タイトルの通りですが、見落としやすそうで私自身上手く情報を拾えなかったので記事として書いてみました
MSKの各種設定変更を考えてる方向けに役に立てば幸いです
※MSKの概要も整理して記載してみましたので、確認したい方はそちらもご参照下さい
ブローカー数の変更を試してみた状況
負荷試験をしている中で、ブローカー数を増やした結果サービスのパフォーマンスにどう影響するか一度確認するために、テスト用MSKクラスターのゾーンあたりのブローカー数を1->2に増加してみました。
①
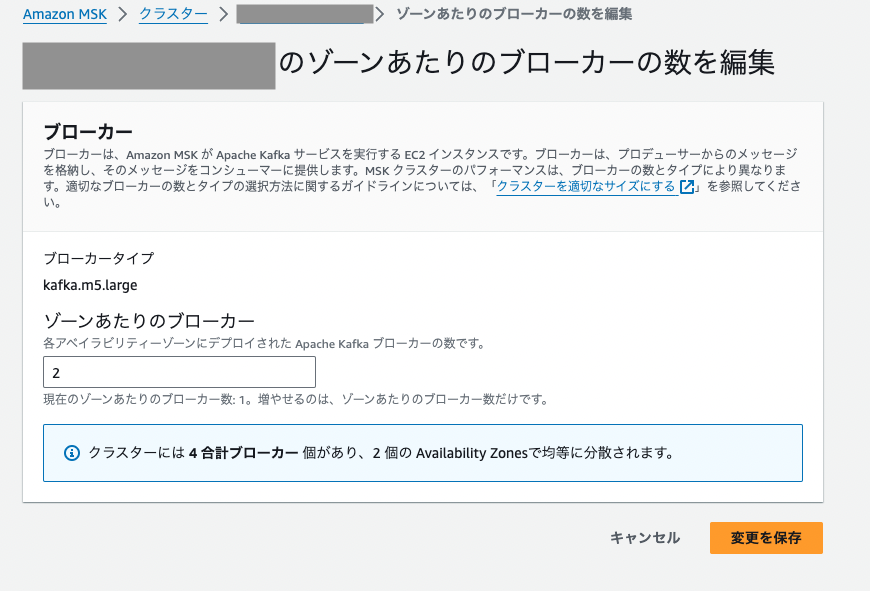
元々の設定がゾーンあたりのブローカー数 1
②
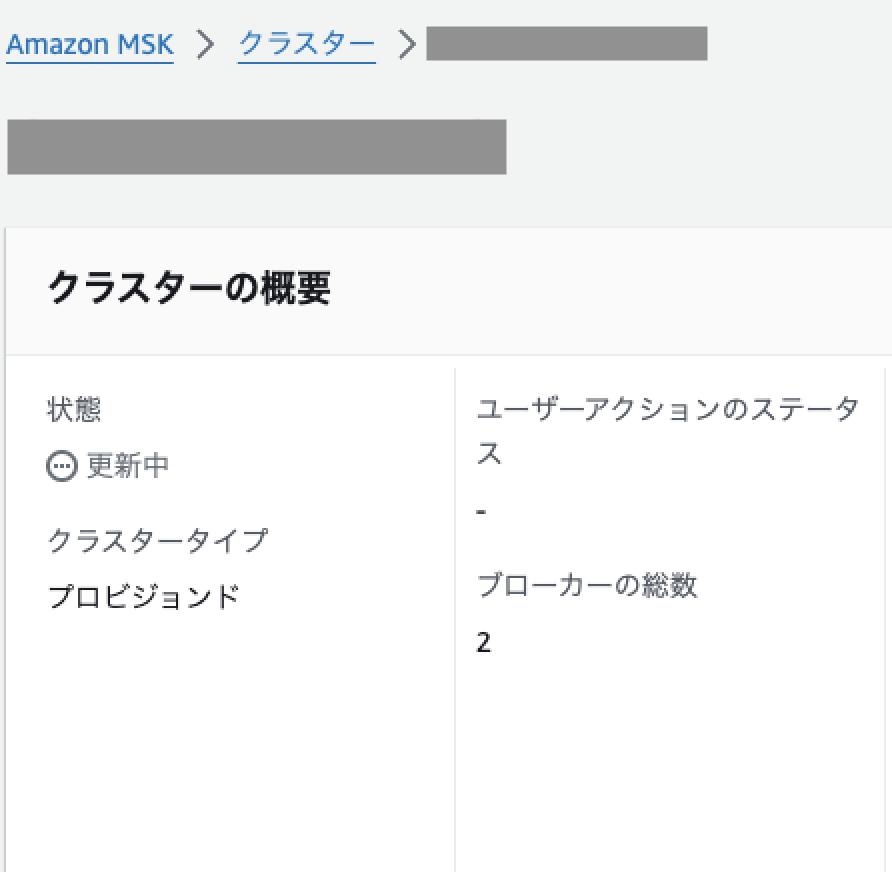
更新中
③
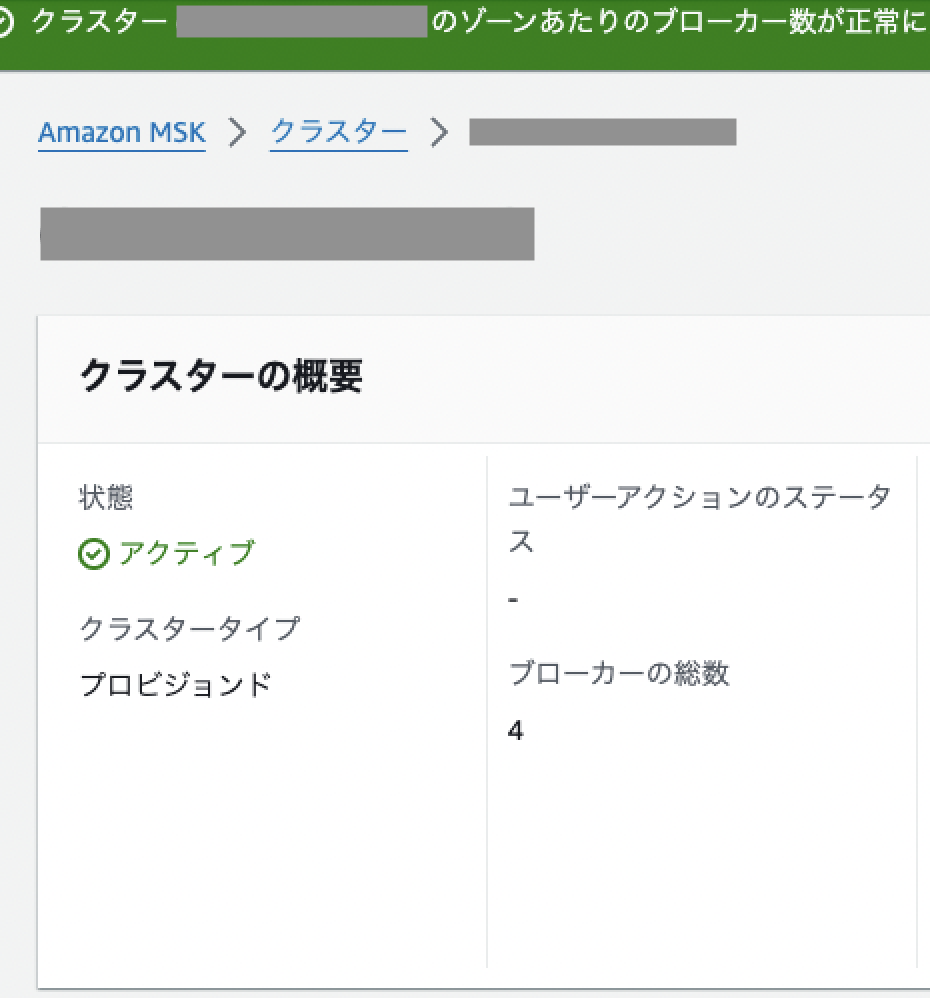
更新完了
ゾーンあたりのブローカー数は2(総数4)になりました
④
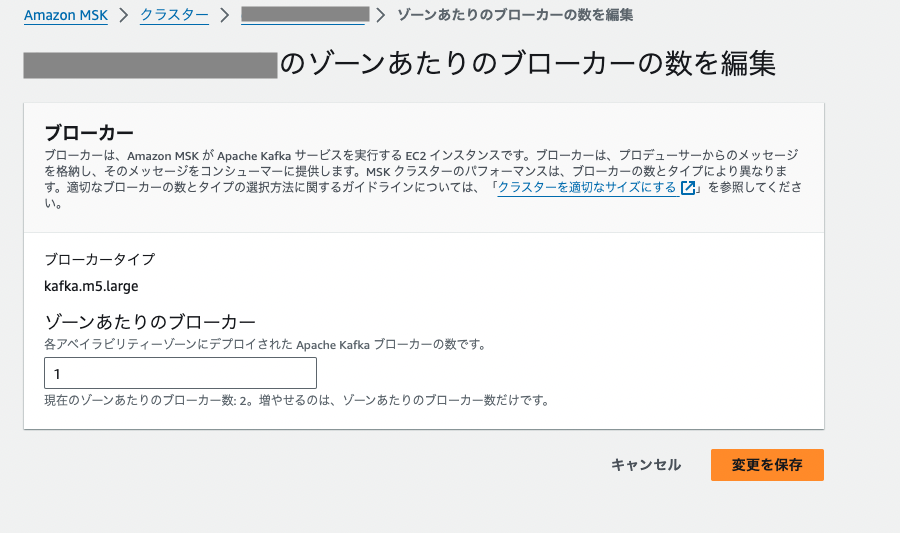
ゾーンあたりのブローカー数を1に戻そうとします
⑤
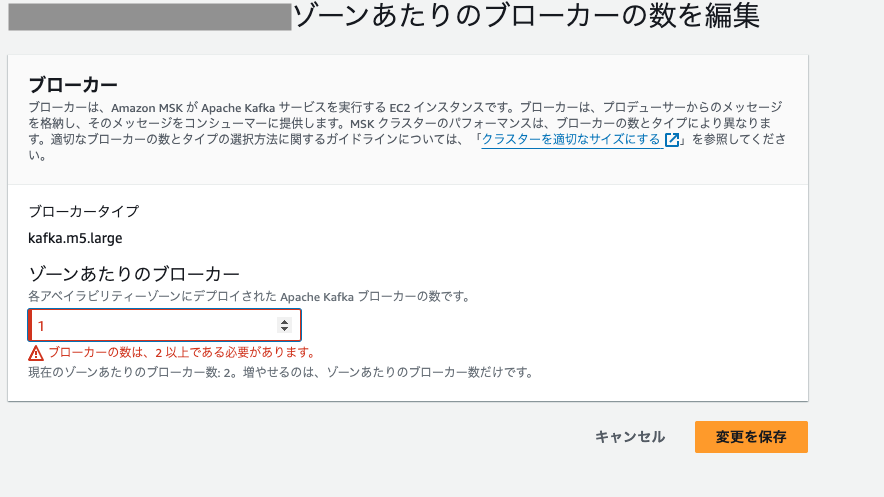
赤字で「ブローカーの数は、2以上である必要があります」と出てきて変更不可でした
(増加しか設定変更できない状態)
サポートの方に確認した結果
現時点ではブローカー数を減らす操作はできないようです
※但し機能要望として声が挙がっているようでして将来的に改善される可能性はありそうです
私もブローカー数の設定変更について公式ドキュメント全体を確認したつもりではありましたが、見つけられませんでした。原文のページに以下言及があります。
Updates the number of broker nodes in the cluster. You can use this operation to increase the number of brokers in an existing cluster. You can't decrease the number of brokers.
HTTPメソッドのUpdateBrokerCountに関する説明ですが、その中に"ブローカーの数を減らすことはできません" と記載がありました
また、日本語の翻訳ドキュメントにはクラスターの拡張に関するページに以下記述があります
Target-Number-of-Brokers パラメータは、このオペレーションが正常に完了したときにクラスターが持つブローカーノードの総数を表します。Target-Number-of-Brokers に指定する値は、クラスター内の現在のブローカー数より大きい整数である必要があります。また、アベイラビリティーゾーンの数の倍数である必要があります。
注意深く確認すれば、大きい整数である必要がある = 現設定以下の整数には設定できないと推測できるかと思います。が、はっきり不可と明言されていないと中々確証を得難いもの。はっきりと数の減少が不可と明記してある、英語の原文ドキュメントを確認できた方が根拠として手堅いです。
また、ブローカーストレージについてもEBSストレージの量を減らすことができない為、注意が必要です
ブローカーストレージのスケールアップについて
https://docs.aws.amazon.com/ja_jp/msk/latest/developerguide/msk-update-storage.html
どう対応したのか?
ブローカー数が増えると、その分ランニングコストも増加します。できるだけ早く元に戻したいところです。復旧対応として、全く同じ設定のMSKクラスターを作成して、各コードのエンドポイントや環境変数名を入れ替えて対処しました。入れ替えに伴う時間がかかってしまいますし、環境変数やエンドポイントの抜け漏れが生じるリスクもあります。できればこのような対応は避けたかったのですが、他に方法もない為やむを得ず..
原文ドキュメントも併せて確認する
これは自戒も含めてですが、、重要情報の見落としを防ぐためにも、原文にも目を通しておくようにしましょう。原文の公式ドキュメントには記載あるが、日本語の翻訳ドキュメントには書いてない情報は結構多いものです。(各サービスのバージョンごとのサポート期限等の情報は特にその傾向にある気がします)
MSKについて
そもそもMSKとは何? という方向けに、自身の学習知識整理も兼ねて概要等を簡単に記載します。(著者は2023年度末頃に初めて齧った程度の初心者です)
正式名称は、'Amazon MSK(Amazon Managed Streaming for Apache Kafka)'
一言で言うと、Apache Kafkaのマネージドサービスです。
さらにApache Kafkaとは何か? といいますと、分散型のリアルタイムデータストリーム処理システムの事です。(ストリーム処理はリアルタイムでデータを収集 -> 変換・分析・配信するデータ処理手法)
ストリームデータは流量が不安定で、データ流量が急増すると負荷が上昇します。処理負荷を平準化する為、メッセージキューでデータを一時的にキューイングして、データの受付と処理を非同期化させれば安定したストリーム処理が可能になります。
また、ストレームデータを流す後続のサービスに対して、並列分散処理をさせたり、イベント駆動型として渡したりすることができます。
メッセージキューについては、こちらの記事が分かりやすく概要解説されてますので是非ご確認下さい
メッセージキューイングとは、異なるアプリケーションプログラム間で動作を連携させてデータを交換させる際の方式のひとつで、送るデータをキューと呼ばれるデータ領域に保持し、データを受ける側の処理が完了するのを待たずに次の処理へ移る方式のこと
メッセージキューイングが導入されることによって、送信する側はキューにデータを置くだけで、送り先と同期できなくても確実にデータを送り届けることができる。接続が途絶えるような状況にあっても、アプリケーションが対処しなくてもメッセージが確実に届く
サービスの利用例:
Kafkaの採用例として、Uberにおける乗客とドライバーのマッチング管理、ブリティッシュガスのスマートホームサービスにおけるリアルタイム分析および予知保全の提供、LinkedIn全体における多数のリアルタイムサービスの実行など
ストリーム処理サービスの競合としては、Kinesis、Apache Pulsar、Apache Spark、RabbitMQなどが挙がります
登場人物と解説
キーワードを整理します
| リソース名 | 説明 |
|---|---|
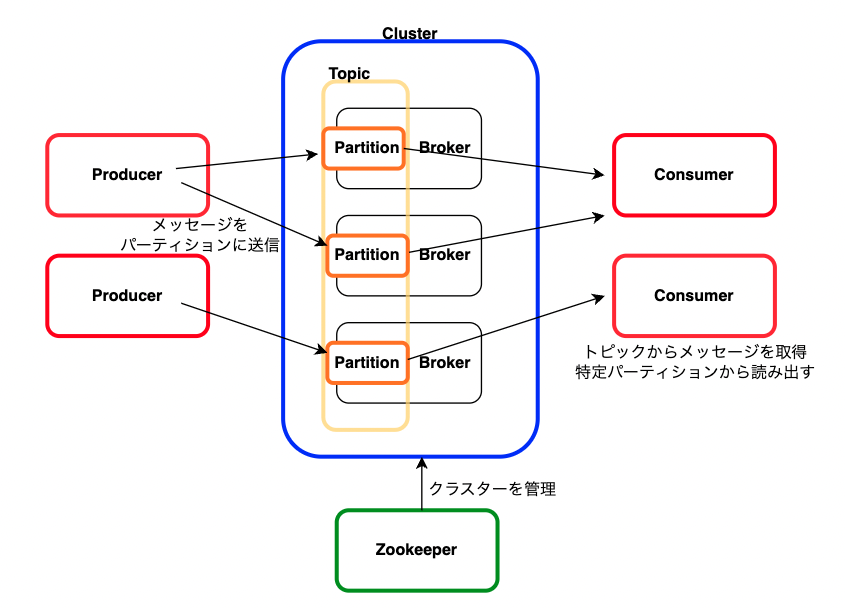
| クラスター | ブローカー、トピック、パーティション、Zookeeperなどを構成する基盤システム |
| ブローカー | メッセージシステムの中核となるサーバー Producerから送信されたメッセージ(レコード)を受け取り、トピックのパーティションに格納コンシューマーへのメッセージ配信を行う ・トピック管理とパーティションを組んでおり、読み書きの負荷を分散する ・パーティションのレプリカを他のブローカーに作成する ・コンシューマーが最後に読んだメッセージの位置を記録 (途中から再開が可能になる) |
| トピック | メッセージのカテゴリ、フィードの事でkafkaがデータを整理する基本単位。一度トピックに書き込まれたデータは不変 |
| パーティション | トピックの中でデータを分割・管理する ・データの分割 ・並列処理 ・複数のプロデューサーが同時に異なるパーティションにデータを書き込める ・コンシューマが同時に異なるパーティションからデータを読み出せる ・オフセットの管理 ・レプリケーションによる耐障害性の向上 |
| プロデューサー | メッセージを特定のパーティションに送信する。メッセージを送信する際にパーティションを指定、あるいはkafkaにパーティションの選択を委ねることができる。複数のメッセージをバッチとしてグループ化し、まとめて送信も可能 |
| コンシューマー | トピックからメッセージを取得してトピックの特定パーティションからメッセージを読み出す ↓ トピック内のメッセージが複数のコンシューマーに分散され並行処理が可能になる 読み出したメッセージの位置を管理して、どのメッセージを読んだか追跡する ↓ 障害発生後の再開時に途中から読み出すことができる |
| オフセット | メッセージストリーム内の各メッセージを識別するための固有の識別子。メッセージが属するパーティション内での位置を示す。 |
| Zookeeper | 分散システムにおける構成管理、名づけ、同期、グループサービス等を提供するサービス。ブローカー、トピック、パーテーションなどのメタデータを管理 |
構成図
本記事の主題ではない為、概要以上の事はこのくらいに留めたいと思います
まとめ
このような失敗はしたくないですが、代わりに色々と学びがありました。
この経験を今後に生かして、長期的にみたらマイナスからプラスになるようにしていければと思います。
参考文献:
kafka公式
https://kafka.apache.org/
解説記事
https://qiita.com/sigmalist/items/5a26ab519cbdf1e07af3
https://qiita.com/sigmalist/items/73d3feeb6e0f5905ed64
https://note.com/commonerd/n/n055f749713d9