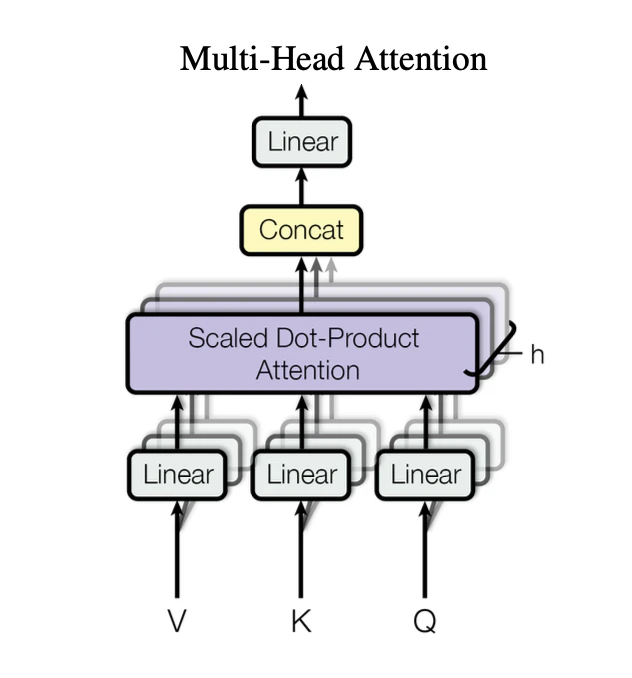
Attentionのブロックへの入力は三又になっていますが、それぞれがQ(クエリ)・K(キー)・バリュー(V)です。
下図はAttentionのブロックの内部構造を示しています。
具体的に計算してみる
$n$と$m$をトークン数とします。
クエリ $Q \in \mathbb{R}^{n \times d_{key}}$、キー $K \in \mathbb{R}^{m \times d_{key}}$、バリュー $V \in \mathbb{R}^{m \times d_{value}}$ とおきます。
- $K$と$V$の行数(トークン数 $m$)は同じである必要アリ。
- $Q$と$K$の列数(ベクトルの次元数 $d_{key}$)は同じである必要アリ。
- アテンションが自己注意(Self-Attention)のときは $n=m$ である。
$q_i \in \mathbb{R}^{d_{key}}$ : クエリーの1つのトークンのベクトル
$k_i \in \mathbb{R}^{d_{key}}$ : キーの1つのトークンのベクトル
$v_i \in \mathbb{R}^{d_{value}}$ : バリューの1つのトークンのベクトル
とすると、各行列は以下のように書けます。
Q = \begin{pmatrix} q_1^T \\ q_2^T \\ \vdots \\ q_n^T \end{pmatrix}, \quad
K = \begin{pmatrix} k_1^T \\ k_2^T \\ \vdots \\ k_m^T \end{pmatrix}, \quad
V = \begin{pmatrix} v_1^T \\ v_2^T \\ \vdots \\ v_m^T \end{pmatrix}
アテンションは以下のように定義されます。
\text{Attention}(Q, K, V) := \text{softmax}\left(\frac{QK^T}{\sqrt{d_{key}}}\right)V
アテンションの成分を実際に計算してみます。
QK^T = \begin{pmatrix} q_1^T \\ q_2^T \\ \vdots \\ q_n^T \end{pmatrix} \begin{pmatrix} k_1, k_2, \dots, k_m \end{pmatrix}
= \begin{pmatrix}
q_1^T \cdot k_1 & q_1^T \cdot k_2 & \dots & q_1^T \cdot k_m \\
q_2^T \cdot k_1 & \dots & \dots & \vdots \\
\vdots & \dots & \dots & \vdots \\
q_n^T \cdot k_1 & \dots & \dots & q_n^T \cdot k_m
\end{pmatrix}
$\to \text{softmax}$ 関数 $\sigma$ は $Z = (z_1, z_2, \dots, z_k) \in \mathbb{R}^k$ について
\sigma(Z)_i := \frac{\exp(z_i)}{\sum_{j=1}^k \exp(z_j)}
だから、
\text{softmax}(QK^T) = \begin{pmatrix}
\frac{\exp(q_1^T \cdot k_1)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)} & \frac{\exp(q_1^T \cdot k_2)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)} & \dots & \frac{\exp(q_1^T \cdot k_m)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)} \\
\frac{\exp(q_2^T \cdot k_1)}{\sum_{j=1}^m \exp(q_2^T \cdot k_j)} & \dots & \dots & \vdots \\
\vdots & \dots & \dots & \vdots \\
\frac{\exp(q_n^T \cdot k_1)}{\sum_{j=1}^m \exp(q_n^T \cdot k_j)} & \dots & \dots & \frac{\exp(q_n^T \cdot k_m)}{\sum_{j=1}^m \exp(q_n^T \cdot k_j)}
\end{pmatrix}
したがって、
\text{softmax}(QK^T)V = \begin{pmatrix}
\frac{\exp(q_1^T \cdot k_1)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)} & \dots & \frac{\exp(q_1^T \cdot k_m)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)} \\
\frac{\exp(q_2^T \cdot k_1)}{\sum_{j=1}^m \exp(q_2^T \cdot k_j)} & \dots & \vdots \\
\vdots & \dots & \vdots \\
\frac{\exp(q_n^T \cdot k_1)}{\sum_{j=1}^m \exp(q_n^T \cdot k_j)} & \dots & \frac{\exp(q_n^T \cdot k_m)}{\sum_{j=1}^m \exp(q_n^T \cdot k_j)}
\end{pmatrix}
\begin{pmatrix} v_1^T \\ v_2^T \\ \vdots \\ v_m^T \end{pmatrix}
= \begin{pmatrix}
\frac{\exp(q_1^T \cdot k_1)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)}v_1^T + \frac{\exp(q_1^T \cdot k_2)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)}v_2^T + \dots + \frac{\exp(q_1^T \cdot k_m)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)}v_m^T \\
\frac{\exp(q_2^T \cdot k_1)}{\sum_{j=1}^m \exp(q_2^T \cdot k_j)}v_1^T + \dots \\
\vdots \\
\frac{\exp(q_n^T \cdot k_1)}{\sum_{j=1}^m \exp(q_n^T \cdot k_j)}v_1^T + \dots + \frac{\exp(q_n^T \cdot k_m)}{\sum_{j=1}^m \exp(q_n^T \cdot k_j)}v_m^T
\end{pmatrix}
= \begin{pmatrix}
\sum_{i=1}^m \frac{\exp(q_1^T \cdot k_i)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)}v_i^T \\
\sum_{i=1}^m \frac{\exp(q_2^T \cdot k_i)}{\sum_{j=1}^m \exp(q_2^T \cdot k_j)}v_i^T \\
\vdots \\
\sum_{i=1}^m \frac{\exp(q_n^T \cdot k_i)}{\sum_{j=1}^m \exp(q_n^T \cdot k_j)}v_i^T
\end{pmatrix}
したがって、
\text{Attention}(Q, K, V) = \frac{1}{\sqrt{d_{key}}} \begin{pmatrix}
\sum_{i=1}^m \frac{\exp(q_1^T \cdot k_i)}{\sum_{j=1}^m \exp(q_1^T \cdot k_j)}v_i^T \\
\sum_{i=1}^m \frac{\exp(q_2^T \cdot k_i)}{\sum_{j=1}^m \exp(q_2^T \cdot k_j)}v_i^T \\
\vdots \\
\sum_{i=1}^m \frac{\exp(q_n^T \cdot k_i)}{\sum_{j=1}^m \exp(q_n^T \cdot k_j)}v_i^T
\end{pmatrix}
\label{a}\tag{1}
となる。
ここで、$Q$の1トークンだけの場合にアテンション計算をしてみる。
$Q_t = q_t^T$ として、
\text{Attention}(Q_t, K, V) = \text{softmax}\left(\frac{Q_tK^T}{\sqrt{d_{key}}}\right)V \quad \text{について}
Q_tK^T = q_t^T (k_1, k_2, \dots, k_m) = (q_t^T \cdot k_1, q_t^T \cdot k_2, \dots, q_t^T \cdot k_m)
\text{softmax}\left(\frac{Q_tK^T}{\sqrt{d_{key}}}\right) = \left( \frac{\exp(q_t^T \cdot k_1 / \sqrt{d_{key}})}{\sum_{j=1}^m \exp(q_t^T \cdot k_j / \sqrt{d_{key}})}, \dots, \frac{\exp(q_t^T \cdot k_m / \sqrt{d_{key}})}{\sum_{j=1}^m \exp(q_t^T \cdot k_j / \sqrt{d_{key}})} \right)
\text{softmax}\left(\frac{Q_tK^T}{\sqrt{d_{key}}}\right)V
= \left( \frac{\exp(q_t^T \cdot k_1 / \sqrt{d_{key}})}{\sum_{j=1}^m \exp(q_t^T \cdot k_j / \sqrt{d_{key}})}, \dots \right) \begin{pmatrix} v_1^T \\ v_2^T \\ \vdots \\ v_m^T \end{pmatrix}
= \frac{\exp(q_t^T \cdot k_1 / \sqrt{d_{key}})}{\sum_{j=1}^m \exp(q_t^T \cdot k_j / \sqrt{d_{key}})}v_1^T + \dots + \frac{\exp(q_t^T \cdot k_m / \sqrt{d_{key}})}{\sum_{j=1}^m \exp(q_t^T \cdot k_j / \sqrt{d_{key}})}v_m^T
= \sum_{i=1}^m \frac{\exp(q_t^T \cdot k_i / \sqrt{d_{key}})}{\sum_{j=1}^m \exp(q_t^T \cdot k_j / \sqrt{d_{key}})}v_i^T
つまり、
\text{Attention}(Q_t, K, V)
= \sum_{i=1}^m \frac{\exp(q_t^T \cdot k_i / \sqrt{d_{key}})}{\sum_{j=1}^m \exp(q_t^T \cdot k_j / \sqrt{d_{key}})}v_i^T
\label{b}\tag{2}
式$(\ref{a})$と式$(\ref{b})$ を見比べることで、
\text{Attention}(Q, K, V) = \begin{pmatrix}
\text{Attention}(Q_1, K, V) \\
\text{Attention}(Q_2, K, V) \\
\vdots \\
\text{Attention}(Q_n, K, V)
\end{pmatrix}
と書くことができるのが分かります。
この数式が示す「KVキャッシュ」の利点
上記最後の結論式が、KVキャッシュ(プロンプトキャッシュ)の仕組みを説明しています。
全体のAttention計算は、「各クエリトークン($Q_i$)ごとの独立した計算結果を、縦に並べただけ」です。つまり、あるクエリ $Q_n$ のAttention結果を求めるために、過去のクエリ $Q_1 \sim Q_{n-1}$ の情報は一切必要ないということです。
LLMがテキストを生成する際、新しいトークンを1つずつ順番に生成していきますが、
新しく生成しようとしている最新のトークン(クエリ $Q_t$ とします)の計算をするとき、過去のトークンから生成されたキー($K$)とバリュー($V$)さえメモリ上にキャッシュ(保存)しておけば、過去の計算を省略できるということです。
ここまでで計算量を減らしてコスト削減ができるということは分かりましたが、具体的にどれくらい削減できるのでしょうか?大手クラウドの90%削減というのは妥当な値なのでしょうか?そこも深掘りしてみましょう。
具体的な計算量の削減効果
先ほどの数式で「計算を省略できる」ということが分かりましたが、実際どれくらい計算量を削減できるかを丁寧に見ていきたいと思います。
Transformerのシーケンス長(入力されるトークン数)を $n$、ベクトルの次元数を $d$ とします。
キャッシュを使わない場合(毎回計算し直す場合)
プロンプトが入力された際、LLMは入力されたすべてのトークン同士の関連度を計算します。自己注意(Self-Attention)においてトークン数を $n$、ベクトルの次元数を $d$(先ほどの式の $d_{key}, d_{value}$)とします。
まず、行列 $Q$ $(n \times d)$ と行列 $K^T$ $(d \times n)$ の積 $QK^T$ を計算します。
出来上がる行列は $(n \times n)$ のサイズになります。この $n \times n$ 個の要素(全部で $n^2$ 個)の1つ1つを求めるために、長さ $d$ のベクトル同士の内積($d$ 回の掛け算)を行う必要があります。
\underbrace{
\begin{pmatrix}
& q_1^T & \\
& q_2^T & \\
& \vdots & \\
& q_n^T &
\end{pmatrix}
}_{n \times d}
\times
\underbrace{
\begin{pmatrix}
k_1 & k_2 & \dots & k_n \\
\end{pmatrix}
}_{d \times n}
=
\underbrace{
\begin{pmatrix}
q_1^T \cdot k_1 & q_1^T \cdot k_2 & \dots & q_1^T \cdot k_n \\
q_2^T \cdot k_1 & q_2^T \cdot k_2 & \dots & q_2^T \cdot k_n \\
\vdots & \vdots & \ddots & \vdots \\
q_n^T \cdot k_1 & q_n^T \cdot k_2 & \dots & q_n^T \cdot k_n
\end{pmatrix}
}_{n \times n}
q_1^T \cdot k_1 = \sum_{l=1}^{d} (q_{1,l} \times k_{l,1}) = (q_{1,1} \times k_{1,1}) + (q_{1,2} \times k_{2,1}) + \dots + (q_{1,d} \times k_{d,1})
したがって、必要な掛け算の総数は $n^2 \times d$ となり、計算量のオーダーは $O(n^2 \cdot d)$ となります。
さらに、その後の計算を進めてもこのオーダーは変わりません。
出来上がった $(n \times n)$ 行列に対する softmax 関数の計算量は $O(n^2)$ なのですが、このことも詳しく見てみましょう。
Z = \underbrace{
\begin{pmatrix}
z_{1,1} & z_{1,2} & \dots & z_{1,n} \\
z_{2,1} & z_{2,2} & \dots & z_{2,n} \\
\vdots & \vdots & \ddots & \vdots \\
z_{n,1} & z_{n,2} & \dots & z_{n,n}
\end{pmatrix}
}_{n \times n}
\xrightarrow{\text{行ごとにSoftmax}}
\underbrace{
\begin{pmatrix}
\frac{\exp(z_{1,1})}{\sum_{j=1}^n \exp(z_{1,j})} & \frac{\exp(z_{1,2})}{\sum_{j=1}^n \exp(z_{1,j})} & \dots & \frac{\exp(z_{1,n})}{\sum_{j=1}^n \exp(z_{1,j})} \\
\frac{\exp(z_{2,1})}{\sum_{j=1}^n \exp(z_{2,j})} & \dots & \dots & \vdots \\
\vdots & \dots & \dots & \vdots \\
\frac{\exp(z_{n,1})}{\sum_{j=1}^n \exp(z_{n,j})} & \dots & \dots & \frac{\exp(z_{n,n})}{\sum_{j=1}^n \exp(z_{n,j})}
\end{pmatrix}
}_{n \times n}
この処理を、一番上の1行目(ある1つのクエリに関する計算)について分解してみます。
行の要素 $(z_{1,1}, z_{1,2}, \dots, z_{1,n})$ を合計が1になる確率値に変換するために、分母である「指数関数の総和($S_1$とします)」を計算して、各要素を割ります。
S_1 = \exp(z_{1,1}) + \exp(z_{1,2}) + \dots + \exp(z_{1,n})
\text{Softmax}(Z_1) = \left( \frac{\exp(z_{1,1})}{S_1}, \frac{\exp(z_{1,2})}{S_1}, \dots, \frac{\exp(z_{1,n})}{S_1} \right)
この1行の計算を完了するためには、「$n$ 個の $\exp$ 計算」、「$n$ 個の足し算($S_1$)」、「$n$ 回の割り算」を行っています。つまり、1行あたり $n$ に比例する計算($O(n)$)が必要です。
行列全体ではこれが $n$ 行分あるため、$n$ 行 $\times O(n) =$ $O(n^2)$ の計算量となります。要するに、行列の全要素($n^2$ 個)を1つずつ舐めて、指数計算や割り算をしているだけなので、計算量は要素数と同じ $O(n^2)$ になるというわけです。
そして、その結果の行列 $(n \times n)$ とバリュー行列 $V$ $(n \times d)$ を掛け合わせますが、これも出来上がる $(n \times d)$ 行列の各要素($n \times d$ 個)について $n$ 回の掛け算を行うため、計算量は$Q$と$K$の時と同様に、$n \times d \times n = n^2 \cdot d$ となり、やはり $O(n^2 \cdot d)$ になります。
以上の$QK^T$と$softmax$と$V$の積の計算量を足し合わせても全体の計算量のオーダーは $O(n^2 \cdot d)$ が支配的になります。
つまり、Attentionの計算量はトークン数 $n$ の2乗に比例して爆発的に増加します(二次関数的な増加)。$n$ が長くなればなるほど、この計算がGPUの計算リソースを強烈に食いつぶす要因になるのです。
KVキャッシュを使う場合
一方、過去の文脈がすべてKVキャッシュとして保存されている場合、新しく生成・入力される「1トークン」についてのみ計算すれば済みます。
計算量に関しても、先ほどの「KVキャッシュを使わない場合」の$Q$の行数$n$を1に置き換えることですぐに計算ができます。
つまり、このときのクエリ $Q_t$ は $(1 \times d)$ のベクトルです。
キャッシュされたキー $K^T$ $(d \times n)$ との掛け算 $Q_t K^T$ に必要な計算量は$O(n \cdot d)$ になり、$softmax$は$O(n)$になり、$V$の掛け合わせでは$O(n \cdot d)$となります。
従って全体の計算量では$O(n \cdot d)$です。
つまり、キャッシュを使わないときは $O(n^2)$ だった計算量が、KVキャッシュを使うことで $O(n)$ へと、計算量のオーダーが「1段下がる」のです。
具体的な数値を入れて確かめる
さてここまでで、以下のような計算量になることが分かりました。
| プロンプトキャッシュなし(KVキャッシュ未使用) | $O(n^2 \cdot d)$ |
| プロンプトキャッシュあり(KVキャッシュ使用) | $O(n \cdot d)$ |
ここに具体的な数値を当てはめて、計算量の削減具合を確かめてみましょう。
例えば、RAGを構成している場合、プロンプトテンプレートの後ろ側に取得されたドキュメント情報を埋め込むことが多いと思います。
このプロンプトテンプレートの共通部分のトークン長が10000だったとします。
そしてドキュメントのトークン長が100だったとします。
そうすると、
プロンプトキャッシュなし(KVキャッシュ未使用)の場合には、
$n^2 \cdot d = (10000 + 100)^2 \cdot d > 1億d$
である一方で、
プロンプトキャッシュあり(KVキャッシュ使用)の場合には、共通部分(10000)の再計算は行わず、新規の100トークンだけを計算するので、
$100 \cdot n \cdot d = 100 \cdot 10000 \cdot d = 100万d$
となります。
これはつまり、プロンプトキャッシュがない時はある時に比べて計算量が1%以下(99%以上の計算量削減)になっているということになります。
実際にはTransformerにはフィードフォワード層などのAttention以外の計算ブロックがあったりするので、もっと計算量があるはずです。それらのことを踏まえつつ、計算量が区切りよく90%くらい減ったのならコストも90%くらい減るだろうということで、大手クラウドがコストを90%OFFという形で設定しているのだろうなと思います。
おわりに
これでプロンプトキャッシュがどのような理屈で実現できているかが分かりました。
なんだかんだで、やはり、大手クラウドのLLMプロバイダーで適用されるとコストが大幅に抑えられるのは納得感のある仕組みでしたね。