はじめに
こんにちは。普段はAWSのインフラエンジニアとして働いており、CloudFormationでのインフラ構築を主に行ってきました。
最近、Terraformを使ったインフラ構築やテスト駆動開発(TDD)に興味を持ち、実際に手を動かして学んでみようと思い立ちました。特に、Lambdaを使った開発でどのようにTDDを取り入れるべきか調べる中で、LocalStackという素晴らしいツールに出会いました。
LocalStackを使えば、ローカル環境でAWSサービスをエミュレートでき、コストをかけずに本番環境と同等の挙動確認ができます。以下のような場合に特に有効です。
- 個人学習でAWSリソースにコストをかけたくない
- 何度もリソースの作成・削除を繰り返すテスト開発を行いたい
- 業務でもリソースに最低限のコストしか割けない
本記事では、データ基盤構築において基本的で重要なパターンの一つである「S3イベント駆動型バッチ処理パイプライン」を題材に、Terraform + LocalStackを使った構築手順を紹介します。
【対象読者】
- TerraformでAWSリソースを管理してみたい方
- LocalStackを使ったローカル開発環境に興味がある方
- S3イベント駆動型の処理フローを実装してみたい方
- インフラエンジニアでプログラミング学習を進めている方
今回構築するシステム
本記事では、S3にログファイルがアップロードされると自動的にデータを処理してDynamoDBに格納する、イベント駆動型のバッチ処理パイプラインを構築します。
システム全体像
以下の図が今回構築するシステムの全体像です。
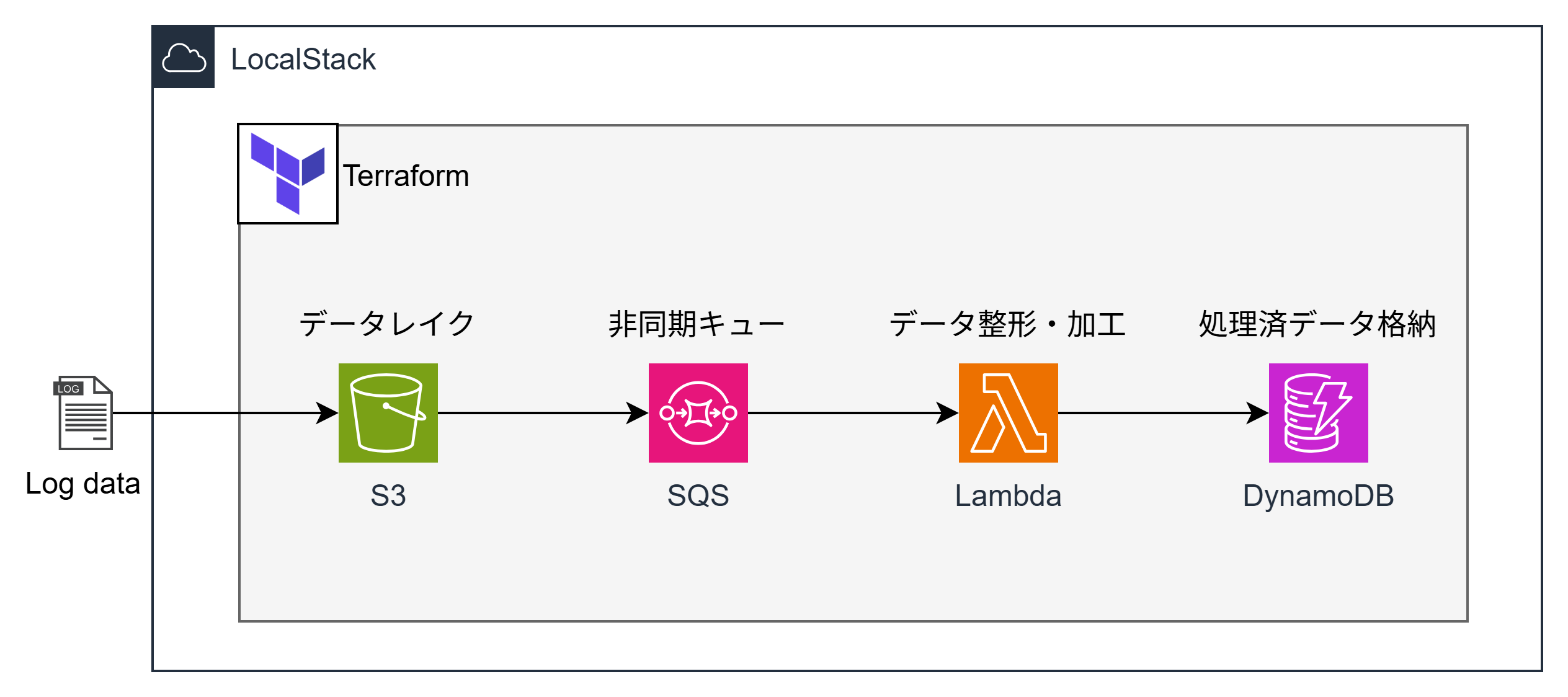
処理の流れは次の通りです。
- データレイク(S3): ログファイルなどの生データをS3バケットにアップロード
- イベント通知(S3 → SQS): S3がファイルアップロードを検知し、SQSキューにイベント通知を送信
- 非同期キュー(SQS): イベントメッセージをキューイングし、処理の信頼性を確保
- データ整形・加工(Lambda): Lambda関数がSQSキューをポーリングし、データを読み込んで整形・加工
- 処理済データ格納(DynamoDB): 加工済みデータをDynamoDBテーブルに保存
各コンポーネントの役割
| 構成要素 | 役割 | LocalStackサービス |
|---|---|---|
| データレイク | 生データファイルの投入先。 | S3 |
| イベント通知 | ファイルアップロードを検知。 | S3 -> SQS |
| ワークキュー | 処理の信頼性を高める非同期キュー。 | SQS |
| データ変換 | キューをポーリングし、データを整形・加工。 | Lambda |
| 格納先 | 処理済みデータを格納。 | DynamoDB |
| 自動化 | 全リソースをコードで定義。 | Terraform |
なぜこの構成なのか
SQSを間に挟む理由
S3からLambdaを直接起動することも可能ですが、本構成ではあえてSQSを間に挟んでいます。これには以下のメリットがあります。
- 処理の信頼性向上: Lambda実行が失敗した場合、メッセージがキューに残り、自動的にリトライされる
- スケーラビリティ: 大量のファイルが同時にアップロードされた場合も、キューでバッファリングし順次処理できる
- 柔軟性: S3とLambdaの間を緩やかに繋ぐことで、片方の仕様変更や機能追加が容易になる
このように、実務で求められる堅牢性を意識した構成になっています。次章では、この構成をLocalStack上で再現するための環境構築手順を説明します。
環境構築
本章では、TerraformとLocalStackを使ってローカル環境でAWSリソースを構築するための準備を行います。
前提条件
以下のツールが必要です。事前にインストールしておいてください。
| ツール | バージョン | 用途 |
|---|---|---|
| Docker | 20.x以上 | LocalStackの実行環境 |
| Python | 3.x | LocalStack CLIのインストールに必要 |
| pip | 最新版 | Pythonパッケージ管理 |
| Terraform | 1.5.x以上 | インフラのコード管理 |
確認コマンド
docker --version
python3 --version
pip --version
terraform --version
LocalStackのセットアップ
LocalStackはDockerコンテナとして動作します。まず、LocalStack CLIをインストールします。
# pipを使ってLocalStack CLIをインストール
pip install localstack
インストール確認
localstack --version
LocalStackの起動
# LocalStackをバックグラウンドで起動
localstack start -d
起動確認は以下のコマンドで行います。
curl http://localhost:4566/_localstack/health
LocalStack Terraform CLI(tflocal)のインストール
LocalStackにTerraformでリソースをデプロイする際、エンドポイントをLocalStackに向ける必要があります。tflocalコマンドを使うことで、この設定を自動的に行えます。
# pipを使ってインストール
pip install terraform-local
インストール確認
tflocal --version
tflocalは内部でterraformコマンドを呼び出しつつ、LocalStack用の環境変数を自動設定してくれる便利なラッパーツールです。
Terraformの初期設定
Terraformのプロジェクトディレクトリを作成し、初期化を行います。
# プロジェクトディレクトリの作成
mkdir s3-event-pipeline
cd s3-event-pipeline
# Terraform初期化
tflocal init
以上で環境構築は完了です。次章では、実際にTerraformコードを書いてAWSリソースを定義していきます。
Terraformコードの実装
本章では、S3イベント駆動型バッチ処理パイプラインを構成する各AWSリソースをTerraformで定義していきます。
ディレクトリ構成
まず、プロジェクトのディレクトリ構成は以下の通りです。
.
├── event
│ └── event.json # テスト用SQSメッセージ
├── function
│ ├── dist
│ │ └── server-log-lambda.zip # Lambda デプロイパッケージ
│ └── src
│ └── main.py # Lambda関数本体
├── iam_policy.tf # IAMポリシー定義
├── log
│ └── server-log.json # テスト用ログファイル
├── main.tf # メインのリソース定義
└── providers.tf # プロバイダー設定
Terraformファイルは役割ごとに分割し、可読性と保守性を高めています。
providers.tf - プロバイダー設定
AWSプロバイダーの設定を行います。LocalStackで動作させる場合も、この設定がベースとなります。
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.92"
}
}
required_version = ">= 1.2"
}
provider "aws" {
region = "ap-northeast-1"
}
tflocalコマンドを使うことで、エンドポイントが自動的にLocalStackに向けられます。
main.tf - 主要リソースの定義
メインとなるAWSリソースを定義します。以下、セクションごとに解説します。
S3バケット名のユニーク化
S3バケット名はグローバルで一意である必要があるため、ランダム文字列を使って衝突を避けます。
resource "random_string" "bucket_suffix" {
length = 8
special = false
upper = false
numeric = true
}
resource "aws_s3_bucket" "server_log" {
bucket = "row-data-server-log-bucket-${random_string.bucket_suffix.result}"
}
S3イベント通知の設定
S3バケットに.jsonファイルがアップロードされたら、SQSキューに通知を送るように設定します。
resource "aws_s3_bucket_notification" "bucket_notification" {
depends_on = [aws_sqs_queue_policy.server_log_queue_policy]
bucket = aws_s3_bucket.server_log.id
queue {
queue_arn = aws_sqs_queue.server_log_queue.arn
events = ["s3:ObjectCreated:*"]
filter_suffix = ".json"
}
}
ポイント: depends_onでSQSキューポリシーが作成されるのを待つことで、権限不足エラーを防ぎます。
SQSキューとポリシー
SQSキューを作成し、S3からメッセージを受信できるようにポリシーを設定します。
resource "aws_sqs_queue" "server_log_queue" {
name = "server-log-queue"
}
data "aws_iam_policy_document" "sqs_allow_s3" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["s3.amazonaws.com"]
}
actions = ["sqs:SendMessage"]
resources = [aws_sqs_queue.server_log_queue.arn]
condition {
test = "ArnEquals"
variable = "aws:SourceArn"
values = [aws_s3_bucket.server_log.arn]
}
}
}
resource "aws_sqs_queue_policy" "server_log_queue_policy" {
queue_url = aws_sqs_queue.server_log_queue.id
policy = data.aws_iam_policy_document.sqs_allow_s3.json
}
ポイント: aws_iam_policy_documentデータソースを使うことで、ポリシーJSONを可読性高く記述できます。
Lambda関数とイベントソースマッピング
Lambda関数を定義し、SQSキューからメッセージを受信するように設定します。
resource "aws_iam_role" "lambda_execution_role" {
name = "server-log-role"
assume_role_policy = data.aws_iam_policy_document.assume_role.json
}
data "archive_file" "server_log" {
type = "zip"
source_dir = "${path.module}/function/src"
output_path = "${path.module}/function/dist/server-log-lambda.zip"
}
resource "aws_lambda_function" "server_log_function" {
function_name = "server-log-function"
handler = "main.lambda_handler"
runtime = "python3.12"
role = aws_iam_role.lambda_execution_role.arn
filename = "${path.module}/function/dist/server-log-lambda.zip"
source_code_hash = data.archive_file.server_log.output_base64sha256
}
resource "aws_lambda_event_source_mapping" "server_log_queue_mapping" {
event_source_arn = aws_sqs_queue.server_log_queue.arn
function_name = aws_lambda_function.server_log_function.arn
batch_size = 10
scaling_config {
maximum_concurrency = 100
}
}
ポイント: archive_fileデータソースで自動的にZIPファイルを作成し、source_code_hashで変更を検知してデプロイします。
DynamoDBテーブル
処理済みデータを格納するDynamoDBテーブルを作成します。
resource "aws_dynamodb_table" "server_logs_table" {
name = "ServerLogsTable"
billing_mode = "PAY_PER_REQUEST"
hash_key = "PK"
range_key = "SK"
attribute {
name = "PK"
type = "S"
}
attribute {
name = "SK"
type = "S"
}
tags = {
Name = "ServerLogsTable"
}
}
ポイント: PAY_PER_REQUESTモードを使うことで、キャパシティ管理が不要になります。
iam_policy.tf - IAMポリシーの定義
Lambda関数が各AWSサービスにアクセスするために必要な権限を定義します。
data "aws_iam_policy_document" "lambda_policy" {
# CloudWatch Logs
statement {
effect = "Allow"
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
]
resources = ["arn:aws:logs:*:*:*"]
}
# DynamoDBへの書き込み
statement {
effect = "Allow"
actions = [
"dynamodb:PutItem",
"dynamodb:BatchWriteItem",
]
resources = ["${aws_dynamodb_table.server_logs_table.arn}"]
}
# S3からオブジェクトを読み取る
statement {
effect = "Allow"
actions = ["s3:GetObject"]
resources = ["${aws_s3_bucket.server_log.arn}/*"]
}
# SQSからメッセージを受信/削除する
statement {
effect = "Allow"
actions = [
"sqs:ReceiveMessage",
"sqs:DeleteMessage",
"sqs:GetQueueAttributes",
]
resources = ["${aws_sqs_queue.server_log_queue.arn}"]
}
}
resource "aws_iam_policy" "lambda_policy" {
name = "lambda_server_log_policy"
description = "Policy for Lambda to read S3, manage SQS, and write to DynamoDB."
policy = data.aws_iam_policy_document.lambda_policy.json
}
resource "aws_iam_role_policy_attachment" "lambda_policy_attach" {
role = aws_iam_role.lambda_execution_role.name
policy_arn = aws_iam_policy.lambda_policy.arn
}
ポイント: 必要最小限の権限のみを付与する「最小権限の原則」に従い、各サービスごとに明示的に権限を定義しています。
リソース間の依存関係
Terraformは自動的にリソース間の依存関係を解決しますが、特に以下の点に注意が必要です。
- S3イベント通知は、SQSキューポリシーが作成された後に設定する(
depends_onで明示) - Lambda関数は、IAMロールとポリシーがアタッチされた後にデプロイされる
- 各リソースのARN参照により、暗黙的な依存関係が構築される
次章では、Lambda関数の実装内容について解説します。
Lambda関数の実装
本章では、SQSキューからメッセージを受信し、S3からログファイルを読み込んでDynamoDBに書き込むLambda関数を実装します。
注: 本記事では、ログの整形・加工処理(JSON化)は割愛し、すでにJSON形式で整形されたログファイル(server-log.json)をそのままDynamoDBに登録する実装に絞ります。実務では、この部分でデータのバリデーションや変換ロジックを追加することになります。
処理フロー
Lambda関数の処理は以下の流れで行われます。
- SQSメッセージの受信: イベントソースマッピングによってSQSキューからメッセージを受信
- S3イベント情報の抽出: SQSメッセージボディからS3バケット名とオブジェクトキーを取得
- S3オブジェクトの読み込み: 指定されたS3オブジェクトを取得し、JSON形式で読み込み
- DynamoDBへの書き込み: 読み込んだデータをDynamoDBテーブルに保存
- エラーハンドリング: 各処理でエラーが発生した場合のログ出力と集計
Pythonコードの実装
function/src/main.pyに以下のコードを実装します。
import json
import boto3
import logging
from botocore.exceptions import ClientError
logger = logging.getLogger()
logger.setLevel(logging.INFO)
try:
dynamodb = boto3.resource('dynamodb')
table_name: str = "ServerLogsTable"
dynamo_table = dynamodb.Table(table_name)
s3_client = boto3.client('s3')
except Exception as e:
logger.error(f"Error initializing AWS clients: {e}")
raise
def lambda_handler(event, context):
success_count = 0
fail_count = 0
for record in event.get('Records', []):
bucket = None
key = None
try:
# 1. SQSメッセージボディをパース
body_str = record.get('body', '{}')
s3_event = json.loads(body_str)
# 2. S3レコードの情報を安全に取り出す
s3_records = s3_event.get('Records', [])
if not s3_records:
logger.warning("SQS message body does not contain expected S3 'Records'. Skipping message.")
fail_count += 1
continue
s3_record = s3_records[0]
# 情報を階層的に安全に取り出す
bucket = s3_record.get('s3', {}).get('bucket', {}).get('name')
key = s3_record.get('s3', {}).get('object', {}).get('key')
if not bucket or not key:
logger.error(f"Missing bucket or key in S3 event structure. Bucket: {bucket}, Key: {key}")
fail_count += 1
continue
logger.info(f"Processing s3://{bucket}/{key}")
# 3. S3からオブジェクトを取得
res = s3_client.get_object(
Bucket=bucket,
Key=key
)
# 4. JSONデータを読み込み
item: dict = json.loads(res["Body"].read().decode("utf-8"))
# 5. DynamoDBにアイテムを書き込み
dynamo_table.put_item(Item=item)
success_count += 1
logger.info(f"Successfully wrote item for key: {key}")
except ClientError as e:
fail_count += 1
logger.error(f"DynamoDB/S3 ClientError for {key}: {e.response['Error']['Message']}")
except json.JSONDecodeError:
fail_count += 1
logger.error(f"JSONDecodeError: S3 object s3://{bucket}/{key} is not valid JSON.")
except Exception as e:
fail_count += 1
logger.error(f"An unexpected error occurred for {key}: {e}")
logger.info(f"Finished processing. Successful writes: {success_count}, Failed writes: {fail_count}")
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Processing attempt complete',
'successful_writes': success_count,
'failed_writes': fail_count
})
}
コードのポイント解説
初期化部分
try:
dynamodb = boto3.resource('dynamodb')
table_name: str = "ServerLogsTable"
dynamo_table = dynamodb.Table(table_name)
s3_client = boto3.client('s3')
except Exception as e:
logger.error(f"Error initializing AWS clients: {e}")
raise
Lambda関数の実行コンテキストが再利用される可能性を考慮し、AWS SDKクライアントはグローバルスコープで初期化します。これにより、コールドスタート時のみ初期化が行われ、パフォーマンスが向上します。
防御的なデータアクセス
body_str = record.get('body', '{}')
s3_event = json.loads(body_str)
bucket = s3_record.get('s3', {}).get('bucket', {}).get('name')
key = s3_record.get('s3', {}).get('object', {}).get('key')
get()メソッドを使用することで、キーが存在しない場合のKeyErrorを防ぎます。SQSメッセージの構造が期待通りでない場合でも、安全にデータを取り出せます。
エラーハンドリング
except ClientError as e:
fail_count += 1
logger.error(f"DynamoDB/S3 ClientError for {key}: {e.response['Error']['Message']}")
except json.JSONDecodeError:
fail_count += 1
logger.error(f"JSONDecodeError: S3 object s3://{bucket}/{key} is not valid JSON.")
except Exception as e:
fail_count += 1
logger.error(f"An unexpected error occurred for {key}: {e}")
エラーの種類ごとに適切なハンドリングを行い、詳細なログを出力します。これにより、デバッグやトラブルシューティングが容易になります。
- ClientError: AWS API呼び出しの失敗(権限不足、リソース不在など)
- JSONDecodeError: S3ファイルが不正なJSON形式
- Exception: その他の予期しないエラー
バッチ処理とカウント
success_count = 0
fail_count = 0
# ... 処理ループ ...
logger.info(f"Finished processing. Successful writes: {success_count}, Failed writes: {fail_count}")
SQSから複数のメッセージを受信する可能性があるため、成功・失敗のカウントを記録し、最終的にログ出力します。これにより、バッチ処理の結果を一目で把握できます。
DynamoDBに保存するデータ構造
今回使用するlog/server-log.jsonのサンプル構造は以下の通りです。
{
"PK": "USER#12345",
"SK": "LOG#2025-10-20T10:30:00Z",
"timestamp": "2025-10-20T10:30:00Z",
"userId": "12345",
"action": "login",
"ipAddress": "192.168.1.100"
}
DynamoDBテーブルの設計では、PK(パーティションキー)とSK(ソートキー)を使用し、効率的なクエリを可能にしています。
次章では、LocalStack上で実際にリソースをデプロイし、動作確認を行います。
LocalStackでの動作確認
本章では、構築したパイプラインをLocalStack上にデプロイし、実際に動作するか確認していきます。
認証情報の設定
LocalStackを使用する際も、AWS CLIの認証情報設定が必要です。ダミーの認証情報を設定します。
aws configure --profile localstack
以下のように入力します。
AWS Access Key ID [None]: DUMMY
AWS Secret Access Key [None]: DUMMY
Default region name [None]: ap-northeast-1
Default output format [None]: json
LocalStackでは認証情報の検証は行われないため、ダミー値で問題ありません。プロファイル名をlocalstackとすることで、本番環境との切り替えが容易になります。
リソースのデプロイ
Terraformを使ってLocalStackにリソースをデプロイします。
デプロイ前の確認
まず、変更内容を確認します。
tflocal plan
問題がなければ、リソースを作成します。
tflocal apply
途中で確認を求められるので、yesと入力してデプロイを実行します。正常に完了すると、以下のリソースが作成されます。
- S3バケット
- SQSキュー
- Lambda関数
- DynamoDBテーブル
- IAMロール・ポリシー
S3バケットの確認
デプロイが完了したら、S3バケットが正しく作成されているか確認します。
aws --profile localstack --endpoint-url=http://localhost:4566 s3 ls
row-data-server-log-bucket-で始まるバケットが表示されれば成功です。次のステップで使用するため、バケット名(特にランダムサフィックス部分)をメモしておきましょう。
テストデータのアップロード
準備したserver-log.jsonをS3にアップロードします。バケット名のxxxxxxxx部分は、実際のランダムサフィックスに置き換えてください。
aws --profile localstack --endpoint-url=http://localhost:4566 s3api put-object \
--bucket row-data-server-log-bucket-xxxxxxxx \
--key server-log.json \
--body ./log/server-log.json
成功すると、以下のようなレスポンスが返ってきます。
{
"ETag": "\"...\""
}
ファイルのアップロード確認
S3にファイルが正しくアップロードされたか確認します。
aws --profile localstack --endpoint-url=http://localhost:4566 s3api list-objects-v2 \
--bucket row-data-server-log-bucket-xxxxxxxx \
--query "Contents[0].{Key: Key}"
以下のようにserver-log.jsonが表示されれば成功です。
{
"Key": "server-log.json"
}
DynamoDBレコードの確認
ファイルがアップロードされると、S3イベント通知 → SQS → Lambda → DynamoDB という流れで自動的に処理が実行されます。DynamoDBにデータが正しく書き込まれたか確認しましょう。
aws --profile localstack --endpoint-url=http://localhost:4566 dynamodb scan \
--table-name ServerLogsTable
成功すると、以下のようにアップロードしたログデータが表示されます。
{
"Items": [
{
"PK": {
"S": "USER#12345"
},
"SK": {
"S": "LOG#2025-10-20T10:30:00Z"
},
"timestamp": {
"S": "2025-10-20T10:30:00Z"
},
"userId": {
"S": "12345"
},
"action": {
"S": "login"
},
"ipAddress": {
"S": "192.168.1.100"
}
}
],
"Count": 1,
"ScannedCount": 1
}
データが正しく格納されていることが確認できました。
ログの確認方法
Lambda関数の実行ログを確認したい場合は、以下のコマンドで確認できます。
aws --profile localstack --endpoint-url=http://localhost:4566 logs tail \
/aws/lambda/server-log-function --follow
これにより、Lambda関数の実行状況やエラー内容をリアルタイムで確認できます。
トラブルシューティング
もしDynamoDBにデータが書き込まれない場合は、以下を確認してください。
SQSキューにメッセージが届いているか
aws --profile localstack --endpoint-url=http://localhost:4566 sqs receive-message \
--queue-url http://localhost:4566/000000000000/server-log-queue
Lambda関数のログを確認
エラーが発生している場合、Lambda関数のログに詳細が記録されています。
IAMポリシーの確認
LocalStackでも権限設定が必要な場合があります。ログにアクセス拒否エラーがないか確認しましょう。
次章では、開発中にハマったポイントと解決策について紹介します。
ハマったポイントと解決策
本章では、実際にこのパイプラインを構築する過程で遭遇した問題と、その解決方法を紹介します。同じ問題でつまずいている方の参考になれば幸いです。
IAM権限周りの設定
ハマったポイント
Lambda関数を実行した際、以下のようなエラーが発生しました。
An error occurred (AccessDeniedException) when calling the PutItem operation:
User is not authorized to perform: dynamodb:PutItem on resource
最初は「LocalStackだから権限周りは気にしなくて良い」と思い込んでいましたが、実際にはLocalStackでも適切なIAMポリシーの設定が必要でした。
解決策
Lambda関数が各AWSサービスにアクセスするために必要な権限を、iam_policy.tfで明示的に定義しました。具体的には以下の権限が必要です。
- CloudWatch Logs: Lambda関数のログ出力
-
S3: オブジェクトの読み取り(
s3:GetObject) -
SQS: メッセージの受信・削除(
sqs:ReceiveMessage,sqs:DeleteMessage,sqs:GetQueueAttributes) -
DynamoDB: アイテムの書き込み(
dynamodb:PutItem,dynamodb:BatchWriteItem)
また、S3からSQSへイベント通知を送信するための権限も必要でした。aws_sqs_queue_policyリソースで、S3サービスプリンシパルからのsqs:SendMessageを明示的に許可する必要があります。
教訓: LocalStackでも本番環境と同様にIAM権限の設定が必要。権限エラーが出たら、まずはIAMポリシーを確認しましょう。
SQSメッセージの構造を理解する
ハマったポイント
Lambda関数の実装時、SQSから受け取ったメッセージから直接S3のバケット名とキーを取得しようとして、KeyErrorが発生しました。
最初は以下のように書いていました。
# ❌ これだとエラーになる
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
解決策
SQSメッセージの構造を正しく理解する必要がありました。実際の構造は以下の通りです。
event['Records'][0] # SQSレコード
└─ body (文字列) # S3イベントがJSON文字列として格納
└─ Records[0] # S3イベントレコード(パース後)
└─ s3
├─ bucket
│ └─ name
└─ object
└─ key
正しい実装は以下のようになります。
# ✅ 正しい実装
body_str = record.get('body', '{}')
s3_event = json.loads(body_str) # まずbodyをパース
s3_record = s3_event.get('Records', [])[0]
bucket = s3_record.get('s3', {}).get('bucket', {}).get('name')
key = s3_record.get('s3', {}).get('object', {}).get('key')
ポイントは、SQSメッセージのbodyフィールドはJSON文字列なので、まずjson.loads()でパースする必要があるということです。
教訓: イベント駆動アーキテクチャでは、各サービス間で渡されるメッセージの構造を正確に把握することが重要。公式ドキュメントやログ出力でデータ構造を確認しましょう。
DynamoDBのスキーマ設計の誤解
ハマったポイント
DynamoDBにデータを登録する際、TerraformでPKとSK以外のフィールド(例: timestamp, userId, actionなど)もattributeブロックで定義する必要があると思い込んでいました。
最初は以下のように書こうとしていました。
# ❌ これは不要
resource "aws_dynamodb_table" "server_logs_table" {
name = "ServerLogsTable"
billing_mode = "PAY_PER_REQUEST"
hash_key = "PK"
range_key = "SK"
attribute {
name = "PK"
type = "S"
}
attribute {
name = "SK"
type = "S"
}
# これらは不要だった
attribute {
name = "timestamp"
type = "S"
}
attribute {
name = "userId"
type = "S"
}
}
しかし、実行すると以下のようなエラーが発生しました。
Error: all attributes must be indexed. Unused attributes: ["timestamp", "userId"]
解決策
DynamoDBのattributeブロックで定義するのは、キー(パーティションキーとソートキー)およびセカンダリインデックスで使用する属性のみです。それ以外のフィールドは、スキーマレスな設計により、Terraformで定義しなくてもデータ投入時に自動的にフィールドとして登録されます。
正しい実装は以下の通りです。
# ✅ 正しい実装
resource "aws_dynamodb_table" "server_logs_table" {
name = "ServerLogsTable"
billing_mode = "PAY_PER_REQUEST"
hash_key = "PK"
range_key = "SK"
# キーとして使用する属性のみ定義
attribute {
name = "PK"
type = "S"
}
attribute {
name = "SK"
type = "S"
}
tags = {
Name = "ServerLogsTable"
}
}
Lambda関数で以下のようにデータを投入すれば、timestampやuserIdなどのフィールドも自動的にDynamoDBに登録されます。
item = {
"PK": "USER#12345",
"SK": "LOG#2025-10-20T10:30:00Z",
"timestamp": "2025-10-20T10:30:00Z",
"userId": "12345",
"action": "login",
"ipAddress": "192.168.1.100"
}
dynamo_table.put_item(Item=item)
教訓: DynamoDBはスキーマレスなNoSQLデータベースであり、Terraformではキーとして使用する属性のみを定義すれば良い。RDBの感覚でスキーマを厳密に定義しようとしないこと。
LocalStack特有の注意点
LocalStackを使う上での補足として、以下の点にも注意が必要です。
-
エンドポイントURL: AWS CLIを使う際は必ず
-endpoint-url=http://localhost:4566を指定するか、awslocalコマンドを使用する -
認証情報: ダミー値でも設定が必要(
aws configureで設定) - リソースの永続化: LocalStackを停止すると、デフォルトではリソースが削除される。永続化したい場合はボリュームマウントを設定する
次章では、本記事のまとめと今後の展望について述べます。
まとめ
本記事では、Terraform + LocalStackを使ってS3イベント駆動型バッチ処理パイプラインを構築する手順を紹介しました。
本記事で学んだこと
技術的な学び
-
Terraformによるインフラ構築: CloudFormationとは異なる記法や、データソースを使った柔軟なリソース定義方法を学びました。特に
aws_iam_policy_documentやarchive_fileといったデータソースの活用は、コードの可読性と保守性を高める上で有効でした。 -
LocalStackでのローカル開発: コストをかけずにAWSサービスをエミュレートできる環境の構築方法を習得しました。
tflocalコマンドを使うことで、本番環境とほぼ同じコードでローカル開発ができるのは大きなメリットです。 - イベント駆動アーキテクチャの実装: S3 → SQS → Lambda → DynamoDBという、実務でもよく使われるデータパイプラインの基本パターンを実装しました。特にSQSを間に挟むことで、処理の信頼性とスケーラビリティを確保できることを実感しました。
設計・運用面での学び
- IAM権限設計の重要性: LocalStackでも本番環境同様に、適切なIAM権限の設定が必要であることを学びました。最小権限の原則に従い、必要な権限のみを明示的に付与することの重要性を再認識しました。
- メッセージ構造の理解: SQSメッセージの構造を正確に把握することで、Lambda関数でのエラーハンドリングが適切に行えるようになりました。イベント駆動型の開発では、サービス間のデータフォーマットを理解することが不可欠です。
- DynamoDBのスキーマレス設計: RDBとは異なるNoSQLの特性を理解し、キー以外の属性はTerraformで定義不要であることを学びました。これにより、柔軟なデータモデル設計が可能になります。
インフラエンジニアとしての気づき
普段はCloudFormationでのインフラ構築を行っていますが、Terraformを触ってみて以下の点が印象的でした。
- マルチクラウド対応の可能性: AWSだけでなく、GCPやAzureなど他のクラウドプロバイダーにも同じ記法で対応できる点は、将来的に大きな強みになると感じました。
- モジュール化のしやすさ: ファイル分割やモジュール構成が直感的で、再利用可能なコンポーネントを作りやすい印象を受けました。
- プログラミング言語的な感覚: データソースや変数の扱いが、プログラミング言語に近い感覚で記述でき、インフラエンジニアがプログラミング学習を進める上で良い教材になると感じました。
今後の展望
今回構築したパイプラインは基本的なものですが、以下のような拡張が考えられます。
短期的な改善
- エラーハンドリングの強化: DLQ(Dead Letter Queue)を追加し、処理に失敗したメッセージを別キューに格納して後で再処理できるようにする
- ログの整形処理: 今回割愛したログのJSON化処理を実装し、実際の生ログから構造化データへの変換ロジックを追加
- テストの充実: Lambda関数のユニットテストや、Terraformのテスト(Terratest等)を導入
中長期的な発展
- 本番環境へのデプロイ: LocalStackで動作確認したコードを、実際のAWS環境にデプロイ。環境ごとの変数管理(dev/stg/prod)を実装
- CI/CDパイプラインの構築: GitHub ActionsやGitLab CIを使って、コード変更時に自動的にテスト・デプロイが行われる仕組みを構築
- モニタリング・アラート: CloudWatch Alarms や X-Ray を使った監視体制の構築。処理の失敗率やレイテンシを可視化
- データ分析基盤との連携: DynamoDBに格納したデータをAthenaやRedshiftで分析できるようにする
おわりに
今回、転職先で使用するTerraformの学習と、TDD(テスト駆動開発)への取り組みの一環として、LocalStackを活用したS3イベント駆動型パイプラインを構築しました。
インフラエンジニアとして、これまでCloudFormation一筋でしたが、新しいツールに挑戦することで視野が広がり、「インフラをコードで管理する」ことの本質的な価値を改めて理解できました。
また、プライベートでRustやGoを使ったOSS開発を進めている身として、Pythonでのスクリプト実装とインフラ構築を組み合わせた開発スタイルは、自分のスキルセットを広げる良い機会になりました。
この記事が、これからTerraformを学ぶ方や、LocalStackでのローカル開発環境構築に興味がある方、そして「インフラエンジニアの言語学習記録」に共感してくださる方の参考になれば幸いです。
最後まで読んでいただき、ありがとうございました。