初版: 2021年3月29日
著者: 株式会社日立製作所 橋本恭佑、Nguyen Ba Hung
はじめに
AI技術への注目の高まりに伴い、機械学習技術をビジネスへ適用するニーズが増えています。
ビジネスに機械学習技術を用いる場合、企業はまず業務に関係するデータを用いて機械学習モデルを作成します。
このとき利用されるデータは特定の時点より前のデータであり、時間が経過しても変化しません。
一方で、実際の業務で利用されるデータは時間の経過とともに変化します。
作成した機械学習モデルを業務へ適用してしばらくすると、データの傾向が変化し、作成した機械学習モデルの精度が低下したり、性別や住所の様な特定のデータに偏った推論が行われる現象が起こります。
前者の現象はデータドリフト、後者の現象はバイアスと呼ばれ、機械学習モデルをビジネスへ適用するSEにとって、データドリフトやバイアスなどの発生を迅速に検知することは、
機械学習モデルをビジネスへ効果的に適用する上で極めて重要といえます。
本投稿では、機械学習モデルをビジネスへ適用するSEを対象として、機械学習モデル及びデータの傾向の監視技術を解説し、
AWSのマネージドサービスであるAmazon SageMakerによって、これらの監視技術を利用可能になることを示します。
次回以降の投稿では米国の電話会社の顧客解約予測を題材として、
監視技術(精度の可視化、データ品質監視、モデルの説明可能性、バイアス監視)について実機検証した結果を紹介します。
投稿一覧
- Amazon SageMakerで実現する機械学習モデルの監視技術・・・本投稿
- Amazon SageMakerで実現する機械学習モデルの精度可視化とデータ品質監視
- Amazon SageMakerで実現する機械学習モデルの説明可能性可視化とバイアス監視
AWSを利用した機械学習モデルの監視の概要
機械学習モデルの監視手法
図1は機械学習モデル構築のライフサイクルを示しています。機械学習モデル構築のライフサイクルは、データの生成、モデルの訓練、モデルのデプロイの3パートから構成されます。
本投稿で扱う機械学習モデル及びデータの傾向の監視技術は、モデルのデプロイを実行した後に、機械学習モデルのパフォーマンスを監視し評価する部分に相当します。
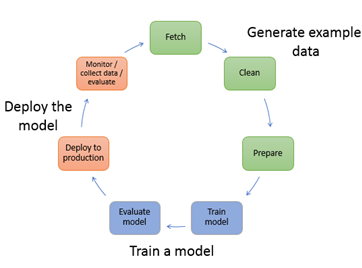
図1: 機械学習モデル作成のライフサイクル(出典: AWSホームページ, https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-mlconcepts.html)
機械学習モデルの監視には、図2に示す4つの手法があります。図2は携帯電話会社の顧客の解約率を予測する機械学習モデルを例として、説明変数を顧客の特性(契約月数やプランなど)、目的変数を解約の有無として示しています。
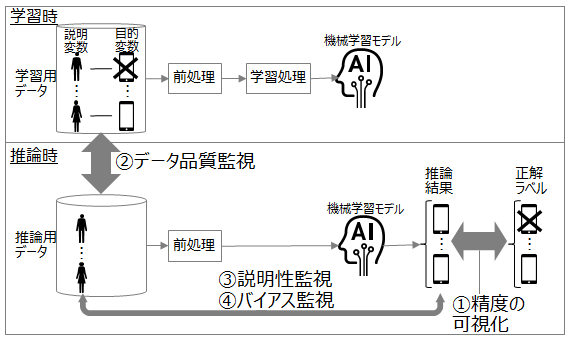
図2: 機械学習モデルの監視手法
① 精度の可視化
推論結果と正解ラベルを比較し、正答率などを算出します。精度を評価する指標の例としては、正答率や再現率、F値があります。
②データ品質監視
データドリフトが起こっていないかを監視します。次の3つの方法があるといわれています1。
- 機械学習モデルの誤答率変化の検知: 精度の変化をデータドリフトとして検知します。
- データの分布変化の検出: 学習用データの分布と推論用データの分布の違いをデータドリフトとして検知します。
- 多重仮説検定の実行: データドリフトが起こっている場合に、こういう試行をするとこのくらいの確率でこういう結果になる、といった仮説を立てて検定を実施し、仮説を満たす場合にデータドリフトとして検知します。
③ 説明性の監視
推論用データと推論結果を比較して、機械学習モデルの推論結果の根拠を監視します。次の3つのアプローチがあるといわれています2。
- Deep Explanation: 説明可能な説明変数を学習する様に、深層学習技術を作り変える。
- Interpretable Models: より構造的で、解釈しやすく、因果関係がわかりやすいモデルを利用する。
- Model Induction: モデルの入出力を推論するモデルを利用する。
④ バイアスの監視
推論用データと推論結果を比較して、推論結果に偏りがないかを監視します。
Amazon SageMakerが提供する機械学習モデルの監視手法
Amazon SageMaker Model Monitor
Amazon SageMaker Model Monitor は、本番環境におけるAmazon SageMakerの機械学習モデルと推論データの品質を監視します。
Amazon SageMaker Model Monitor を使用すると、モデルの品質変化に関するアラートを設定できます。
変化を検出することで、モデルの再学習や、システムの監査、データ品質の問題の修正などを決定できます。図3にSageMaker Model Monitorの概略図を示します。図3の緑色のバケツはS3ストレージを示しています。
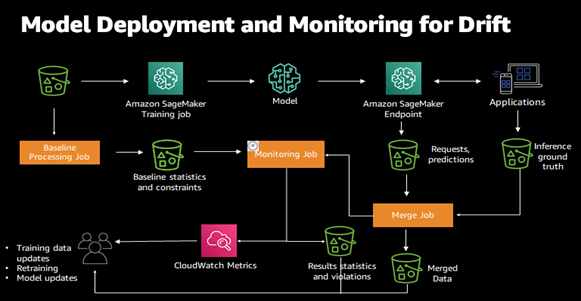
図3: Amazon SageMaker Model Monitor(出典: AWSホームページ, https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html)
Amazon SageMaker Model Monitorは、ベースライン処理ジョブ(Baseline Processing Job)とスケジュールされた監視ジョブ(Monitoring Job)の2つのジョブで構成され、それぞれが学習用データと推論用データを利用します。
ベースライン処理ジョブは、学習用データを元に、ベースライン統計(データの欠損、平均、最小、最大、標準偏差など、学習用データに関する簡単な統計値)と制約条件(特徴量の型や値の範囲、データの形式など)を作成します。
その後、スケジュールされた監視ジョブは定期的(毎時、毎日などの事前定義された期間)にベースライン統計および制約条件と推論用データとを比較し、推論用データの統計値と、推論用データに含まれる違反値を抽出します。
抽出した結果はAmazon CloudWatch(図3の中央左のピンク色のアイコン)とAWS S3ストレージ(図3の中央右の緑色のバケツ)へ転送されます。
最後に、しきい値などのあらかじめ定めた基準に基づいて、Amazon SageMaker Model Monitorの監視結果が顧客や開発者に送信されます。
Amazon SageMaker Clarify
Amazon SageMaker Clarify(Clarify)は、説明変数の推論結果への寄与度を算出し可視化します。
また、特定の説明変数に関する正解ラベルや推論結果の偏りが、訓練用データや機械学習モデルに含まれることを検知します。
Clarifyによって、説明性の監視や、バイアスの監視が可能になります。
Amazon SageMaker Studio
Amazon SageMaker Studio(Studio)は、AWSにおける機械学習のための統合開発環境です。
図1のライフサイクルをAWSマネジメントコンソール画面の様にウェブベースのインターフェース上で行うことができ、SageMaker Studio Notebookを呼び出して機械学習モデルの精度を可視化することや、Model MonitorやClarifyが出力したレポートを確認することができます。
Model Monitor, Clarify, Studioを組み合わせることで、4つの監視技術を実現できます。
①: 精度の可視化(Model MonitorとStudio): 推論結果と正解ラベルを比較して精度などを算出し可視化します。
②: データ品質監視(Model MonitorとStudio): 推論用データの分布と学習用データの分布を比較します。
③: 説明可能性の可視化(ClarifyとStudio): SHapley Additive exPlanations(SHAP)3を使用して、機械学習モデルの推論結果がどの説明変数により強く依存するかを可視化します。
④: バイアスの監視(ClarifyとStudio): 特定の説明変数に対する機械学習モデルの推論結果の偏りを、複数のバイアスメトリックを算出して可視化します。バイアスメトリックには、KLダイバージェンス(2つの正規分布の類似度を定量化する指標)などがあります。
おわりに
今回の投稿では、機械学習モデルの監視技術の概要と、Amazon SageMakerで実現できる監視技術の概要を紹介しました。
次回以降の投稿では、米国の電話会社の顧客解約予測を題材として、Amazon SageMakerを利用して機械学習モデルの精度の可視化とデータ品質監視を実証した例を紹介します。
注釈
-
Jie Lu, et al., ”Learning under Concept Drift: A Review”, IEEE Transaction on Knowledge and Data Engineering, 2019. ↩
-
DARPA, “Explainable Artificial, Intelligence”, https://www.darpa.mil/program/explainable-artificial-intelligence ↩
-
Lundberg, S.M. and Lee, S.I., "A Unified Approach to Interpreting Model Predictions", 31st Conference on Neural Information Processing Systems (NIPS 2017), pp. 4765-4774. ↩