初版: 2021年7月27日
著者: 橋本恭佑, 河野泰隆、株式会社 日立製作所
はじめに
AI技術への注目の高まりに伴い、機械学習技術をビジネスへ適用するニーズが増えています。
ビジネスに機械学習技術を用いる場合、企業は機械学習モデルを作成・検証し実際の業務へ適用した後で、機械学習モデルの性能を監視します。
監視を通して機械学習モデルの精度劣化などを検知した場合は、企業は機械学習モデルの作成に利用したデータを見直し、機械学習モデルを再学習させることで、機械学習モデルの精度を維持する必要があります。
特に、データの傾向が時間経過とともに変化するビジネスにおいては、業務適用後に、データの傾向が機械学習モデルの作成・検証時のデータの傾向から変わる事象が何度も起こるため、再学習が繰り返し行われます。この投稿では、機械学習モデルの再学習効率化を目的として、パブリッククラウド(AWS)上で機械学習モデルの監視を通して精度劣化を検知し、精度劣化した機械学習モデルを自動で再学習させる方法を解説します。
今回作成する機械学習モデルの再学習機能の概要
題材とする問題の内容
この投稿では業務システムで利用されるコンピューティングリソースの性能値を予測する機械学習モデルの監視と再学習を題材とします。
今回の機械学習モデルは、業務システムで利用されるコンピューティングリソースのプロビジョニングを目的として、業務システムのワークロードから必要なコンピューティングリソースの性能値を推論します。
業務システムのワークロードは時間とともに変化するため、機械学習モデルの作成・検証時と推論時とでデータの傾向が変わり、推論精度が劣化する可能性があります。
そこで、機械学習モデルの推論の精度を監視し(機能1)、精度劣化を観測した場合に機械学習モデルを再学習させる(機能2)ことで、機械学習モデルの推論の精度を維持する仕組みための仕組みが必要となりました。
アーキテクチャ
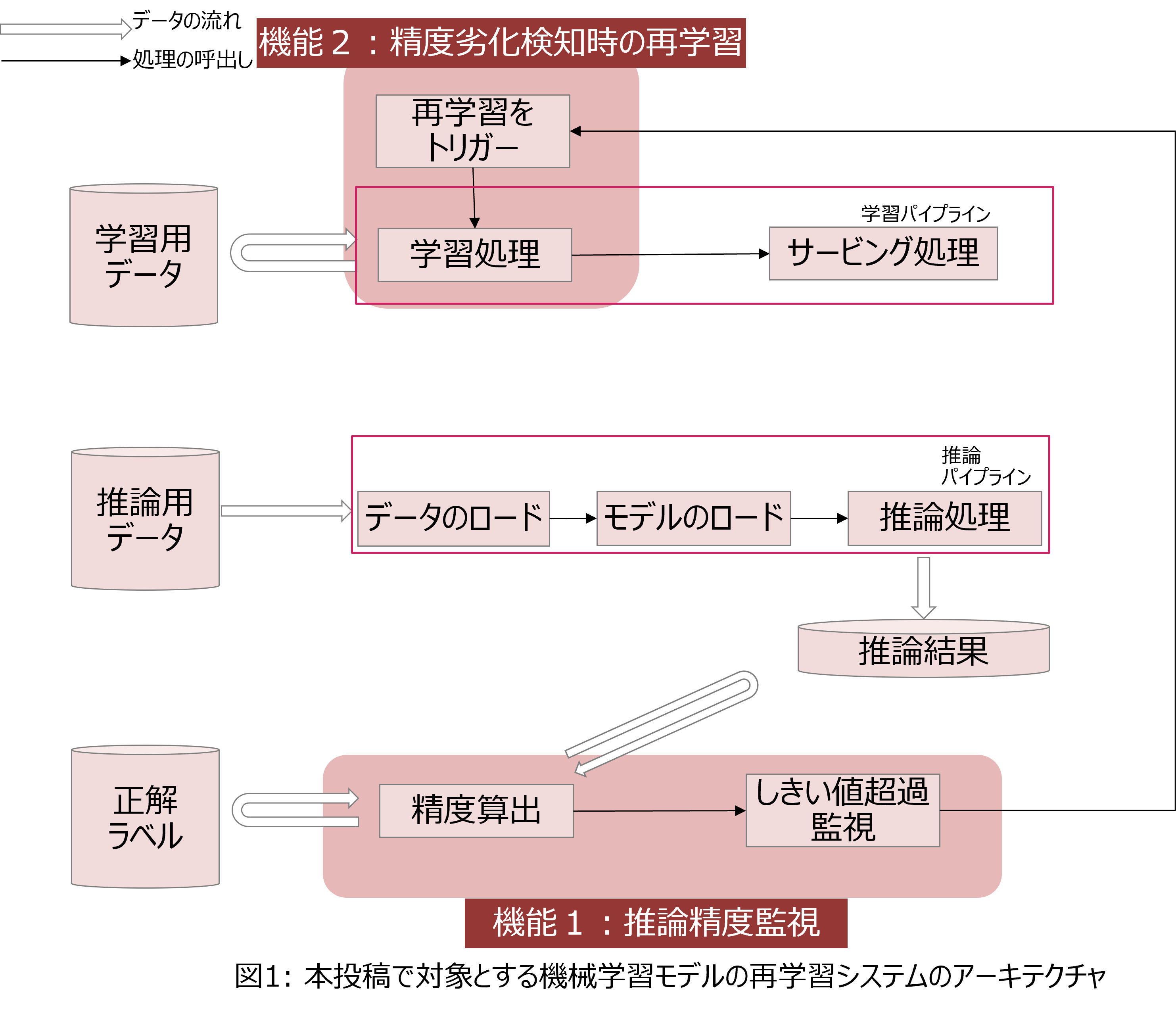
上記の機能1、機能2を実現する、機械学習モデルの運用管理のためのシステムのアーキテクチャを図1に示します。「機能1: 推論精度監視」は、実際の性能値(正解ラベル)がアップロードされる都度、機械学習モデルの推論結果と正解ラベルを自動で比較し、精度を算出して、前もって定めた精度のしきい値を下回らないかを確認します。また、「機能2: 精度劣化検知時の再学習」は、推論精度が前もって定めた精度のしきい値を下回った場合に、機械学習モデルの推論精度が劣化したとみなして、自動で機械学習モデルを再学習させます。
Amazon SageMakerにより実現可能な範囲と追加開発項目
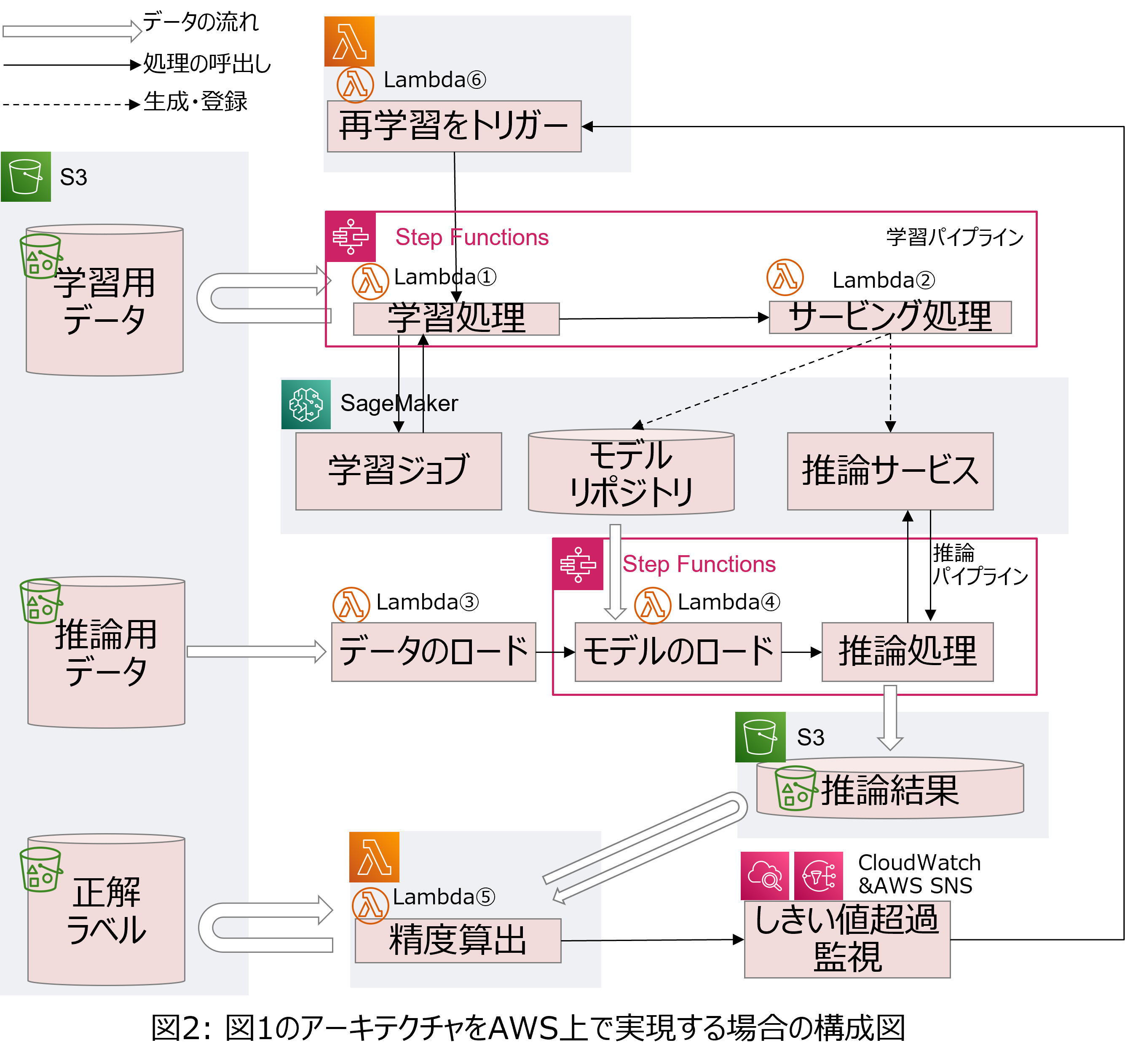
図 1に示したアーキテクチャをAWSで実現する場合の構成図の例を図 2に示します。機械学習モデルの学習ジョブ・モデル管理・バッチでの推論処理はAmazon SageMakerを用いて実装できます。一方で、今回の様なバッチでの推論精度監視には、SageMaker Model Monitorを利用できないため、別途開発が必要となります。
さらに、機械学習モデルの再学習についても、Amazon SageMakerの学習ジョブを起動する機能の開発が必要となります。今回は、バッチでの推論精度監視を、AWS Lambda、Amazon CloudWatch、Amazon SNSを利用して開発しました。また、精度劣化検知時の再学習機能を、AWS Step FunctionsとAWS Lambdaを利用して開発しました。
各機能の動作フロー
機能1:推論精度監視
(1) 推論パイプラインの実行
まず、推論パイプラインをAWS Step Functionsのワークフローとして実現します。ワークフローを定義したステートマシンのソースコードを下記に示します。推論パイプラインは、推論用データが到着してから、AWS Lambda関数(図2のLambda③)によって開始されます。AWS Lambda関数(図2のLambda③)は、推論用データに含まれる、予測対象となるコンピューティングリソースや性能値(以降、メタデータと呼称)を抽出して、推論パイプラインに送信します。
{
"StartAt": "Resolve Model",
"States": {
"Resolve Model": { ・・・図2のLambda④を呼び出して、対象のモデルを検索
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "computer-pred-demo-model-resolver",
"Payload": {
"ThingName.$": "$.thing_name",
"ResourceType.$": "$.res_type",
"PredictionColumn.$": "$.pred_col"
}
},
"ResultPath": "$.resolve_result",
"Next": "Model found or not"
},
"Model found or not": { ・・・対象のモデルの有無を判定
"Type": "Choice",
"Choices": [
{
"Variable": "$.resolve_result.Payload.statusCode",
"NumericEquals": 200,
"Next": "Batch transform"
}
],
"Default": "Model not found"
},
"Batch transform": { ・・・対象のモデルを使用して推論を実行
"Type": "Task",
"Resource": "arn:aws:states:::sagemaker:createTransformJob.sync",
"Parameters": {
"ModelName.$": "$.resolve_result.Payload.body",
"BatchStrategy": "MultiRecord",
"MaxConcurrentTransforms": 1,
"MaxPayloadInMB": 6,
"TransformInput": {
"CompressionType": "None",
"ContentType": "text/csv",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri.$": "States.Format('{}', $.inference_data_path)"
}
},
"SplitType": "Line"
},
"TransformOutput": {
"S3OutputPath.$": "States.Format('{}/output/', $.output_path)"
},
"TransformResources": {
"InstanceCount": 1,
"InstanceType": "ml.m5.xlarge"
},
"TransformJobName.$": "$$.Execution.Name"
},
"End": true
},
"Model not found": {
"Type": "Fail",
"Cause": "No model having ResourceType and PredictionColumn specified!"
}
}
}
AWS Lambda関数(図2のLambda③)からメタデータを受信した推論パイプラインは、"Resolve Model"でAWS Lambda関数(図 2のLambda④)を呼び出し、予測対象とする機械学習モデルをロードします。機械学習モデルにはメタデータがタグとして付与されているため、AWS Lambda関数ではこれらのタグを元に、推論に用いる機械学習モデルの有無を検索します。タグは機械学習モデルの学習パイプライン内で付与されます(詳細は後述します)。指定された機械学習モデルが存在する場合は、SageMakerのバッチ変換ジョブが呼び出されて("Batch Transform")、機械学習モデルに推論用データが入力され、推論を実行します。推論が実行されて結果がS3ストレージに格納されると、処理を終了します。
(2) 推論精度の算出
次に、精度算出を行う処理の実現方法について述べます。今回のサンプルでは簡単に、AWS Lambda関数(図 2のLambda⑤)を用いて実現しました。
精度算出のためのAWS Lambda関数は、S3ストレージのイベント通知機能を利用して、正解ラベルがS3ストレージへ格納されると実行されます。推論結果と正解ラベルをS3ストレージからロードして、あらかじめ実装したアルゴリズムに基づき精度を算出して、算出結果をCloudWatchに出力すると終了します。
(3) 推論精度の監視と再学習のトリガー
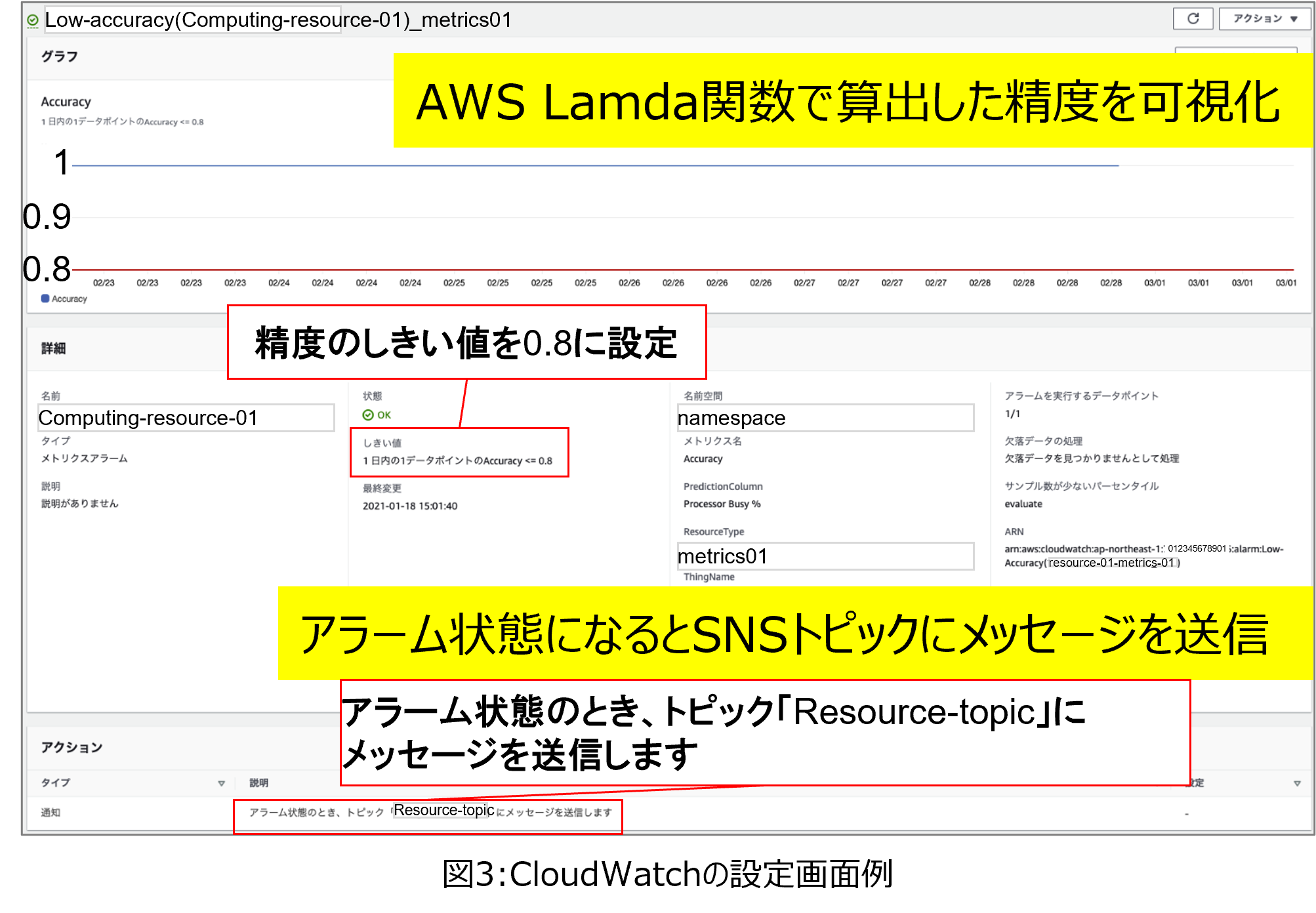
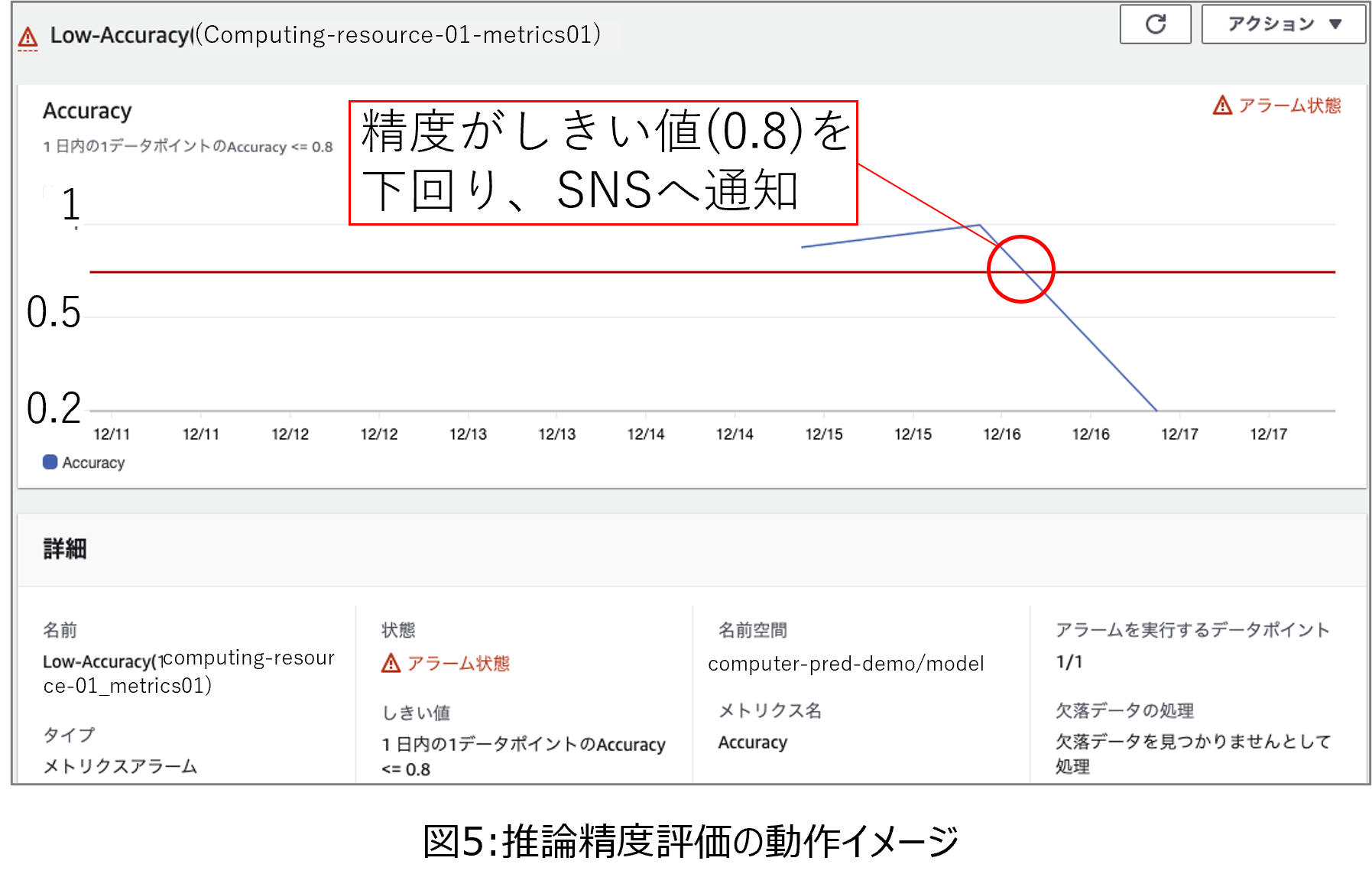
次に、推論精度の記録としきい値超過監視のためのCloudWatchの設定画面を図3に示します。図3の上側のグラフは、縦軸を精度、横軸を時刻としており、青のグラフが推論精度、赤のグラフがあらかじめ定めたしきい値を示します。たとえば図3ではしきい値を0.8と設定しており、青の凡例で示した精度が0.8を下回った場合、CloudWatchはAWS SNSへメッセージを送信します。AWS SNSはCloudWatchからメッセージを受信すると、再学習を実行する様にAWS Lambda関数へのトリガーをかけます。
再学習のトリガーをかけるAWS Lambda関数では、再学習に用いる学習用データの範囲を選択します。学習用データを決定した後で、学習用データのcsvファイルを生成し,学習パイプラインを実行します。
機能2:精度劣化検知時の再学習
学習パイプラインをAWS Step Functionsのワークフローとして実現します。ワークフローを定義したステートマシンのソースコードを下記に示します。
学習パイプラインは、AWS Lambda関数(図2のLambda⑥)から再学習リクエストを受信すると開始されます。AWS Lambda関数(図2のLambda⑥)は、再学習の対象とする機械学習モデルのメタデータ(予測対象となるコンピューティングリソースやメトリクス)を学習パイプラインへ送信します。
{
"StartAt": "Decide targets",
"States": {
"Decide targets": { ・・・図2のLambda①を実行して、対象のモデルを検索
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "computer-pred-demo-train-target-decider",
"Payload.$": "$"
},
"ResultPath": "$.target_result",
"Next": "Target found or not"
},
"Target found or not": { ・・・対象のモデルの有無を判定
"Type": "Choice",
"Choices": [
{
"Variable": "$.target_result.Payload.statusCode",
"NumericEquals": 200,
"Next": "Train models"
}
],
"Default": "Target not found"
},
"Train models": { ・・・対象のモデルを再学習して保存
"Type": "Map",
"ItemsPath": "$.target_result.Payload.body.targets",
"Iterator": {
"StartAt": "Resolve experiment",
"States": {
"Resolve experiment": {・・・図2のLambda②を実行して、再学習の対象とする機械学習モデルの過去の学習の記録を取得
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "computer-pred-demo-experiment-resolver",
"Payload.$": "$"
},
"ResultPath": "$.experiment_result",
"Next": "Train model"
},
"Train model": { ・・・対象のモデルを再学習させる
"Type": "Task",
"Resource": "arn:aws:states:::sagemaker:createTrainingJob.sync",
"Parameters": {
"AlgorithmSpecification": {
"TrainingImage": "012345678901.dkr.ecr.ap-northeast-1.amazonaws.com/computer-pred-training:latest",
"TrainingInputMode": "File",
"MetricDefinitions": [
{
"Name": "RMSE",
"Regex": "RMSE=(.*?);"
},
{
"Name": "R2",
"Regex": "R2=(.*?);"
}
]
},
"EnableManagedSpotTraining": true,
"CheckpointConfig": {
"S3Uri.$": "$.checkpoint_path"
},
"OutputDataConfig": {
"S3OutputPath.$": "$.output_path"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 3600,
"MaxWaitTimeInSeconds": 3600
},
"ResourceConfig": {
"InstanceCount": 1,
"InstanceType": "ml.m5.xlarge",
"VolumeSizeInGB": 30
},
"RoleArn": "arn:aws:iam::012345678901:role/SageMakerExecutionRole",
"InputDataConfig": [
{
"DataSource": {
"S3DataSource": {
"S3DataDistributionType": "ShardedByS3Key",
"S3DataType": "S3Prefix",
"S3Uri.$": "States.Format('{}', $.train_data_path)"
}
},
"ChannelName": "train",
"ContentType": "text/csv"
},
{
"DataSource": {
"S3DataSource": {
"S3DataDistributionType": "ShardedByS3Key",
"S3DataType": "S3Prefix",
"S3Uri.$": "States.Format('{}', $.test_data_path)"
}
},
"ChannelName": "testing",
"ContentType": "text/csv"
}
],
"HyperParameters": {
"fit_args.$": "$.fit_args",
"feature_importance": "true"
},
"ExperimentConfig": {
"ExperimentName.$": "$.experiment_result.Payload.body.experiment"
},
"TrainingJobName.$": "States.Format('{}-{}', $$.Execution.Name, $.id)"
},
"ResultPath": "$.train_result",
"Next": "Save Model"
},
"Save Model": { ・・・再学習させたモデルを保存する
"Type": "Task",
"Resource": "arn:aws:states:::sagemaker:createModel",
"Parameters": {
"PrimaryContainer": {
"Image": "012345678901.dkr.ecr.ap-northeast-1.amazonaws.com/computer-pred-inference:latest",
"Environment": {},
"ModelDataUrl.$": "$.train_result.ModelArtifacts.S3ModelArtifacts"
},
"Tags": [
{
"Key": "ThingName",
"Value.$": "$.thing_name"
},
{
"Key": "ResourceType",
"Value.$": "$.res_type"
},
{
"Key": "PredictionColumn",
"Value.$": "$.pred_col"
}
],
"ExecutionRoleArn": "arn:aws:iam::012345678901:role/SageMakerExecutionRole",
"ModelName.$": "$.train_result.TrainingJobName"
},
"ResultPath": "$.save_result",
"End": true
}
}
},
"End": true
},
"Target not found": {
"Type": "Fail",
"Cause": "No target!"
}
}
}
学習パイプラインが再学習リクエストを受信すると、学習パイプラインは"Decide targets"で、別のAWS Lambda関数(図 2のLambda①)を実行して、再学習リクエストと同時に受信したメタデータと一致するタグを持つ機械学習モデルを取得します。機械学習モデルを取得できた場合("Target found or not")、学習パイプラインは"Resolve experiment"でAWS Lambda関数(図 2のLambda②)を実行して、再学習の対象とする機械学習モデルの、過去の学習の記録を取得します。そして、再学習のための学習用データを用いて機械学習モデルの学習処理を"Train model"で実行します。ここで、SageMakerの学習ジョブが実行されます。
SageMakerの学習ジョブが完了すると、学習パイプラインは"Save Model"で、メタデータを機械学習モデルのタグとして付与して、機械学習モデルをS3ストレージに保存し、再学習の記録をモデル管理に保存します。
動作検証
検証シナリオ
機能検証のため、推論用データを毎日23時にアップロードするAWS Lambda関数を用意して、作成したサンプルに入力しました。また、精度評価は毎日0時に前日の推論結果に対する精度評価を実施しました。推論精度劣化を起こすダミーデータを用意して、精度がしきい値を下回る現象(しきい値超過)を起こして再学習させました。再学習に利用する学習用データの範囲は、推論精度がしきい値を下回った時刻から1週間前までとしました。
動作検証
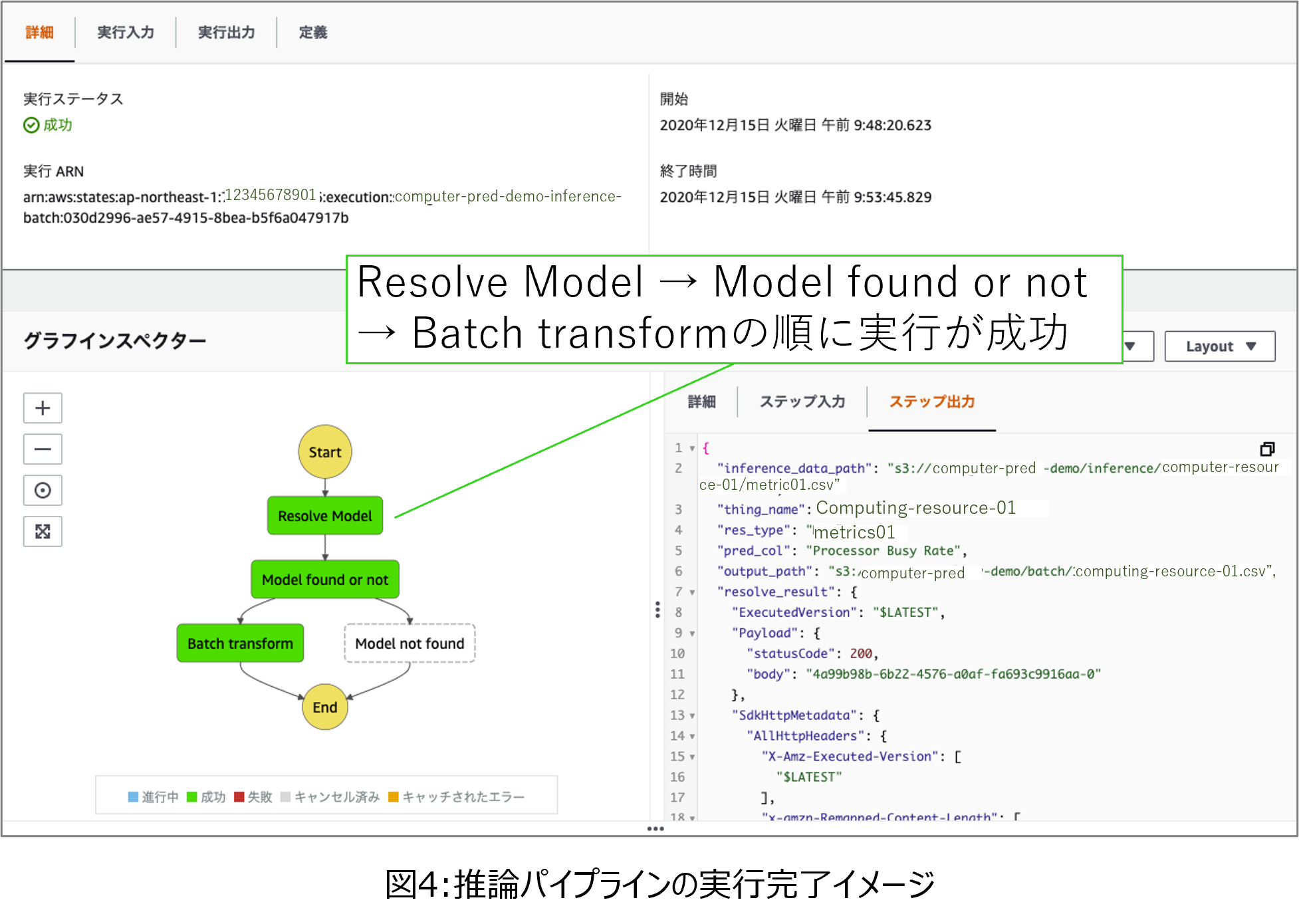
まず、AWS Lambda関数が23時に推論用データを入力すると、推論パイプラインが実行されます。この推論パイプラインでは、対象の機械学習モデルをロードし、データを入力して推論を実行し、推論結果をS3ストレージに格納します。推論が完了した時のイメージを図4に示します。図4の下の左側のステートマシンは推論パイプラインであり、実行が成功した部分が緑色で示されています。
次に、0時になるとAWS Lambda関数が実行されて、前日の推論結果に対する精度を評価します。精度を評価してCloudWatchで可視化した画面を図5に示します。図5の上側のグラフの縦軸が推論精度、横軸が時刻です。推論精度(青色の凡例)がしきい値(赤色の凡例。今回は0.8)を下回ったことから、精度劣化を検知したことがわかります。このような状態になると、CloudWatchはAWS SNSへメッセージを送信して、AWS SNSが再学習のトリガーをかけると、AWS Lambda関数によって再学習のための学習パイプラインが実行されます。
最後に、再学習時の学習パイプラインの実行完了イメージを図6に示します。図6の下の左側のステートマシンが学習パイプラインを示しており、実行が成功した部分が緑色で示されています。
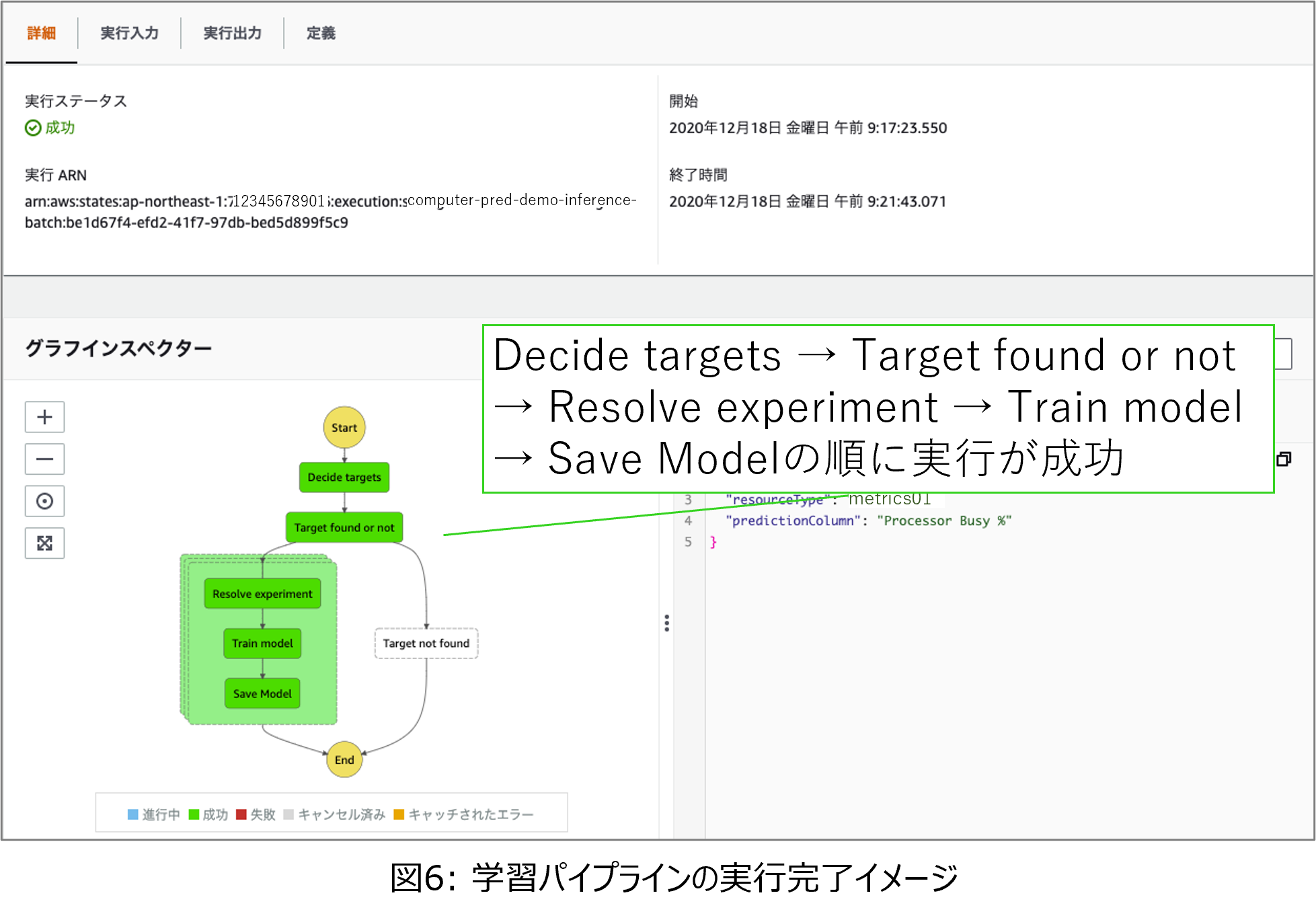
図4、図5、図6で示した結果より、今回作成したサンプルの推論精度監視機能と、精度劣化検知時の再学習機能の動作を確認できました。
おわりに
本記事では機械学習モデルの監視を通して精度劣化などを検知した後の、機械学習モデルの再学習を、AWSのSageMakerの機能を用いて実現する方法について紹介しました。