初版: 2021年4月20日
著者: 橋本恭佑、Nguyen Ba Hung
はじめに
以前の投稿から、機械学習モデルをビジネスへ適用するSEを対象として、Amazon SageMakerによって利用可能になる、機械学習モデル及びデータの傾向の監視技術を解説しています。今回の投稿では米国の電話会社の顧客解約予測を題材として、
精度の可視化とデータ品質監視を実機検証した結果を紹介します。
投稿一覧
- Amazon SageMakerで実現する機械学習モデルの監視技術
- Amazon SageMakerで実現する機械学習モデルの精度可視化とデータ品質監視・・・今回の投稿
- Amazon SageMakerで実現する機械学習モデルの説明可能性可視化とバイアス監視
データと実験
顧客解約予測データセット
今回は、Kaggleで公開されている、米国の携帯電話会社の顧客解約予測データセットを用いて検証を行います。 この顧客解約予測データセットは、1つの目的変数と69の説明変数を持っています。説明変数には、顧客の所在地(文字列だが、One-hot encodingするため2値)、毎日の時間帯毎の通話量(数値)、国際通話プランの加入有無(2値)や通話時間(数値)を含みます。
本実験ではデータセットを学習用(2333レコード)、検証用(665レコード)と推論用(333レコード)の3つのデータセットに分割し、推論用のデータセットを説明変数と目的変数を切り離して、説明変数を推論用データ、目的変数を正解ラベルとして利用します。また分割の際は学習用のデータセットと推論用のデータセットの両方に14%ずつ解約する顧客のデータがあるようにデータセットを分けました。
ところで、元のデータセットはドリフトやバイアスを引き起こすデータを含まないため、今回の実験ではデータドリフトを起こすために、顧客の所在地(2値)について通常とは異なる型(小数値)の推論用データを生成し途中から入力しました。
機械学習モデルの監視システム
今回はAmazon SageMakerの組み込みExtreme Gradient Boosting アルゴリズムを利用して学習した機械学習モデルをデプロイします。そして、この機械学習モデルに検証用データを送信して、モデルを監視します。今回実験に用いる機械学習モデルの監視システムの構成を図1に示します。図1の薄い赤で囲った範囲をSageMaker Studioを用いて起動・操作・閲覧できます。Model Monitor, Clarify, SageMaker Studioの紹介は以前の投稿を参照ください。
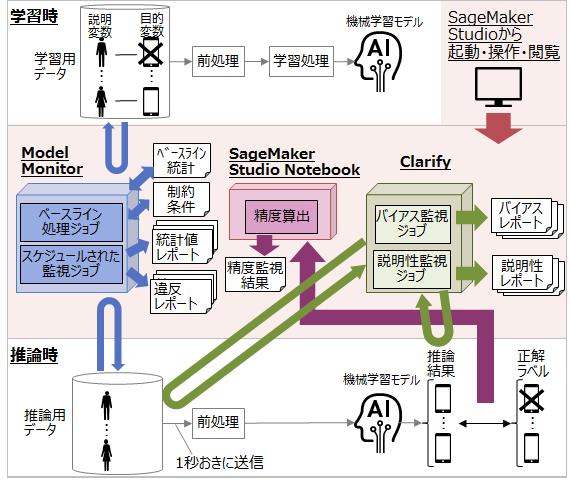
図1: システム構成図
精度の可視化はSageMakerのnotebookインスタンス上(図1中央の赤い直方体)で行います。一定時間毎にS3に格納された推論結果と正解ラベルを比較して、精度や適合率を算出します。
データ品質監視は、Model Monitorのベースライン処理ジョブとスケジュールされた監視ジョブにより行われます。以前の投稿で示したベースライン処理ジョブとスケジュールされた監視ジョブは同一のModel Monitorのインスタンス上(図1左の青い直方体)で実行されます。学習用データをModel Monitorへ入力すると、Model Monitorはベースライン処理ジョブを実行して、ベースライン統計と制約条件をS3ストレージへ出力します。またModel Monitorは、スケジュールされた監視ジョブを実行して、一定時間ごとに推論用データ、ベースライン統計および制約条件を比較し、S3ストレージやCloudWatchへ統計値や違反のレポートを出力します。
実験設定
図1に示したModel Monitorのインスタンス、SageMaker Studio Notebookインスタンス、SageMaker Clarifyのインスタンスはm5.xlargeインスタンス(CPU:4x 3.1 GHz Intel XeonR Platinum 8175M with AVX-512、メモリ:16GiB)としました。推論用データは毎秒2件ずつ機械学習モデルへ入力しました。さらに監視は1時間毎に行い、機械学習モデルが算出した解約の確率が0.8以上の場合に「解約」と判定します。
実験結果と考察
精度の可視化
SageMaker Studio Notebookを利用して精度、適合率、再現率、ROC曲線の下側の面積(AUCROC)の4つの指標をノートブックインスタンス上で計算し、SageMaker Studio上で可視化しました。図2は、機械学習モデルの20分ごとの4つの指標を示しています。
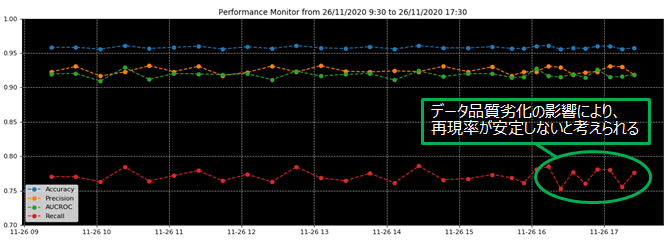
図2: 機械学習モデルの 20 分毎の精度、適合率、再現率、ROC 曲線
グラフのx軸は時刻であり、y軸の赤、緑、オレンジ、シアンの凡例はそれぞれ再現率、ROC曲線の面積、正答率、および精度を表しています。機械学習モデルの精度は95%を超えており、すべての推論用データを「解約しない」と予測する場合の精度(86%)よりも優れています。
今回の問題の様に、目的変数の配分のバランスがとれていない問題に対して、精度は有益な指標とは言えないため、他の指標として適合率、再現率、ROC曲線の下側の面積も可視化しました。精度は、解約すると推論した顧客の総数のうち、実際に解約した顧客の数の割合を示します。ROC曲線の面積(AUCROC)は、真陽性率(今回は実際に解約した顧客を「解約する」と予測する確率)を縦軸に、真陰性率(実際に解約しない顧客を「解約する」と予測する確率)を横軸にとったときの曲線の面積であり、その値が0.5を超えるとランダムな判定よりも優れていることを表します。今回はAUCROCの値が0.9以上で推移しており、作成した機械学習モデルが期間中、実際に解約した顧客を「解約する」と予測した事象が多かったことがわかります。
一方で、再現率は、実際に解約した顧客の中で、機械学習モデルが「解約する」と予測した顧客の割合を示していますが、それは75%から80%の範囲であり、16:00から17:30までの変動が大きいです。これは、途中からデータ品質監視の実験のために顧客の所在地(2値)について通常とは異なる型(小数値)の推論用データを流したことが原因です。図2の結果を通して、データ品質劣化の影響が再現率の変化に現れたことを確認できました。
データ品質監視
データ品質監視は、推論用データが学習用データと異なる特徴を持つデータになっていないかを監視する処理です。まず、ベースライン処理ジョブが、推論用データの特徴をベースライン統計と制約条件という2種類のデータとしてS3上に出力します。ベースライン統計には、欠落率、平均、最小、最大、標準偏差などの学習⽤データに関する統計値が含まれます。また、制約条件には、⽋損の有無、データ型、および⾮負など、学習用データの条件が含まれます。今回の実験におけるベースライン統計と制約条件を図3、図4に示します。
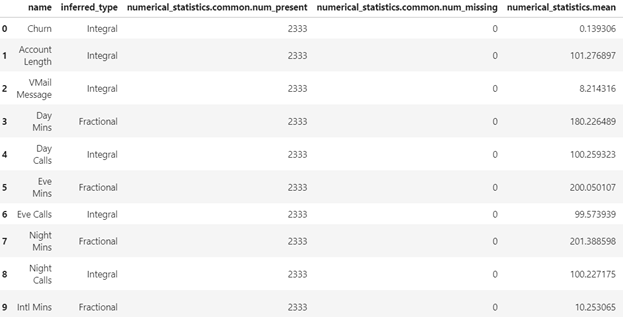
図3: ベースライン統計(最初の10個のデータ)
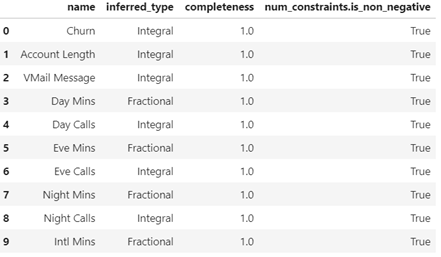
図4: 制約条件(最初の10個のデータ)
次に、スケジュールされた監視ジョブが、推論⽤データとベースライン統計および制約条件と比較し、1時間毎に推論⽤データの統計値と違反値を抽出し、S3ストレージに保存します。統計値と違反値はそれぞれstatistic.json、constraint_violations.jsonに⽰した様にjson形式で出⼒されます。今回の実験におけるstatistic.jsonとconstraint_violations.jsonを以下に示します。今回の推論用データでは、途中からデータ品質劣化検知の実験のために、顧客の所在地について、学習用データの際の型(2値)とは異なる型(小数値)を含み流しております。constraint_violations.jsonでは、violationとして、data_type_check(型違反)を検出しており、データの品質劣化を検知できたことがわかります。
{
"version" : 0.0, # 推論用データのバージョン
"dataset" : {
"item_count" : 7195 # 観測した推論用データの個数
},
"features" : […, { # 説明変数毎に統計値が出力される
"name" : "Account Length", # 説明変数の名前
"inferred_type" : "Integral", # 説明変数の値の型
"numerical_statistics" : { # 説明変数毎の統計値
"common" : { # 欠損値の有無
"num_present" : 7195,
"num_missing" : 0
},
"mean" : 99.98485059068798,
"sum" : 719391.0,
"std_dev" : 39.35913182019196,
"min" : 10.0,
"max" : 232.0,
"distribution" : { # 説明変数の分布に関連する情報
"kll" : {
"buckets" : [ {
"lower_bound" : 10.0,
"upper_bound" : 32.2,
"count" : 386.0
}, …{
"lower_bound" : 209.8,
"upper_bound" : 232.0,
"count" : 23.0
} ],
"sketch" : {
"parameters" : {
"c" : 0.64,
"k" : 2048.0
},
"data" : [ [ 112.0,… , 232.0 ] ]
}
}
}
}
},
]
{
"violations" : [ { # 違反のあった説明変数毎に情報が出力される
"feature_name" : "State_VT", # 説明変数名
"constraint_check_type" : "data_type_check", # 違反の種類
"description" : "Data type match requirement is not met. Expected data type: Integral, Expected match: 100.0%. Observed: Only 99.72482113373692% of data is Integral." # 違反の詳細な内容
}, … {
"feature_name" : "State_VA",
"constraint_check_type" : "data_type_check",
"description" : "Data type match requirement is not met. Expected data type: Integral, Expected match: 100.0%. Observed: Only 99.72482113373692% of data is Integral."
} ]
}
SageMaker Studioを利用すると、スケジュールされた監視ジョブの監視期間中の監視結果一覧を図5に示した画面で閲覧できます。図5の中央にある赤いテキストは、データの品質を監視している特定の期間中に問題があることを示しています。
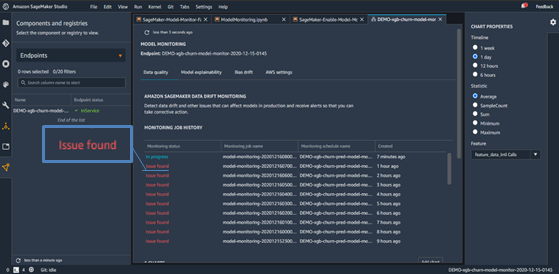
図5 スケジュールされた監視ジョブの監視結果一覧
図5の赤いテキストをクリックすることで、実際に品質に問題のあったデータを表示することができます。図6は、図5の赤字部分のある1行をクリックすると表示される、推論用データの違反値の一覧で、違反の詳細が示されています。図5と同様に図6にも、途中からデータ品質劣化検知の実験のために流した、顧客の所在地(2値)について通常とは異なる型(小数値)の推論用データが含まれていることが示されており、Model Monitorがデータ品質の問題を検知できたことがわかります。
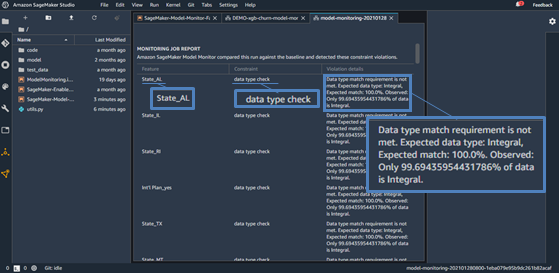
図6 推論用データの違反値の一覧
おわりに
今回の投稿では、Amazon SageMakerを利用して機械学習モデルの精度の可視化とデータ品質監視を実証した例を紹介しました。次回の投稿では、機械学習モデルの説明可能性の可視化とバイアス監視を検証した例を紹介します。