課題提起
タテヨコのデータセットをが手元にあるとします。
強烈に大きなデータでなければ、pythonのpandasのread_csvで読んで概観を掴む時に、まずは.describe()で各種統計量が把握できますが、次の一手でカラムごとの分布って見たくなりません?
この記事では、matplotlib, pandas plot, seabornの3つの描画ライブラリを使って、ほぼ一気に各カラムの分布を描画するコードを紹介します。
環境
python 3.6
ライブラリ群の準備
冒頭に書いたように、matplotlib, pandas, seabornを読み込んでおきます。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
データの読み込み&データフレーム作成
この例ではload_bostonをベースにしますが、自前のデータでもいいですよ。
from sklearn.datasets import load_boston
X = load_boston()
X.feature_names
# array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
df = pd.DataFrame(X.data, columns=X.feature_names)
df.head()
データはこんな感じ:

で、冒頭に書いた.describe()をやっとくと、、
df.describe()
こんな感じ:

まぁ、そんなもんか、と。
分布を確認って?
データを見る時、字面じゃなくて絵的に見えた方が直感に訴えることもありますよね。
まずはヒストグラム、というか分布を描いてみよう、と(この記事の目標)
データセットdfのカラムCRIMの分布(ヒストグラム)を確認してみます。
matplotlibの場合
plt.hist(df['CRIM'])

pandas plotの場合
pandasの描画機能を使うと
df['CRIM'].plot(kind='hist')

seabornの場合
なんかヤケにbinが細いな、、、
sns.histplot(df['CRIM'])

ただ、カラムごとにこれやるのツラいですよね。。
で、カラムごとの分布を出力しよう。
取り敢えず、たくさんグラフを出すので少し大きめに出力するようにしておきましょう:
fig = plt.figure(figsize=(25, 25))
この後、先ほどと同様に3通り(matplotlib, pandas plot, seaborn)で一気に出力するコードを書いてみます。
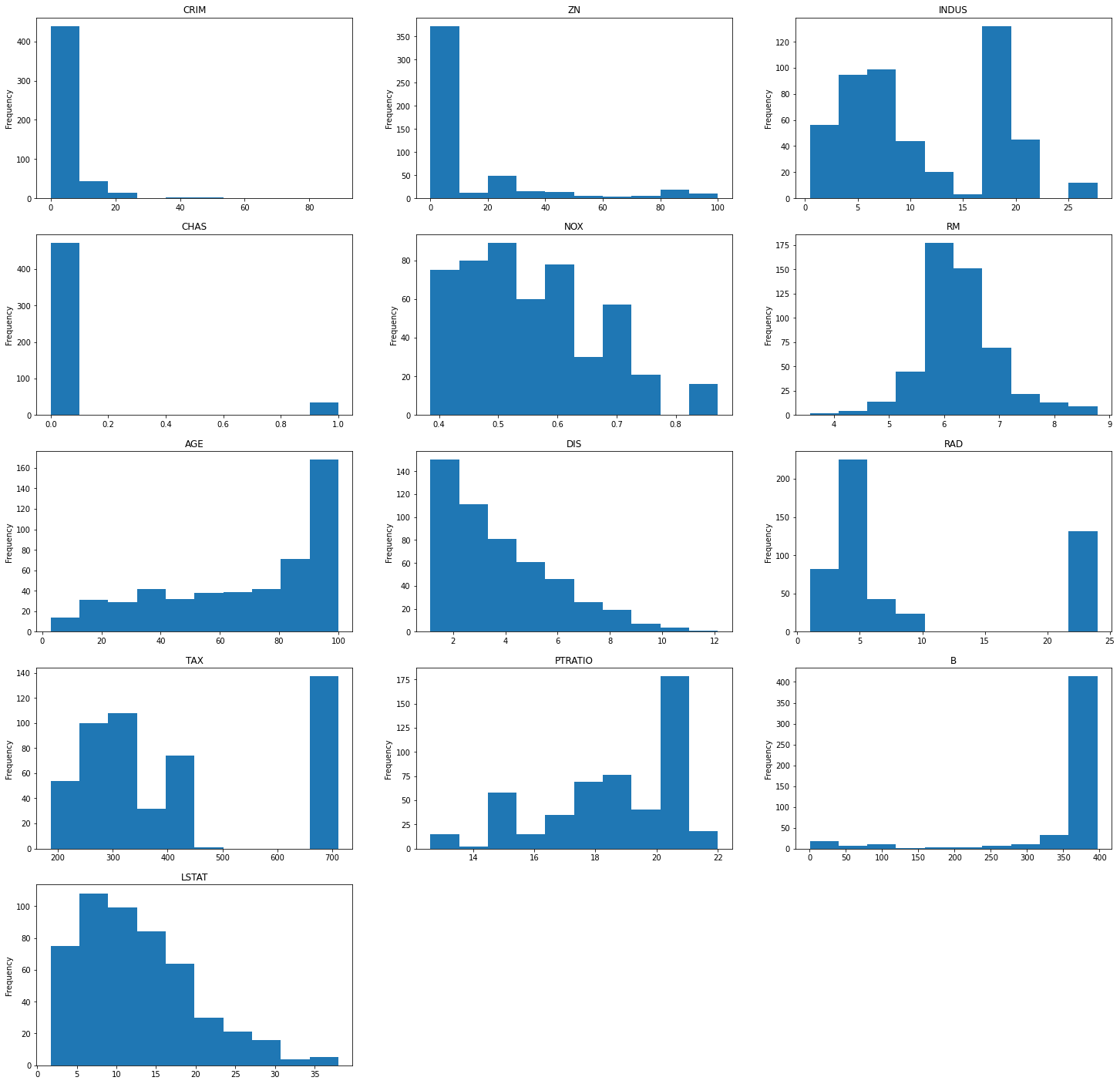
matplotlibで一気に出力
for i, col in enumerate(df.columns):
plt.subplot2grid((5, 3), (i//3, i%3))
plt.hist(df[col])
plt.title(col)

ポイント
for i, col in enumerate(df.columns):
plt.subplot2grid((5, 3), (i//3, i%3))
- アイデアの源泉はココ。
forループでカラムを1つずつ取って並べりゃいいだろう、と。enumerateでグラフに順番iを付けて描いていきます。 -
plt.subplot2gridでそれを実現します。グリッド状に並べていきます。-
(5,3)のところは、縦に5つ、横に3つ並べる、という意味。load_bostonはカラムが13あります。5 x 3=15のグリッドを用意しておけば全部描き切れますね。 -
(i//3, i%3)は、グリッドの座標みたいな感じ。i//3はiを3で割った時の商、i%3は余り。イメージ的には↓な感じです。
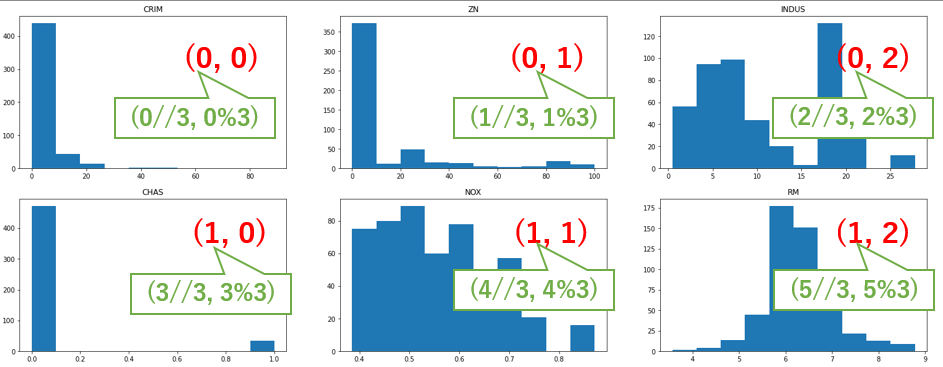
- 残りの
plt.hist(df[col])で描画、plt.title(col)でタイトルを表示、、、てのをcolごとに実行します。色味を変えたり、グリッドの大きさを変えたりする場合は適宜引数を変えたり、、、などは、Referenceを眺めてみて下さい!
-
pandas plotで出力
基本的なアイデアは一緒ですが、pandas plotった場合のコード:
for i, col in enumerate(df.columns):
ax = plt.subplot2grid((5, 3), (i//3, i%3))
df[col].plot(kind='hist', ax=ax)
ax.set_title(col)
seabornで出力
同じくseabornだとこんな感じ:
for i, col in enumerate(df.columns):
ax = plt.subplot2grid((5, 3), (i//3, i%3))
sns.histplot(df[col], ax=ax)
ax.set_title(col)
