機械学習で予測値を検出し、評価行うという一連の作業を学習したかったので、チュートリアルであるタイタニックから乗客が生存するか否かを予測を行いました。自分用の復習用メモとして挙げています。
環境:
Window10
Google colaboratory
参考動画:
今回「はやたす / Pythonチャンネル」を参考にさせて頂きました。
データサイエンスの7ステップ
1,目的・課題の特定
2,データの取得・収集
3,データ理解・データの可視化
4,データの加工・前処理
5,機械学習モデルの作成
6,評価・テスト
7,レポーティング or アプリケーション化
今回2~6に絞ってトライしました。
2,データの取得・収集
データの収集はKaggleから入手しました。Data項目押し、DownloadALLをクリックすれば、test.csv, train.csvがダウンロードされます。
入手したデータは実行環境Google colaboratory で、Kaggeleから取得したデータを読み込む為には、Google Driveをマウントする必要があります。やり方は下記になります。実行すれば、コードが発行され、埋め込み部にコードをコピーして実行すれば、マウントできます。
from google.colab import drive
drive.mount('/content/drive')
3,データ理解・データの可視化
先ずは、ライブラリーをインポートする。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
import seaborn as sns
import seaborn as sns
sns.set()
sns.set()
%matplotlib inline
%matplotlib inline
データの読み込み
Google driveに入れたファイルのパスをとり, dir_pathに代入します。
dir_path = '/content/drive/MyDrive/DataScience/titanic/'
学習データの読み込み(pd.read_csvを使うことで、表形式でデータの読み込みができます)
train_df = pd.read_csv(dir_path + 'train.csv')
テストデータの読み込み
test_df = pd.read_csv(dir_path + 'test.csv')
データの中身確認
# 学習データの先頭5行を確認してみる
train_df.head()

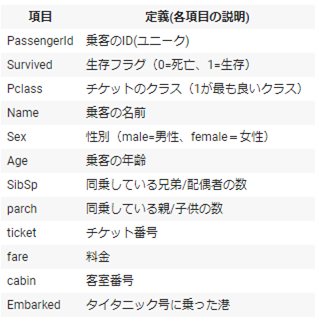
データーのColumn項目の内容は下記になります。
# テストデータの先頭5行を確認してみる
test_df.head()

実際、学習データとテストデータを比較してみましょう。比較するにはデータの大きさを比較します。
データの大きさを確認するには、df.shapeを使います。
# データフレームの大きさ
print(train_df.shape)
print(test_df.shape)
(891, 12)
(418, 11)
上記は、(行数, 列数)を表しています。行数は乗客の数、列数はヘッダー情報の数を表しています。
テストデータは、カラムが一つ足りなくなっています。確認するとSurvivedが抜けています。
データの特徴を知る
それには、学習用データと練習用データを縦に繋げて、連結しましょう。学習データとテストデータが分けておく必要がないのと、分けておくと同じコードを2回実行する恐れを防ぐためです。
連結するには、以下のようにpd.concat()を使います。
ignore_index=Trueとしておくことで、連結するときのインデックス番号(=1番左の番号)を振り直しできます. ignore_index=Trueを入れないとインデックス番号が連結されません。
# 学習データとテストデータを連結する
df = pd.concat([train_df, test_df], ignore_index=True)
print(df)
df.shape
インデックス番号が0~1308に割り振られているとともに(1309, 12)として大きさを表しており、学習データが891行、テストデータが418行だったのでちゃんと行が連結されています。
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0.0 3 ... 7.2500 NaN S
1 2 1.0 1 ... 71.2833 C85 C
2 3 1.0 3 ... 7.9250 NaN S
3 4 1.0 1 ... 53.1000 C123 S
4 5 0.0 3 ... 8.0500 NaN S
... ... ... ... ... ... ... ...
1304 1305 NaN 3 ... 8.0500 NaN S
1305 1306 NaN 1 ... 108.9000 C105 C
1306 1307 NaN 3 ... 7.2500 NaN S
1307 1308 NaN 3 ... 8.0500 NaN S
1308 1309 NaN 3 ... 22.3583 NaN C
[1309 rows x 12 columns]
(1309, 12)
確認として、テストデータは、Surviviedが無かったので、学習用データとして連結すると空になるはずです。念のため、df.tail()で最後の5行をを確認してみます。
下記SurviviedがNaNとして空になっていることがわかり、ちゃんと学習用データーとテストデータが連結されています。

データの可視化
データの内容を更に理解するために、データ内の項目がどのような内容になっているか理解する必要があります。ここでは、性別 : どんな内訳になっているのか?チケットのクラス : どんな階級の人が多いのか?を見ていきます。
可視化をするには、グラフが便利で、matplotlibで表示していきます。
Matplotlibで表示する方法
matplotlibで男女の内訳を確認するには、まず各性別ごとの人数を集計する必要があります。
①性別ごとにグループ分け(=男性と女性に分ける)して、②各性別ごとにカウントするってことになります。グループ分けには、df.groupby(カラム名)で行い、カウントするにはagg関数で行います。
# ①性別ごとにグループ分けして、②各性別ごとにカウントする
df.groupby('Sex').agg({'Sex':'count'})
Sex
Sex
female 466
male 843
この集計結果を、変数tmpに入れ,変数に格納するとき、カラム名のSexをcount_sexに変更します。
tmp = df.groupby('Sex').agg({'Sex':'count'}).rename(columns={'Sex':'count_sex'})
カラム名がcount_sexに変更になっています。
count_sex
Sex
female 466
male 843
```
それでは、データの準備ができたので、男女数を比較する為の棒グラフを作成します。
matplotlibで棒グラフを作成するには、plt.bar(変数名.x軸で使う列(=カラム), 変数名.y軸で使う列(=カラム))
```python
# グラフの大きさを設定
plt.figure(figsize =(10,6))
# 性別の数を確認してみる
plt.bar(tmp.index, tmp.count_sex)
plt.show()
```

#### pandasでグラフ表示する
```python
# pandasで棒グラフを作成する
tmp.plot(kind = 'bar', figsize = (10,6))
plt.show()
```

#### Seabornで表示する
```python
# グラフの大きさを設定
plt.figure(figsize=(10,6))
# 性別の数を確認してみる
sns.countplot('Sex', data=df)
plt.show()

では、チケットのクラス : どんな階級の人が多いのか?をSeabornを使って見ていきます。
# グラフの大きさを設定
plt.figure(figsize=(10,6))
# 性別の数を確認してみる
sns.countplot('Pclass', data=df)
plt.show()

機械学習では、使うカラムは決めておく必要があるので、今回は、以下4つの特徴量を使います。
チケットのクラス
年齢
性別
港
欠損値データの確認
データの可視化と一緒にやるべきことが、欠損値の確認です。欠けているデータがあるなら、それを補ったり削除したりする必要があります。欠損値があると機械学習でうまく予測できないからです。
欠損値確認方法:df.isnull().sum()
下記を見ると、乗客の年齢(=Age)やタイタニック号に乗った港(=Embarked)、またチケットの料金(=Fare)が欠けています。
PassengerId 0
Survived 418
Pclass 0
Name 0
Sex 0
Age 263
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 1014
Embarked 2
dtype: int64
```
#### データの加工・前処理・特徴量エンジニアリング
データの中身を確認したら、欠損値を埋めていくなど機械学習で使うためのデータに変換していく必要があります。この部分を、「データの前処理」と言います。機械学習で良い結果を出すために、新しいカラムを作成することを特徴量エンジニアリングと言います。
①欠損値補完:Embarked
```python
# Embarkedの欠損値を確認する
df.Embarked.isnull().sum()
```
```
2
```
2人の乗客だけデータが欠けていることが分かりました。欠損値がかなり多いわけではないので、今回は最も乗客が多かった港で補います。
それでは、Seabornでどのくらいのタイタニック号に乗った人の港毎の人数を確認します。
```python
# グラフの大きさを設定
plt.figure(figsize=(10,6))
# 乗船した港を確認する
sns.countplot('Embarked', data = df)
plt.show()
```

多くの乗客がSという港から乗ってました。欠けている2箇所をSで補います。欠損値を補完するには、fillna("補完したい値")で書いてあげます。
また、データに変更を加える前に、df.copy()を使って元データをコピーしてから欠損値の補完をしていきたいと思います。このことで、元データが変更されることはことはありません。
```python
# 元データをコピー
df2 = df.copy()
# 欠損値の補完
df2.Embarked = df2.Embarked.fillna('S')
```
```python
# 乗船した港の欠損値を再度確認する
df2.Embarked.isnull().sum()
```
欠損値0になっており、補完できていました。
②欠損値補完:Age
乗客の年齢がどうなっているのか確認します。「どの年齢層の乗客が多いのか」を把握します。
各層ごとのボリュームを見たい場合には、ヒストグラムを使います。
その前に年齢層がどうなっているのか知りたいところです。
最小値と最大値が分かればどのようにグラフを作成すればいいのか分かります。
```python
# 年齢の最小値と最大値を確認
print(df2.Age.max())
print(df2.Age.min())
結果は、最大値80歳、最小値0歳だということがわかりました。そうすれば、0~80歳で、10歳単位で8つに分ければいいことになります。
80.0
0.17
```
次に、シーボンでsns.distplot(df.変数, bins=分割数, kde=False )を使うと、ヒストグラムの描画できます。
```
seabornのdistplotメソッドでヒストグラムのオプションと説明は下記になります。
オプション 説明
data Seriesまたは1d-array、listのみ
bins 等級値(x軸の刻み目)の数。スタージェスの公式(※後述)で最適化可能
color 色の指定
label 凡例の指定。plt.legend()必須。
kde True:密度近似関数の描画
rug True:実数値の描画
fit norm:正規分布の描画
```

見ると20歳代から30歳代が多い傾向にあります。どの数値で補完するかについては、このグラフから、年齢の中央値を使ってあげると良さそうです。
````python
# 年齢の平均値と中央値を確認する
print(df2.Age.mean())
print(df2.Age.median())
29.881137667304014
28.0
中央値28.0を使っていきます。
欠損値を補完するときは、Embarkedと同様に、先にdf2.copy()でデータフレームをコピーしておきます。あとは年齢の中央値で補完するので、先に計算して変数age_medianに格納していきます。
# df2をコピー
df3 = df2.copy()
# 年齢の中央値を計算
age_median=df3.Age.median()
age_median
あとは、Embarkedと同様に、fillna()を使って欠損値の補完をします。
# 年齢の欠損値を、計算しておいた中央値で補完する
df3.Age = df3.Age.fillna(age_median)
# 年齢の欠損値の数を確認する
df3.Age.isnull().sum()
結果はゼロになり、ちゃんと補完できたことを示しています。
カテゴリカル変数の数値変換
乗船した港や性別のように、中身がカテゴリーになっているデータを「カテゴリカル変数」と言います。カテゴリカル変数の数値変換の主なものは、下記になります。
①ワンホットエンコーディング:
各カテゴリーに対して別のカラムを準備して、「該当する部分には1, そうではない部分には0」を振り分ける方法。

②ラベルエンコーディング:
各カテゴリーを純粋に数値変換する方法。
使用するデータの絞り込み
カテゴリカル変数に数値変換する前に、機械学習で使うカラムを絞ります。
カラムを選ぶときは、①使わないカラムを削除する方法と②使うカラムだけ指定する方法があります。
今回は①使わないカラムを削除する方法で進めました。
データフレームからカラムを削除するには、以下のようになります。
# 今回使わないカラムを削除する
df4 = df3.drop(columns=['Name', 'SibSp', 'Parcカテゴリカル変数1 : 乗船した港の数値変換h','Ticket','Fare', 'Cabin'])
# 先頭5行を確認する
df4.head()
下のようにカラムを絞り込むことができました。

カテゴリカル変数1 : 乗船した港の数値変換
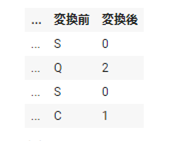
カテゴリカル変数には、ホットエンコーディングを使います。ホットエンコーディングは、Pandasのget_dummies()を使います。
pd.get_dummies(df4['Embarked'])

数値変換で1309行、全行できました。
今回の変換で作成されたカラムは、CとかQだけだと他の人が見た際、わからないので、引数prefix="Embarked"を付けて、乗船した港を明確にします。
# ワンホットの結果を変数tmp_embarkedに格納する
tmp_embarked = pd.get_dummies(df4['Embarked'], prefix='Embarked')
Embarkedと付ける乗船港であることが分かります。
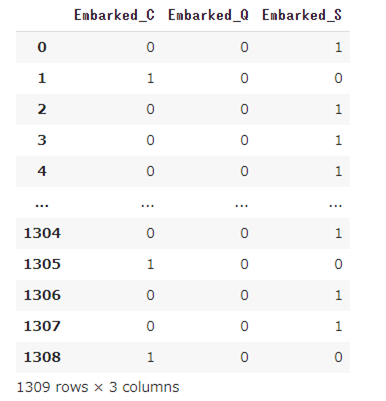
次に、元のデータフレームに連結します。それにはPandasのconcat()を使います。今回は横に連結します。axis=1(横連結)、axis=0(縦連結)
# 元のデータフレームにワンホット結果を連結して、変数df5に格納する
df5 = pd.concat([df4, tmp_embarked], axis=1).drop(columns=['Embarked'])
df5.head()

カテゴリカル変数2 : 性別数値の数値変換
性別の変換は、2種類しかないので、ラベルエンコーディングを使います。
# 性別をワンホットエンコーディングする
pd.get_dummies(df5['Sex']).head()
# ラベルエンコーディングした結果を最初の5行を表す。
df5['Sex'] = pd.get_dummies(df5['Sex'],drop_first=True)
df5.head()

学習用データとテストデータに分割する
機械学習を使って生存するか否かを予測するには、「学習で使うデータ」と「生存するか否かを当てたい乗客データ」に分割しておく必要があります。
学習で使うデータ : 学習データ・訓練データ
予測したいデータ : テストデータ
データの分割をしていく際、分割の基準を決める必要があります。今回は、生存するか否かを予測したいので、「Survivedにデータが入っているか否か」で判断します。
先ずは学習用データは、生存数が入っているデータで、テストデータは、生存数が入っていないことで分けます。
Survivedが空になっていることを判定するには、df5.Servived.isnull()のように書きます。
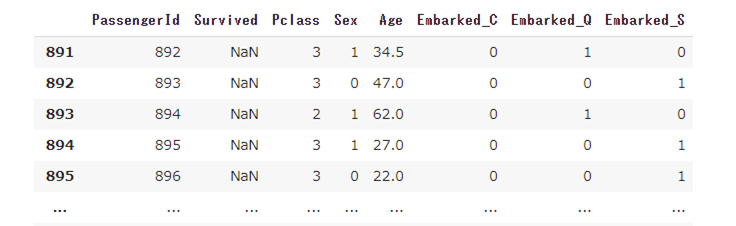
df5[df5.Survived.isnull()]
SurvivedがNaNになっており、情報が空になっています。
逆にSurvivedが空ではないデータを求めるには、[~]を入れます。これは「~ではない」の意味になります。
df5[~df5.Survived.isnull()]

よって, Survivedが空になっているものはテストデータ、なっていないものは学習用データーにします。
train = df5[~df5.Survived.isnull()]
test = df5[df5.Survived.isnull()]
テストデータに入っているSurvivedは不要なので削除。
# Survivedを削除
test = test.drop(columns=['Survived'])
test.head()
Survivedが消えています。

次に、学習データを「学習に使うカラム(=特徴量)」と「正解(=目的変数)」に分割します。
特徴量と正解を分割する理由は、機械学習が「特徴量から得た情報と、正解の"関係性"を学習して記憶しておく」からです。
学習で使うカラムは、元のデータtrainからSurvivedを削除し、正解はSurvivedだけ取りだします。
# 正解をy_trainに格納する
y_train = train.Survived
# 特徴量をx_trainに格納する
x_train = train.drop(columns=['Survived'])
# 特徴量を確認
x_train.head()

# 正解を確認
y_train.head()
0 0.0
1 1.0
2 1.0
3 1.0
4 0.0
Name: Survived, dtype: float64
これで学習データとテストデータの分割が完了しました。
機械学習を使って予測する
それでは機械学習を使って、タイタニック号の乗客が「生存するか否か」を予測します。
機械学習に色々なアルゴリズム・モデルがある内、決定木モデルを使って予測します。
決定木は、以下の画像のように、条件に応じて分岐をすることで予測する機械学習モデルです。
»参考記事 : https://qiita.com/3000manJPY/items/ef7495960f472ec14377
Pythonで決定木を使うには、ライブラリScikit-learnをインポートします。
今回は決定木モデルの作成以外でScikit-learnを使わないので、以下のように書いてライブラリをインポートしていきましょう。
# ライブラリのインポート
from sklearn import tree
モデル作成の準備として使用する合図をコードで書きます。
# 決定木モデルの準備
model = tree.DecisionTreeClassifier()
Classifierは、分類の意味です。そもそも機械学習には、分類と回帰という考えがあります。
●分類 : ラベルを予測すること
例:今回のように生存するか否かを当てる
●回帰 : 数値を予測すること
例 : 明日の株価(=数値)を当てる
決定木は回帰にも使えるので、その場合にはDecisionTreeRegressor()を使います。Regressorが回帰という意味です。
モデルの作成
準備した決定木を使って機械学習を開始するには、以下のようにmodel.fit()と書いてあげます。
# 決定木モデルの作成
model.fit(x_train, y_train)
作成したモデルを使って予測する
# 作成した決定木モデルを使った予測をおこなう。
y_pred = model.predict(test)
array([0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 1., 1., 0.,
1., 0., 0., 0., 0., 1., 1., 1., 0., 1., 1., 0., 0., 0., 0., 1., 0.,
0., 1., 0., 0., 0., 0., 0., 1., 0., 1., 1., 0., 0., 1., 1., 1., 1.,
0., 1., 1., 0., 0., 0., 0., 0., 1., 0., 1., 0., 1., 1., 1., 1., 0.,
0., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 1., 1., 0., 0., 0., 1.,
0., 1., 0., 1., 1., 0., 0., 1., 0., 1., 0., 1., 0., 0., 0., 1., 0.,
1., 0., 1., 0., 0., 1., 0., 0., 0., 1., 1., 1., 1., 1., 0., 0., 0.,
1., 1., 1., 1., 0., 1., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 0.,
1., 0., 0., 0., 0., 1., 0., 0., 0., 1., 1., 0., 1., 0., 1., 0., 0.,
1., 1., 0., 1., 0., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 1., 1., 0., 1., 1., 0., 0., 1., 1., 1., 0., 1.,
0., 0., 0., 0., 1., 0., 0., 1., 0., 1., 0., 0., 0., 1., 1., 0., 1.,
0., 1., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 1., 0., 1., 0., 1.,
0., 1., 0., 1., 1., 0., 1., 0., 0., 0., 1., 0., 1., 0., 0., 0., 1.,
1., 1., 1., 1., 0., 0., 0., 0., 1., 0., 1., 1., 1., 0., 1., 0., 0.,
0., 1., 0., 1., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 1.,
1., 1., 0., 1., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 1., 0.,
0., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 1., 1.,
0., 1., 0., 0., 0., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0.,
0., 1., 0., 1., 0., 0., 0., 1., 0., 0., 1., 1., 0., 1., 0., 0., 0.,
0., 1., 0., 1., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 1.,
0., 1., 0., 0., 1., 1., 1., 0., 0., 0., 0., 1., 0., 0., 1., 0., 0.,
1., 1., 0., 0., 0., 1., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1., 1.,
1., 1., 0., 0., 1., 0., 1., 0., 0., 1., 0., 1., 1., 0., 1., 0., 0.,
1., 0., 1., 1., 0., 0., 1., 0., 0., 0.])
この数字は今回予測していた「乗客が生存するか否か」の予測の結果です。乗客が生存する場合には1, そうでない場合には0ということになります。
これをテストデータと連結していきます。テストデータの乗客の数だけ予測結果の数が存在するか確認します。まずはテストデータと予測結果の大きさを調べます。大きさを調べるにはlen関数です。
# テストデータと予測結果の大きさを確認する
len(test),len(y_pred)
(418, 418)の結果が出ます。各乗客ごとに生存したか否かを予測できたということになります。
予測結果をとテストデータに連結していきます。予測結果の連結には、テストデータに新しいカラムを追加していきます。
# 予測結果をテストデータに反映する
test['Survived'] = y_pred
評価・テスト
今回の決定木モデルの予測結果が正しいのかどうか検証していく必要があります。今回使っているKaggleは、指定されているフォーマットでデータを提出すると、モデルの精度を判定できるようになっています。どのような形式で提出すべきかは、OverviewのEvaluationを見ると、Submission File FormatにPassenger Id, Survivedが記載されており、このカラムで作成したデータを作る必要があります。

上記で作成したテストデータ+予測結果のデータから、提出用のシートを作成します。
# 提出用のデータマートを作成する
pred_df = test[['PassengerId','Survived']].set_index('PassengerId')
小数点表記になっているので、整数に変換する。
pred_df.Survived = pred_df.Survived.astype(int)
pred_df.head()
最後にCSVを読み込むとき同様、出力するときもPandasを使っていきます。
# CSVの作成
pred_df.to_csv('submission_v1.csv',index_label=['PassengerId'])
出来上がったCSVファイルをKaggleのSubmit predictionsクリックし、CSVをアップロードする場所になりますので、ファイルをアップロード。



最終的にsubmission_v1.csv部分は、0.72009と72%と出力されました。比較的高い数値ではないかと思います。今回、決定木モデルで行いましたが、次回は違うモデルで試してみようかと思います。